Huawei's Noah's Ark Lab-Enterprise Intelligence Team's latest research achievement "Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting" was accepted by AAAI 2020. This study augments the source time series data into high-order tensors with the help of multi-way delay transformation technology, and cleverly combines the tensor decomposition technology with the classic time series forecasting model ARIMA, and then proposes a forecasting method suitable for multiple time series technology (BHT-ARIMA), especially for scenes with short sequence length and small number of samples.
1. Research background
Time series forecasting has been one of the common yet most challenging tasks. For decades, it has played an important role in statistics, machine learning, data mining, econometrics, operations research and many other fields. For example, forecasting the supply and demand of a product can be used to optimize inventory management, production planning, and vehicle scheduling, etc., which is critical to most aspects of supply chain optimization. In the Huawei supply chain scenario, due to the characteristics of the product—for example, the sales cycle of electronic products (mobile phones or laptops) is very short (usually 1 year), the supply cycle of its raw materials is also very short. Under such circumstances, its raw material demand forecast and product sales forecast are based on very short historical data.
1.1 Research questions
For similar scenarios, the problems we face:
a. When it is necessary to predict multiple time series at the same time, the internal relationship between the series (products) should be taken into account (as shown in the figure below)
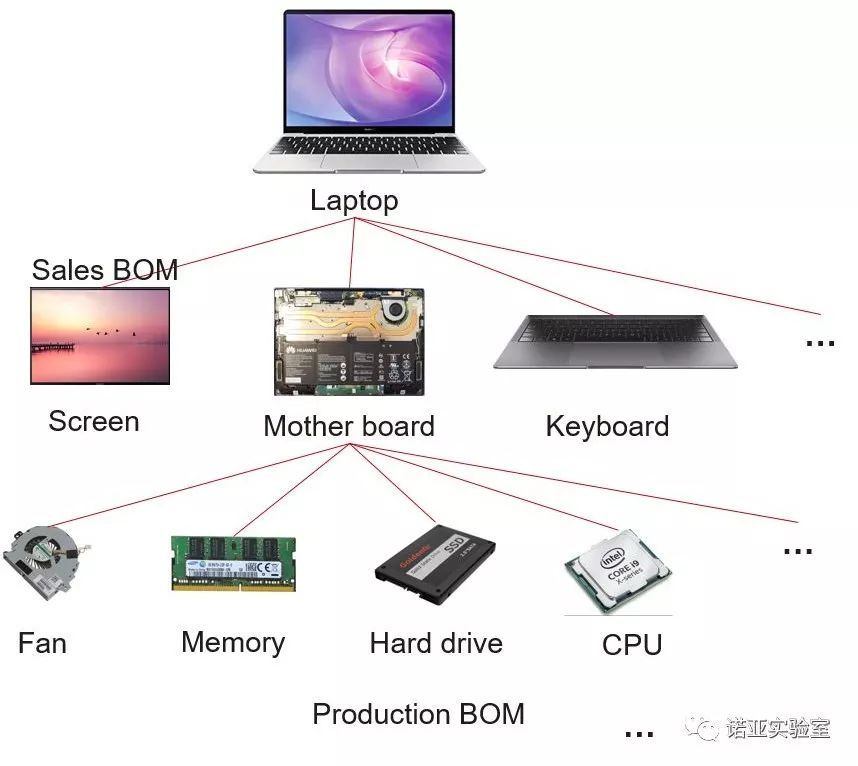
Figure 1: There is a certain intrinsic relationship between the components/raw materials required to produce a product such as a Laptop
b. Time series are mostly small samples (short time length, small number of sequences), difficult to train models
c. The time series in actual production are all non-stationary, complex and fluctuating (as shown in the figure below)
