Article Directory
The content is compiled from "Get the Offer Data Analyst Job Interview Guide" - Xu Lin's fourth chapter programming skills test
Other content:
[Data Analyst Job Interview Guide] Necessary basic knowledge
[Data Analyst Job Interview Guide] Essential The essential usage of Hive SQL for programming skills sorting
[Data Analyst Job Interview Guide] Practical skills part
Familiar with Python
Know R language
Master SQL
Some experiences and points to note about using Hive SQL in an Internet company internship
Big Data Foundation
Hive is a data warehouse tool for Hadoop, which maps structured data files into a database table and provides SQL-like query functions: Hive SQL
Hadoop mainly solves two major problems: big data storage and big data analysis. The solution depends on HDFS and Mapreduce respectively.
HDFS: Scalable, fault-tolerant, high-performance distributed file system, asynchronous replication, write once, read many times, mainly responsible for storage.
MapReduce is a distributed computing framework, including Map mapping and Reduce reduction process, which is responsible for computing on HDFS.
When Hadoop stores and calculates massive amounts of data but requires the front-end to display data changes in real time, real-time performance cannot be guaranteed. MySQL is a relational database that stores data on a local server, which can satisfy real-time display, but it may be killed by the computational load.
At present, the general method is to process the original data set through Hive SQL in Hadoop, try to complete the calculation of large amount of data in Hive, and then import the processed data into MySQL by way of exporting.
Below isTake Hive SQL as an example:
Common types of database
Single-table query SQL statements that do not involve subqueries: select, from, where, group by, having, order by select
Execution sequence: from->where->group by ->select->having->order by
When group by exists, non-aggregate fields after select will be regarded as group fields, and one-to-one correspondence must be guaranteed ! Group by is before sellect, so aliases cannot be used directly.
Only when there is a group by, use having. It is mainly for aggregated fields and retrograde filtering. Field aliases can be used.
desc descending, asc ascending
multi-table query
join: connect in units of fields (columns) [used more widely].
1. inner join (inner join): only keep the records that exist in both tables
2. left join (left join): keep all the records in the left table, if there is no match, use NULL
3. right join: keep all the records in the right table
4. full join: keep both left and right table records
union: connect in units of records (rows), you need to ensure that the number of fields in the two tables to be connected is the same, and they correspond one-to-one in sequence.
There is union.union all in mysql; Hive only has union all (without deduplication)
Hive is mostly a partitioned table, which speeds up queries and saves computing resources. Without an index, each query requires a full scan. Increasing partitions can reduce the number of scans per scan.
Partition table: incremental table and full table.
More
aggregate function
After the select appears, the records are summarized according to the grouping fields
| aggregate function | meaning |
|---|---|
| sum(col) | Calculate the sum of all records in the group after grouping |
| avg(col) | ...mean |
| count(col) | number of records |
| stddev(col) | standard deviation |
| variance(col) | variance |
| max()min() | Maximum and minimum |
| percentile(col,p) | p-quantile, p:0~1 |
distinct
Deduplication, two scenarios:
one is to use after select to deduplicate the entire record (all field values are the same) select distinct id,name...;
the other is to perform aggregation functions, deduplication after grouping, and then perform aggregation calculations. count(distinct subject): Count the number of subjects that have taken the exam
case when
- Used in grouping statements and selection statements, after group by ( field aliases cannot be used ), a new grouping field is provided.
select case when city in ('青岛','济南')then '山东'
else '其他'
end as province
count(1) as total
from table
where pt>='2019-01-01'
group by case when city in ('青岛','济南')then '山东'
else '其他'
end
- After selection, generate new fields based on existing fields
- In the aggregation function:
count(distinct case when score>=60 then subject end)as total_suc_subject: the number of subjects passed in the statistical examination
aggregate function+distinct+case whenBasically complete the SQL grouping calculation!
window function
Recommend Alibaba Cloud Documentation
Similar aggregation functions also perform aggregation calculations after grouping records, but instead of returning only one value for each group, multiple values are returned. To be precise, forEach record in the groupBoth return a specific value. It can only appear after select, and the basic structure
of group by and partition by will not be used to indicate that all records are grouped according to col1 and col2, and the same records are sorted according to col3 and col4 in descending or ascending order.函数名() over (partition by col1,col2 order by col3 desc/asc,col4 asc/desc)
Commonly used (must be mastered, can reduce table-to-table connections):

dynamic update
User retention rate: the proportion of users who used the app n days ago are still using it today. The index is obtained n days after the original data is generated, and the partition data before n days needs to be updated, which involves the concept of dynamic partition.
