論文の原文:必要なのは注意だけです
最近、ネットワークを学習しているときに、多くの新しい論文のネットワーク設計が以前の古典的なネットワークの構造を依然として使用していることがわかりました。3D 点群の分野では、Frame-toFrame 構造に属する非常に人気のあるネットワーク Deep Closet Point (DCP) があり、Transformer モジュールはネットワーク設計部分で言及されています。
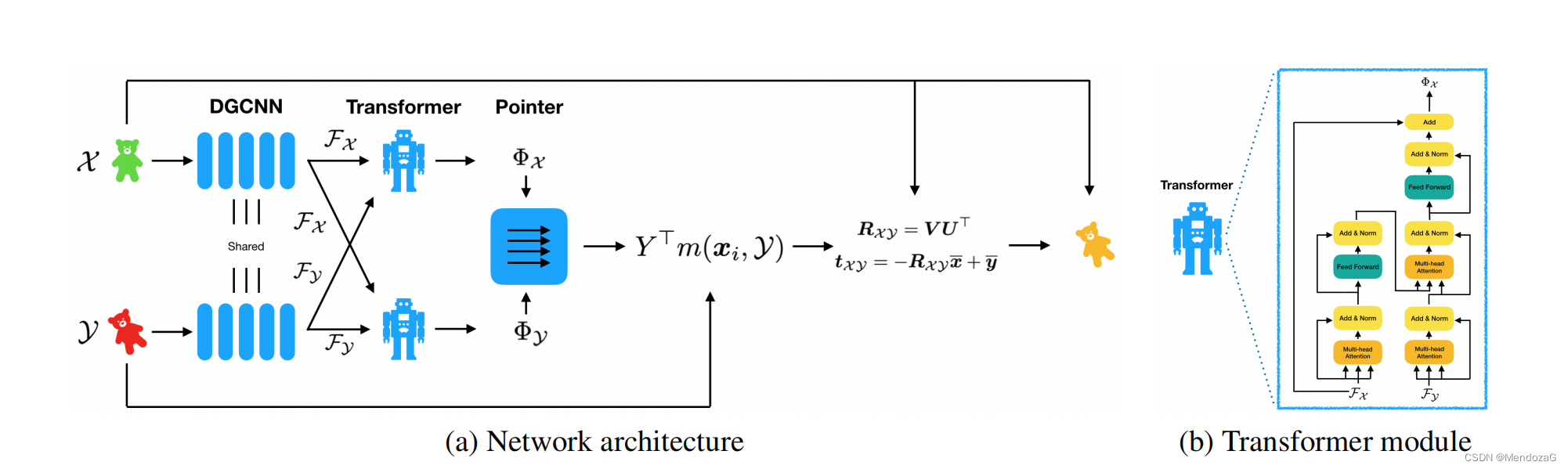
そしてエフェクトを比較すると、DCPにもV1とV2の2つのバージョンがあり、違いはアテンションモジュールが追加されているかどうかです。この論文の著者である Wang Yue 氏は DGCNN (Dynamic Graph CNN) の著者でもあり、変圧器に影響を受けてこのような構造を設計しました。
