1. System introduction
The browsing record system is mainly used to record the real-time browsing records of Jingdong users, and provide the function of real-time query browsing data. When an online user visits the product details page once, the browsing record system will record a piece of browsing data of the user, and perform a series of processing and storage such as deduplication of product dimensions for the browsing data. Then the user can query the user's real-time browsing product records through My Jingdong or other portals, and the real-time performance can reach the millisecond level. At present, this system can provide each user of JD.com with query and display of the latest 200 browsing records.
2. System design and implementation
2.1 Overall system architecture design
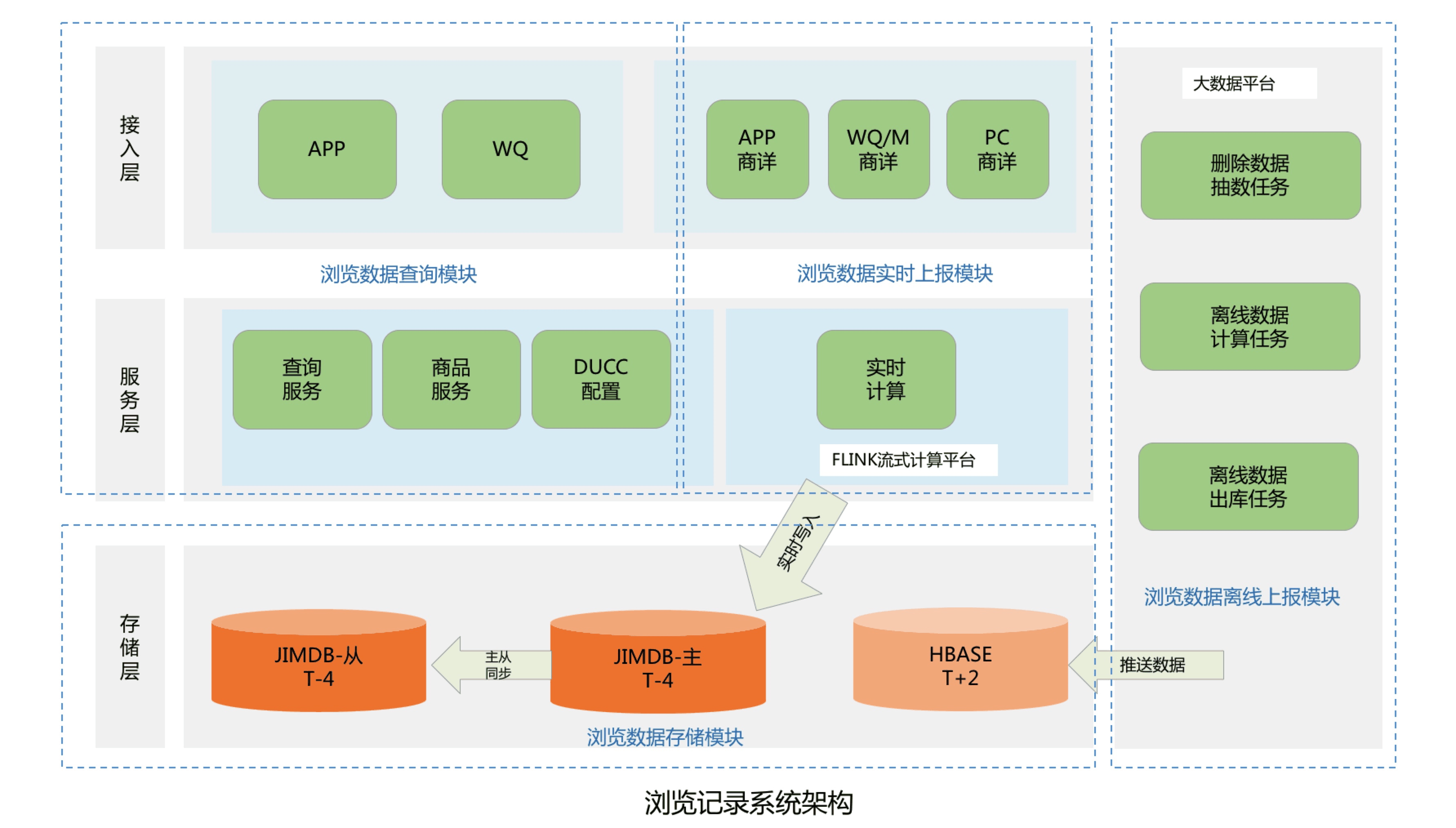
The entire system architecture is mainly divided into four modules, including browsing data storage module, browsing data query module, browsing data real-time reporting module and browsing data offline reporting module:
- Browsing data storage module: mainly used to store the browsing history of JD users. Currently JD.com has nearly 500 million active users. According to each user retaining at least 200 browsing history records, it is necessary to design and store nearly 100 billion user browsing history data;
- Browsing data query module: mainly provides a microservice interface for the front desk, including functions such as querying the total number of browsing records of users, real-time browsing record lists and deletion operations of browsing records;
- Browsing data real-time reporting module: mainly processes real-time PV data of all online users of JD.com, and stores the browsing data in a real-time database;
- Browsing data offline reporting module: It is mainly used to process the PV offline data of all JD users, clean, deduplicate and filter the user's historical PV data, and finally push the browsing data to the offline database.
