File upload is a common topic. When the file is relatively small, you can directly convert the file into a byte stream and upload it to the server. However, if the file is relatively large, upload it in an ordinary way. A good way, after all, very few people will endure, when the uploading of the file is interrupted in the middle, it is an uncomfortable experience to continue uploading but only to start uploading from the beginning. Is there a better upload experience? The answer is yes, that is, several upload methods to be introduced below.
1. Multipart upload
1.1 What is multipart upload
Fragment upload is to divide the file to be uploaded into multiple data blocks (we call it Part) according to a certain size and upload them separately. After uploading, the server will process all the uploaded files. Summarize and integrate into original files.
1.2 Scenarios of multipart upload
-
large file upload
-
The network environment is not good, and there are scenarios where retransmission risks are required
2. Breakpoint resume
2.1 What is resume from breakpoint
Breakpoint resuming is to divide the download or upload task (a file or a compressed package) into several parts artificially when downloading or uploading. Each part uses a thread to upload or download. If there is a network failure, you can Continue uploading or downloading unfinished parts from the part that has already been uploaded or downloaded, and there is no need to start uploading or downloading from the beginning.
The breakpoint resume upload in this article is mainly for the breakpoint upload scenario.
2.2 Application scenarios
Resumable upload can be regarded as a derivative of multipart upload, so resume upload can be used in all scenarios where multipart upload can be used.
2.3 Realize the core logic of breakpoint resume
During the multipart upload process, if the upload is interrupted due to abnormal factors such as system crashes or network interruptions, the client needs to record the progress of the upload. When uploading again is supported later, you can resume uploading from where the previous upload was interrupted.
In order to avoid the problem that the progress data of the client after uploading is deleted and the uploading is restarted from the beginning, the server can also provide a corresponding interface to facilitate the client to query the uploaded fragment data, so that the client knows the uploaded data. Fragment data, so as to continue uploading from the next fragment data.
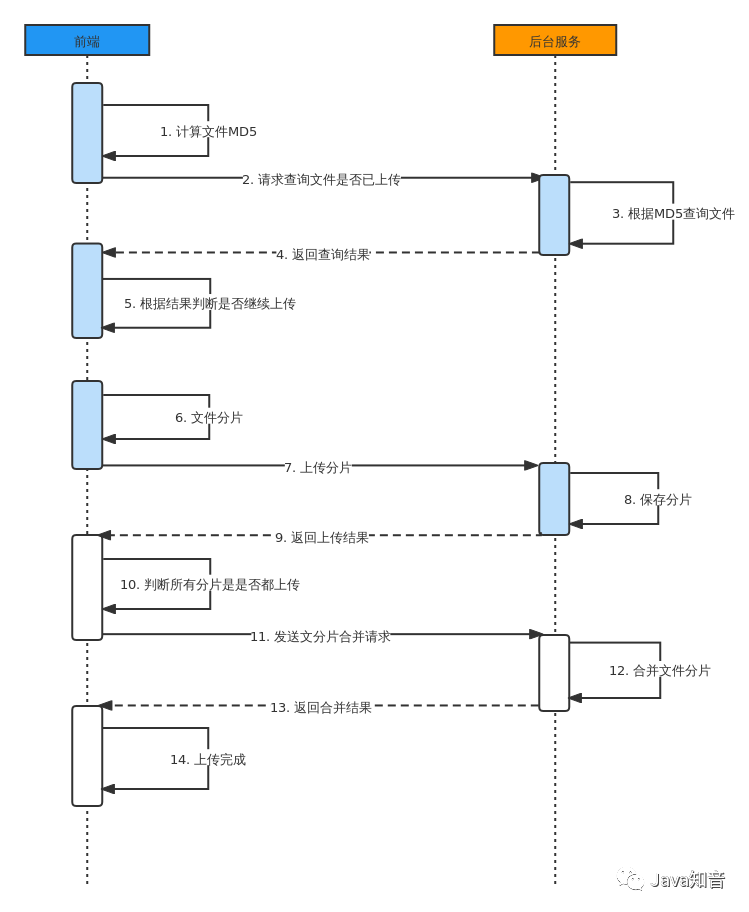
The overall process is as follows:
-
The front end calculates the percentage of file installation, uploads one percent of the file each time (file fragmentation), and assigns a serial number to the file fragmentation
-
The backend puts the files uploaded by the frontend each time into the cache directory
-
Wait for the front end to upload all the file content, and then send a merge request
-
The backend uses
RandomAccessFilemultithreading to read all fragmented files, one thread for one fragment -
Each thread in the backend writes the fragmented files into the target file according to the serial number
-
In the process of uploading files, the network is disconnected or manually suspended. When uploading next time, a resume request is sent to let the backend delete the last fragment.
