Deep learning is a major branch of machine learning. In order to learn deep learning better, you need to master some basic machine learning knowledge.
Article directory
1.1 Key Components
1.1.1 Data (data)
Each dataset consists of individual samples(example, sample) . Typically, each sample consists of a set of attributes
called features from which a machine learning model makes predictions. In supervised learning problems, there is a special property to predict, which is called a label . The transformation of datasets from small to large sets the stage for the success of modern deep learning. Many exciting deep learning models are overshadowed by the absence of large datasets. Even though some deep learning models work on small datasets, their performance is not higher than traditional methods. Generally speaking, the more data we have, the easier our job is. When we have more data, we can usually train more powerful models, thus reducing our reliance on preconceived assumptions. At the same time, it is not enough to just have massive amounts of data, we also need the right data. If the data is full of errors, or if the features of the data do not predict the task goal, the model is likely to be invalid.(features,或协变量(covariates))(label,或目标(target))
"Garbage in, garbage out." ("Garbage in, garbage out.")
The data set usually needs to be fully representative when it is selected. If the data has some bias, then the model is likely to be biased.
1.1.2 Model
Most machine learning involves transformation of data. For example, we take a set of sensor readings and predict how normal and abnormal the readings are. This simple model can solve the above simple problems, but there are many complex problems beyond the limits of traditional methods, which require deep learning.
The main difference between deep learning and classical methods is that the former focuses on powerful models, which are intricately intertwined by neural networks and contain layers of data transformation, so they are called deep learning(deep learning) .
1.1.3 Objective function
Machine learning can be simply described as "learning from experience" The "learning" here refers to autonomously improving the efficiency of a model to complete certain tasks. But what counts as real improvement? In machine learning, we need to define a measure of how good or bad a model is. This measure is "optimizable" in most cases, and we call it the objective function(objective function) .
We usually define an objective function and want to optimize it to the lowest point. Because lower is better, these functions are sometimes called loss functions(loss function,或cost function) .
Typically, the loss function is defined in terms of model parameters and depends on the dataset. On a dataset, we learn optimal values for model parameters by minimizing the total loss. The dataset consists of some samples collected for training, called the training dataset (or training set) . However, a model that performs well on training data does not necessarily have the same performance on a "new dataset", which is often referred to as a test dataset (or test set`( test set) ).
To sum up, we usually divide the available dataset into two parts: **训练数据集**for fitting the model parameters, and **测试数据集**for evaluating the fitted model. Then we observe the performance of the model on these two datasets. You can think of "the performance of a model on a training dataset" as "a student's score on a mock exam". This score is used as a reference for some real final exams, and even encouraging grades do not guarantee final exam success. In other words, test performance may deviate significantly from training performance. When a model performs well on the training set, but fails to generalize to the test set, we say the model is "overfitted(overfitting) " . Just like in real life, even though you do well on mock exams, the real exams don't always hit the mark.
1.1.4 Algorithm
Once we have some data sources and their representation, a model and a suitable loss function, we next need an algorithm that can search for the best parameters to minimize the loss function. In deep learning, most of the popular optimization algorithms are usually based on one basic method - gradient descent(gradient descent) . In short, at each step, gradient descent examines each parameter to see in which direction the training set loss would move if you only changed that parameter by a small amount. Then, it optimizes the parameters in a direction that can reduce the loss.
1.2 Various machine learning problems
1.2.1 Supervised Learning
A function (model parameters) is learned from the given training data set, and when new data arrives, the result can be predicted according to this function.
A concrete example: Suppose we need to predict whether a patient will have a heart attack, then the observations "heart attack" or "heart attack did not" would be our labels. Input features may be vital signs such as heart rate, diastolic and systolic blood pressure.
Supervised learning process: randomly select a subset from a known large number of data samples, and obtain basic ground-truth labels for each sample. Sometimes these samples are already labeled (for example, did the patient recover within the next year?); other times, we might need to manually label the data (for example, to classify images). These inputs, along with the corresponding labels, constitute the training dataset. We then choose a supervised learning algorithm that takes as input the training dataset and outputs a "completed learned model". Finally, we put the previously unseen sample features into this "completed learned model" and use the model's output as a prediction for the corresponding label.
