If you need source code and data sets, please like, follow and leave a message in the comment area~~~
1. Introduction to Text Sentiment Analysis
Text sentiment analysis refers to the process of analyzing, processing and extracting subjective text with emotional color by using natural language processing and text mining technology.
Next, we mainly implement sentiment classification. Sentiment classification is also called sentiment tendency analysis, which refers to identifying whether the tendency of the subjective text is affirmative or negative, or positive or negative, for a given text. The most studied content in the field of sentiment analysis. Usually, there are a large number of subjective texts and objective texts on the Internet, and objective texts are objective descriptions of affairs without emotional color or emotional tendency. The object of emotion classification is subjective text with emotional tendency, so emotion classification must first carry out subjective and objective refinement of the text, focusing on emotion word recognition, using different text feature representation methods and classifiers for recognition research, network Subjective and objective classification of text in advance can improve the speed and accuracy of sentiment classification
2. Dataset Introduction
The data set used in this blog is IMDB data. The IMDB data set contains 50,000 severely polarized comments from the Internet. The data is divided into 25,000 comments for training and 25,000 comments for testing.
The URL corresponding to the data is given in it.

3. Data preprocessing
Because this data set is very small, if you use this data set for word embedding, there may be overfitting, and the model is not universal, so a word embedding that has been learned is passed in, using glove's 6B 100-dimensional pre-training data
As shown below

4. Algorithm model
1: Recurrent Neural Network (RNN)
It is a kind of neural network that specializes in processing time series data samples. Each layer of it not only outputs to the next layer, but also outputs a hidden state for the current layer to use when processing the next sample.
The network structure diagram is as follows
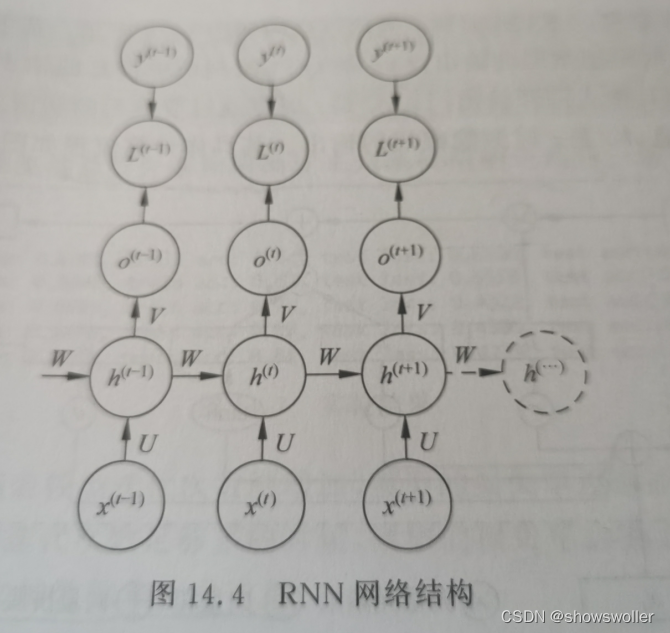
2: Long Short-Term Memory Neural Network (LSTM)
However, RNN will encounter great difficulties in dealing with long-term dependencies. Therefore, calculating the connection between distant nodes will design multiple multiplications of the Jacobian matrix, which will cause gradient disappearance or gradient explosion. LSTM can effectively solve this problem. Its main idea is
The introduction of gating units and linear connections
Gating unit: selectively save and output historical information
Linear connection: LSTM can better capture the dependencies with large intervals in the middle of time series data
The working diagram is as follows
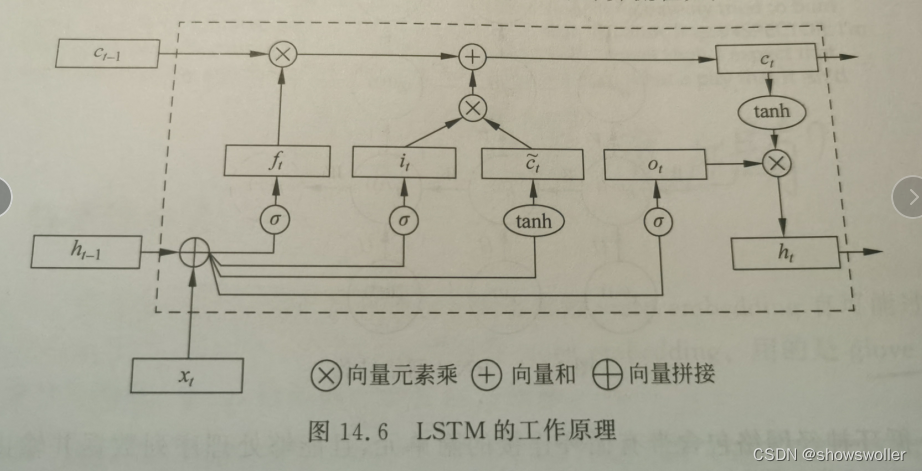
5. Model Training
The effect of using the PyTorch-based LSTM model is as follows
It is recommended to use GPU or cuda. It takes a long time to train with cpu alone~~~

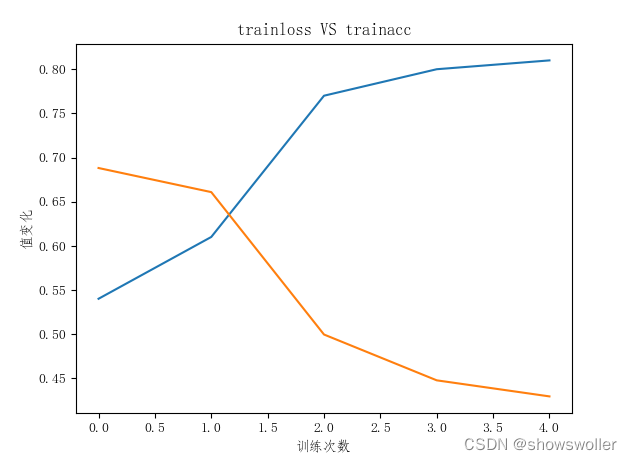
The training result graph is as follows
Loss vs. Accuracy Variation on Test Set
It can be seen from the figure below that when the training reaches about 4-5 times, the model has gradually converged and there is no need to train it many times

Loss vs. Accuracy Variation on Training Set