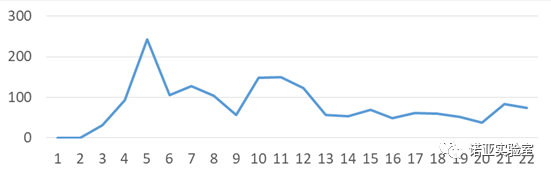
Figure 2: Changes in monthly demand for an item in actual production
1.2 For the above problems, the existing technology can not solve?
- Time series algorithms are not suitable for capturing nonlinear high-dimensional features, and the prediction of multiple sequences is poor and time-consuming
- Machine learning algorithms have high requirements for the construction of features and cannot effectively capture the internal relationship between sequences
- The deep learning algorithm model requires a large amount of data training and takes a long time to train, while the time series has the characteristics of small samples
- Although the tensor decomposition algorithm can consider mining the relationship between multiple time series, it is mainly suitable for high-order time series, and short time series data are usually low-order tensors
1.3 Technical Background - Tensor Decomposition
Tensor is a proper term for multidimensional data. Vectors and matrices can be thought of as first- and second-rank tensors, respectively. In the real world, many data such as videos exist in the form of tensors. Tensor decomposition is a powerful computational technique for extracting valuable features from raw data by decomposing it. Tucker decomposition is one of the very commonly used tensor decomposition models. For a third-order tensor, three second-order factor matrices (factor matrix) and a third-order nuclear tensor (core tenor) can be obtained by Tucker decomposition. In other words: Tucker decomposition maps the original tensor to a kernel tensor with good properties (such as low-rank) through a factor matrix (also called a mapping matrix). Kernel tensors can be further applied to tasks such as classification, clustering, and regression. as the picture shows:
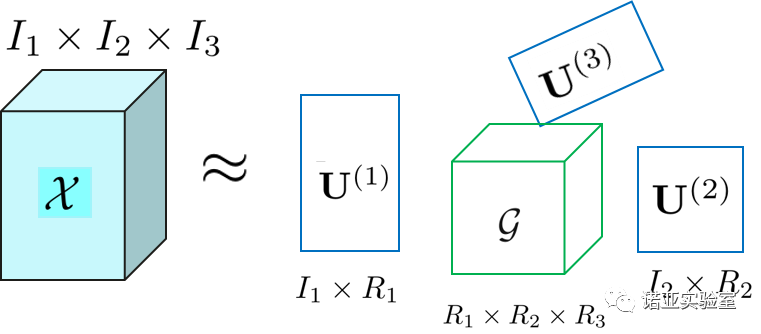
Figure 3: A third-order tensor is decomposed by Tucker to obtain a smaller-sized core tensor multiplied by three factor matrices
2. The proposed technical solution
2.1 Overview of the innovative points of the solution
For the problem of predicting multiple small sample time series, the solution we propose mainly has the following three innovations:
- [Data augmentation (feature space reconstruction)] Convert small sample data to high-order tensor data to obtain multidimensional data with larger data volume and better characteristics (such as low-rank and other structured characteristics) (without loss of original data) information).
- [Constrained low-rank tensor decomposition] Use the Tucker tensor decomposition technique under the orthogonal constraint to extract the augmented data to obtain new features (core tensors) with smaller size but better quality.
- [Tensorized ARIMA for forecasting] Tensorize the existing classic forecasting model ARIMA model, and then directly use the multi-dimensional core features obtained from the decomposition to train tensor ARIMA for forecasting.
2.2 Implementation steps
Specifically, it mainly includes the following three steps:
step 1:
Multiple short time series are converted into high-order multi-dimensional data along the time dimension by using the multi-path delay embedding transformation technology (MDT). The resulting high-order multidimensional tensor is called "Block Hankel Tensor (BHT)". BHT has good properties like low rank or smoothness, which are easier to learn and train than raw data. The implementation process is shown in Figure 4. For example, suppose there are 1000 time series, the length of each series is 40,即 I = 1000,T=40, set the parameters t = 5, and after MDT is transformed along the time dimension, a 1000*5*(40-5+1)=1000*5*36three-dimensional tensor is obtained. In other words, each 1000*1vector of size becomes each matrix 1000*5slice of size, that is, transformed into a 1000*5*36three-dimensional tensor. By extension, for higher-dimensional time series, such as video data, we can get higher-order tensors.
