Hello everyone, I am Dugufeng, a former port coal worker, currently working as the person in charge of big data in a state-owned enterprise, and the manager of the big data flow of the official account. In the last two years, because of the needs of the company and the development trend of big data, I began to learn about data governance.
Data governance requires systematic learning to truly master, and professional examination certification is also required to prove one's learning ability and knowledge mastery in data governance. If you have any questions about data governance and data governance certification CDMP, you can refer to my previous article for a detailed introduction.
Total text: 6099 words 10 pictures
Estimated reading time: 16 minutes
This document is based on the collation of learning materials related to data governance, and is collated for the study notes (mind map and knowledge points) of the data governance professional certification CDMP .
The article is long, it is recommended to read after bookmarking.
For subsequent documents, please pay attention to the big data flow of the official account , and will continue to update~
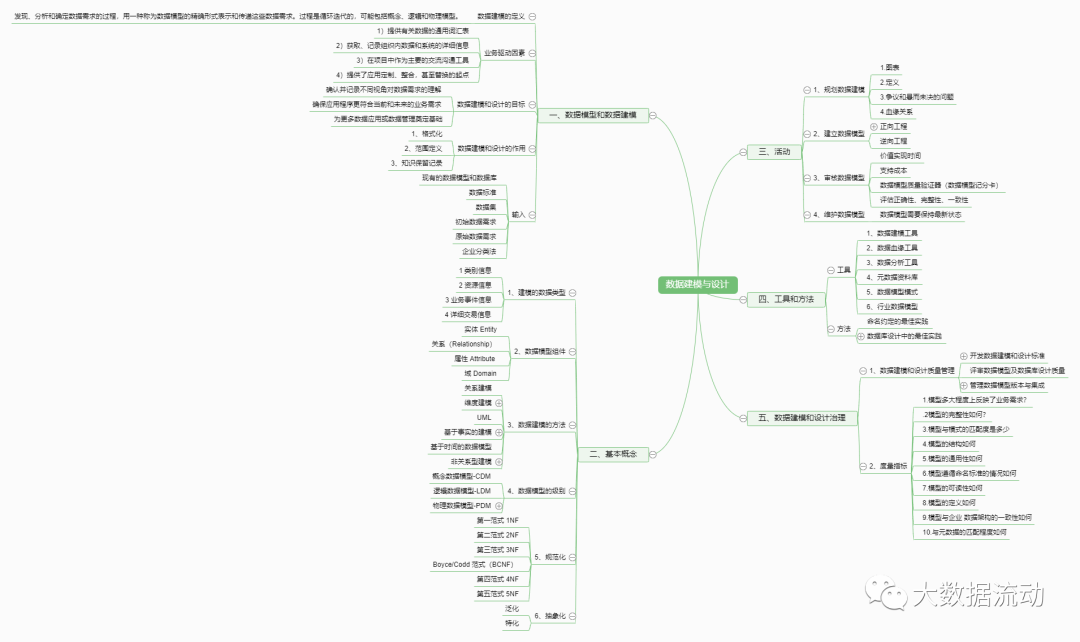
This document is part of the data modeling and design notes, mind maps and knowledge points. It is divided into 6 parts. Due to the display of the page, some levels cannot be fully expanded. The structure is shown in the figure below.
1. Data model and data modeling
Definition of data modeling : The process of discovering, analyzing, and determining data requirements, representing and communicating those data requirements in a precise form called a data model. The process is iterative and may include conceptual, logical and physical models.
Data models help organizations understand their assets.
There are 6 common data models : 1. Relational model. 2. Multidimensional mode. 3. Object-oriented mode. 4. Fact mode. 5. Time series model. 6. NoSQL mode. According to the different levels of detailed description, it can be divided into: conceptual model. logical model. physical model.
