Backend Architecture Evolution
monolithic architecture
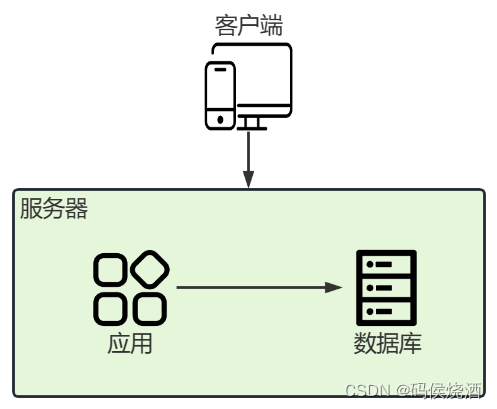
The so-called monolithic architecture means that there is only one server, and all systems, programs, services, and applications are installed on this server. For example, a bbs system, the database it uses, the pictures and files it needs to store, etc., are all deployed on the same server.
The advantage of the monolithic architecture is that it is simple and relatively cheap. Generally, in the early days of the Internet, or entrepreneurial teams, they have experienced monolithic architecture. To cope with the situation of high concurrency through configuration upgrades, such as upgrading the CPU/memory to 64 cores and 128G memory.
Application and database separation - vertical architecture
When server load is too high, split and deploy application server and database server separately.

When the website accumulates more content, the number of users and visits will also increase. When the daily UV exceeds 10,000 and PV exceeds 100,000, the load on the server will become higher and higher under the single architecture.
When the number of visits to the website is increasing, the amount of concurrency that the top-end server can support is also limited. At this time, it is time to upgrade the architecture. The easiest way is to upgrade from a single architecture to a vertical architecture: deploying applications and databases separately.
Database master-slave architecture
The website has a steady stream of visits, the pressure on the database is increasing, and congestion and slow queries often occur. At this time, you can consider increasing the number of servers in the database.

It is more common to use the database master-slave mode, which can be one master and one slave or one master and multiple slaves. One master and one slave is a master library plus a slave library, using two servers.
The main library is responsible for all data write requests, and the slave library can only be used for query, which disperses the query pressure of the main library. Similar to one master and multiple slaves, it is to add multiple slave libraries, so that the query performance can be improved by increasing the server resources of the slave libraries.
Notice:
- After the master-slave mode of the database is adjusted, some modifications to the program are required to realize the separation of reading and writing of data.
- Change the previous single database instance to read and write two database instances, and the configuration information of the database should also increase the master-slave data configuration.
- In the program, most of the read requests are changed to slave database instances.
Existing problems: There will be a delay in the master-slave synchronization of the database: a piece of data is successfully written to the master database, but it is immediately read from the slave database. Because of the synchronization delay, this piece of data has not been synchronized from the master database to the slave database, so the query fails. result.
At this time, it is necessary to monitor the delay of the slave library. Taking MySQL as an example, execute the statement on the slave library show slave status;to check the status of the slave library, Slave_IO_Runningand Slave_SQL_Runningboth need to be Yes. Seconds_Behind_MasterThe degree of delay, the larger the value, the longer the delay. In addition to always paying attention to the delay of the slave library, some strategic adjustments are also required in terms of programs. For example, don't change all queries to read from the library, and give priority to changing data that is not sensitive to time updates to read from the library.
Distributed Application Architecture
The concurrency of the system also increases at the same time, and the load of a single application server is too high. Consider expanding the server capacity from one server to multiple application servers.
