essay
Dissatisfaction with oneself is a fundamental characteristic of any talented person

Reference books:
- "Phoenix Architecture"
- "Microservice Architecture Design Patterns"
Before the start of this article, I would like to remind readers that it is better for readers to read with "what is the difference between IPC and RPC" doubts
introduction
From the perspective of an architect, the first problem to be solved in the implementation of the microservice architecture is how to make remote service calls.
I guess those who have been exposed to the microservice architecture have RPC frameworks such as dubbo, feign, openfeign, etc. in their minds to realize remote service calls. But during the interview process, if the interviewer asks everyone what the realization principles of these remote service frameworks are, some friends will be dumb (the previous bloggers experienced it during the interview). The main purpose is to study hard every day, and now I will summarize what I have learned and publish it in the form of articles, in addition to consolidating myself, I also hope to bring a little help to everyone.
Inter-process communication (IPC)
Inter-process communication: refers to the interaction between the data of two processes
Before understanding IPC, let's take a look at how the same process interacts with data. Let's take a classic case program "hello world" as an example:
// Caller : 调用者,代码里的main()
// Callee : 被调用者,代码里的println()
// Call Site : 调用点,即发生方法调用的指令流位置
// Parameter : 参数,由Caller传递给Callee的数据,即“hello world”
// Retval : 返回值,由Callee传递给Caller的数据。以下代码中如果方法能够正常结束,它是void,如果方法异常完成,它是对应的异常
public static void main(String[] args) {
System.out.println("hello world");
}
Result of decompilation (javap -c **.class):
public class com.servicemeshmall.componet.infrastructure.config.RedisConfig {
public com.servicemeshmall.componet.infrastructure.config.RedisConfig();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}
Let's analyze this program from starting to calling the println() method to output the line hello world, the computer (physical machine or virtual machine) needs to complete the following tasks:
- Call the getstatic bytecode instruction to get the PrintStream static object in System
- Call the ldc bytecode instruction to push the reference address of the string helloworld onto the stack (transfer method parameters)
- According to the signature of the println() method, determine its execution version. This is actually not a simple process. Whether it is static analysis at compile time or dynamic allocation at runtime, in short, it is necessary to find a clear Callee according to the clearly defined principles in some language specifications. "Definite" refers to the only A Callee, or multiple Callees with strict priorities, such as different overloaded versions. This process is not reflected in the result of decompilation, but it is a process that will be executed before the method is called. (to determine the method version)
- Call invokevirtual bytecode instruction, instruction println() method (execute called method)
- Call the return bytecode instruction, push the execution result of Callee to the stack, and restore the instruction flow of the program to the next instruction of Call Site, and continue to execute downward
The above is the core execution process of the method call in java. Putting it in the same JVM, this process is no problem, but let’s think about it, if it is called in a different JVM, what problems will happen? There are two immediate obstacles: First, the second and fifth steps to pass parameters and return results all rely on the help of stack memory. If Caller and Callee belong to different processes, they will not have the same stack Memory, pushing parameters in the memory of the Caller process is meaningless for the execution of the Callee process. Secondly, the method version selection in the third step depends on the definition of language rules. If Caller and Callee are not programs implemented in the same language, method version selection will be a fuzzy and unknowable behavior.
IPC is a technology that emerged to solve the two obstacles of the appeal. For the sake of simplicity, we ignore the second obstacle for the time being. Assuming that Caller and Callee are implemented in the same language, let’s first solve how to communicate between the two processes. The problem of exchanging data. There are several ways that can be considered (citing the book "Phoenix Architecture"):
- Pipe (Pipe) or Named Pipe (Named Pipe): A pipe is similar to a bridge between two processes, and a small amount of character stream or byte stream can be passed between processes through the pipe. Ordinary pipes are only used for communication between related processes (another process started by one process). Named pipes get rid of the limitation of ordinary pipes without names. In addition to having all the functions of pipes, they also allow unrelated processes. Communication. A typical application of the pipeline is the | operator in the command line, for example:
ps -ef | grep java
- Signal (Signal): The signal is used to notify the target process that a certain event has occurred. In addition to being used for inter-process communication, the process can also send a signal to the process itself. A typical application of a signal is the kill command, for example:
# Shell 进程向指定 PID 的进程发送 SIGKILL 信号
kill -9 pid
- Semaphore (Semaphore): The semaphore is used for synchronization and cooperation between two processes. It is equivalent to a special variable provided by the operating system, and the program can perform wait() and notify() operations on it. (In short, it is to communicate between processes through a shared variable. Locking and unlocking are actually a communication method, which is provided by the operating system level)
- Message Queue (Message Queue): The above three methods are only suitable for transferring a small amount of information. The POSIX standard defines a message queue for communication with a large amount of data between processes. Processes can add messages to the queue, and processes that have been granted read permission can consume messages from the queue. The message queue overcomes the shortcomings of the small amount of information carried by the signal, the pipeline can only be used for unformatted byte streams, and the buffer size is limited, but the real-time performance is relatively limited.