Transformer モジュールの構造を拡大すると次のようになります。
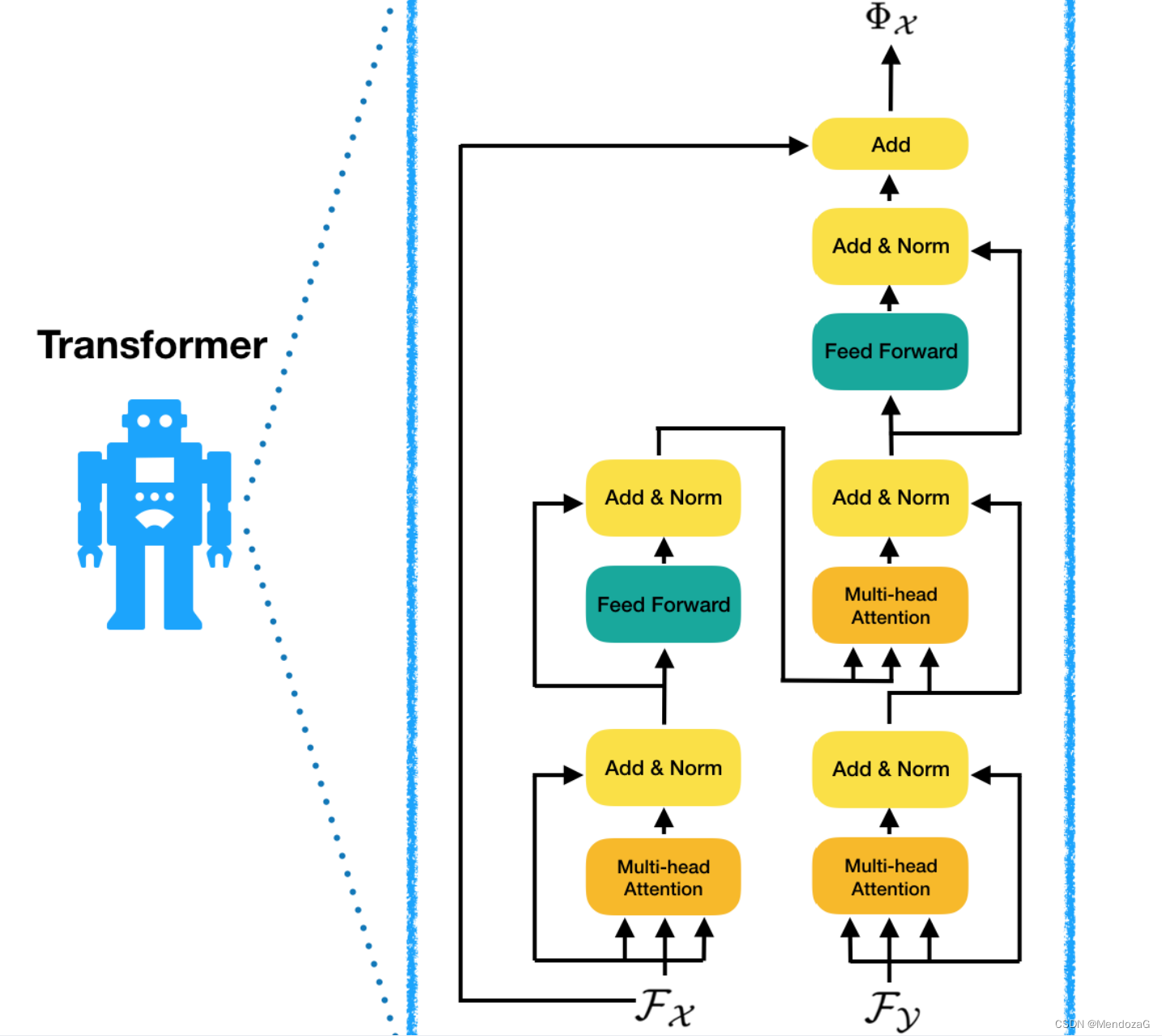
トランスフォーマーの構造は次のとおりです。
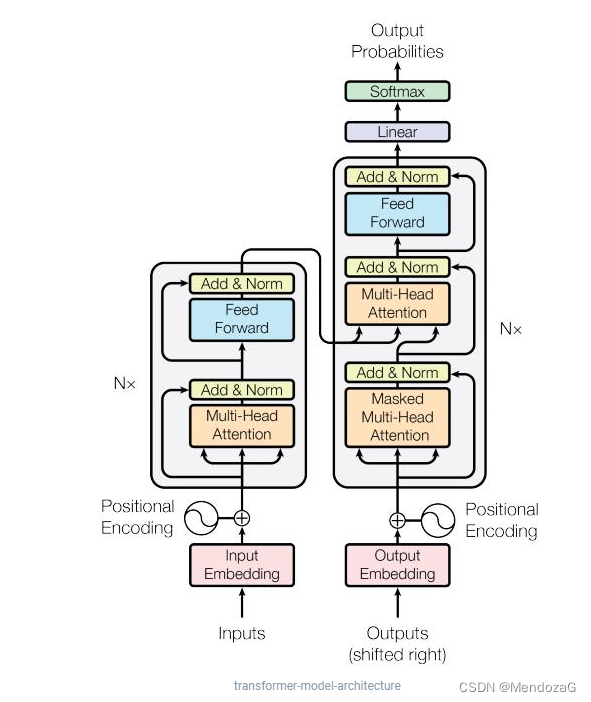
左側がエンコーダー、右側がデコーダーです。このモデルは 2017 年に Google によって提案され、NLP の問題を解決するために初めて使用されました。以下に示すように:

まずは簡単な図を見てみましょう。
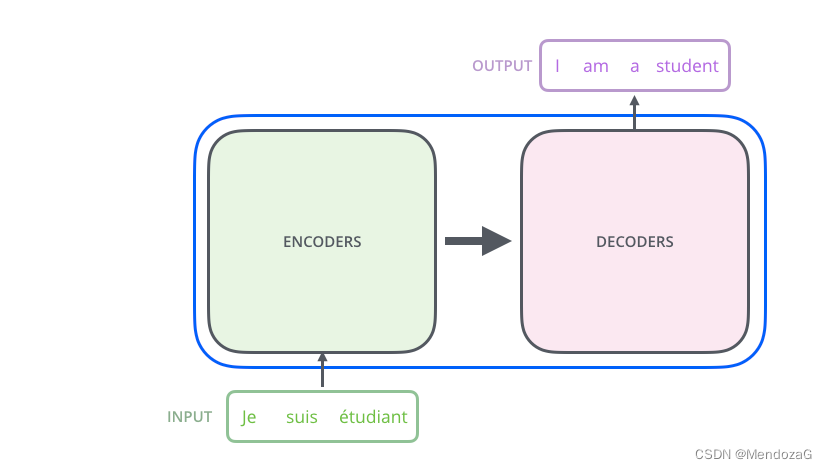
入力はフランス語、出力は英語で、フランス語の単語が何らかのフランス語(埋め込み)を経てEncoderに入力され、Decoderを経て英語の単語として出力される、というのが直感的に感じられることです。