Datawhale202211 Li Hongyi "Machine Learning" (Deep Learning Direction) P5-P8 - Error and Gradient Descent
Article Directory
foreword
This section introduces the relevant knowledge of error and gradient, which is the basis of model training. At the same time, we will also see some coping strategies for problems in the training process, which are more theoretical.
1. Error
Where did the error come from?
Error - the accuracy of the entire model;
Bias - the error between the output of the model on the sample and the true value;
Variance - the error (stability) between each output of the model and the output of the model
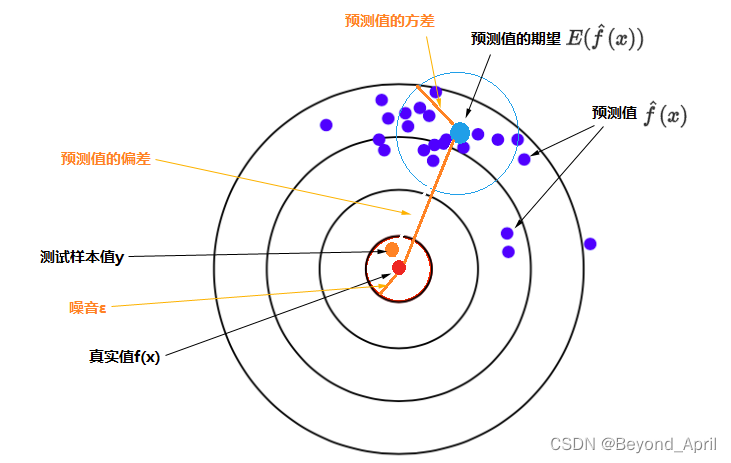
In the actual experiment process, Bias and Variance often cannot have both. We try to use limited training samples to estimate unlimited real data. When we believe in the authenticity of the data, it is easy to ignore the bright knowledge of the model. By ensuring the accuracy of the model on the training samples to reduce the bias of the model, it is easy to overfit. Increase the uncertainty of the model; if we are more inclined to the prior knowledge of the model, we will increase the stability by increasing the limit, which will increase the Bias. Therefore, trade-off bias and variance are important topics.
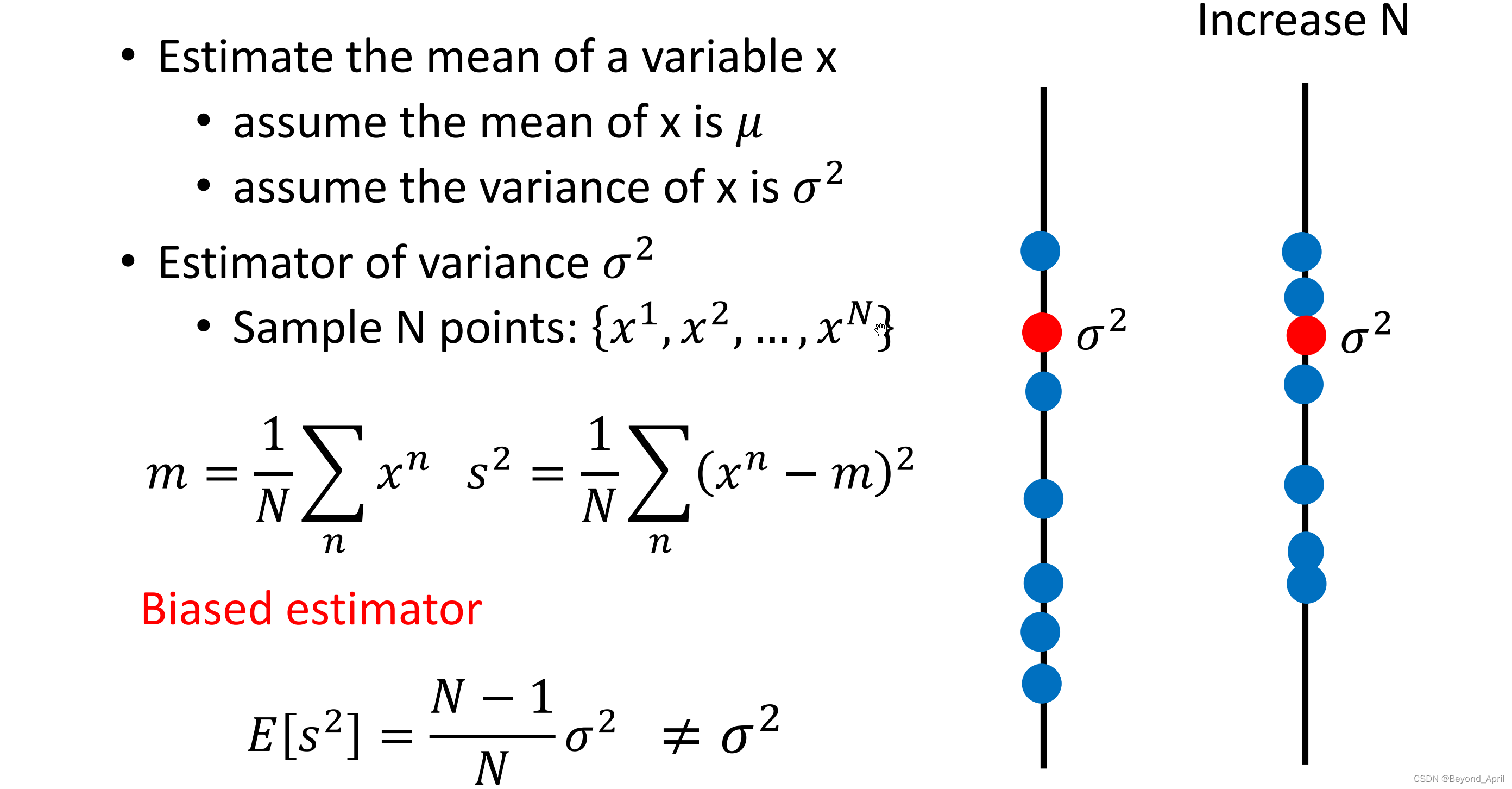