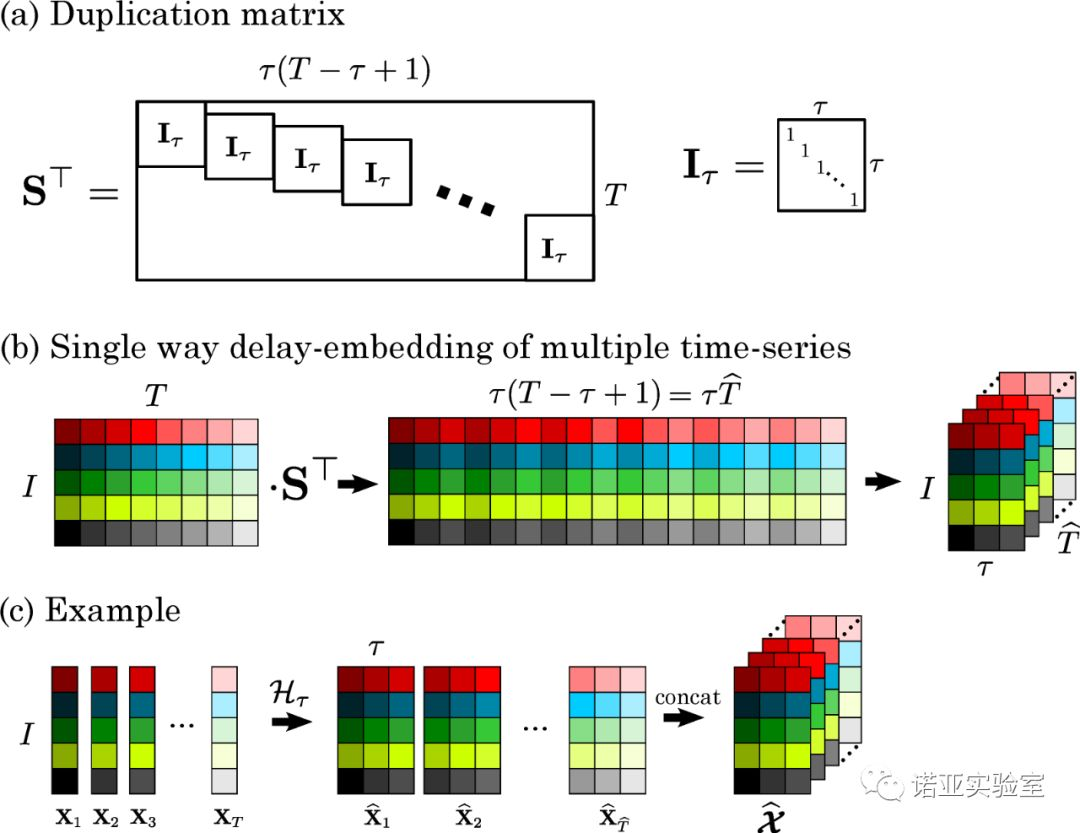
Figure 4: Figure (a) shows the mapping matrix S in MDT technology (called a repeated matrix in MDT); (b) shows a matrix with a size of I * T passing through the mapping matrix S along the time dimension T direction Do transformation to get a three-dimensional tensor data; (c) further show the case of figure (b): the values of all time series at each time point, after MDT transformation, each one-dimensional vector becomes a set of matrices
Here, we only transform the data along the time dimension because the adjacent relationships in other non-time dimensions are not very correlated (in other words, the ordering between different time series can be arbitrarily replaced). Therefore, it is not meaningful to implement MDT in all data directions, but instead increases the amount of calculation (the BHT order becomes higher and the dimension becomes larger). In any case, our algorithm can support multi-directional MDT at the same time to obtain higher-order (more dimensional) data.
Step 2:
After the BHT is obtained in step 1, the Tucker tensor decomposition technique is used to decompose it to obtain new features, which are called core tensors. This decomposition process requires a common set of mapping matrices. Existing tensor models impose constraints on the mapping matrix in the direction of each data dimension, and we only relax the constraints on the time dimension, that is, we only add orthogonal constraints on the time dimension, while the orthogonal constraints on other dimensions remain unchanged. , to better capture the intrinsic correlation between sequences. At the same time, this study tensorizes the existing classical forecasting algorithm (ARIMA) so that it can directly process multidimensional data.