-
The front end resends the last file fragment
2.4 Implementation Process Steps
Option 1, routine steps
-
Divide the file to be uploaded into data blocks of the same size according to certain segmentation rules;
-
Initialize a multipart upload task and return the unique identifier of this multipart upload;
-
Send each fragmented data block according to a certain strategy (serial or parallel);
-
After the sending is completed, the server judges whether the uploaded data is complete. If it is complete, the data block is synthesized to obtain the original file.
Scheme 2, the steps implemented in this paper
-
The front-end (client) needs to fragment the file according to the fixed size, and the serial number and size of the fragment should be brought when requesting the back-end (server).
-
The server creates a conf file to record the location of the blocks. The length of the conf file is the total number of blocks. Every time a block is uploaded, a 127 is written to the conf file. The position that has not been uploaded is 0 by default, and the position that has been uploaded is 0.
Byte.MAX_VALUE 127(This step is the core step to realize breakpoint resume and second transmission) -
The server calculates the start position according to the segment number given in the request data and the size of each segment (the segment size is fixed and the same), and writes the read file segment data into the file.
The overall implementation process is as follows:
3. Fragment upload/breakpoint upload code implementation
3.1 Front-end implementation
The front-end File object is a special type of Blob and can be used in the context of any Blob type.
That is to say, methods that can handle Blob objects can also handle File objects. In the Blob method, there is a Slice method that can help complete the slice.
Core code:
fileMD5 (files) {
// 计算文件md5
return new Promise((resolve,reject) => {
const fileReader = new FileReader();
const piece = Math.ceil(files.size / this.pieceSize);
const nextPiece = () => {
let start = currentPieces * this.pieceSize;
let end = start * this.pieceSize >= files.size ? files.size : start + this.pieceSize;
fileReader.readAsArrayBuffer(files.slice(start,end));
};
let currentPieces = 0;
fileReader.onload = (event) => {
let e = window.event || event;
this.spark.append(e.target.result);
currentPieces++
if (currentPieces < piece) {
nextPiece()
} else {
resolve({fileName: files.name, fileMd5: this.spark.end()})
}
}
// fileReader.onerror = (err => { reject(err) })
nextPiece()
})
}
Of course, if we are a Vue project, there are better choices. We can use some open source frameworks. This article recommends using vue-simple-uploader file fragment upload, breakpoint resume and second transfer.
Of course, we can also use webuploaderthe plug-ins provided by Baidu for fragmentation.
The operation method is also very simple, just follow the operation given in the official document.
Official webuploader documentation:
-
http://fex.baidu.com/webuploader/getting-started.html
3.2 Backend writes files
The backend implements file writing in two ways:
-
RandomAccessFile
-
MappedByteBuffer
Before learning down, let's briefly understand the use of these two classes
RandomAccessFile
In addition to the File class, Java also provides classes that specifically deal with files, namely RandomAccessFile(random access files) classes.
This class is the most feature-rich file access class in the Java language, and it provides numerous file access methods. RandomAccessFileThe class supports "random access" mode, where "random" means that you can jump to any position of the file to read and write data. When accessing a file, you don't have to read the file from beginning to end, but want to access a certain part of a file "as you want" like accessing a database. At this time, using classes is the best choice RandomAccessFile.
RandomAccessFileThe object class has a position indicator, pointing to the position of the current reading and writing. After the current reading and writing of n bytes, the file indicator will point to the next byte after the n bytes.
When the file is just opened, the file pointer points to the beginning of the file, and the file pointer can be moved to a new position, and subsequent read and write operations will start from the new position.
RandomAccessFileThe class has a great advantage in random (relative to sequential) reading of long-record format files such as data, but this class is limited to operating files and cannot access other I/O devices, such as networks and memory images.
RandomAccessFileThe constructor of the class is as follows:
//创建随机存储文件流,文件属性由参数File对象指定
RandomAccessFile(File file , String mode)
//创建随机存储文件流,文件名由参数name指定
RandomAccessFile(String name , String mode)
These two construction methods both involve a parameter mode of String type, which determines the operation mode of the random storage file stream. The value of mode and its corresponding meaning are as follows:
-
"r": Open in read-only mode, calling any write (write) method of this object will result in IOException exception
-
"rw": Open for reading and writing, supporting reading or writing of files. If the file does not exist, it is created.