2.1.1 Design and implementation of data storage module
Considering the need to store nearly 100 billion user browsing records, and to meet the real-time storage of millisecond-level browsing records and front-end query functions of JD Online users, we separated the hot and cold browsing history data. Jimdb operates purely in memory and has a fast access speed, so we store the user's (T-4) browsing record data in Jimdb's memory, which can meet the real-time storage and query of JD Online's active users. The offline browsing data other than (T+4) is directly pushed to Hbase and stored on the disk to save storage costs. If an inactive user queries cold data, the cold data will be copied to Jimdb to improve the next query performance.
The hot data uses the ordered set of JIMDB to store the user's real-time browsing records. The user name is used as the KEY of the ordered set, the SKU of the browsed product is used as the element of the ordered set, and the time stamp of the browsed product is used as the score of the element, and the expiration time is set to 4 days for the KEY.
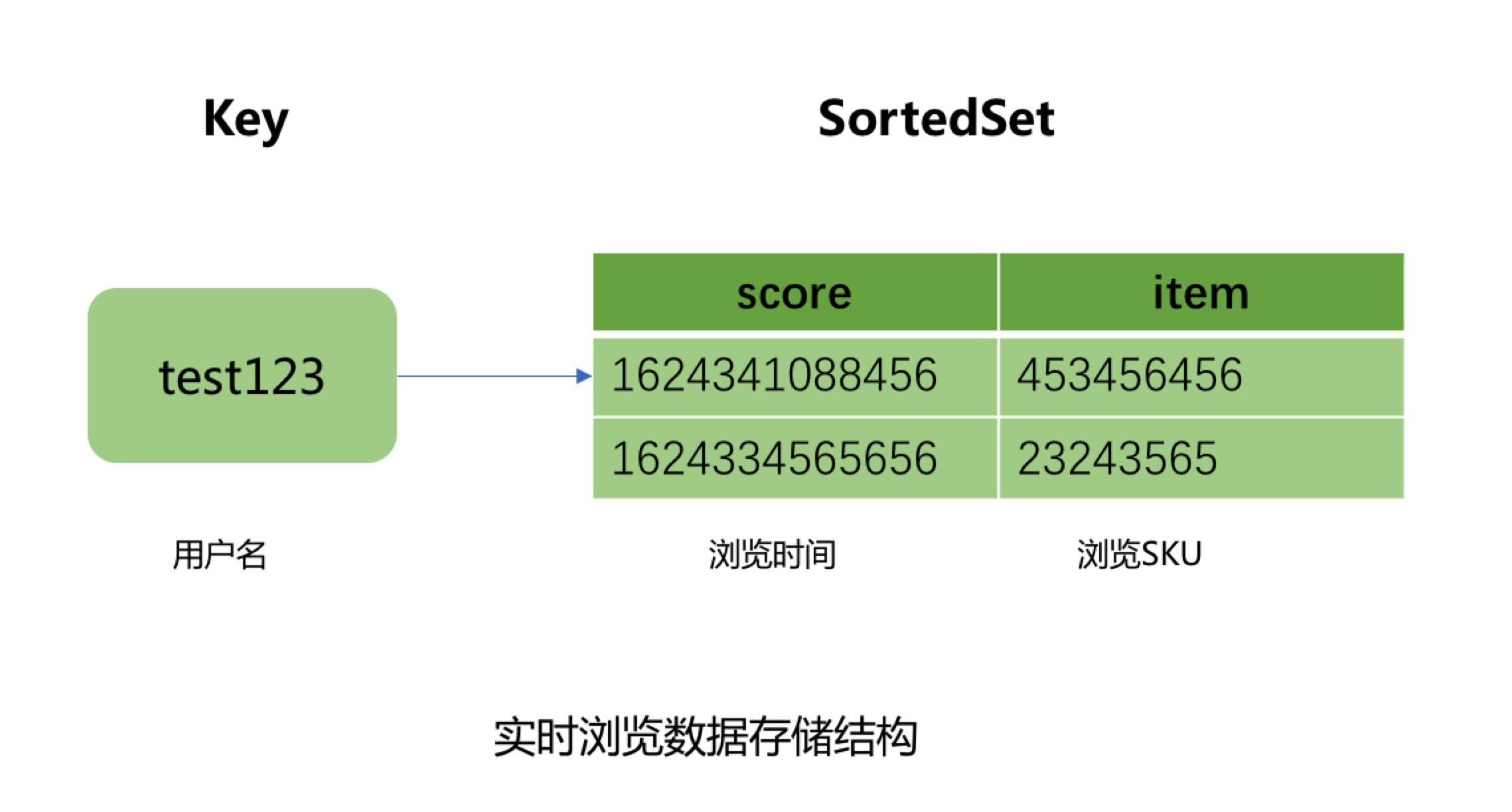
Why choose 4 days for the hot data expiration time here?
This is because the offline browsing data of our big data platform is reported and summarized in T+1. It is already the next day when we start processing users’ offline browsing data. In addition to our own business process processing and data cleaning and filtering process, it also takes more than ten hours to execute and push it to Hbase. Therefore, the expiration time of hot data needs to be set at least 2 days, but considering the process of large data task execution failure and retry, it is necessary to reserve 2 days for task retry and data repair time, so the hot data expiration time is set to 4 days. Therefore, when the user has not browsed new products within 4 days, the browsing records viewed by the user are directly queried and displayed from Hbase.
