Table of contents
1. Internal modules and their functions
2. Execution process of a select statement
3. Execution process of an update statement
4, InnoDB's buffer pool (Buffer Pool)
1. Internal modules and their functions
The inside of mysql is mainly divided into the mysql service layer and the storage engine layer. The service layer includes connectors, parsers, preprocessors, optimizers, and executors. Mainly for data operation, filtering, and calculation functions; the storage engine layer is a separate storage engine layer, which is mainly responsible for data access, and the storage engine is the file system hardware of the computer.

- Connector
- parser
- preprocessor
- optimizer
- Actuator
- storage engine
1. Connector:
The connector mainly manages database link objects and verifies user permissions when connecting
2. Parser:
The parser mainly performs lexical and grammatical analysis on SQL. The lexical analysis mainly splits the sql statement into individual words, and the grammatical analysis is to perform some grammatical checks on the sql, such as whether single quotation marks, brackets, etc. are normal and have a normal end, and then the sql statement to be executed according to the grammatical rules of mysql generate a parse tree (query: select_lex)

3. Preprocessor
The preprocessor is mainly used to perform further checks on the sql with no problem in grammar after the parser parses and executes the sql normally without reporting an error, such as checking whether the table in the sql exists, whether the field exists, whether the sql is ambiguous, and the user's execution permission Does it match. After preprocessing a new parse tree will be generated.
4. Optimizer
Can the sql obtained after preprocessing in the previous step be executed directly? In fact, there are many ways to execute a sql, and the results are all the same, but how to choose the best way to execute is implemented by the optimizer.
The optimizer mainly generates different execution plans based on the parse tree generated by the preprocessor , and selects an optimal execution plan (mysql uses a cost-based optimizer, the one with the smallest cost is selected).
Other optimizations of the optimizer include selecting that table as the base table when multi-table associated queries, selecting that index when there are multiple indexes, removing redundant parentheses, 1=1 identity, etc.
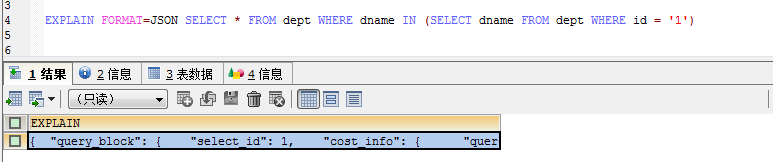
You can check the execution plan information by adding EXPLAIN in front of the sql statement . Add EXPLAIN FORMAT=JSON SQL... to view more detailed execution plan information.

5. Actuator
The executor calls the execution plan generated by the optimizer by calling the API interface provided by the storage engine layer, and finally returns the result data to the client.
6. Storage engine
There are three main types of storage engines: InnoDB, MyISAM, and Memory.
How to specify: When creating a table, specify create table 'xxxx'(xxxx) ENGINE=InnoDB through the ENGINE keyword
Differences between different engines:
InnoDB (2 files):
It is the default storage engine of mysql5.7.
Supports transactions and foreign keys, so data integrity and consistency are higher.
Supports row-level locks and table-level locks.
Support read and write concurrency, write without blocking read (MVCC).
The special index storage method can reduce IO and improve query efficiency.
Memory (1 file):
Put the data in the memory, the speed of reading and writing is very fast, but if the database restarts or crashes, all the data will disappear. Only suitable for temporary tables.
Store the data in the table into memory.
Hash indexes are used by default.
MyISAM (3 files)
Supports table-level locks (inserts and updates lock tables). Transactions are not supported.
Has a high insertion (insert) and query (select) speed.
Stores the number of rows in the table (count is faster).
(How to quickly insert 1 million pieces of data into the database? We have an operation to insert data with MyISAM first, and then modify the storage engine to InnoDB.)
How to choose a storage engine
If you have high requirements for data consistency and need transaction support, you can choose InnoDB.
If there are more data queries and less updates, and the query performance requirements are relatively high, you can choose MyISAM.
If you need a temporary table for query, you can choose Memory.
2. Execution process of a select statement

3. Execution process of an update statement
Updata actually refers to the statement of update insert and delete operation.

4, InnoDB's buffer pool (Buffer Pool)
Since the data is stored on the hard disk, the storage engine needs to operate the data by first reading and loading the data into the memory for operation. The storage engine has a minimum unit when reading disk data, which is called the page size. The operating system also has a page size, which is generally 4KB (a 1byte text file takes up 4kb). The page size of InnoDB is 16KB, that is, the data that InnoDB reads and writes from each I/O operation on the hard disk is an integer multiple of 16KB.
In order to speed up data operations and corresponding speed, InnoDB designed a memory buffer Buffer Pool. When InnoDB reads data, it first judges whether the data is in the memory buffer, if it exists, it reads directly from the buffer, if it does not exist, it reads from the hard disk, and caches the data in the buffer .
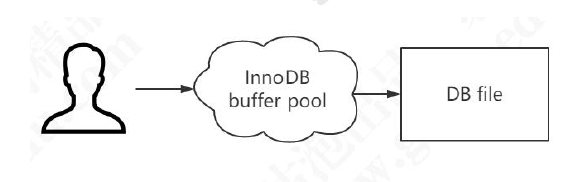
Dirty page : When modifying data, the data is also written into the buffer first. This is because the data in the buffer area is inconsistent with the data in the hard disk, which is called dirty pages.
Scrubbing : InnoDB has a dedicated background thread that will periodically write the modified data in the buffer to the hard disk at one time. This process is called scrubbing.
5,InnoDB的Log Buffer:
Redo log (redo log, ib_logfile0 and ib_logfile1 located in the /var/lib/mysql/ directory, 2 files by default): we know that the data in the above BufferPool is stored in a memory buffer, if an interruption occurs In scenarios such as electricity, the data in the memory will disappear. If there is no mechanism to ensure the persistence of the data in the buffer, the newly updated data will not be written to the disk, resulting in data loss. So InnoDB has a redo log file specially used to record every modification operation in the buffer pool. In the event of a power outage, etc., when the database is started next time, InnoDB will refresh the operations that were not previously flushed to the disk from the redo log to the disk. To ensure data persistence. (Since writing redolog files is sequential read and write (one seek time + one rotation + one read and write), it is more efficient than random read and write of database data (multiple times (seek time + rotation time + read and write time)) , so write redolog instead of directly writing to the database data file). The size of the redo log is fixed. Once the data is full, it will trigger InnoDB's scheduled tasks to perform dirty operations. Then continue to log content before overwriting.

Undo log (rollback log): The undo log mainly records the data status before the transaction is started. If an exception occurs during the transaction, the undo log will be used to achieve data rollback recovery. To ensure the atomicity of transactions. This is similar to the beforeimage record in alibaba seata distributed transaction consistency, which is used for failure recovery compensation.
6,Binlog
binlog records all DDL and DML statements in the form of events. Its two very important functions are 1. Master-slave replication and 2. Data recovery.
The principle of master-slave replication is to read the binlog of the master server from the server, and then execute it again.