-
"rws": Open for reading and writing. Unlike "rw", every update of the file content must be updated to the potential storage device synchronously. The "s" here means synchronous (synchronous)
-
"rwd": Open for reading and writing. Unlike "rw", each update of the file content must be updated to the potential storage device synchronously. Using "rwd" mode only requires updating the content of the file to the storage device, while using "rws" mode not only updates the content of the file, but also updates the metadata of the file, so at least one low-level I/O is required Operation
import java.io.RandomAccessFile;
import java.nio.charset.StandardCharsets;
public class RandomFileTest {
private static final String filePath = "C:\\Users\\NineSun\\Desktop\\employee.txt";
public static void main(String[] args) throws Exception {
Employee e1 = new Employee("zhangsan", 23);
Employee e2 = new Employee("lisi", 24);
Employee e3 = new Employee("wangwu", 25);
RandomAccessFile ra = new RandomAccessFile(filePath, "rw");
ra.write(e1.name.getBytes(StandardCharsets.UTF_8));//防止写入文件乱码
ra.writeInt(e1.age);
ra.write(e2.name.getBytes());
ra.writeInt(e2.age);
ra.write(e3.name.getBytes());
ra.writeInt(e3.age);
ra.close();
RandomAccessFile raf = new RandomAccessFile(filePath, "r");
int len = 8;
raf.skipBytes(12);//跳过第一个员工的信息,其姓名8字节,年龄4字节
System.out.println("第二个员工信息:");
String str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
System.out.println("第一个员工信息:");
raf.seek(0);//将文件指针移动到文件开始位置
str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
System.out.println("第三个员工信息:");
raf.skipBytes(12);//跳过第二个员工的信息
str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
raf.close();
}
}
class Employee {
String name;
int age;
final static int LEN = 8;
public Employee(String name, int age) {
if (name.length() > LEN) {
name = name.substring(0, 8);
} else {
while (name.length() < LEN) {
name = name + "\u0000";
}
this.name = name;
this.age = age;
}
}
}
MappedByteBuffer
Java io operations usually use BufferedReaderbuffered BufferedInputStreamIO classes to process large files, but java nio introduces a MappedByteBuffermethod based on operating large files, which has extremely high read and write performance
3.3 Core code for write operation
In order to save the length of the article, I only show the core code below, and the complete code can be downloaded at the end of the article
Implementation of RandomAccessFile
@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS)
@Slf4j
public class RandomAccessUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile accessTmpFile = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
accessTmpFile = new RandomAccessFile(tmpFile, "rw");
//这个必须与前端设定的值一致
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
long offset = chunkSize * param.getChunk();
//定位到该分片的偏移量
accessTmpFile.seek(offset);
//写入该分片数据
accessTmpFile.write(param.getFile().getBytes());
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessTmpFile);
}
return false;
}
}
MappedByteBuffer implementation
@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER)
@Slf4j
public class MappedByteBufferUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile tempRaf = null;
FileChannel fileChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
tempRaf = new RandomAccessFile(tmpFile, "rw");
fileChannel = tempRaf.getChannel();
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
//写入该分片数据
long offset = chunkSize * param.getChunk();
byte[] fileData = param.getFile().getBytes();
mappedByteBuffer = fileChannel
.map(FileChannel.MapMode.READ_WRITE, offset, fileData.length);
mappedByteBuffer.put(fileData);
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.freedMappedByteBuffer(mappedByteBuffer);
FileUtil.close(fileChannel);
FileUtil.close(tempRaf);
}
return false;
}
}