- Shared Memory: Allows multiple processes to access the same common memory space, which is the most efficient form of inter-process communication. Originally, the memory address spaces of each process were isolated from each other, but the operating system provides a program interface that allows processes to actively create, map, separate, and control a certain piece of memory. When a block of memory is shared by multiple processes, each process is often used in combination with other communication mechanisms, such as semaphores, to achieve inter-process synchronization and mutual exclusion coordination operations. (It can be controlled by the program, which is different from the method level in 3)
- Socket interface (Socket): Message queues and shared memory are only suitable for communication between multiple processes on a single machine. The socket interface is a more general inter-process communication mechanism that can be used for process communication between different machines. Socket (Socket) was originally developed by the BSD branch of the UNIX system, and has now been ported to all major operating systems. For the sake of efficiency, when it is limited to local inter-process communication, the socket interface is optimized, it does not go through the network protocol stack, and does not require operations such as packaging and unpacking, calculation of checksums, maintenance of sequence numbers, and responses. It simply copies the application layer data from one process to another. This inter-process communication method has a proper name: UNIX Domain Socket, also known as IPC Socket
Now we have a variety of capabilities to implement inter-process communication, but which method is more suitable for implementation requires us to consider several issues from a higher-level perspective (the question comes from: Professor Andrew Tanenbaum's paper "A Critique of The Remote Procedure Call Paradigm"):
- Two processes communicate, who is the server and who is the client?
- How to handle exceptions? How should the caller be notified of the exception?
- What should I do after multi-thread competition occurs on the server?
- How to improve the efficiency of network utilization, such as whether the connection can be multiplexed by multiple requests to reduce overhead? Is multicast supported?
- How to express parameters and return values? What endianness should it have?
- How to ensure the reliability of the network? For example, what should I do if a link is suddenly disconnected during the call?
- What should I do if the sent request server does not receive a reply?
- …
As for why the question was raised, it is because the scientific community initially implemented inter-process communication through sockets, hiding the communication details of remote method calls at the bottom of the operating system. Obviously, history has proved that this method is used to achieve inter-process communication. It is a directional error. As for why this is a directional error, the big guys have summarized the following problems in socket implementation through the paper "Eight Fallacies of Distributed Computing Through the Network" (note , the following is irony):
- The network is reliable - the network is reliable.
- Latency is zero - Latency is non-existent.
- Bandwidth is infinite - the bandwidth is infinite.
- The network is secure - The network is secure.
- Topology doesn't change - Topology is static.
- There is one administrator -- there is always one administrator.
- Transport cost is zero - do not have to consider the transmission cost.
- The network is homogeneous - the network is homogeneous.
Since the IPC that we wanted to implement through the socket at the beginning did not meet the conditions required for remote service calls under distributed computing, then we need to use other methods to meet the requirements of remote service calls under distributed computing. There are two methods of remote service invocation under distributed computing: HTTP Rest and RPC framework.
Remote Service Call (RPC)
Remote service calls refer to two programs located in non-overlapping memory address spaces, and at the language level, use a channel with limited bandwidth to transmit program control information in a synchronous manner.