では、Encoder モジュールと Decoder モジュールはどのように設計されているのでしょうか。
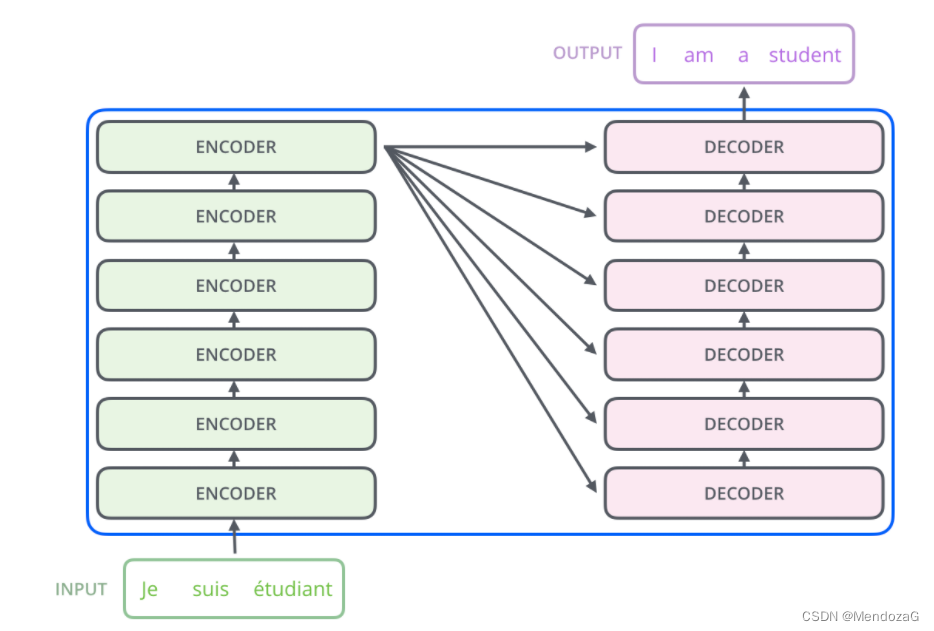
実際、これら 2 つのモジュールは一連のエンコーダとデコーダで構成されています。上図の構造は 6 です。実際には、設計と要件によって異なりますが、エンコーダとデコーダの数は同じである必要があります。
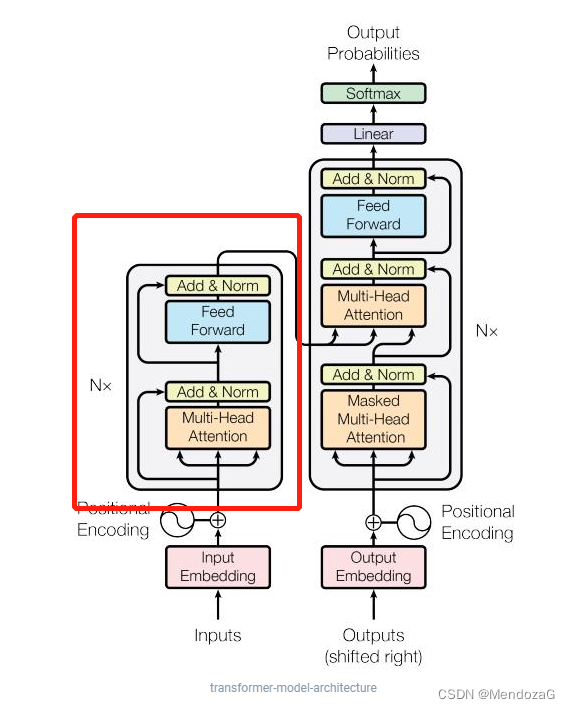
モジュールをスケールアップします。
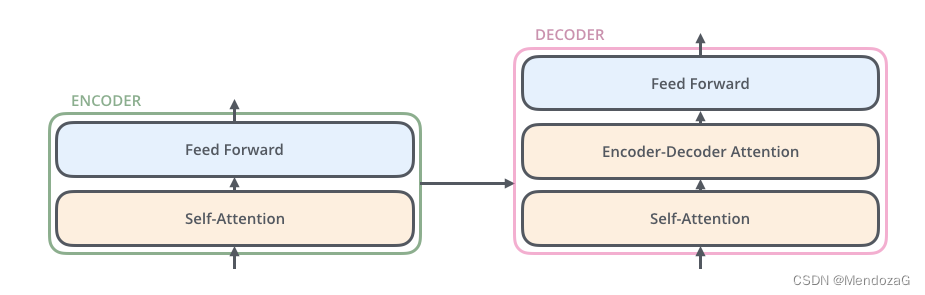
この 2 つは構造が似ており、デコーダーの中央にはアテンション レイヤーの層があり、デコーダーが入力の関連部分に焦点を当てるのに役立ちます。