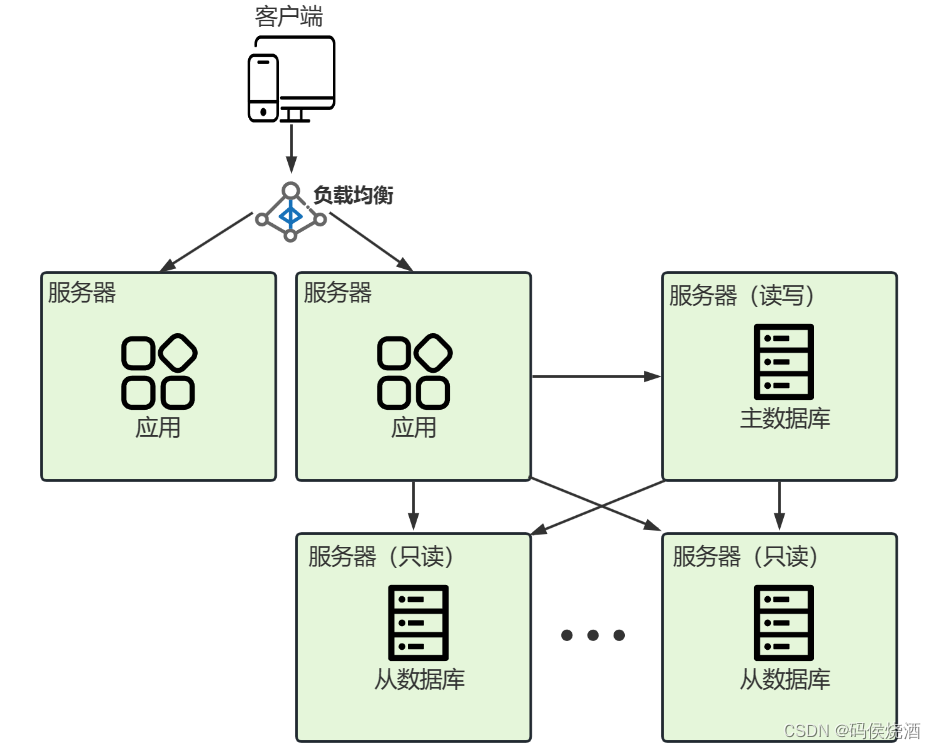
Deploy one application system on each server, and then deploy a load balancing server, such as Nginx, as a unified access layer.
In a distributed system, there is a problem with relying on local files: uploaded pictures and files are only saved on the local file system, and these files do not exist on other servers, so 404 will appear. The simpler method is to mount the same nfs on each application server and configure the same directory. In this way, files are still read and written in a centralized manner, but only read and write through the network, and are no longer local IO. In addition, additional OSS clusters can be built, and CDN optimization can be introduced at the same time.
Under the distributed architecture, the support of normal websites basically reaches 200,000-300,000 PVs.
Distributed cache architecture
The pressure on the database is still high, and there are more and more slow queries, reaching the bottleneck. At this time, the distributed cache service is introduced to liberate the database.
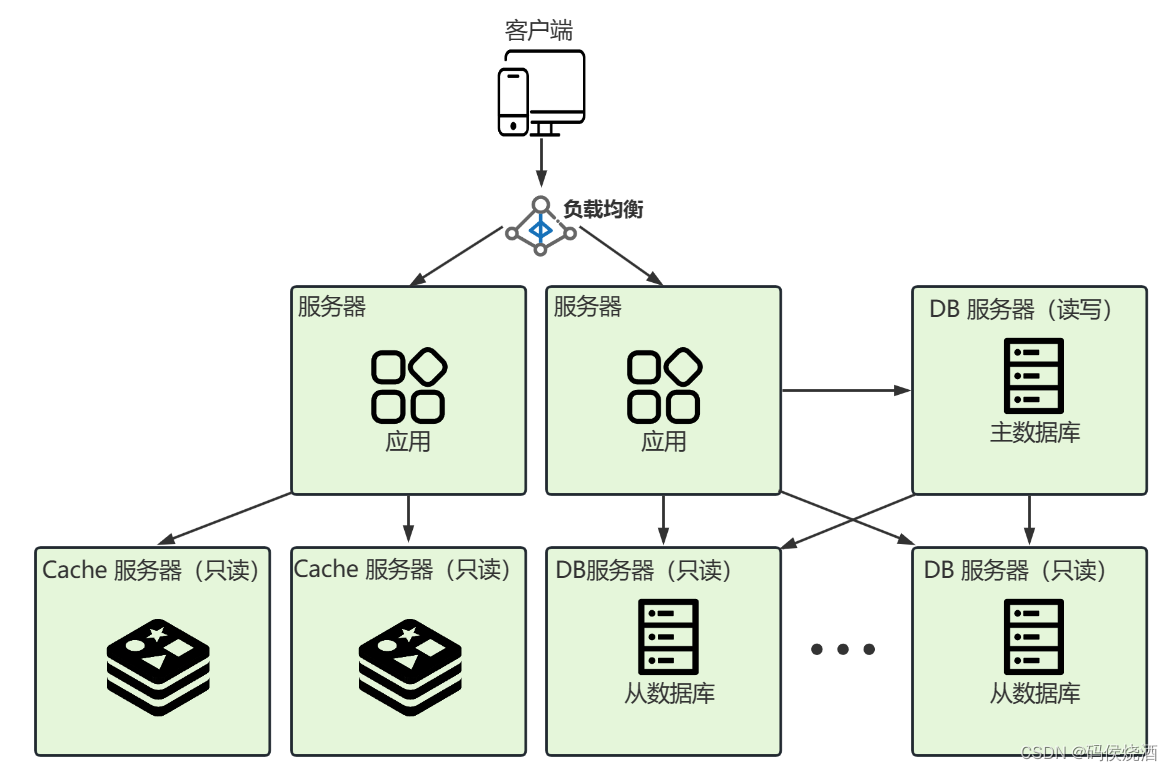
At this stage, the database is facing huge concurrent pressure, and the benefits of horizontal and vertical expansion of the database server are not great. Distributed cache service can be introduced. For example: use Redis cluster.
It is generally believed that a MySQL server can support 1,000 concurrency, and a Redis server can support 100,000 concurrency. Using the cache, you can cache the results of some slow queries that take hundreds of milliseconds. The cache query takes only 1-2ms, and the performance is improved hundreds of times.
There are some new problems, such as: data consistency between the database and the cache (more content, 20,000 words are omitted here). Finally, under this system architecture, it is fully capable of dealing with millions of users and millions of PVs per day.
Database sub-table sub-database
When the data scale is getting bigger and bigger, and the amount of data is growing rapidly, exceeding tens of millions, as long as it involves operations such as database query and batch update, it will become very slow and become the bottleneck of the entire system again. In view of the continuous growth of data scale, it is necessary to upgrade the database architecture again, and consider horizontal splitting and vertical splitting of databases and data tables.
The amount of data in a single table is too large. Consider dividing the data table into tables, such as controlling the data size of a single table to one million.