estimate
- Evaluate the bias of x
Assuming that the mean of x is μ and the variance is σ^2, evaluate the mean
- Get N sample points
- Calculate the mean m (m≠μ)
- Calculate multiple groups of m and find the expectation E(m)
- find the variance
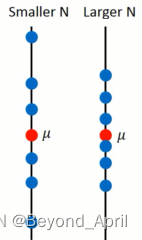
- Evaluate the variance of x
judgment
No good training set - too much deviation - underfitting
Good training set, big problem in test set - large variance - overfitting
- Large deviation - underfitting
- Redesigned model
- Add more parameters or consider more complex models
- Large variance - overfitting
- train with more data
- Dataset augmentation: cropping, shifting...
choose
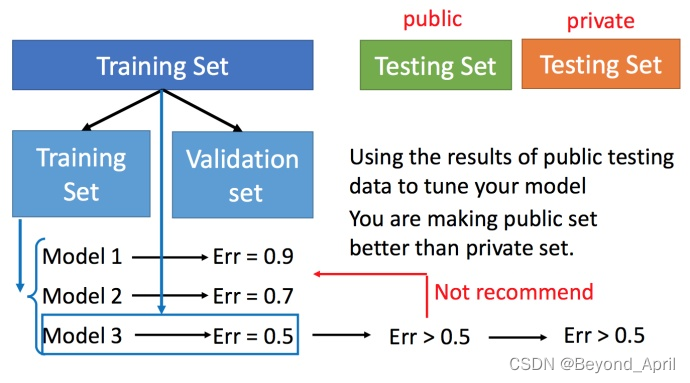
- Cross-validation
Cross-validation is to divide the training set into two parts, one part is used as the training set and the other part is used as the verification set.
- Determine the model with the newly split training and validation sets
- Then use the entire training set and validator to experiment with the model and make adjustments
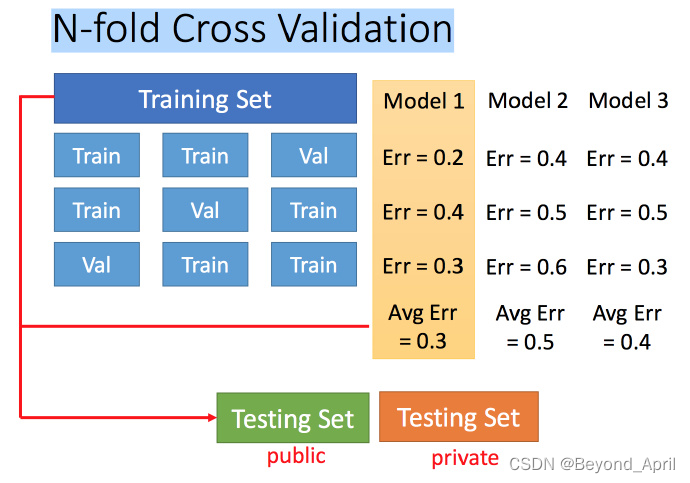
- N-fold cross-validation
- Divide the training set into multiple parts, and train multiple models separately
- Choose the best global training of Average
2. Gradient descent
Adjust the learning rate