先ほど述べた、入力された単語を特定の形式 (ベクトル) に変換する方法は、NLP では埋め込みアルゴリズムと呼ばれます。それは次のように理解できます。

実際に実装するのは次のとおりです。

このうち z は自己注意の結果であり、ソフトマックスの結果です。詳細については後述する。この自己注意の部分について詳しく話しましょう。
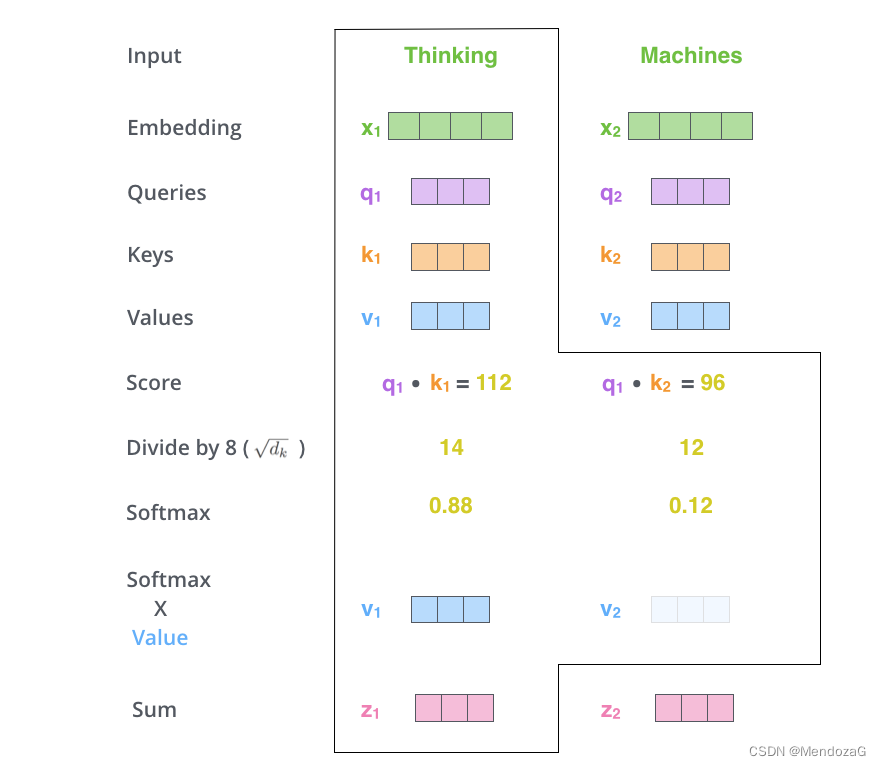
この部分は論文の非常に重要な部分に関係します: Q、K、V。最初にこれら 3 つの文字を見たとき、私たちは間違いなく少し混乱するでしょう。実際、この 3 つは次のことを表します: クエリ、キー、値。実際にはQueryとKeyのマッチングを行い、異なるキーに対応する値を組み合わせてスコアを出し、スコアが高いものにはより高いアテンションを与える、これがアテンションの仕組みです。