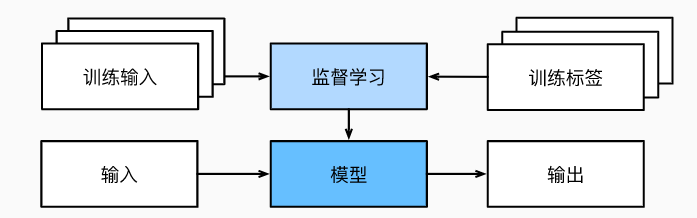
Although supervised learning is only one of several broad categories of machine learning problems, most of the successful applications of machine learning in industry are supervised learning. This is because, to a certain extent, many important tasks can be clearly described as: estimating the probability of something unknown given a specific set of available data.
1.2.1.1 Regression
Regression is one of the simplest supervised learning tasks.
It can be a good solution to the "how many" problem, such as:
- How many hours does this operation take?
- How much rainfall will this town expect over the next six hours?
According to the type of relationship between independent variables and dependent variables, it can be divided into linear regression analysis and nonlinear regression analysis.
Linear regression is often one of the techniques of choice when learning predictive models. In linear regression, the dependent variable is continuous, while the independent variable can be continuous or discrete, and the nature of the regression line is linear.
1.2.1.2 Classification
In classification problems, we want the model to be able to predict which category (formally known as class) an example belongs to.
It can solve the "which" problem very well, such as:
- The simplest classification problem has only two classes, which we call "binary classification". For example, a dataset might consist of animal images, and the labels might be {cat,dog}.
- When we have more than two classes, we call the problem a multivariate classification
(multiclass classification)problem. Common examples include handwritten character recognition {0,1,2,…9,a,b,c,…}.
1.2.1.3 Tagging Issues
The problem of learning to predict classes that are not mutually exclusive is called multi-label classification (multi-label classification).
Take, for example, the tags people put on tech blogs like "machine learning", "technology", "gadgets", "programming languages", "Linux", "cloud computing", "AWS". A typical article might use 5-10 tags because the concepts are interrelated. A post about "cloud computing" might refer to "AWS", while a post about "machine learning" might also refer to "programming languages".
For example, this picture:

there is a cat, a rooster, a dog, a donkey, and some trees in the background. Depending on what we ultimately want to do with our model, it may not make much sense to treat it as a binary classification problem. Instead, we might want the model to depict the content of the input image, a cat, a dog, a donkey, and a rooster.
1.2.1.4 Search
Sometimes we don't just want the output to be a category or a real value. In the field of information retrieval, we wish to rank a set of items. Taking web search as an example, our goal is not to simply 查询(query)-网页(page)classify " ", but to find the part that users need most in the massive search results. The ordering of search results is also important, our learning algorithm needs to output an ordered subset of elements. In other words, if we were asked to output the first 5 letters of the alphabet, returning "A, B, C, D, E" and "C, A, B, E, D" are different. Even if the result sets are the same, the order within the sets sometimes matters.
One possible solution to this problem: first assign a corresponding relevance score to each element in the set, then retrieve the element with the highest rating.
1.2.1.5 Recommendation System
Another type of search and ranking-related problem is 推荐系统(recommender system)that it aims to make "personalized" recommendations to specific users.
For example, for movie recommendations, the recommendation results pages for sci-fi fans and comedy fans can be very different. Similar applications appear in retail products, music and news recommendations, and more.
In some applications, customers provide explicit feedback on how much they like a particular product. For example, product ratings and reviews on Amazon. In other cases, customers provide implicit feedback. For example, a user skips certain songs in a playlist, which may indicate that those songs are not suitable for the user. In general, a recommender system scores a match for a "given user and item", and this "score" may be an estimated rating or probability of purchase. From this, for any given user, the recommender system can retrieve the set of objects with the highest scores and then recommend them to the user. The above are just simple algorithms, whereas industrially produced recommender systems are much more advanced, taking detailed user activity and item characteristics into account. Recommender system algorithms are tuned to capture a person's preferences.