Hive does not support insert, update, and delete, and cannot directly modify records. Data modification is realized by fully updating partitions.
First create a partition table;

one line to multiple lines
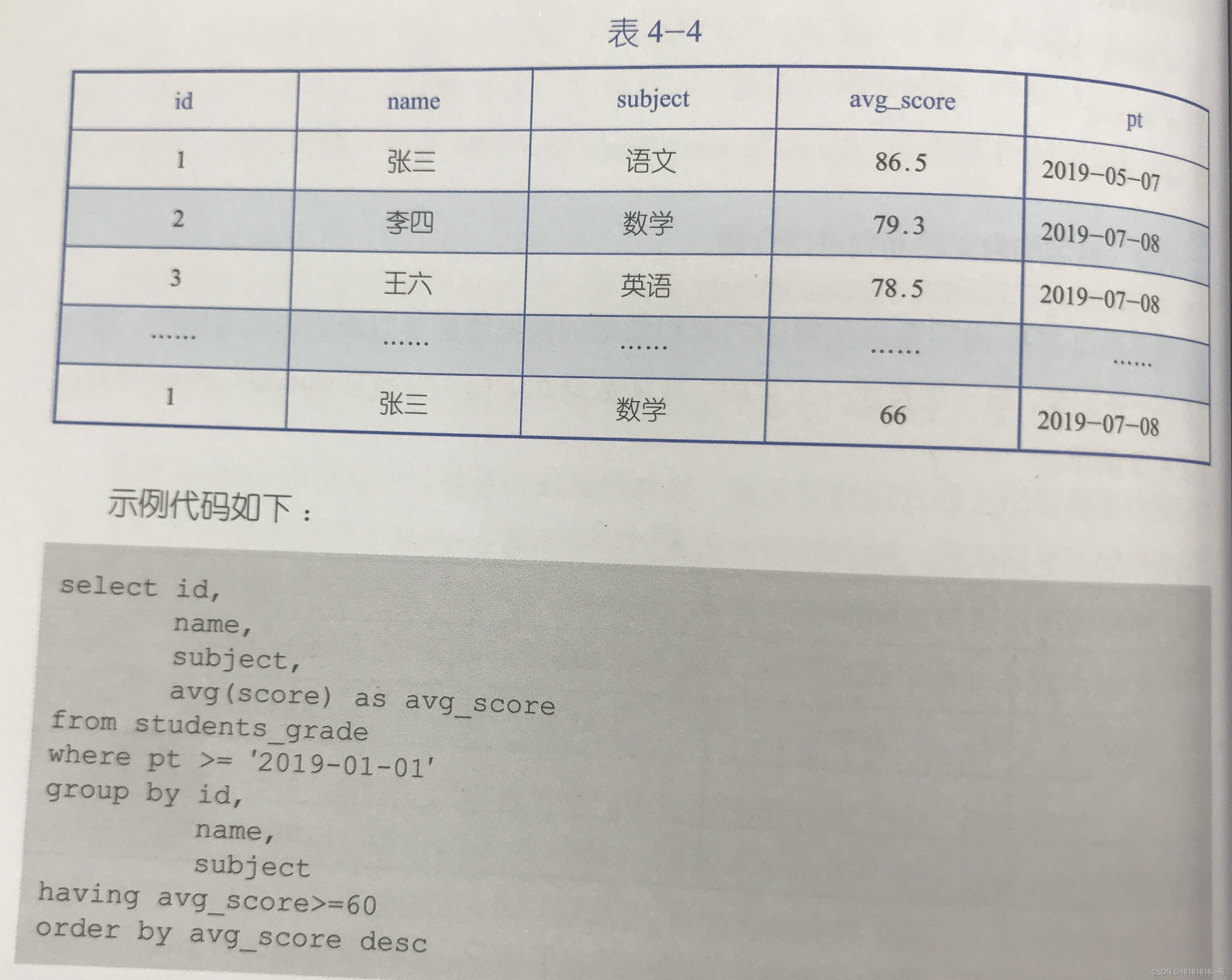
group by multiple lines into one line
![[External link image transfer failed, the source site may have an anti-leeching mechanism, it is recommended to save the image and upload it directly (img-vSF3Djdb-1678341151851)(images/Pasted%20image%2020230309133003.png)]](https://img-blog.csdnimg.cn/3ed8131e33a74e9b9f7a98c11a5b7797.png)
Tuning
For example, when you need to join a large table and a small table, you can use MAPJOIN to load the small table into the memory, usually the size of the small table is 25MB.
If the calculation speed is still not fast after the above operations, considerdata skewquestion.
During the execution of the Hive SQL statement, it goes through two steps of Map and Reduce.