The semantic relationship diagram of data modeling and design is as follows:
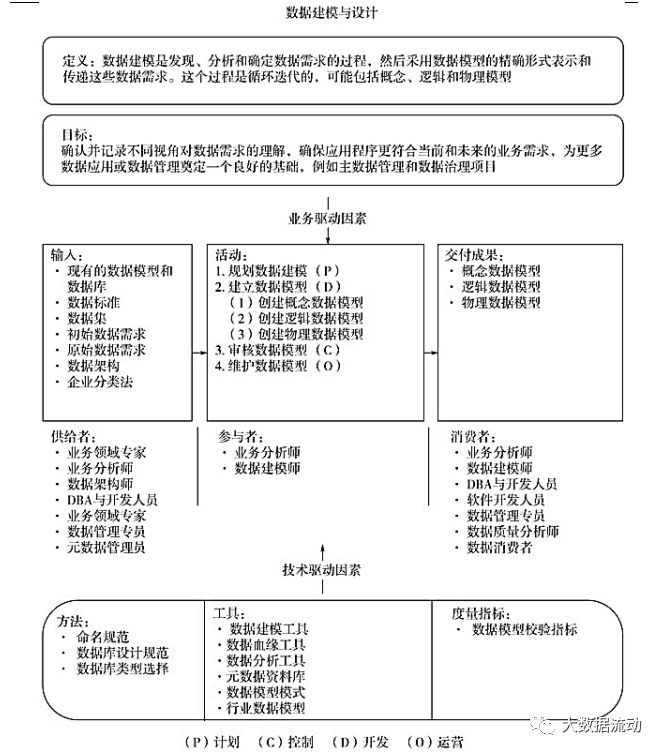
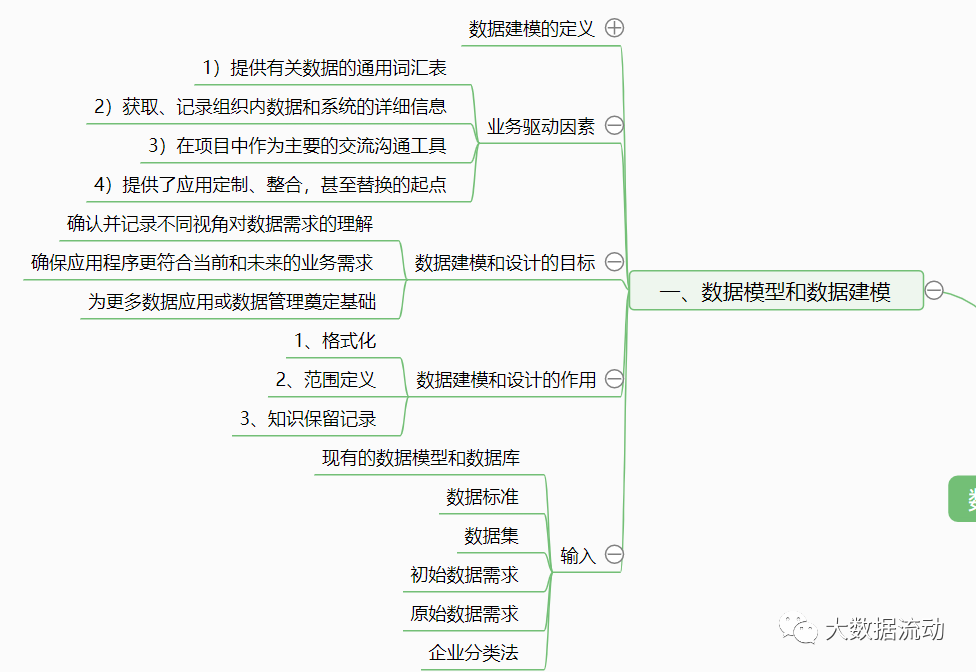
Business Drivers : 1) Provide a common vocabulary about data. 2) Obtain and record detailed information on data and systems within the organization. 3) As the main communication tool in the project. 4) Provides a starting point for application customization, integration, and even replacement.
Data model is an important form of metadata.
The goal of data modeling and design: confirm and record the understanding of data requirements from different perspectives, ensure that applications are more in line with current and future business needs, and lay the foundation for more data applications or data management, such as master data management and data governance projects .
The role of data modeling and design, confirming and recording the understanding of data requirements from different perspectives is helpful for: 1. Formatting and standardizing the structure of data. 2. Define the scope and define the boundaries. 3. Knowledge retention records. Information retention.
Data modeling and design activities : 1 Plan data modeling. 2 Build a data model (create conceptual, logical, physical models). 3 Review the data model. 4 Maintain the data model.