Step 3:
predict. We directly use the core tensor to train the tensor ARIMA model to predict the new core tensor, and then through Tucker inverse transformation and MDT inverse transformation, get the predicted values of all sequences at the same time. This not only reduces computation (due to smaller core tensor sizes), but also improves forecasting accuracy by exploiting the interrelationships between multiple time series during model building
In summary, we have obtained a new forecasting algorithm named BHT-ARIMA, and its workflow diagram is as follows:
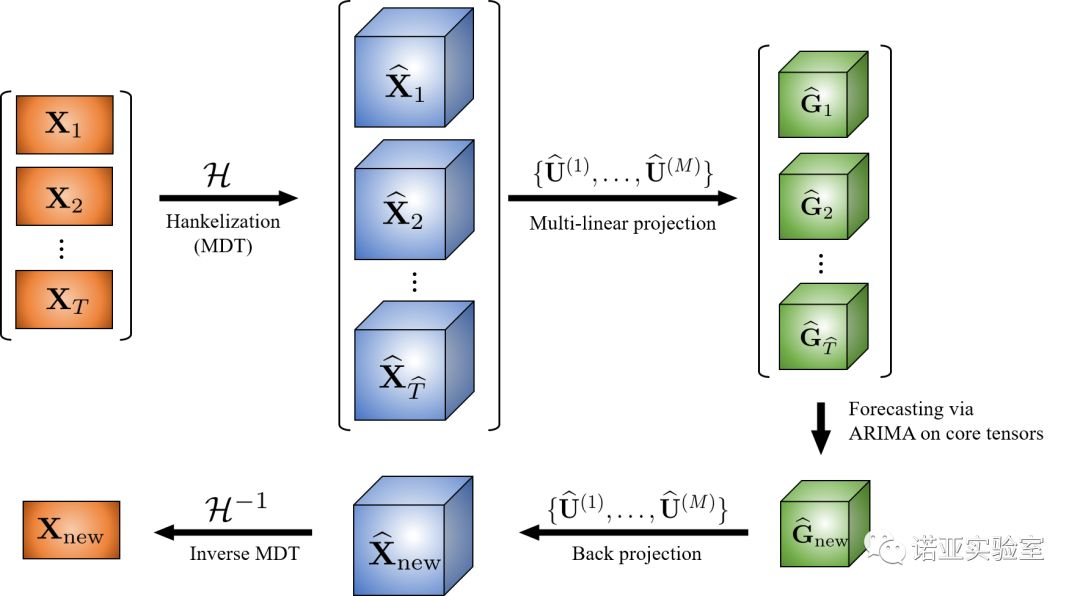
(a) BHT-ARIMA applied to second-order time series data (matrix)
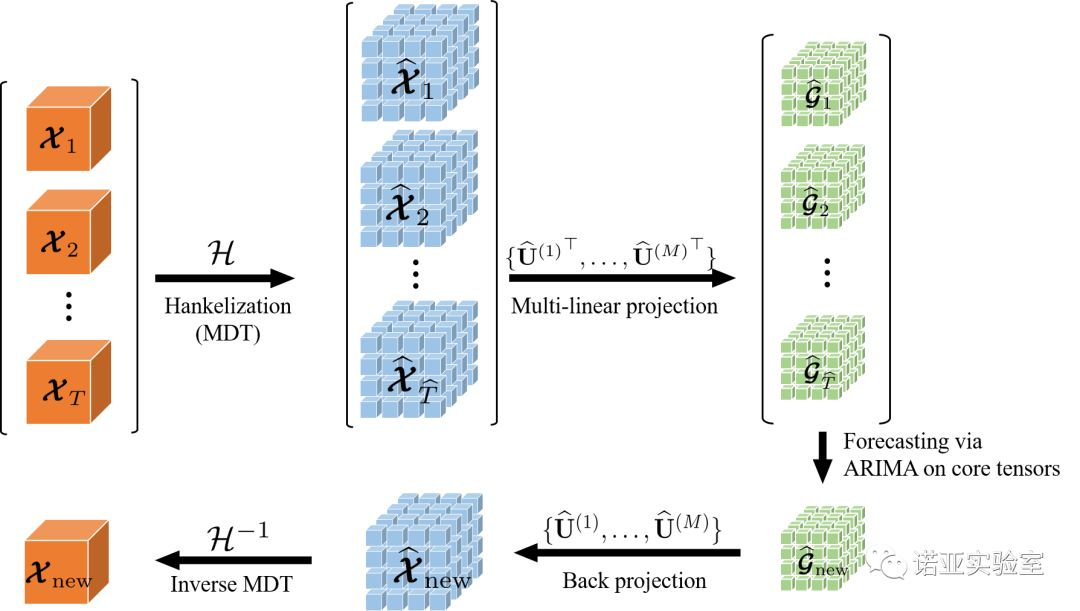
(b) BHT-ARIMA applied to third-order tensor time series data
Figure 5: Workflow diagram of the algorithm BHT-ARIMA. Transform the source data (multiple time series) into high-order tensor time series BHT through MDT technology. Further use tensor decomposition technology (Tucker decomposition) to extract new features (core tensor G) from BHT. At the same time, these core tensors are directly trained on the tensor ARIMA model to obtain new core tensors. The new core tensor obtains the predicted value of the source sequence after inverse tensor decomposition and inverse MDT transformation
This study integrates the respective advantages of data augmentation transformation technology, low-rank tensor decomposition technology, and tensor prediction model into a unified framework, which is not only faster, but also captures the internal relationship between multiple time series, thereby Can improve prediction results, especially for short data. Next, we verify the actual effect of BHT-ARIMA through extensive experiments.
