[Hands-on deep learning] Dropout-temporary retreat method
Robustness to Perturbations
- Good predictive models: To close the gap between training and testing performance, one should aim for simple models
- Simplicity: the function is not sensitive to small changes in the input, e.g. when we classify images we expect that adding some random noise to the pixels should be largely innocuous
- Training with input noise is equivalent to Tikhonov regularization
- Actual noise addition: During training, they propose to inject noise into each layer of the network before computing subsequent layers. Because when training a deep network with multiple layers, injecting noise only enhances smoothness on the input-output mapping.
Temporary Retirement
-
Back-off method: The back-off method calculates each internal layer while injecting noise during the forward propagation process, which has become a common technique for training neural networks. The reason why it is called the back-off method is that some neurons in the training process are discarded on the surface, and then in each iteration of the whole training process, the standard back-off method consists of resetting the current neurons before computing the next layer. Some nodes in the layer are set to 0.
-
How to inject noise: Inject noise in an unbiased way, so that when other layers are fixed, the expected value of each layer is equal to the value without noise
-
Gaussian noise is added to the input of the linear model, and at each training iteration, a distribution with mean 0, sampling noise is added to the input x to generate perturbed points
-
Dropout can effectively alleviate the occurrence of overfitting, and achieve the effect of regularization to a certain extent.

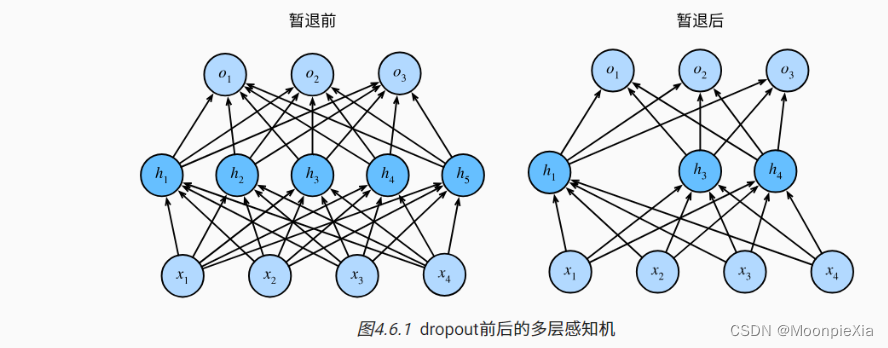
Regular terms are only used in training, they affect the update of model parameters
Dropout can be used as a trick for training deep neural networks. Overfitting can be significantly reduced by ignoring half of the feature detectors (making half of the hidden nodes value 0) in each training batch. This approach can reduce the interaction between feature detectors (hidden layer nodes). Detector interaction means that some detectors rely on other detectors to function. Dropout is simple: when we propagate forward, let the activation value of a certain neuron stop working with a certain probability p, which can make the model more generalized, because it will not rely too much on some local Characteristics,
Summarize
- Dropout randomly sets some output items to 0 to control the complexity of the model
- Often acts on the output of the hidden layer of the multi-layer perceptron
- Dropout probability is a hyperparameter that controls model complexity
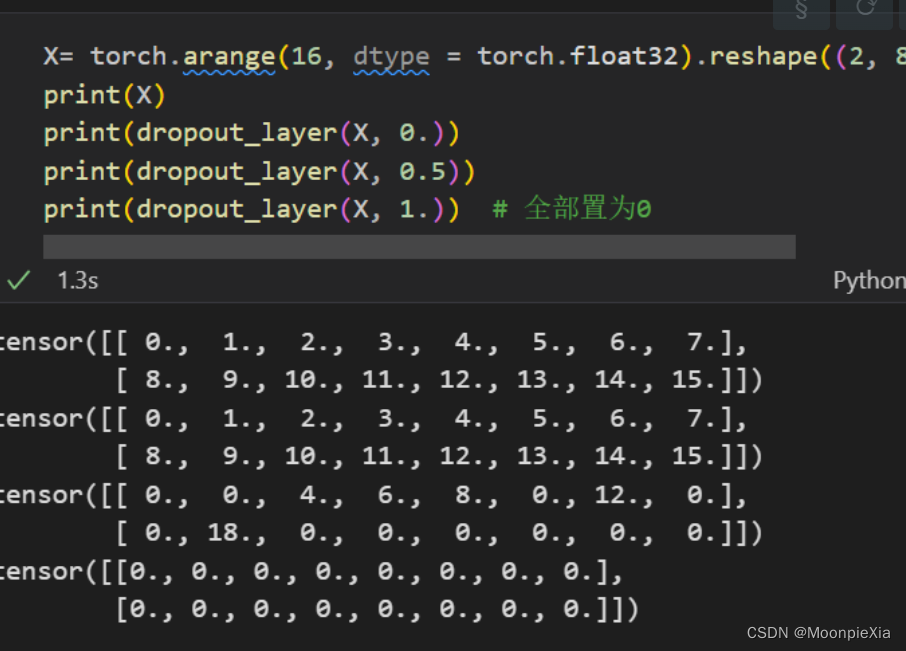
simple test
# 以dropout的概率丢弃张量输入X中的元素,重新缩放剩余部分:将剩余部分除以1.0- dropout
def dropout_layer(X,dropout):
assert 0 <= dropout <= 1
# 如果dropout 是1 将所有的x元素置为0
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中 所有元素都将被保留
if dropout == 0:
return X
# 在 0 1之间
# 使用torch.rand创建一个与X形状相同的二值掩码张量,掩码张量中的每一个元素
# 以概率1 - dropout 设置为1 否则是0
# 该掩码张量决定了dropout过程中那些元素被保留 那些元素被丢弃
mask = (torch.rand(X.shape) > dropout).float()
# 掩码张量和X进行相乘 将被丢弃的元素置为0
return mask * X / (1.0 - dropout)
Use in Multilayer Perceptron
Define model parameters
We define a multilayer perceptron with two hidden layers, each containing 256 units.
define model
Applies the respite method to the output of each hidden layer (after the activation function) and can set the respite probability separately for each layer: a common technique is to set a lower respite probability near the input layer, the following The model sets the respite probabilities of the first and second hidden layers to 0.2 and 0.5 respectively and respite only works during training
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
train and test
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
Profile implementation
# 简单首先 在每一个全连接层之后添加一个dropout层
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std = 0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)