Input : Existing data model and database. data standards. data set. Initial data requirements. Raw data requirements. data architecture. Business Taxonomy. Deliverables: Conceptual, logical, physical data models.
Method : naming convention. Database design specification. Database type selection.
Tools : Data modeling tools. Data lineage tool. Data analysis tools. Metadata repository (stores descriptive information about the data model). Data Model Patterns (Basic Patterns. Suite Patterns. Integration Patterns). Industry data model.
Metrics : data model validation metrics.
For the convenience of understanding, organize the mind map of this part as follows:
2. Basic concepts
1. Modeled data types
Modeled data types :
1 Category information, data that classifies things or assigns types of things, such as color and model.
2 Resource information, the basic data needed to implement the operation process, such as products and customers. Resource entities are sometimes called reference data.
3 Business event information, data created during operations, such as customer orders.
4 Detailed transaction information, generated by sales system and sensors, used to analyze trends, big data. These 4 types are static data, and some dynamic data can also be modeled, such as the scheme of the system.
2. Data model components
Data model components: entities, relationships, attributes, domains.
【entity】
Entity: A thing that is different from other things.
Describe who, what, when, where, why, how, measure.
Entity aliases vary by model type. The relational model uses "entity", the dimensional model uses "dimension" and "fact table", the object-oriented type uses "class" or "object"; the basic time model uses "center", "satellite", "link", and the relational type uses "file", "node". Entity aliases are called "concepts" and "terms" in the conceptual model. These are called "entities" in the logical model. Called "table" in the physical model. The definition of an entity belongs to the core metadata.
It is generally represented by a rectangle, and the middle of the rectangle is the entity name entity and entity instance: the entity instance is the embodiment or value of a specific entity.
High-quality data definition has three characteristics : clarity, accuracy, and completeness .
【relation】
Relationships are associations between entities. Relationships capture high-level interactions between conceptual entities, detailed interactions between logical entities, and constraints between physical entities. Relationships use "navigation paths" in dimensional models and "boundaries", "links" in NoSQL. Use "relationship" on the conceptual and logical level, and use "constraint" and "reference" on the physical level. Relationships are represented as lines on a data modeling diagram.
Cardinality of a relationship : Indicates the number of relationships an entity participates in with other entities. There are "0, 1, many".
The arity of the relationship: the number of entities involved in the relationship. One-way relationship, two-way relationship, three-way relationship. Unary relations: recursive relations, self-referential relations. One-to-many: Hierarchical relationship. Many-to-many: network relationships or graphs. Binary Relationship: A relationship involving two entities. Ternary Relationship: A relationship involving three entities.
Foreign Key Foreign Key : Represents the relationship in physical model modeling, and establishes a foreign key in the database to define the relationship.
【Attributes】
Attribute Attribute: Define, describe or measure the nature of an aspect of an entity. Attributes may contain domains. Attributes are represented in the figure as lists within solid rectangles. The physical representation of an attribute in an entity is a column, field, tag, or node in a table, view, document, graph, or file.
Identifiers , keys, are collections of one or more properties that uniquely identify an entity instance. The key structure can be divided into single key, combined key, composite key, proxy key, and can be divided into candidate key, primary key and spare key according to function.
Key structure type: Single key: A property that uniquely identifies an entity instance. Surrogate key: It is also a single key, the unique identifier of the table, usually a counter, automatically generated by the system, an integer, the meaning has nothing to do with the value, technical, and should not be visible to the user. Composite key: A set of two or more attributes that together uniquely identify an entity instance. Composite key: Contains an organizational key and at least one other single key, composite key, or non-key attribute.
Functional type of key: Superkey: Any set of attributes that uniquely identifies an instance of an entity. Candidate key: A minimum set of attributes identifying an entity instance, which may contain one or more attributes. Minimal means that no arbitrary subset of candidate keys can uniquely identify an entity instance. An entity can have multiple candidate keys. Candidate keys can be business keys (natural keys). Business Key: One or more attributes used by business professionals to retrieve a single entity instance. Business keys and surrogate keys are mutually exclusive. Primary key: A candidate key that is selected as a unique identifier for an entity. Alternate key: It is a candidate key, which is unique but not selected as the primary key, and can be used to find specific entity instances.