- Bruce Jay Nelson, Remote Procedure Call , Xerox PARC, 1981
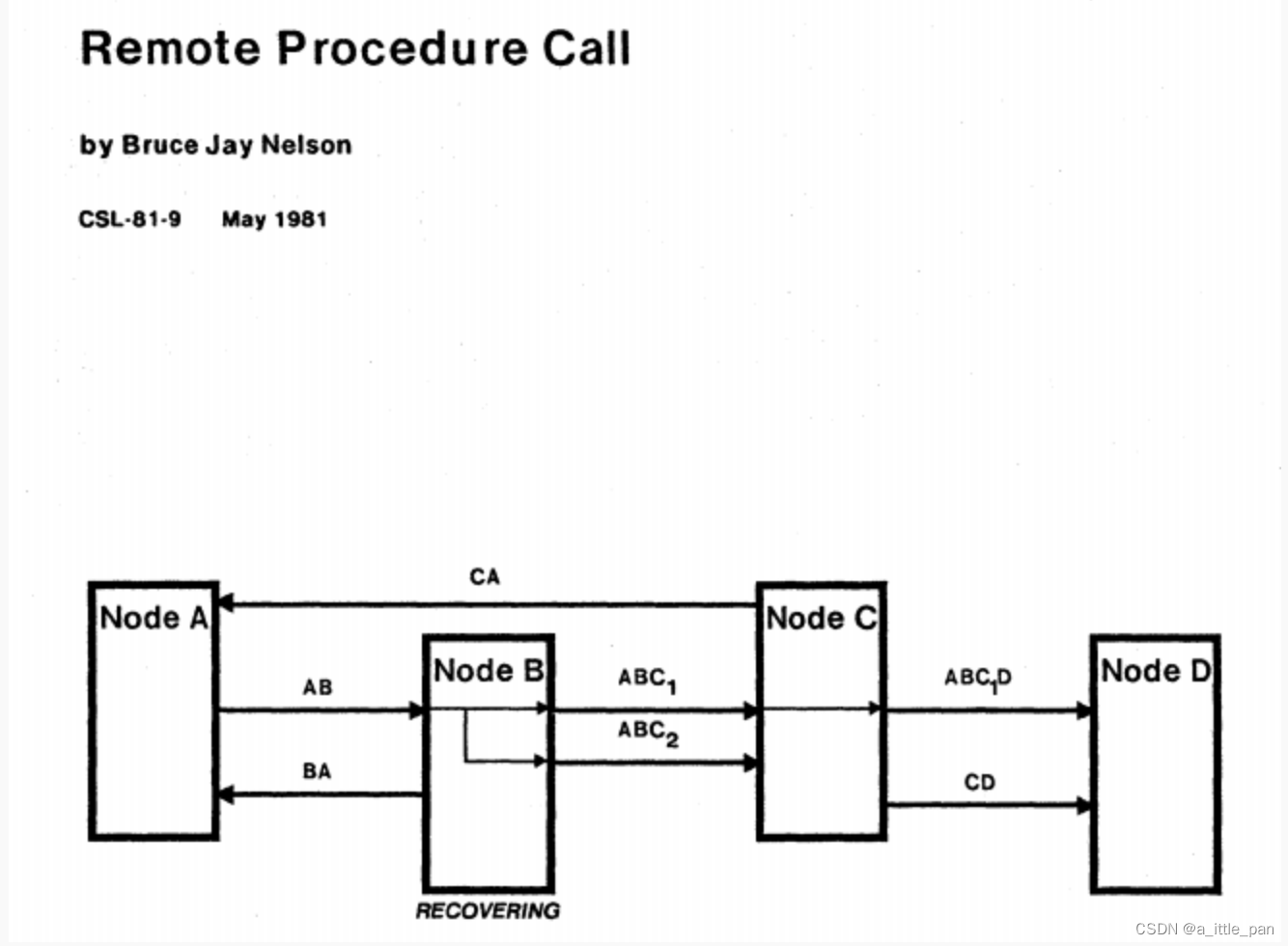
In the early 1980s, the legendary Xerox Palo Alto Research Center released the Cedar language-based RPC framework Lupine, and implemented the world's first RPC-based commercial application Courier, and the above-mentioned RPC concept was also proposed by Xerox.
Now RPC frameworks are flying all over the sky, well-known RMI (Sun/Oracle), Thrift (Facebook/Apache), Dubbo (Alibaba/Apache), gRPC (Google), Motan1/2 (Sina), Finagle (Twitter), brpc ( Baidu/Apache), .NET Remoting (Microsoft), Arvo (Hadoop), JSON-RPC 2.0 (public specification, JSON-RPC working group), etc.
As for why there are so many RPCs at present, it is because none of the RPC protocols adopted by the current RPC framework can solve the "three problems in the RPC process" well, and each framework has a different focus, such as (quoted from " Phoenix Architecture"):
- Towards object-oriented development, not satisfied with RPC bringing process-oriented coding to distributed, hoping to be able to perform cross-process object-oriented programming in distributed systems, represented by RMI, .NET Remoting, the previous CORBA and DCOM Can also be classified into this category, this line has an alias called distributed object (Distributed Object)
- Development towards performance, represented by gRPC and Thrift. There are two main factors that determine RPC performance: serialization efficiency and information density. Serialization efficiency is well understood. The smaller the capacity of serialized output results, the faster the speed and the higher the efficiency; the information density depends on the proportion of the payload (Payload) in the protocol to the total transmitted data. Using the transmission protocol The higher the level, the lower the information density, as evidenced by the poor performance of SOAP using XML. Both gRPC and Thrift have their own excellent proprietary serializers. In terms of transport protocols, gRPC is based on HTTP/2 and supports multiplexing and header compression. Thrift is implemented directly based on the TCP protocol of the transport layer, eliminating the need for The overhead of additional application layer protocols.