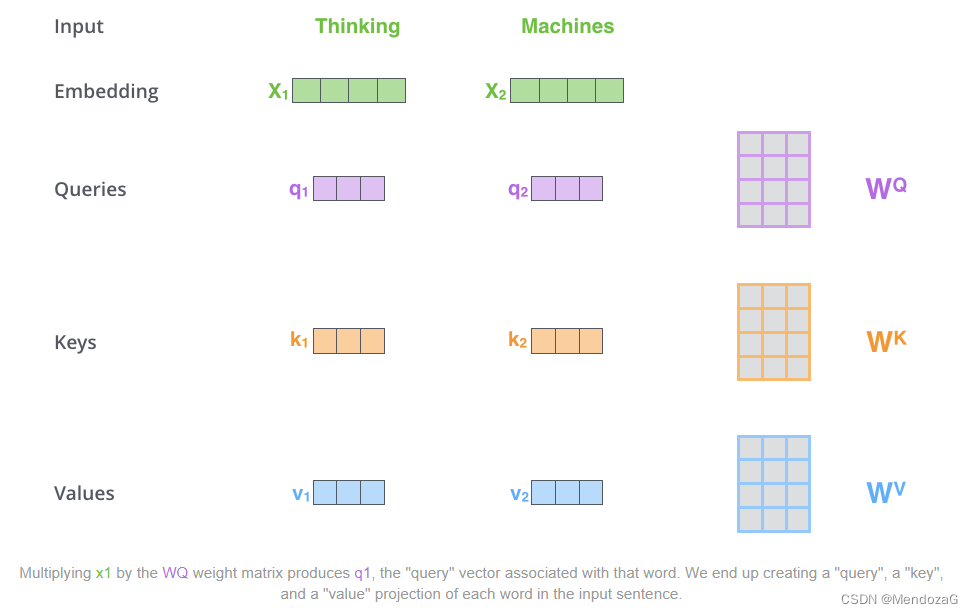
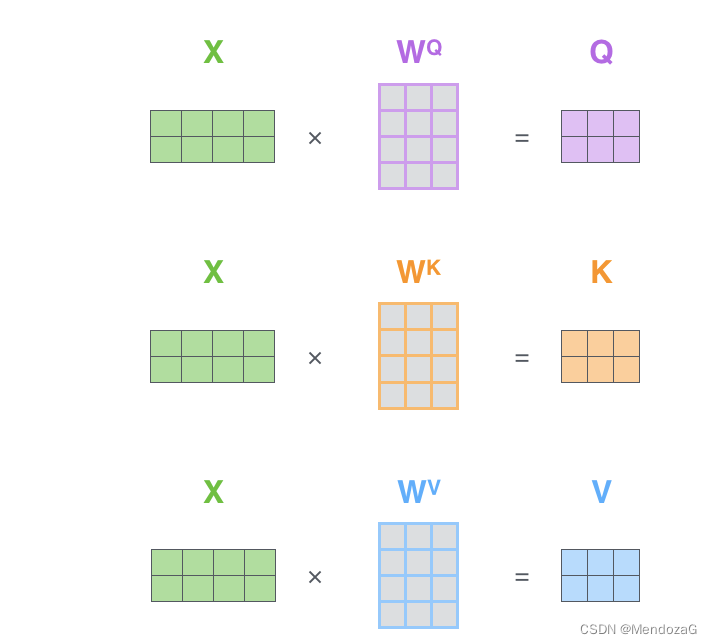
上記の 3 つの行列はトレーニング中に取得されます。
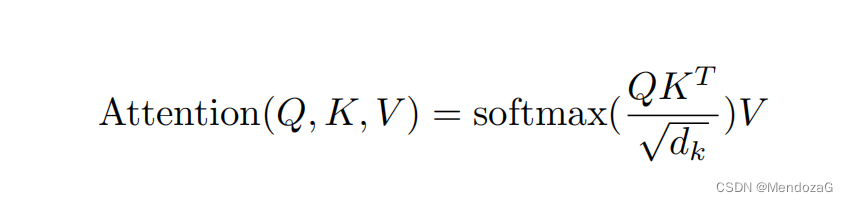
上の式の値は、上で説明した Z 値です。
この図は 1 つを理解するためのものですが、複数の場合はどうなるでしょうか。構成マトリックス:
また、Z 値は次のように表すこともできます。
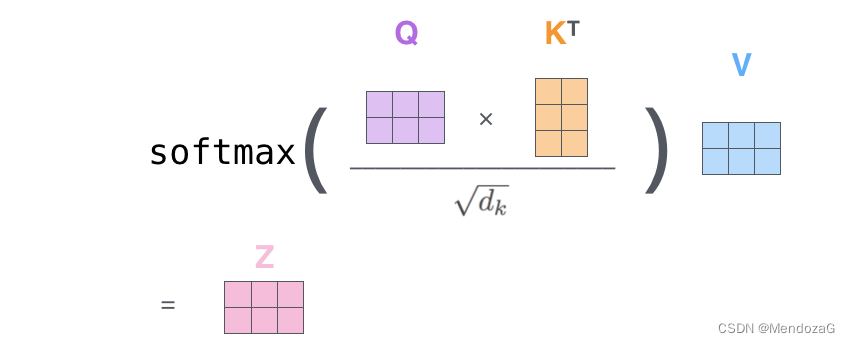
Q と Kの掛け算は、各要素の内積を組み合わせることで理解できます。2 つのベクトルの内積は、2 つのベクトル間の相関関係を特徴付けます。0 であれば、2 つが一致していることを意味します。相関関係はなく、1 に近いほど、両者の相関度は高くなります。