6. Code
Part of the source code is as follows
# coding: utf-8
# In[1]:
import torch.autograd as autograd
import torchtext.vocab as torchvocab
from torch.autograd import Variable
import tqdm
import os
import time
import re
import pandas as pd
import string
import gensim
import time
import random
import snowballstemmer
import collections
from collections import Counter
from nltk.corpus import stopwords
from itertools import chain
from sklearn.metrics import accuracy_score
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
# In[2]:
def clean_text(text):
## Remove puncuation
text = text.translate(string.punctuation)
## Convert words to lower case and split them
text = text.lower().split()
# Remove stop words
stops = set(stopwords.words("english"))
text = [w for w in text if not w in stops and len(w) >= 3]
text = " ".join(text)
## Clean the text
text = re.sub(r"[^A-Za-z0-9^,!.\/'+-=]", " ", text)
text = re.sub(r"what's", "what is ", text)
text = re.sub(r"\'s", " ", text)
text = re.sub(r"\'ve", " have ", text)
text = re.sub(r"n't", " not ", text)
text = re.sub(r"i'm", "i am ", text)
text = re.sub(r"\'re", " are ", text)
text = re.sub(r"\'d", " would ", text)
text = re.sub(r"\'ll", " will ", text)
text = re.sub(r",", " ", text)
text = re.sub(r"\.", " ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\/", " ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r"\+", " + ", text)
text = re.sub(r"\-", " - ", text)
text = re.sub(r"\=", " = ", text)
text = re.sub(r"'", " ", text)
text = re.sub(r"(\d+)(k)", r"\g<1>000", text)
text = re.sub(r":", " : ", text)
tan ", text)
text = re.sub(r"\0s", "0", text)
text = re.sub(r" 9 11 ", "911", text)
text = re.sub(r"e - mail", "email", text)
text = re.sub(r"j k", "jk", text)
text = re.sub(r"\s{2,}", " ", text)
## Stemming
text = text.split()
stemmer = snowballstemmer.stemmer('english')
stemmed_words = [stemmer.stemWord(word) for word in text]
text = " ".join(stemmed_words)
print(text)
return text
# In[3]:
def readIMDB(path, seg='train'):
pos_or_neg = ['pos', 'neg']
data = []
for label in pos_or_neg:
files = os.listdir(os.path.join(path, seg, label))
for file in files:
with open(os.path.join(path, seg, label, file), 'r', encoding='utf8') as rf:
review = rf.read().replace('\n', '')
if label == 'pos':
data.append([review, 1])
elif label == 'neg':
data.append([review, 0])
return data
# In[3]:
root = r'C:\Users\Admin\Desktop\aclImdb\aclImdb'
train_data = readIMDB(root)
test_data = readIMDB(root, 'test')
# In[4]:
def tokenizer(text):
return [tok.lower() for tok in text.split(' ')]
train_tokenized = []
test_tokenized = []
for review, score in train_data:
train_tokenized.append(tokenizer(review))
for review, score in test_data:
test_tokenized.append(tokenizer(review))
# In[5]:
vocab = set(chain(*train_tokenized))
vocab_size = len(vocab)
# In[6]:
# 输入文件
glove_file = datapath(r'C:\Users\Admin\Desktop\glove.6B.100d.txt')
# 输出文件
tmp_file = get_tmpfile(r'C:\Users\Admin\Desktop\wv.6B.100d.txt')
# call glove2word2vec script
# default way (through CLI): python -m gensim.scripts.glove2word2vec --input <glove_file> --output <w2v_file>
# 开始转换
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_file, tmp_file)
# 加载转化后的文件
wvmodel = KeyedVectors.load_word2vec_format(tmp_file)
# In[7]:
word_to_idx = {word: i + 1 for i, word in enumerate(vocab)}
word_to_idx['<unk>'] = 0
idx_to_word = {i + 1: word for i, word in enumerate(vocab)}