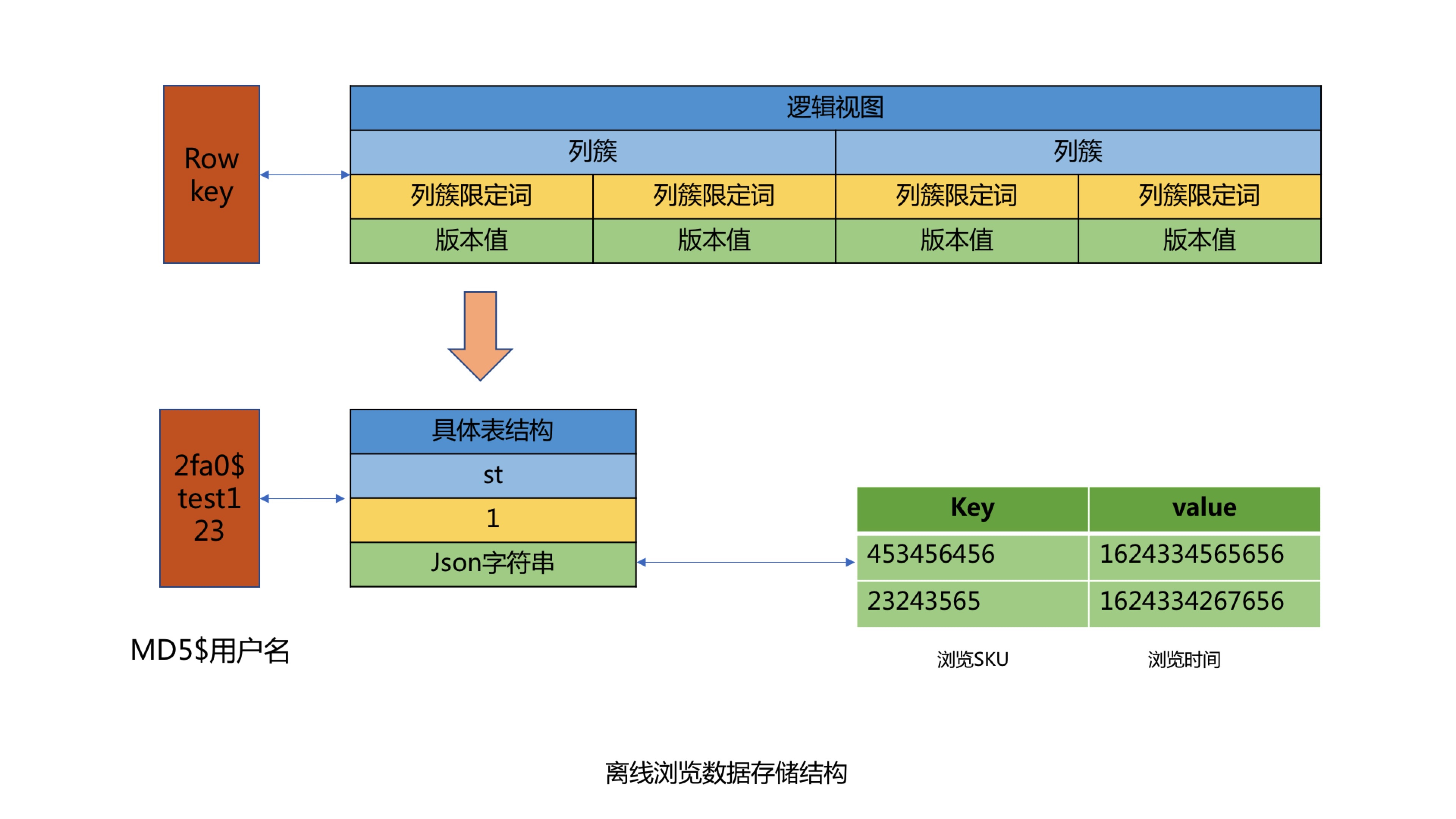
Cold data uses the KV format to store user browsing data, using the user name as the KEY, and the Json string corresponding to the user's browsing product and browsing time as the Value for storage. When storing, the user's browsing order must be guaranteed to avoid secondary sorting. When using the user name as the KEY, since most user names have the same prefix, there will be a problem of data skew, so we perform MD5 processing on the user name, and then intercept the middle four digits after the MD5 as the prefix of the KEY, thus solving the data skew problem of Hbase. Finally, set the expiration time for KEY to 62 days to realize the automatic cleaning function of offline data expiration.
2.1.2 Design and implementation of query service module
The query service module mainly includes three microservice interfaces, including the interface of querying the total number of user browsing records, querying the list of user browsing records and deleting user browsing records.
- Problems faced in the interface design of querying the total number of user browsing records
1. How to solve the problem of current limiting and anti brushing?
Based on Guava's RateLimiter current limiter and Caffeine local cache, the three dimensions of method global, caller and user name are implemented. The specific strategy is that when calling the method for the first time, a current limiter of the corresponding dimension will be generated, and the current limiter will be saved in the local cache implemented by Caffeine, and then a fixed expiration time will be set. When the method is called next time, the corresponding current limiter key will be generated and the corresponding current limiter will be obtained from the local cache.
2. How to query the total number of user browsing records?
First query the cache of the total number of user browsing records. If the cache is hit, the result will be returned directly. If the cache is not hit, you need to query the user’s real-time browsing record list from Jimdb, and then add product information in batches. Since the user’s browsing SKU list may be large, here you can query product information in batches. The batch number can be dynamically adjusted to prevent the query performance from being affected by too many products in one query. Since the browsing product list displayed on the front desk needs to be deduplicated for the same SPU product, the product information fields that need to be supplemented include product name, product image, and product SPUID. After deduplication of the SPUID field, determine whether to query Hbase offline browsing data. Here, you can judge whether you need to query Hbase offline browsing records through the offline query switch, user clear flag, and the number of browsing records after SPUID deduplication. If the number of browsing records has reached the maximum number of browsing records set by the system after deduplication, offline records will not be queried. If it is not satisfied, continue to query the offline browsing record list, merge it with the user's real-time browsing record list, and filter out duplicate browsing SKU products. After obtaining the user's complete browsing record list, filter out the deleted browsing records of the user, then count the length of the list, and compare it with the maximum number of user browsing records set by the system to get the minimum value, which is the total number of user's browsing records.