- It is developing towards simplification, represented by JSON-RPC. It may be controversial to choose the RPC with the strongest function and the fastest speed, but JSON-RPC will definitely be one of the candidates for the weak and slow one. Function and efficiency are sacrificed in exchange for simplicity and portability of the protocol, and the interface and format are more common, especially suitable for applications such as web browsers that generally do not have additional protocol support or additional client support.
Although the current RPC framework does not meet the requirements of the "perfect RPC protocol" that solves the "three problems that RPC needs to solve", the RPC framework from Alibaba—Dubbo (although it is not maintained by Ali now~), needs to be praised. It has its own transport protocol (Dubbo protocol) by default, and also supports other protocols; by default, Hessian 2 is used as the serializer. If you have JSON needs, you can replace it with Fastjson. If you have higher performance requirements, you can Replace it with more efficient serializers such as Kryo, FST, and Protocol Buffers. If you don't want to rely on other component libraries, you can directly use the serializer that comes with JDK. This design alleviates to a certain extent the RPC framework must choose, it is difficult to be perfect.
Three problems that RPC needs to solve ("Phoenix Architecture")
In the mid-to-late 1980s, Hewlett-Packard and Apollo proposed the idea of Network Computing Architecture (NCA), and then developed it into a remote service call framework DCE/RPC under the UNIX system in the DCE project. The author once DCE was introduced in the "original distributed era", which is the first attempt to explore distributed organization in history. Since DCE itself is based on the UNIX operating system, DCE/RPC is usually only suitable for UNIX system programs (MS RPC, the predecessor of Microsoft COM/DCOM, is a variant version of DCE. If these derivative versions are counted, it will be more common). In 1988, Sun Microsystems drafted and submitted the RFC 1050 specification to the Internet Engineering Task Force (IETF), which designed a set of TCP/IP-based support for wide area networks or mixed network environments. The RPC protocol in C language was later called ONC RPC (Open Network Computing RPC, also known as Sun RPC). These two sets of RPC protocols are the originators of various RPC protocols and frameworks today. All the RPC protocols that have been popular in the past few decades are nothing more than using various means to solve the following three basic problems:
- How to represent data: The data here includes the parameters passed to the method and the return value after the method is executed. Whether it is passing parameters to another process or retrieving execution results from another process, it involves how they should be expressed. The method call in the process can easily solve the problem of data representation by using the data type preset by the programming language and the data type customized by the programmer. The remote method call may face the situation that the two sides of the interaction use different programming languages; even if only one For the RPC protocol of different programming languages, under different hardware instruction sets and different operating systems, the same data type may have different performance details, such as differences in data width and byte order, and so on. An effective method is to convert the data involved in the interaction into a neutral data stream format agreed in advance for transmission, and convert the data stream back to the corresponding data type in different languages for use. This process is difficult to say, but I believe everyone must be familiar with it, that is, serialization and deserialization. Each RPC protocol should have a corresponding serialization protocol, such as:
- ONC RPC 的External Data Representation (XDR)
- CORBA 的Common Data Representation(CDR)
- Java RMI 的Java Object Serialization Stream Protocol
- gRPC 的Protocol Buffers
- Web Service 的XML Serialization
- JSON Serialization supported by many lightweight RPCs
- How to transfer data: To be precise, it refers to how to interoperate and exchange data between endpoints of two services through the network. Here, "exchange data" usually refers to the application layer protocol, and the actual transmission is generally based on standard transport layer protocols such as TCP and UDP. The interaction between two services is not just throwing a serialized data stream to represent parameters and results. Many other information, such as exceptions, timeouts, security, authentication, authorization, transactions, etc., may cause both parties to exchange information demand. In computer science, there is a special name "Wire Protocol" to represent the behavior of exchanging this type of data between two Endpoints. Common Wire Protocols are:
- Java Remote Message Protocol for Java RMI (JRMP, also supports RMI-IIOP)
- CORBA's Internet Inter ORB Protocol (IIOP, which is the implementation version of the GIOP protocol on the IP protocol)
- DDS 的Real Time Publish Subscribe Protocol(RTPS)
- Web Service 的Simple Object Access Protocol(SOAP)
- If the requirements are simple enough, both parties are HTTP Endpoints, it is also possible to use the HTTP protocol directly (such as JSON-RPC)
