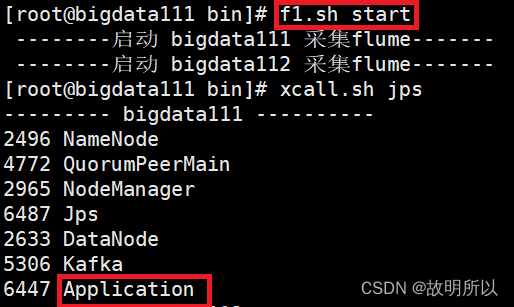
1. Problem description
Enter the command on the command line to run Flume to start
[root@bigdata111 flume-1.9.0]# bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
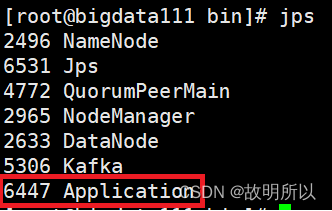
But when I run the shell start-stop script I wrote, it doesn't work
The script is as follows:
#!/bin/bash
case $1 in
"start"){
for i in bigdata111 bigdata112
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.9.0/conf/ -f /opt/module/flume-1.9.0/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in bigdata111 bigdata112
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
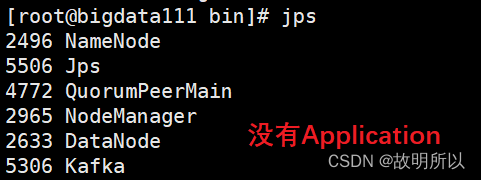
reason:
This should not be a big problem, it may be caused by environment variables.
The linux environment variables, whether to log in or not, and whether to access interactively, determine the loading order of the system /etc/profile and /etc/profile.d/*.sh and ~/.bashrc and ~/.profile or other files.
Change the environment variables in the same location of centos and ubuntu, ssh to the remote machine to execute a certain command, one may find the command, and the other may not find the command.
Two, the solution
Go to the lib folder of flume and delete the default guava-11*.jar dependency
[root@bigdata111 lib]# rm -fr guava-11.0.2.jar
Under normal circumstances, after deleting this jar, flume will look for guava used in $HADOOP_HOME in hadoop.
Then copy the guava*.jar in hadoop to the lib file of flume
[root@bigdata111 lib]# cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/flume-1.9.0/lib/
Execute the script again and find it successful