3. Experimental verification
We applied BHT-ARIMA to 3 public time series datasets: Electricity, Traffic, Smoke videoand 2 Huawei supply chain datasets: PC sales 和Raw Materials, and compared nine commonly used or latest algorithms:
- classic
ARIMA,VAR和XGBoost - Two popular industry forecasting methods:
Facebook-Prophet 和Amazon-DeepAR - Two neural network based methods:
TTRNN和GRU - Two matrix/tensor based methods:
TRMF和MOAR - Furthermore, we take the block Hankel tensor BHT as the input of MOAR, resulting in a new algorithm "BHT+MOAR" to evaluate the effectiveness of MDT combined with tensor decomposition.
We compare the time series of different lengths and sample numbers, and the result is the error NRMSE to measure the prediction accuracy. The results are shown in Tables 1 and 2: BHT-ARIMA outperforms all compared methods on four datasets, and has more advantages on shorter/smaller time series. Overall, BHT-ARIMA reduces the prediction error by an average of more than 10% compared with other algorithms.

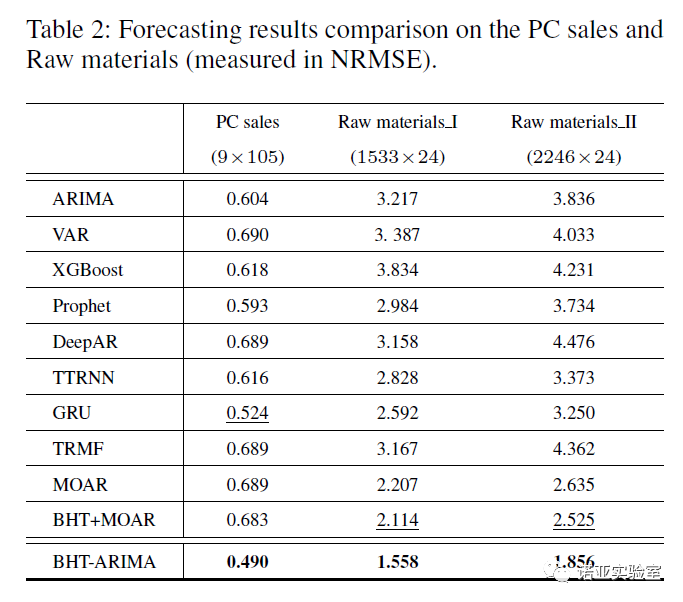

Figure 6: Prediction results under different proportions of training samples in the video Smoke Video
We further test on higher order video data. As shown in Figure 6, BHT-ARIMA consistently maintains its superiority on different training sets (even with only 10% training samples). Although ARIMA can use more than 50% of the training data to obtain slightly better prediction results than BHT-ARIMA, its computational cost and storage requirements are very high - because like other linear models, they cannot directly handle tensor data only It can be transformed into a high-dimensional vector.