ここで、 dk は入力ベクトルの次元です。次元で除算するのは、勾配の安定性を確保するためです。勾配の消失を効果的に制御できます。Q と K の両方が平均値 0、分散 1 の dk 次元行列であると仮定すると、乗算の結果は平均値 0、分散は dk になります。ルート記号なので、ルート記号の下を dk で割ります。
マルチヘッドの場合、これは複数のスプライシングと線形化の結果です。
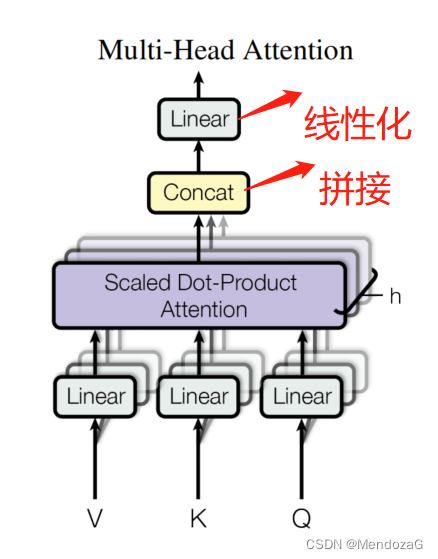
プロセス全体は次のように理解できます。
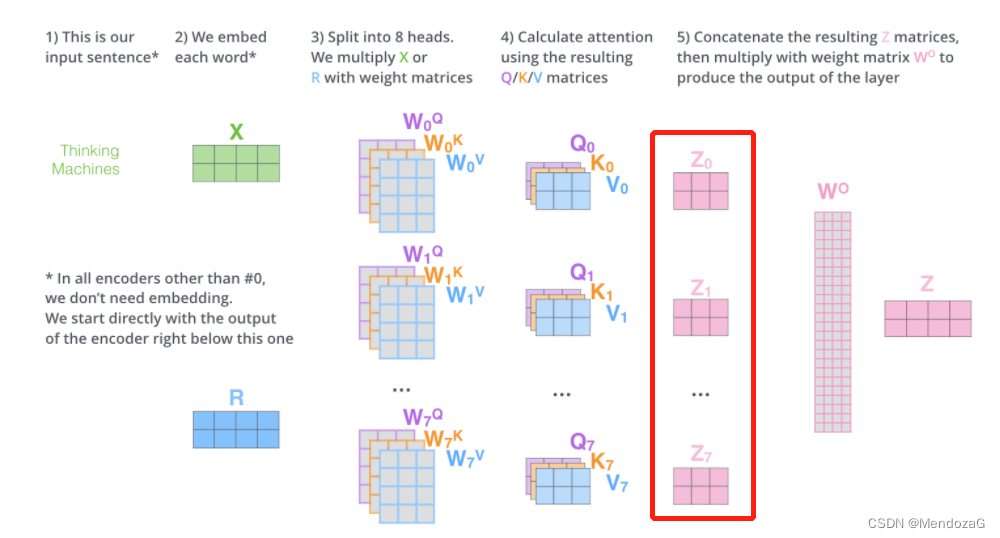
以下に応用例を示します。
区別: The animal didn't cross the street because it was too tired"これは、人間にとっては非常に単純ですが、機械にとってはそうではないものを指します。マルチヘッド モデルは次のとおりです。