Stand-alone entity: whose primary key contains only attributes belonging to that entity, represented by a rectangle symbol. A non-independent entity means that its primary key contains at least one attribute of another entity, and at least one identification relationship is represented by a rounded rectangle.
【area】
Domain Domain: All possible values that can be assigned to an attribute. Provides a way to normalize attribute features. Valid and invalid values. A domain can be restricted by additional rules called constraints.
Domains can be defined in many different ways, such as 1. Data Type 2. Data Format 3. List 4. Range 5. Rule-Based.
3. Data modeling method
The six common data modeling methods are relational modeling, dimensional modeling, object-oriented modeling, fact-based modeling, time-based modeling, and non-relational modeling . Each modeling method is expressed in some specific notation.
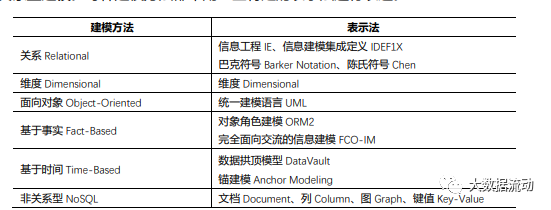
【Relational Modeling】
The purpose of relational model design is to accurately express business data and eliminate redundancy. The most common method is the information engineering method, which uses a three-pointed line (duck's foot model) to represent the cardinality.
【Dimensional Modeling】
Dimensional modeling is used to optimize the query and analysis of massive data. Modeled using Axis Notation. The lines between entities in this model represent the navigation paths used to illustrate the business problem.
Fact table: Rows correspond to specific numeric measures, such as amounts. Fact tables take up most of the space in the data and have a large number of rows.
Dimension table: Indicates important objects of the business, mainly retaining text descriptions. Dimensions are entry points or links to fact tables. Serves as the primary source of query or report constraints. Highly anti-paradigm, accounting for about 10% of the total. Each dimension has a unique identifier in each row, mainly a surrogate key and a natural key. Dimensions also have properties. Gradient dimensions manage changes based on the rate and type of change. The main changes are coverage, new rows, and new columns.
Snowflaking: Normalize the flat, single-table, and dimensional structures in the star schema into corresponding component hierarchies or network structures.
Granularity: The meaning or description of a single row of data in the fact table, the most detailed information that each row has. One of the key steps.
Consistent Dimensions: Based on the entire organization, these dimensions can be shared across different models.
Consistent Facts: Use standardized terminology across multiple data marts.
【UML】
UML: Unified Modeling Language, a graphical style modeling language.
UML specifies classes (entity types) and the relationships between them.
【Fact-Based Modeling】
Fact-Based Modeling, FBM. is a conceptual modeling language.
Including: 1. Object role modeling. 2. Fully communication-oriented modeling.
[Time-based data model]
Time-based modeling is used when data values must be associated with specific time values in a chronological order.
Data vault : central table/link table/satellite table. Specifically designed to meet the needs of enterprise data warehouses.
Anchor modeling: suitable for situations where information structure and content change over time. Provides a graphical language for conceptual modeling that can be extended to handle temporary data. It has four basic modeling concepts of anchor, attribute, connection and node. Anchors simulate entities and events. Properties mimic the characteristics of anchors. Links represent relationships between anchors. Nodes simulate shared properties.
[Non-relational modeling]
Non-relational database: document database. Key-value database. column database. graph database.
4. The level of the data model
Data Model Level: 1 Conceptual model. 2 outside mode. 3 internal modes.
These three levels are the conceptual level, the logical level, and the physical level .
【Conceptual Data Model-CDM】
A collection of related subject areas to describe profile data requirements.
【Logical Data Model-LDM】
A detailed description of the data requirements.
【Physical Data Model-PDM】
Detailed technical solutions. Based on the logic model, it is matched with certain hardware, software and network tools.
The physical data model needs to specify:
1. Specification model.
2. View.
3. Partition. (horizontal split, vertical split)
4. Anti-planning.
Denormalization: ① Combine data from multiple other tables in advance to avoid costly runtime joins.
② Create smaller, pre-filtered copies of data to reduce expensive runtime calculations and/or scans of large tables.
③ Pre-calculate and store expensive data calculation results to avoid competition for system resources at runtime.
5. Standardization
Normalization is the process of using rules to convert complex services into standardized data structures.