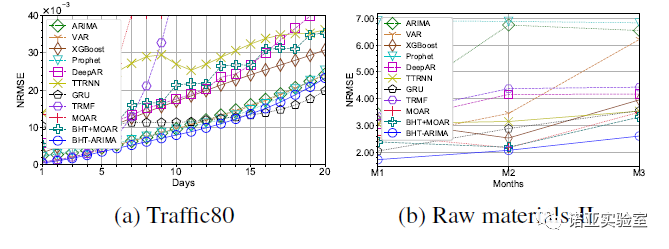
Figure 7: Long-term (multi-step) prediction results on Traffic and Raw material datasets
Fig. 7 shows the comparison of long-term prediction results, which further confirms the good performance of BHT-ARIMA. With more steps to predict, the errors of all methods generally increase, while BHT-ARIMA consistently maintains its best performance overall, especially on the shorter Raw materials dataset. Although GRU slightly outperforms our method after 15-step forecasting on the Traffic80 dataset, its computation time is nearly 900 times that of BHT-ARIMA.
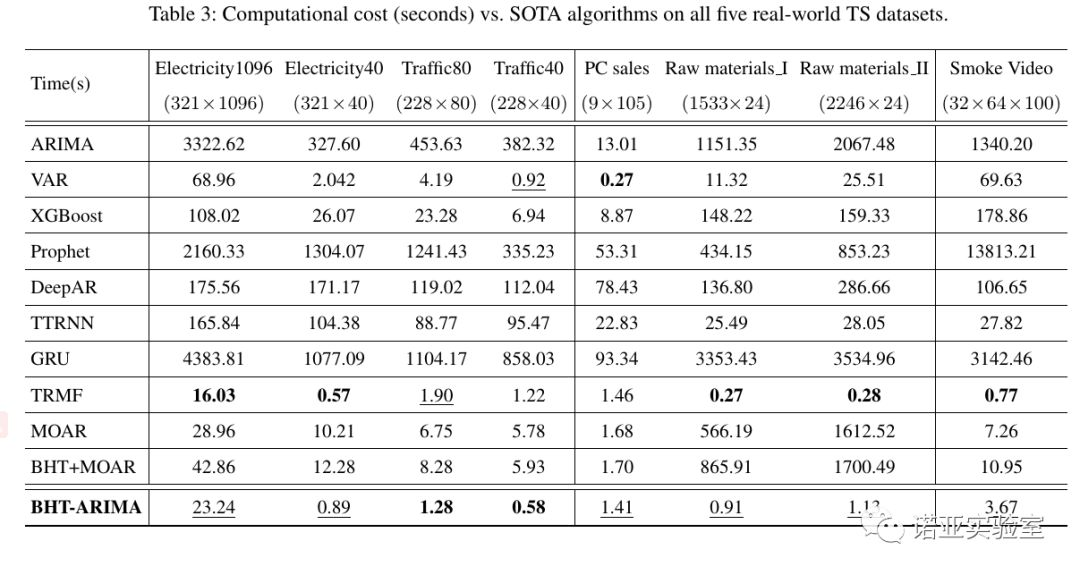
Finally, we compare the training time of all methods, as shown in Table 3. Overall, BHT-ARIMA is the second fastest algorithm - we focused on accuracy and haven't optimized the code for efficiency yet. Although TRMF is somewhat slower than VAR in some cases, it is overall the fastest since its core is programmed in C. Although GRU and ARIMA rank second or even surpass BHT-ARIMA in some tests, they are the slowest methods (more than 500 times slower than our algorithm on average).
Four. Summary
This study combines MDT transformation technology with Tucker decomposition for the first time and introduces it into the field of time series forecasting. The high-order tensor BHT obtained by MDT not only augments the data but also has a good structure such as low rank, thereby improving the model input-especially for short and small sample data. Then further use Tucker decomposition to obtain a core tensor with a smaller size but better characteristics, and then combine it with tensor ARIMA to quickly train to obtain prediction results. In this way, the proposed algorithm BHT-ARIMA skillfully combines the unique advantages of the three techniques of MDT augmented data, tensor decomposition, and ARIMA in a unified model. By testing public data sets and Huawei's supply chain data, it is verified that BHT-ARIMA is continuously faster and better than existing prediction algorithms (100+ times faster and 10%+ prediction accuracy on average), effectively solving multiple (short and small) The problem of simultaneous forecasting of time series. At present, our team is implementing this technology in actual projects