- Split horizontally. The structure of the sub-tables is exactly the same, but only part of the total data is stored in each sub-table.
- Split vertically. The fields of the subtable are all part of the larger table.
The database sharding method is similar to the table sharding method, and horizontal or vertical splitting is also considered.
microservice architecture
When applications become more and more complex, consider splitting the application into multiple sub-services, and you need to pay attention to the service boundary of the vertical split.
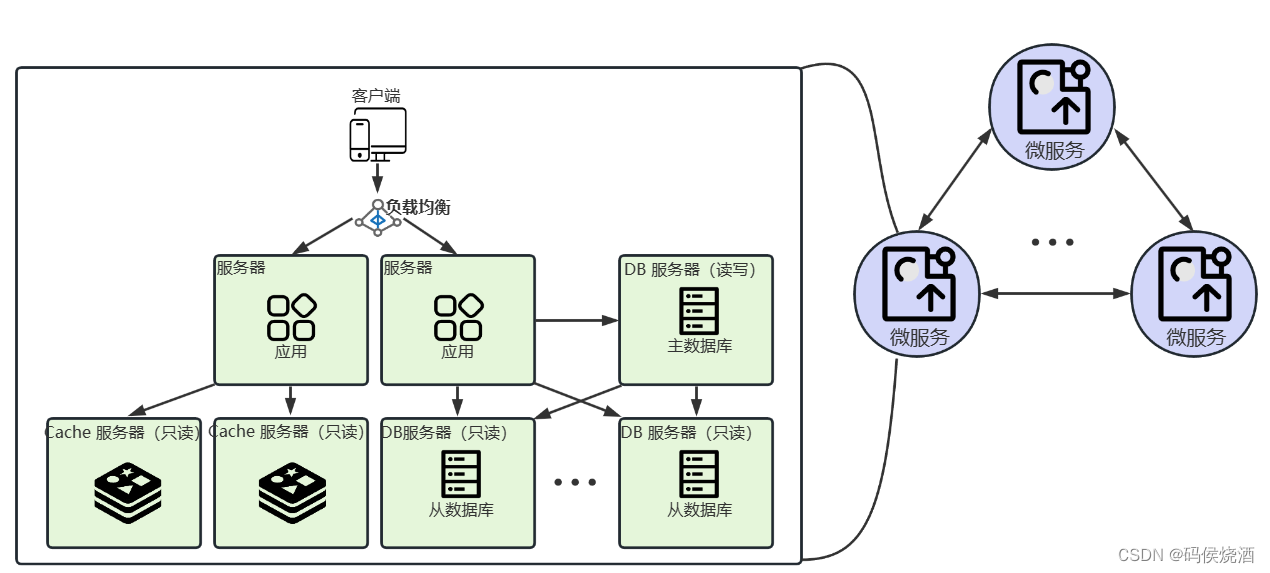
A large application system is vertically split, and the basis for service splitting is that the data of each service is as independent as possible. For example: in the blog system, you can consider splitting the article system, comment system, picture file system, etc.
The early SOA architecture, that is, service-oriented architecture, also split a large system into many independent services. In fact, the microservice architecture is similar to the SOA architecture, and it is a sublimation of SOA. One of the key points of the microservice architecture is "business requires thorough componentization and serviceization". The original single business system will be split into multiple small applications that can be independently developed, designed, and run. Such small applications and other applications cooperate and communicate with each other to complete an interaction and integration.
K8S containerization, cloud native architecture
There are too many microservices and management is too difficult. Through technologies such as K8S, thousands of microservices and server resources with millions of cores can be managed easily. At the same time, the cycle of development, testing and release can be shortened.
Cloud native will further help us improve the efficiency and flexibility of development and operation and maintenance, and improve the availability of systems and products. No longer limited by resources and regions, services can be quickly deployed and run in dozens of regions around the world.
The MySQL cluster, Redis cluster, distributed storage, message queue, Elasticsearch, Prometheus, distributed log system, real-time computing service, etc. used in the system.