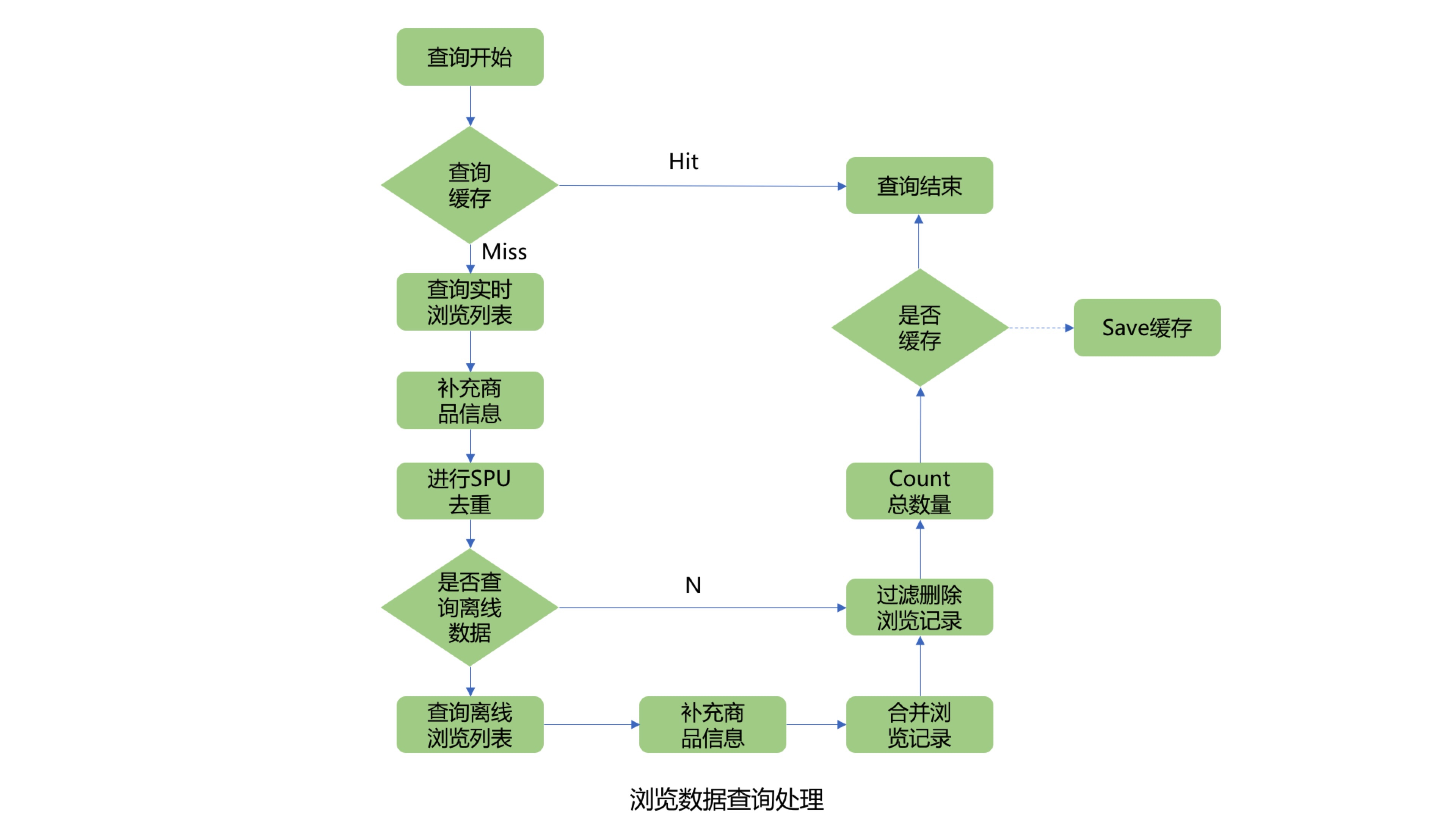
3. Query the list of user browsing records
The process of querying the list of user browsing records is basically the same as the process of querying the total number of user browsing records.