- How to determine the method: This is not a big problem in the local method call. The compiler or interpreter will convert the called method signature into a pointer to the entry position of the subprocess in the process space according to the language specification. However, once different languages are considered, things will immediately become troublesome. The method signatures of each language may be different, so "how to express the same method" and "how to find the corresponding method" still have to be unified across languages Standard will do. This standard can be very simple to implement, such as directly specifying a unique number for each method of the program, which will never be repeated on any machine. When calling, it does not matter how its method signature is defined, and directly passes this number You can find the corresponding method. This method, which sounds rude and shabby, is really the solution that DCE/RPC originally prepared. Although in the end DCE still came up with a set of language-independent Interface Description Language (Interface Description Language, IDL), which became the basis for many RPC references or dependencies (such as CORBA's OMG IDL), but the only coding scheme that never repeats UUID (Universally Unique Identifier) is also preserved and widely circulated, and today it has been widely used in all aspects of program development. Similarly, protocols for representing methods are:
- Android 的Android Interface Definition Language(AIDL)
- CORBA 的OMG Interface Definition Language(OMG IDL)
- Web Service 的Web Service Description Language(WSDL)
- JSON-RPC 的JSON Web Service Protocol(JSON-WSP)
The above three basic problems in RPC can all find corresponding operations in the process of calling local methods. The idea of RPC starts with local method calls. Although it has long since ceased to be completely consistent with local method calls, its design idea still bears the deep imprint of local method calls. It is more important for us to grasp the connection between the two to make an analogy. A solid understanding of the nature of RPC can be beneficial.
REST(Representational State Transfer)
Before starting to understand REST (the REST mentioned here is actually the RESTful we often talk about) to implement remote service calls, we need to be clear that REST and RPC are two completely different concepts, and the core of the difference is abstract The goals are different, that is, the difference between resource-oriented programming ideas and process-oriented programming ideas.
REST is an inter-process communication mechanism using the HTTP protocol. Roy Fielding, the father of REST, once said:
REST provides a series of architectural constraints. When used as a whole, it emphasizes the scalability of component interactions, the commonality of interfaces, the independent deployment of components, and middleware that can reduce interaction delays. It strengthens security and also Capable of encapsulating legacy systems
After reading the above explanation, you should find it more difficult to understand REST. Let's understand REST from another angle. In fact, unlike RPC, REST is a higher-level thing than the protocol level (higher level: more abstract than the protocol level). Lu Xun once He said: "The more abstract things are, the harder they are to understand." Lu Xun also said: "To understand abstract things, you must first clarify the abstract concepts." As a loyal fan of Mr. Lu Xun, I chose to listen to Mr. Lu Xun at that time.
But HTTP is a protocol we are familiar with, so this article will not elaborate too much. Let us describe several concepts in REST through specific examples (quoted from "Phoenix Architecture"):
- Resource (Resource): For example, if you are reading an article called "Remote Service Call of Microservice Series", the content of this article itself (you can understand it as the information and data it contains) we call it "resource". Whether you buy a book, read a web page in a browser, print out a document, read it on a computer screen or browse it on a mobile phone, although the appearance is different, the information in it remains the same , you are still reading the same "resource".
- Representation: When you read this article through a computer browser, the browser sends a request to the server "I need the HTML format of this resource", and the HTML returned by the server to the browser is called "representation" , you may get PDF, Markdown, RSS and other forms of versions of this article through other means, and they are also multiple representations of a resource. It can be seen that the concept of "representation" refers to the form of representation when information interacts with users, which is actually consistent with the semantics of the "Presentation Layer" that is often said in our software layered architecture.
- State (State): When you finish reading this article and feel that the blogger wrote it well and then want to like, bookmark, and comment, you send three requests to the server for "like, bookmark, and comment". But "likes, favorites, comments" are relative concepts, and you must rely on "which article you are currently reading" to respond correctly. This kind of contextual information that can only be generated in a specific context is called "status" . What we call stateful (Stateful) or stateless (stateless) are only relative to the server side. The server needs to complete the "like, favorite, comment" request, or remember the user's state by itself : Which article the user is reading now, this is called stateful; or the client can remember the state and tell the server clearly when requesting: I am reading a certain article, and now I want to read its next one, This is called statelessness.