To manage and maintain so many large-scale distributed systems, it is necessary to optimize and improve the performance of the service and ensure the high reliability and availability of the system. The human resources and server resources that need to be invested here will be very huge. If the management and control of cloud-native resources is not good, and the cost control is not good, you can choose the hybrid cloud method.
microservice technology
- The microservice architecture is a distributed system, a decentralized system.
- Service deployment may span hosts, network segments, computer rooms, and even regions, and calls are made between services through http interfaces or RPC.
service discovery
Service discovery is the soul of the microservice architecture, which is to register service information to a configuration center, and from the configuration center, you can find more information about the service. The configuration center here, also called the registration center, manages all service information. The registration center is a central service that cannot be bypassed by all microservices to create, start, run, destroy, and call each other.
- A registration center that manages all service information;
- Functions: registration, query, health check;
- The amount of data is large, including multiple services and multiple instances.
Functions of the Registry
服务注册. When the service is started, information such as the service name and the access method of the service are registered in the registration center.- Service name is a keyword.
- The access method of the service needs to have the calling protocol, whether it is http or gRPC, etc. At the same time, there will be an access address, which may be a domain name, or a collection of IP:port.
服务查询. Find the access method to call the service through the service name.健康检查. Let the registration center know the running status of the service at any time. When an instance of the service is abnormal, an alarm is issued, the service is automatically restarted, etc.
The registry itself is a distributed storage system. As a configuration center, in addition to storing service information, there may be custom configuration information for each microservice. For the registry, the biggest challenge is system reliability and data consistency. Therefore, all registries are deployed on multiple servers. Moreover, a complete configuration information will be saved on each machine. Moreover, data synchronization between multiple servers requires the implementation of some complex consistency protocols in order to ensure strong data consistency.
Service discovery process:
- The service provider registers service information with the registration center.