File operation core template class code
@Slf4j
public abstract class SliceUploadTemplate implements SliceUploadStrategy {
public abstract boolean upload(FileUploadRequestDTO param);
protected File createTmpFile(FileUploadRequestDTO param) {
FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class);
param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath()));
String fileName = param.getFile().getOriginalFilename();
String uploadDirPath = filePathUtil.getPath(param);
String tempFileName = fileName + "_tmp";
File tmpDir = new File(uploadDirPath);
File tmpFile = new File(uploadDirPath, tempFileName);
if (!tmpDir.exists()) {
tmpDir.mkdirs();
}
return tmpFile;
}
@Override
public FileUploadDTO sliceUpload(FileUploadRequestDTO param) {
boolean isOk = this.upload(param);
if (isOk) {
File tmpFile = this.createTmpFile(param);
FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile);
return fileUploadDTO;
}
String md5 = FileMD5Util.getFileMD5(param.getFile());
Map<Integer, String> map = new HashMap<>();
map.put(param.getChunk(), md5);
return FileUploadDTO.builder().chunkMd5Info(map).build();
}
/**
* 检查并修改文件上传进度
*/
public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) {
String fileName = param.getFile().getOriginalFilename();
File confFile = new File(uploadDirPath, fileName + ".conf");
byte isComplete = 0;
RandomAccessFile accessConfFile = null;
try {
accessConfFile = new RandomAccessFile(confFile, "rw");
//把该分段标记为 true 表示完成
System.out.println("set part " + param.getChunk() + " complete");
//创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127
accessConfFile.setLength(param.getChunks());
accessConfFile.seek(param.getChunk());
accessConfFile.write(Byte.MAX_VALUE);
//completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传)
byte[] completeList = FileUtils.readFileToByteArray(confFile);
isComplete = Byte.MAX_VALUE;
for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) {
//与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE
isComplete = (byte) (isComplete & completeList[i]);
System.out.println("check part " + i + " complete?:" + completeList[i]);
}
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessConfFile);
}
boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete);
return isOk;
}
/**
* 把上传进度信息存进redis
*/
private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath,
String fileName, File confFile, byte isComplete) {
RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class);
if (isComplete == Byte.MAX_VALUE) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true");
redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5());
confFile.delete();
return true;
} else {
if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false");
redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(),
uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf");
}
return false;
}
}
/**
* 保存文件操作
*/
public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) {
FileUploadDTO fileUploadDTO = null;
try {
fileUploadDTO = renameFile(tmpFile, fileName);
if (fileUploadDTO.isUploadComplete()) {
System.out
.println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName);
//TODO 保存文件信息到数据库
}
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
}
return fileUploadDTO;
}
/**
* 文件重命名
*
* @param toBeRenamed 将要修改名字的文件
* @param toFileNewName 新的名字
*/
private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) {
//检查要重命名的文件是否存在,是否是文件
FileUploadDTO fileUploadDTO = new FileUploadDTO();
if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) {
log.info("File does not exist: {}", toBeRenamed.getName());
fileUploadDTO.setUploadComplete(false);
return fileUploadDTO;
}
String ext = FileUtil.getExtension(toFileNewName);
String p = toBeRenamed.getParent();
String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName;
File newFile = new File(filePath);