2.1.2 Design and implementation of browsing data real-time reporting module
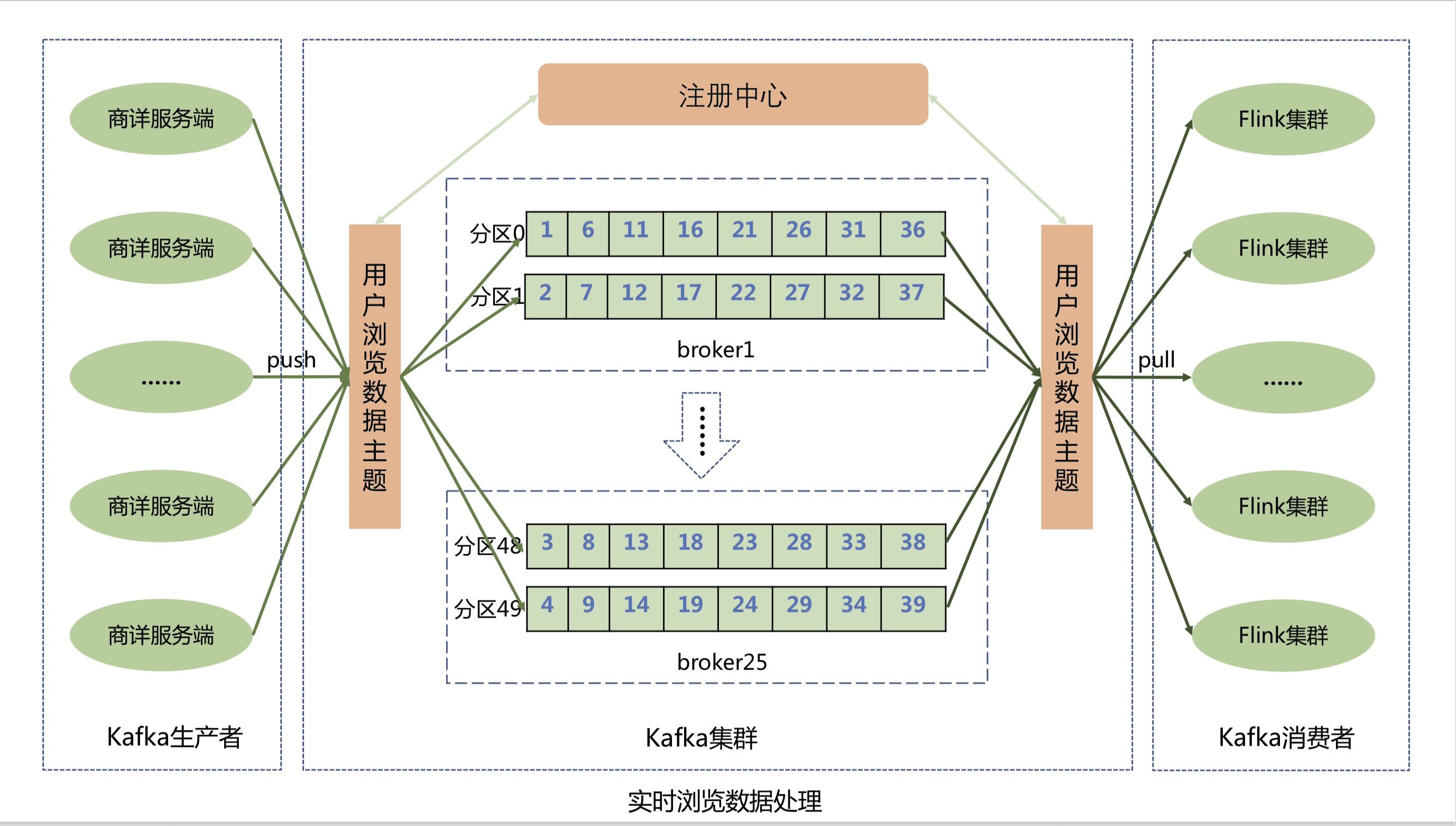
The Shangxiang server reports the user's real-time browsing data to the message queue of the Kafka cluster through the Kafka client. In order to improve the data reporting performance, the user's browsing data topic is divided into 50 partitions. Kafka can evenly distribute the user's browsing messages to the 50 partition queues, thereby greatly improving the throughput of the system.
The browsing record system consumes user browsing data in the Kafka queue through the Flink cluster, and then stores the browsing data in Jimdb memory in real time. The Flink cluster not only realizes horizontal dynamic expansion, further improves the throughput of the Flink cluster, prevents a backlog of messages, but also ensures that the user's browsing messages are consumed exactly once, and user data will not be lost and can be automatically restored when an exception occurs. Flink cluster storage implementation uses Lua scripts to merge and execute multiple Jimdb commands, including inserting sku, judging the number of sku records, deleting sku and setting expiration time, etc., optimizing multiple network IO operations into one.