z1 と z2 の値から、動物と疲労は機械に対する高い注意力に基づいていることがわかります。
5つのレイヤーを展開すると以下のようになりますが、少しわかりにくいかもしれません。

さらに、語順の問題という未解決の問題もあります。同じ単語や文章で構成された文章でも、語順が異なると意味が変わってしまいますが、これをインターネット上で実現するのは困難です。したがって、位置エンコード部分はネットワークに入る前に追加されます。
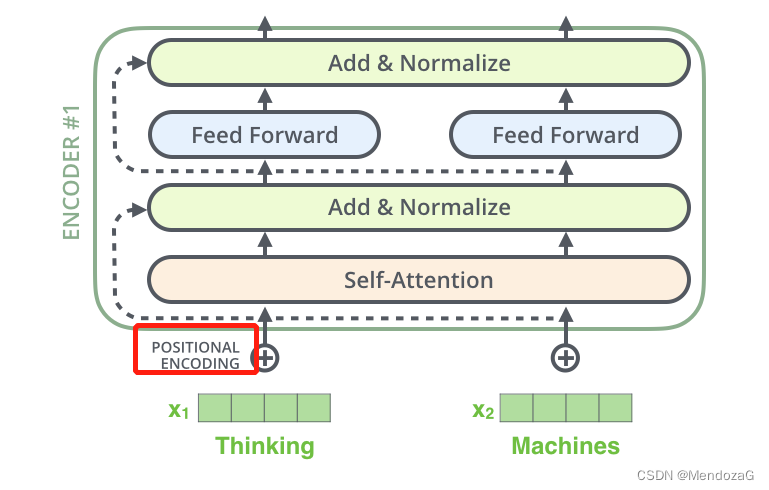
また、入力と出力の次元が異なる場合がありますので、このときパディングマスクを削除する必要がありますが、通常はソフトマックス値が0になるように対応する位置に負の無限大を追加します。