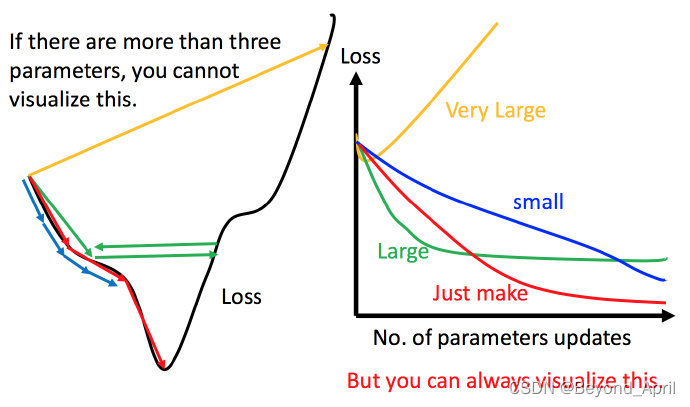
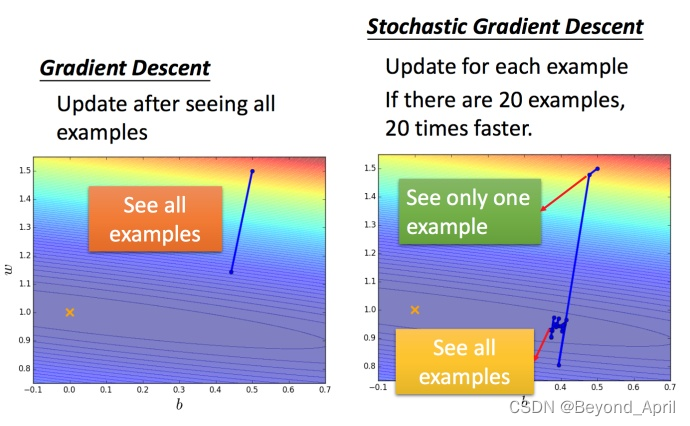
stochastic gradient descent
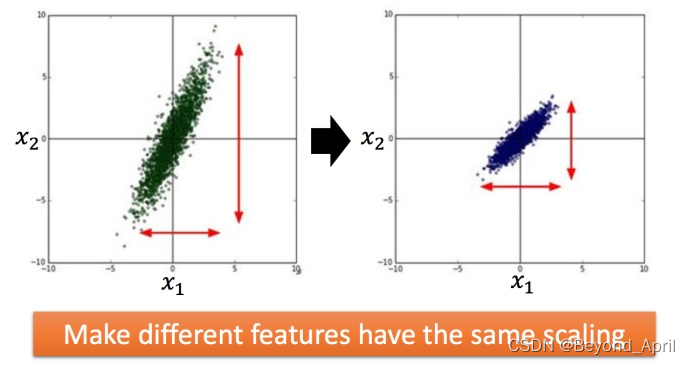
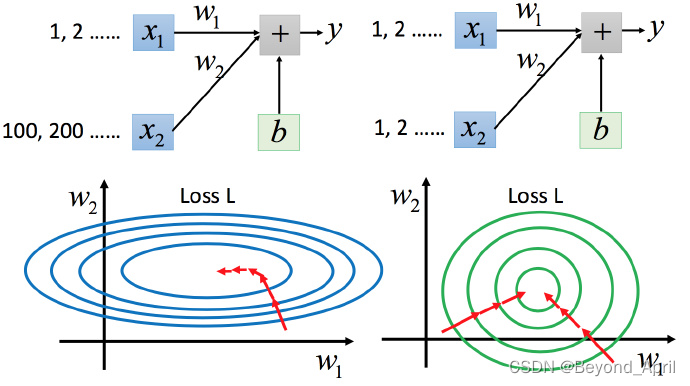
feature scaling
3. Reference documents
Feeding from Datawhale
Li Hongyi's "Machine Learning" open source content 1:
https://linklearner.com/datawhale-homepage/#/learn/detail/93
Li Hongyi's "Machine Learning" open source content 2:
https://github.com/datawhalechina/leeml -notes
Li Hongyi's "Machine Learning" open source content 3:
https://gitee.com/datawhalechina/leeml-notes
Feeding from the official
Li Hongyi's "Machine Learning" official address
http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
Li Mu's "Hands-On Deep Learning" official address
https://zh-v2.d2l.ai/
Feeds from netizens
Gradient basic knowledge reference
https://blog.csdn.net/weixin_50967907/article/details/127259554
Summarize
1. This course is very suitable for novices, and the inner logic of each step is explained very well.
2. It is a pity that many concepts are difficult to get quickly without actual combat. You can match some actual combat exercises by yourself, and you will have the opportunity to continue later.
3. Thanks to the datawhale friends for their support, especially the support and help within the group, and make persistent efforts.