- Before a service consumer initiates a request to a service provider, it obtains service information from the registration center. Here, because the timing of obtaining service information is different, there are two modes of service discovery:
- In the client discovery mode, service information is obtained on the side of the service consumer. After getting the service information, implement the load balancing strategy by yourself and directly request to the service provider.
- The server-side discovery mode introduces a server-side gateway, and service consumers only need to request the server-side gateway. Then at the server gateway, uniformly obtain service information, and then implement a load balancing strategy. The final request goes to the service provider.
Some implementations of service discovery: Apache Zookeeper, Etcd, Consul.
Frequency limit, current limit, downgrade and fuse of service calls
In order to deal with online emergencies, such as a bug in a certain target service, the performance and concurrency capabilities drop sharply, and various measures need to be taken to ensure the availability of the system.
time out
The caller actively terminated the requested connection. When calling the API, the TCP timeout period is generally configured according to the estimated interface delay of the target service. If the API returns within 100ms in most cases, then the TCP request timeout can be set to 500ms or 1s. If the timeout is not set, then when the target service is abnormal and cannot respond quickly normally, all requests from the source service and the target service will wait indefinitely, and the number of TCP connections will increase, which will affect the resource overhead of the system It is also getting
bigger and bigger.
Limiting
Limit the maximum number of concurrent requests. If the target service can support a maximum of 100QPS, then the source service cannot allow more than this concurrent request to enter.
Commonly used algorithms:
- Counter fixed window algorithm. The only counter in the world, the request incoming counter is +1, and the request end counter is -1. When the number of counters exceeds the maximum limit, the counter will no longer be +1, and all requests exceeding the limit will be rejected. Incrementing and decrementing the counter is performed by atomic operations. The disadvantage is that it cannot handle a large number of requests influx at the same time.
- Counter sliding window algorithm. Assume that the unit time is 1 second and the current limiting threshold is 3. Within 1 second of the unit time, every time a request comes, the counter is incremented by 1. If the accumulated number of counters exceeds the current limit threshold 3, all subsequent requests are rejected. After 1s is over, the counter is cleared to 0 and starts counting again. shortcoming:
- A system service is unavailable for a period of time (not exceeding the time window). For example, the window size is 1s, the current limit size is 100, and then 100 requests come in exactly at the 1st ms of a certain window, and then the requests at the 2ms-999ms will be rejected. During this time, the user will feel that the system service is unavailable.
- A window switch may generate twice the threshold traffic request. Assuming that the current limit threshold is 5 requests, and the unit time window is 1s, if we send 5 requests concurrently in the first 0.8-1s and 1-1.2s of the unit time. Although none of them exceeded the threshold, if the count is 0.8-1.2s, the number of concurrency is as high as 10, which has exceeded the definition of the threshold of not exceeding 5 per unit time 1s, and the number of passed requests has reached twice the threshold.
- Sliding window current limiting. Sliding window current limiting solves the problem of fixed window critical value, which can ensure that the threshold will not be exceeded in any time window. In addition to the need to introduce counters, the sliding window also needs to record the arrival time of each request in the time window, so the memory usage will be more.
- Leaky Bucket Algorithm. Similar to the message queue idea, water flows into the leaky bucket at an arbitrary rate, and water flows out at a fixed rate. When the water exceeds the capacity of the bucket, it will be overflowed, that is, discarded. To achieve peak shaving and valley filling, and smooth requests.
- Token Bucket Algorithm.
- The token administrator puts tokens into the token bucket at a fixed speed according to the size of the current limit.
- If the number of tokens is full and exceeds the limit of the token bucket capacity, it will be discarded.
- When the system receives a user request, it will first go to the token bucket to ask for a token. If the token is obtained, then the business logic of the request is processed; if the token is not obtained, the request is rejected directly.
fuse
Temporarily return the request to call the target service quickly, and it is not allowed to call the target service repeatedly. Because when the target service has a large number of abnormal situations within a certain period of time, if you continue to request the target service at this time, there is a high probability that the abnormal result will still be returned.