上図の構造では、Add&Normalization は次のように視覚的に表現できます。
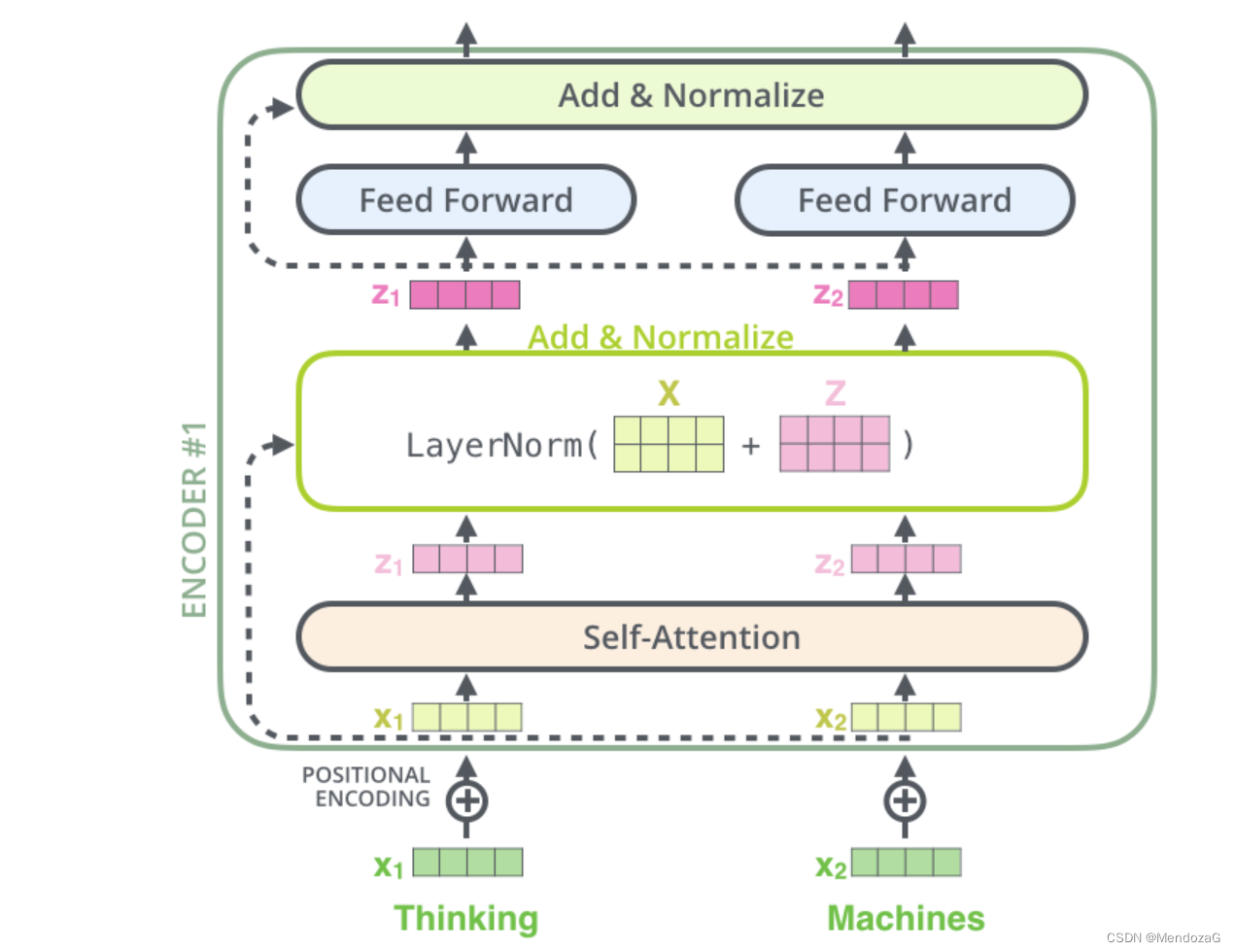
-------------------------------------------------- --------------------------------------
この記事のほとんどの写真は次からのものです。
The Illustrated Transformer – Jay Alammar – 機械学習を一度に 1 つの概念を視覚化します。
上記の記事はとても良いものなので、ぜひ読んでみてください。
読むか見ることもお勧めします:
1. Self-Attention と Transformer - machine-learning-notes (これは推奨記事の解釈です)