What is XGBoost

XGBoost is an excellent version of GBDT. The overall structure of XGBoost is consistent with that of GBDT. On the basis of training a tree, the next tree is trained to predict the gap between it and the real distribution. Composition enables simulation of real distributions.
Of course, XGBoost has its own unique features. When we train a model, we usually define an objective function and then optimize it. The objective function of XGBoost includes two parts: a loss function and a regularization term.
The loss function represents the degree to which the model fits the data . We usually use its first-order derivative to point out the direction of gradient descent. XGBoost also calculates its second-order derivative, which further considers the trend of gradient changes, making the fitting faster and more accurate. high.
The regularization term is used to control the complexity of the model. The more leaf nodes, the larger the model, which not only takes a long time to calculate, but also overfits when it exceeds a certain limit, resulting in a decline in the classification effect. The regularization term of XGBoost is a penalty mechanism. The more the number of leaf nodes, the greater the penalty, thus limiting their number.
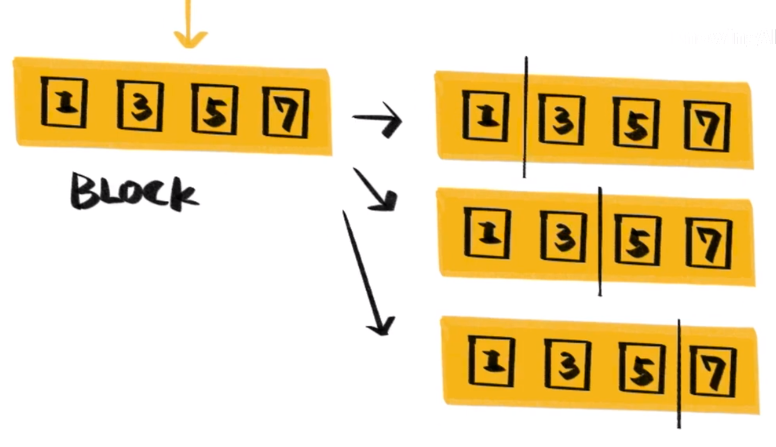
In addition to the mathematical principles, the biggest improvement of XGBoost is that the calculation speed is greatly improved. In the construction of the tree, the most time-consuming part is the sorting of the eigenvalues to determine the best split point . XGBoost sorts the features before training and stores them as Block structures, and then reuses these structures to reduce the amount of calculation.
It is good at capturing the dependencies between complex data, can obtain effective models from large-scale data sets, and supports multiple systems and languages in practicality. These are the advantages of XGBoost. It also has flaws, such as poor table entries on high-dimensional coefficient feature datasets and small-scale datasets.
After XGBoost, there are also Boosting methods such as LightGBM and CatBoost, which have their own advantages in terms of improving computing speed and processing category features.