- Transfer: Regardless of whether the state is provided by the server or the client, the behavioral logic of "likes, favorites, and comments" must only be provided by the server, because only the server owns the resource and its representation. In some way, the server increases and displays the number of likes, favorites, and comments of the article, which is called "representational state transfer".
- Uniform Interface (Uniform Interface): The above-mentioned server transfers the representation state "in a certain way". What is the specific way? The answer is the HTTP request. A set of "unified interface" has been agreed in advance in the HTTP protocol, which includes seven basic operations: GET, HEAD, POST, PUT, DELETE, TRACE, and OPTIONS. Any server that supports the HTTP protocol will abide by it. This set of rules, if these actions are taken for a specific URI, the server will trigger the corresponding representation state transition.
- Hypertext Driven (Hypertext Driven): Although the representation state transfer is triggered by the browser actively sending a request to the server, the request leads to the appearance of the result of "likes, favorites, and comments of the article". However, you and I both know that this cannot really be the active intention of the browser. The browser sends different requests to the server according to user behavior, and then displays the content by rendering the resources of the server. As the browser is a common client for all websites, the navigation (state transfer) behavior of any website cannot be preset in the browser code, but is driven by the request response information (hypertext) sent by the server. This is very different from other software with clients. In those software, business logic is often pre-installed in the program code, and there is a dedicated page controller (whether in the server or in the client) To drive the state transition of the page
- Self-Descriptive Messages (Self-Descriptive Messages): Since there may be many different forms of resource representation, there should be clear information in the message to inform the client of the type of the message and how to process the message. A widely adopted self-describing method is to identify the Internet media type (MIME type) in the HTTP Header named "Content-Type", such as "Content-Type : application/json; charset=utf-8", then Note that the resource will be returned in JSON format, please use UTF-8 character set for processing.
In addition to the concepts listed above that are not easy to understand by looking at the names, there is another common misunderstanding that is worth noting in the process of understanding REST. When Fielding proposed REST, the scope he talked about was "architectural style and network software architecture design." "(Architectural Styles and Design of Network-based Software Architectures), rather than a "remote service design style" that is now narrowly understood by people, the scope difference between the two is like the topic "software architecture" discussed in this book Like the topic "Accessing Remote Services" discussed in this chapter, the former is a large superset of the latter, although based on the topic of this section and most people's concerns, we will indeed use the "Remote Service Design Style" As the focus of the discussion, at least the difference in scope should be clearly stated.
Now that we have understood the basic concepts of REST, let's take a look at REST's Richardson Maturity Model. The model proposes four levels (0-3):
- Level 0: The client of the Level 0 service only initiates an HTTP POST request to the service endpoint to make a service call. Each request specifies the operation to be performed, the target for this operation (for example, a business object), and the necessary parameters.
- Level 1: Level 1 services introduce the concept of resources. To perform an operation on a resource, a client issues a POST request specifying the operation to perform and including any parameters.
- Level 2: The service at the level uses HTTP verbs to perform operations, such as GET for acquisition, POST for creation, and PUT for update. The request query parameters and body (if any) specify the parameters for the operation. This enables services to leverage web infrastructure services, such as caching GET requests via a CDN.
- Level 3: Level 3 services are designed based on the HATEOAS (Hypertext As The Engine Of Application State) principle. The basic idea is to include links in the resource information returned by the GET request, and these links can perform operations allowed by the resource. For example, the client cancels an order through the link contained in the order resource, or sends a GET request to obtain the order, and so on. The advantages of HATEOAS include not having to write hard-linked URLs in client code. In addition, since the resource information includes links to allowed operations, the client does not have to guess what operation to perform in the current state of the resource
Benefits and Drawbacks of REST:
Benefits:
- It's very simple and familiar
- The HTTP API can be tested using a browser extension (such as the Postman plugin) or a command line such as curl (assuming JSON or other text format is used)
- Direct support for request/response communication
- HTTP is firewall friendly.
- No intermediate agent is required, which simplifies the system architecture.
Disadvantages:
- It only supports request/response communication
- May result in reduced availability. Since the client and service communicate directly without a broker to buffer messages, they must both stay online during the REST API call
- The client must know the location (URL) of the service instance
- Fetching multiple resources in a single request is challenging.
- Sometimes it is difficult to map multiple update operations to HTTP verbs.