idx_to_word[0] = '<unk>'
# In[8]:
def encode_samples(tokenized_samples, vocab):
features = []
for sample in tokenized_samples:
feature = []
for token in sample:
if token in word_to_idx:
feature.append(word_to_idx[token])
else:
feature.append(0)
features.append(feature)
return features
# In[9]:
def pad_samples(features, maxlen=500, PAD=0):
padded_features = []
for feature in features:
if len(feature) >= maxlen:
padded_feature = feature[:maxlen]
else:
padded_feature = feature
while (len(padded_feature) < maxlen):
padded_feature.append(PAD)
padded_features.append(padded_feature)
return padded_features
# In[10]:
train_features = torch.tensor(pad_samples(encode_samples(train_tokenized, vocab)))
train_labels = torch.tensor([score for _, score in train_data])
test_features = torch.tensor(pad_samples(encode_samples(test_tokenized, vocab)))
test_labels = torch.tensor([score for _, score in test_data])
# In[13]:
class SentimentNet(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentNet, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.use_gpu = use_gpu
self.bidirectional = bidirectional
self.embedding = nn.Embedding.from_pretrained(weight)
self.embedding.weight.requires_grad = False
self.encoder = nn.LSTM(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels)
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
# In[16]:
num_epochs = 5
embed_size = 100
num_hiddens = 100
num_layers = 2
bidirectional = True
batch_size = 64
labels = 2
lr = 0.8
device = torch.device('cpu')
use_gpu = True
weight = torch.zeros(vocab_size + 1, embed_size)
for i in range(len(wvmodel.index_to_key)):
try:
index = word_to_idx[wvmodel.index_to_key[i]]
except:
continue
weight[index, :] = torch.from_numpy(wvmodel.get_vector(
idx_to_word[word_to_idx[wvmodel.index_to_key[i]]]))
# In[17]:
net = SentimentNet(vocab_size=(vocab_size + 1), embed_size=embed_size,
num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=weight,
labels=labels, use_gpu=use_gpu)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=lr)
# In[18]:
train_set = torch.utils.data.TensorDataset(train_features, train_labels)
test_set = torch.utils.data.TensorDataset(test_features, test_labels)
train_iter = torch.utils.data.DataLoader(train_set, batch_size=batch_size,
shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size=batch_size,
shuffle=False)
# In[20]:
num_epochs = 20
# In[ ]:
for epoch in range(num_epochs):
start = time.time()
train_loss, test_losses = 0, 0
train_acc, test_acc = 0, 0
n, m = 0, 0
for feature, label in train_iter:
n += 1
net.zero_grad()
feature = Variable(feature.cpu())
label = Variable(label.cpu())
score = net(feature)
loss = loss_function(score, label)
loss.backward()
optimizer.step()
train_acc += accuracy_score(torch.argmax(score.cpu().data,
dim=1), label.cpu())
train_loss += loss
with torch.no_grad():
for test_feature, test_label in test_iter:
m += 1
test_feature = test_feature.cpu()
net(test_feature)
test_loss = loss_function(test_score, test_label)
test_acc += accuracy_score(torch.argmax(test_score.cpu().data,
dim=1), test_label.cpu())
test_losses += test_loss
end = time.time()
runtime = end - start
epoch: %d, train loss: %.4f, train acc: %.2f, test loss: %.4f, test acc: %.2f, time: %.2f' %
(epoch, train_loss.data / n, train_acc / n, test_losses.data / m, test_acc / m, runtime))
# In[ ]:
It's not easy to create and find it helpful, please like, follow and collect~~~