//修改文件名
boolean uploadFlag = toBeRenamed.renameTo(newFile);
fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp());
fileUploadDTO.setUploadComplete(uploadFlag);
fileUploadDTO.setPath(filePath);
fileUploadDTO.setSize(newFile.length());
fileUploadDTO.setFileExt(ext);
fileUploadDTO.setFileId(toFileNewName);
return fileUploadDTO;
}
}
upload interface
@PostMapping(value = "/upload")
@ResponseBody
public Result<FileUploadDTO> upload(FileUploadRequestDTO fileUploadRequestDTO) throws IOException {
boolean isMultipart = ServletFileUpload.isMultipartContent(request);
FileUploadDTO fileUploadDTO = null;
if (isMultipart) {
StopWatch stopWatch = new StopWatch();
stopWatch.start("upload");
if (fileUploadRequestDTO.getChunk() != null && fileUploadRequestDTO.getChunks() > 0) {
fileUploadDTO = fileService.sliceUpload(fileUploadRequestDTO);
} else {
fileUploadDTO = fileService.upload(fileUploadRequestDTO);
}
stopWatch.stop();
log.info("{}",stopWatch.prettyPrint());
return new Result<FileUploadDTO>().setData(fileUploadDTO);
}
throw new BizException("上传失败", 406);
}
4. Second pass
4.1 What is Instant Transmission
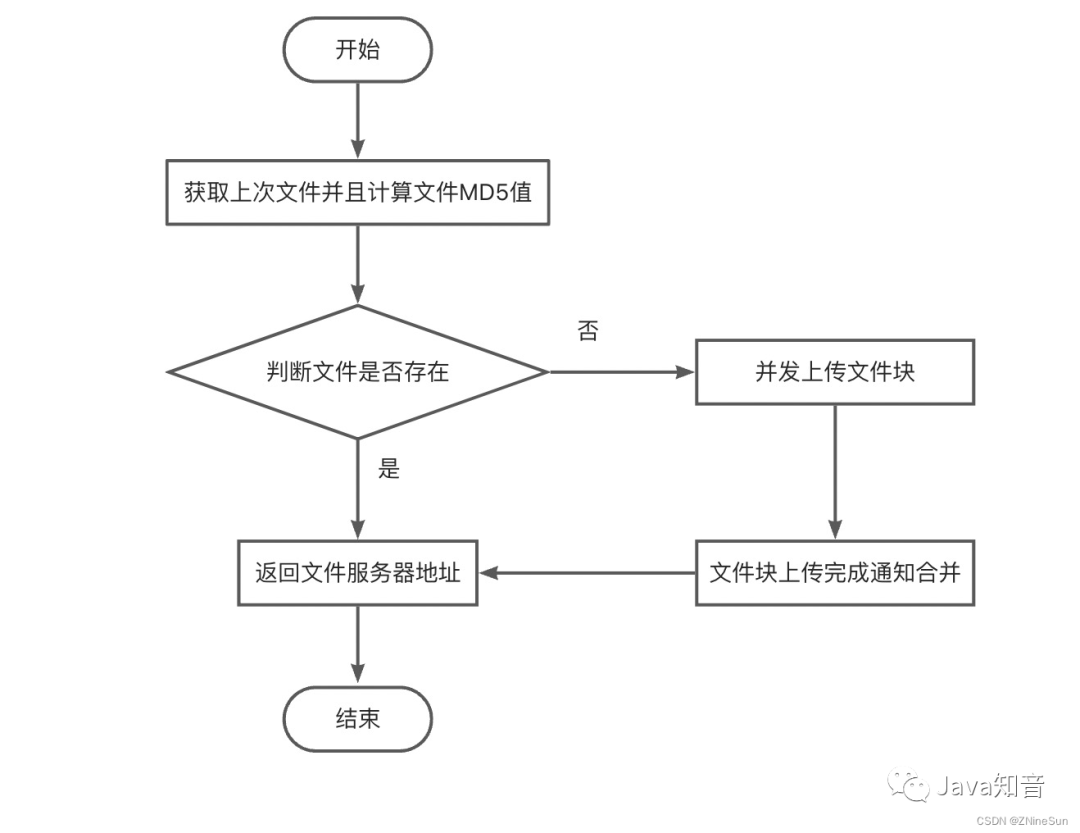
In layman's terms, when you upload something to be uploaded, the server will first perform MD5 verification. If there is the same thing on the server, it will directly give you a new address. In fact, what you download is the same file on the server. If you don’t want to transfer in seconds, you only need to change the MD5, which is to modify the file itself (changing the name does not work). For example, if you add a few more words to a text file, the MD5 will change and the transfer will not be performed in seconds.
4.2 Realized core logic of instant transmission
Use the set method of redis to store the file upload status, where the key is the md5 of the file upload, and the value is the flag indicating whether the upload is complete.
When the flag bit is true, the upload has been completed. If the same file is uploaded at this time, it will enter the second transmission logic.
If the flag bit is false, it means that the upload has not been completed. At this time, you need to call the set method to save the path of the block number file record, among which
-
key Add a fixed prefix to upload file md5
-
value is the block number file record path
4.3 Core code
private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath,
String fileName, File confFile, byte isComplete) {
RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class);
if (isComplete == Byte.MAX_VALUE) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true");
redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5());
confFile.delete();
return true;
} else {
if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false");
redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(),
uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf");
}
return false;
}
}
5. Summary
In the process of uploading in pieces, the cooperation between the front end and the back end is required. For example, the file size of the upload block number at the front and back ends must be the same, otherwise there will be problems with the upload.
Secondly, file-related operations normally require building a file server, such as using fastdfs, hdfs, etc.
If the project team thinks that building a file server by itself takes too much time, and the project needs only upload and download, then it is recommended to use Ali's oss server, and its introduction can be found on the official website:
-
https://help.aliyun.com/product/31815.html
Ali's oss is essentially an object storage server, not a file server, so if there is a need to delete or modify a large number of files, oss may not be a good choice.
project address:
-
https://gitee.com/ninesuntec/large-file-upload