1.2.1.6 Sequence Learning
Most of the above problems have fixed-size inputs and produce fixed-size outputs. In these cases, the model will only use the input as "raw material" to generate the output, without "remembering" the specific content of the input.
If the input samples are independent of each other, the above model may be perfect. But if the input is continuous, our model may need to have a "memory" function.
For example in the processing of video clips:
each video clip may consist of a different number of frames. From the image of the previous frame, we may be more certain about what happened in the following frame. The same is true for languages, where both the input and output of machine translation are sequences of words.
1.2.2 Unsupervised Learning
Machine learning problems that do not contain a "target" in the data are unsupervised learning
聚类(clustering)问题: Can we classify data without labels? For example, given a set of photos, can we separate them into pictures of landscapes, pictures of dogs, babies, cats, and mountains? Likewise, given the web browsing history of a set of users, can we cluster users with similar behaviors?主成分分析(principal component analysis)问题: Can we find a small number of parameters to accurately capture the linearly related properties of the data? For example, the trajectory of a ball can be described by its speed, diameter and mass. As another example, tailors have developed a small set of parameters that describe the shape of the human body fairly accurately to suit the needs of clothing.因果关系(causality)和概率图模型(probabilistic graphical models)Question: Can we describe the root cause of many of the observed data? For example, if we have demographic data on house prices, pollution, crime, geographic location, education, and wages, can we simply discover the relationship between them based on empirical data?生成对抗性网络(generative adversarial networks): Gives us a way to synthesize data, even complex unstructured data like images and audio. The underlying statistical mechanism is a test that checks whether real and fake data are the same.
1.2.3 Interaction with the environment
Whether it's supervised or unsupervised learning, we fetch a lot of data up front and then start the model without interacting with the environment. All learning here takes place after the algorithm is disconnected from the environment, called 离线学习(offline learning).
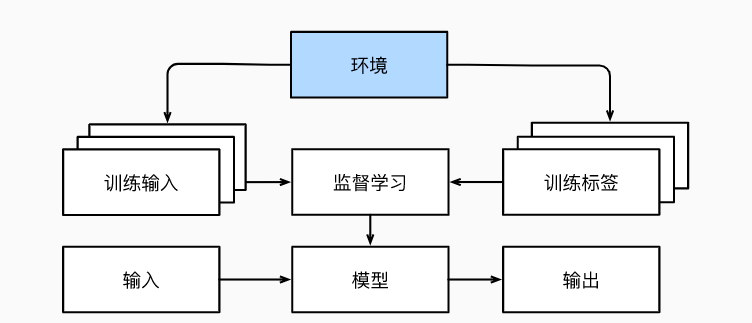
This simple offline learning has its charm. The bright side is that we can do pattern recognition in isolation without having to be distracted by other problems. The downside, however, is that the problem to be solved is rather limited. But if we need AI to be able to interact with the environment, rather than simply make predictions, to be "intelligent agents", we need to take into account that the behavior of interactions may affect future observations.
1.2.4 Reinforcement Learning
Reinforcement learning is a field in machine learning that emphasizes how to act based on the environment to maximize the desired benefit.
It is inspired by the behaviorism theory in psychology, that is, how organisms gradually form anticipation of stimuli under the stimulation of rewards or punishments given by the environment, and produce habitual behaviors that can obtain the greatest benefits. This is a class of problems that explicitly consider interaction with the environment.
To give a few specific examples:
- TaskBot-Ali Xiaomi's task-based question answering technology
- Taobao E-commerce Search
- Q-learning in reinforcement learning can be used to deal with dynamic pricing problems
The scenarios involved in reinforcement learning and its practical application are very extensive and relatively complex. If you are interested, you can learn more about it.