Why choose Flink stream processing engine and Kafka instead of directly writing browsing data into Jimdb memory on the Shangxiang server?
First of all, JD.com is a 24/7 e-commerce website with more than 500 million active users. Every second, there will be users browsing the product details page, which is like flowing water, which is very suitable for the distributed streaming data processing scenario.
Compared with other stream processing frameworks, Flink's distributed snapshot-based solution has many advantages in terms of function and performance, including:
- Low latency: Since the storage of the operator state can be asynchronous, the process of taking a snapshot will basically not block the processing of the message, so it will not negatively affect the message delay.
- High throughput: When the operator state is small, there is basically no impact on throughput. When there are many operator states, compared with other fault-tolerant mechanisms, the time interval of distributed snapshots is user-defined, so users can adjust the time interval of distributed snapshots by weighing the error recovery time and throughput requirements.
- Isolation from business logic: Flink's distributed snapshot mechanism is completely isolated from the user's business logic, and the user's business logic will not depend on or have any impact on the distributed snapshot.
- Error recovery cost: The shorter the time interval of distributed snapshots, the less time for error recovery, which is negatively correlated with throughput.
Second, JD.com has a lot of seckill activities every day, such as Moutai’s rush to buy, with millions of reservation users, and millions of users refresh the business details page in the same second, which will generate a traffic flood. If all are written in real time, it will put a lot of pressure on our real-time storage and affect the performance of the front-end query interface. Therefore, we use Kafka to perform peak shaving processing, and also decouple the system, so that the Shangxiang system does not have to rely on the browsing record system.
Why choose Kafka here?
Here you need to understand the characteristics of Kakfa first.
- High throughput and low latency: The biggest feature of kakfa is that it sends and receives messages very quickly. Kafka can process hundreds of thousands of messages per second, and its minimum delay is only a few milliseconds.
- High scalability: Each topic (topic) contains multiple partitions (partitions), and the partitions in the topic can be distributed among different hosts (brokers).
- Persistence and reliability: Kafka can allow persistent storage of data, messages are persisted to disk, and supports data backup to prevent data loss. The underlying data storage of Kafka is based on Zookeeper storage, and Zookeeper we know that its data can be stored persistently.
- Fault tolerance: Allow nodes in the cluster to fail, a node goes down, and the Kafka cluster can work normally.
- High concurrency: Support thousands of clients to read and write at the same time.
Why is Kafka so fast?
-
Kafka uses the zero-copy principle to move data quickly, avoiding switching between cores.
-
Kafka can send data records in batches, from producers to file systems to consumers, and view these batches of data end-to-end.
-
While batching, data compression is performed more efficiently and I/O latency is reduced.
-
Kafka writes to disk sequentially, avoiding the waste of random disk addressing.
At present, the system has experienced many major promotion tests, and the system has not been downgraded. There is no backlog of users' real-time browsing messages, and the processing capacity of millisecond level has been basically realized. The method performance of TP999 has reached 11ms.