The basic goal of normalization is to ensure that each attribute appears in only one position, so as to eliminate redundancy or inconsistency caused by redundancy.
First Normal Form 1NF: Every entity has an effective primary key, and every attribute depends on the primary key.
Second Normal Form 2NF: Every entity has a minimal primary key, and every attribute depends on the full primary key.
Third Normal Form 3NF: Each entity has no hidden primary key, and attributes do not depend on any attribute other than the key value (only on the complete primary key). The normalization of the model usually requires reaching the third normal form.
Boyce/Codd Normal Form (BCNF): Solve the crossed composite candidate key problem. A candidate key is either a primary key or an alternate key.
Fourth Normal Form 4NF: Decompose all ternary relations into binary relations until these relations are not further divisible.
Fifth normal form 5NF: Decompose the dependency relationship inside the entity into a binary relationship, and all connections depend on some primary keys.
6. Abstraction
Abstraction is the process of removing details and improving the applicability of extensions, including: generalization and specialization .
Generalization is to abstract the parent class, and specialization is to distinguish attributes to find subclasses.
For the convenience of understanding, organize the mind map of this part as follows:
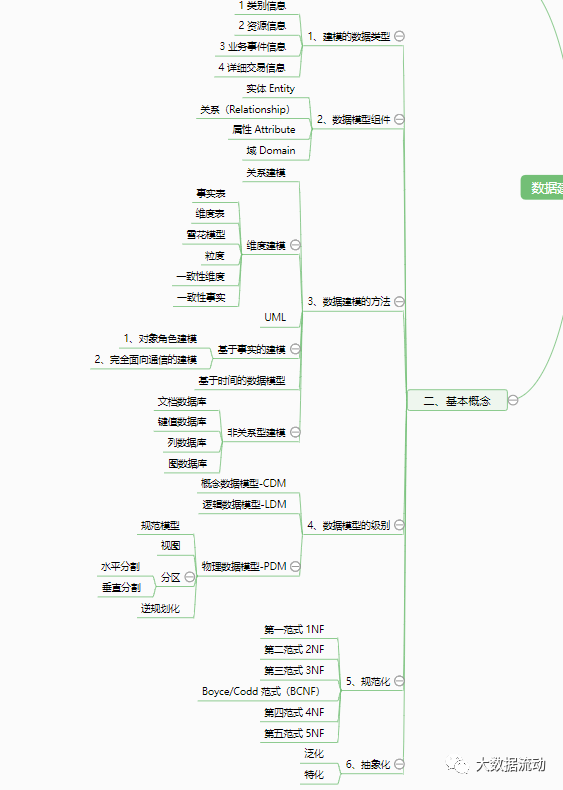
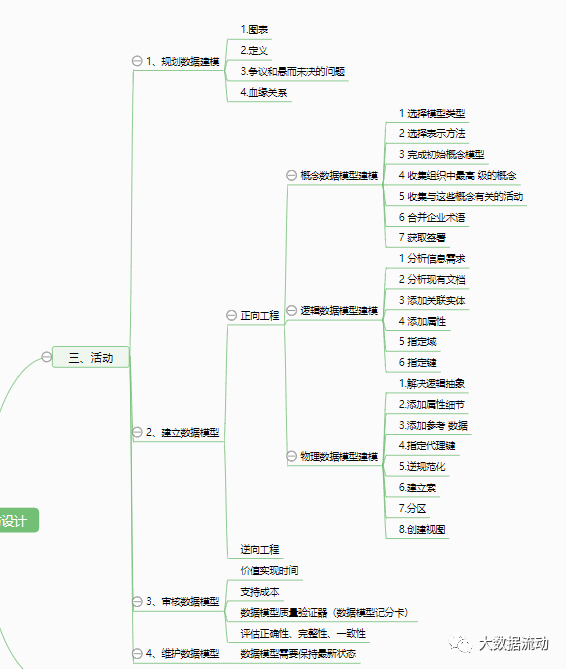
3. Activities
1. Planning data modeling
Deliverables for planning data modeling: 1. Diagrams. 2. Definition. 3. Controversies and unresolved issues. 4. Blood relationship: presented in the form of source/target mapping.
2. Build a data model
【Forward Engineering】
The process of building a new application starting from requirements. Conceptual - logical - physical.