Fusing is just temporarily stopping the call, and after a while, some requests will come in to see if the back-end service is back to normal. For example, if the timeout request, 500, 503 and other responses of the service exceed 100 times within one minute, a downgrade or circuit breaker will be triggered. After 3 minutes of downgrade or fuse, try to make 10 consecutive requests to the backend service, and if all return normally, resume. If none of them return normally, continue to maintain the degraded or blown state, and try to recover after the next 3 minutes.
downgrade
A scene similar to fusing. There are a lot of exceptions in the target service. At this time, the response should not be as simple and rude as a fuse, but a more friendly response. The main purpose is to make the service look normal and return normally when the service is abnormal.
Common methods of downgrading:
- To read old data, if there is backup data and cache data, it can be used at this time.
- If the service implements multiple solutions, it can switch to other solutions to execute when solution 1 is abnormal.
- Default value, return to default value when setting downgrade.
- Abandoning some requests can reduce the concurrency of backend services.
- Reduce the quality, directly skip the time-consuming and computationally intensive logic, and do not require real-time calculation of all results.
- Reverse filtering, if it is too laborious to filter a result set, you can consider not filtering and return all the content directly.
- Compensation, record the log when the service is abnormal, and then perform compensatory operations afterwards.
isolation
Isolate different dependent calls by type isolation/user isolation, etc., to avoid mutual influence between services. For example, the source service A/B directly calls the target service C. The source service A has a burst of high concurrency to request the target service C. If the destination service C is congested, then the request of the source service B will also be affected at this time.
Service Governance
Service governance includes the following aspects:
- Service Design: Ensure that services are designed to meet business needs and follow best practices and standards.
- Service development: ensure the quality and reliability of service development, and follow coding standards and specifications.
- Service testing: Make sure the service works properly in various scenarios, including functional testing, performance testing, and security testing.
- Service Deployment: Ensure that the service can be successfully deployed into the target environment and can be integrated with other services.
- Service monitoring: monitor the running status of the service, discover and solve problems in time, and ensure the stability and reliability of the service.
- Service upgrades: when necessary, upgrade and update services to meet business needs and technical requirements.
- Service management: manage the entire life cycle of services, including version control, document management, security management, etc.
- Service governance is very important to the service-oriented architecture in the modern enterprise architecture. It can help enterprises realize service reuse, improve service quality, reduce service development costs, and improve service reliability and security.
load balancing
To put it simply, the role of load balancing is to distribute all requests to each service instance reasonably, so as to avoid the situation that a service instance is always under high load.
Common Load Balancing Algorithms
- Round Robin & Weighted Round Robin
- Polling method: Now there are three service instances, then the first request will call instance 1, the second request will call instance 2, the third request will call instance 3, the fourth request will call instance 1, and the fifth request will call In calling instance 2, the cycle continues. The first is to design an incrementing counter, which will be incremented for each request, and then use this counter to perform a modulo operation on the number of instances 3, and the remainder is the instance to be called.
- Weighted polling method: The weight of instance 1 is 3, so it can be assigned 1, 2, and 3 as the remainder of calling it. The weight of instance 2 is 2, so the two numbers 4 and 5 can be assigned as the remainder of calling it. The weight of instance 1 is 1, so the 1 number 6 can be assigned as the remainder of calling it. When the request comes in, the counter still increments in the same way, but instead of taking the modulus of the number of instances 3, it takes the modulo of the sum of weights 3+2+1=6, and the remainder will know which instance to call.
- Random method & weighted random method: replace the counter with a random number. When each request comes in, instead of incrementing the counter, it assigns a random number to the request, and then uses this random number to perform a modulo operation, and the remainder can determine the instance to be called.
- Random method: modulo the number of instances.
- Weighted random method: Modulo the sum of weights.
- Minimum Connection Algorithm: The service instance with the least number of connections is called first.
- Source address hashing method: A numerical value calculated by a hash function is used to perform a modulo operation on the size of the server list, and the result obtained is the serial number of the server to be accessed by the customer service end. When you want all requests of a user to be called to the same instance, you can choose IP or user ID for hash calculation.
In addition, there are load balancing strategies that apply consistent hash algorithms , etc.
The implementation scheme of load balancing is generally in the client, DNS, gateway, and also in various middleware components, such as database proxy, cache proxy, etc.