2.1.3 Design and implementation of browsing data offline reporting module
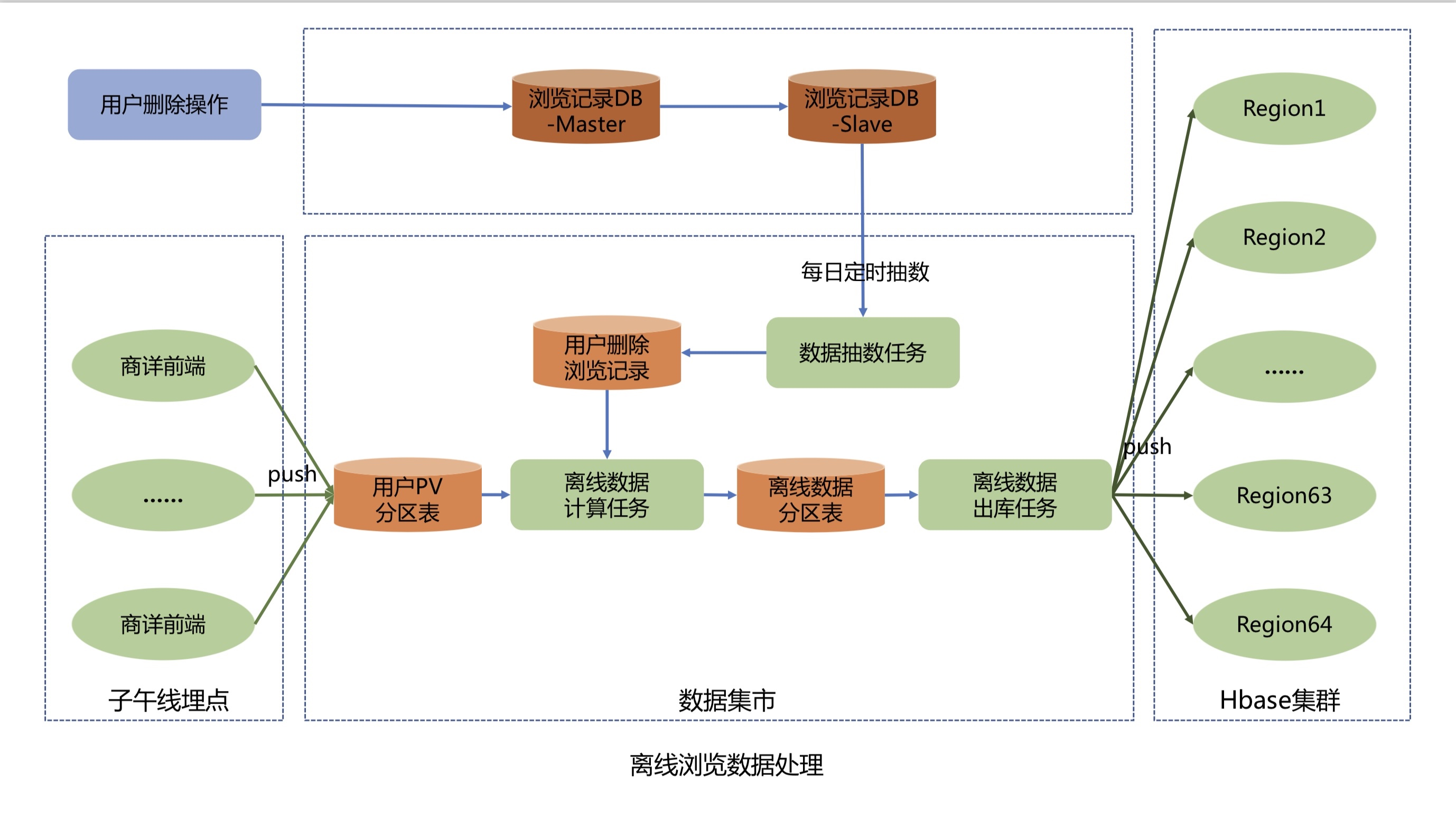
The offline data reporting process is as follows:
-
The business details front-end reports the user's PV data through Meridian's API, and Meridian writes the user's PV data into the user's PV partition table in the data mart.
-
The data sampling task draws data from the user-deleted browsing record table of the browsing record system Mysql library to the data mart at 2:33 a.m. every day, and writes the deleted data to the user-deleted browsing record table.
-
The offline data calculation task starts at 11:00 a.m. every day. It first extracts nearly 60 days and 200 pieces of deduplicated data per person from the user PV partition table, then filters and deletes the data according to the user’s deletion and browsing record table, and calculates the user names that have been added or deleted that day, and finally stores them in the offline data partition table.
-
The offline data outbound task cleans and converts T+2 incremental offline browsing data from the offline data partition table at 2:00 a.m. every day, and pushes the KV format offline browsing data of T+2 active users to the Hbase cluster.
RustDesk 1.2: Using Flutter to rewrite the desktop version, supporting Wayland accused of deepin V23 successfully adapting to WSL 8 programming languages with the most demand in 2023: PHP is strong, C/C++ demand slows down React is experiencing the moment of Angular.js? CentOS project claims to be "open to everyone" MySQL 8.1 and MySQL 8.0.34 are officially released Rust 1.71.0 stable version is releasedAuthor: Jingdong Retail Cao Zhifei
Source: JD Cloud Developer Community