Conceptual data model modeling : 1 Select the model type. 2 Select a representation method. 3 Complete the initial conceptual model. 4 Gather the top-level concepts in your organization. 5 Collect activities related to these concepts. 6 Consolidation of corporate terms. 7 Get signed.
Logical data model modeling : 1 Analyze information requirements. 2 Analyze existing documents. 3 Add associated entities. 4 Add attributes. 5 Specify the domain. 6 Specify the key.
Physical data model modeling : 1. Solve logical abstraction [subtype absorption. Supertype partition. ] 2. Add attribute details 3. Add reference data object 4. Specify surrogate key 5. Denormalize 6. Build index 7. Partition 8. Create view.
【Reverse Engineering】
The process of documenting an existing database, most modeling tools support reverse engineering of various databases.
3. Review the data model
time to value realization. support costs. Data Model Quality Validator (Data Model Scorecard). Assess correctness, completeness, consistency.
4. Maintain data model
Maintaining the data model: The data model needs to be kept up to date.
For the convenience of understanding, organize the mind map of this part as follows:
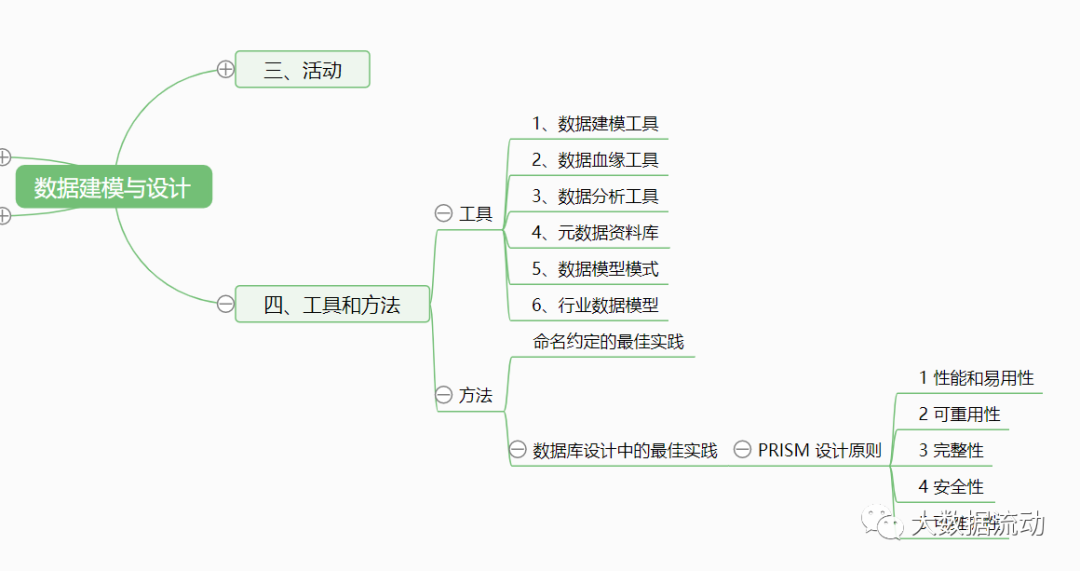
4. Tools and methods
【tool】
1. Data modeling tools
2. Data lineage tools
3. Data analysis tools
4. Metadata database
5. Data model mode
6. Industry data model
【method】
1. Best practices for naming conventions
2. Best practices in database design
Best Practices in Database Design - PRISM Design Principles: 1 Performance and Ease of Use. 2 Reusability. 3 Integrity. 4 Security. 5 maintainability.
For the convenience of understanding, organize the mind map of this part as follows:
5. Data Modeling and Design Governance
1. Data modeling and design quality management
【Development of data modeling and design standards】
1. A list and description of standard data modeling and database design deliverables.
2. A list of standard names, acceptable abbreviations, and abbreviation rules for uncommon words that apply to all data model objects.
3. A list of standard naming formats for all data model objects, including attributes and classifiers.
4. A list and description of the standard methods used to create and maintain these deliverables.
5. A list and description of data modeling and database design roles and responsibilities.
6. A list and description of all metadata attributes captured in data modeling and database design, including business and technical metadata
7. Metadata quality expectations and requirements.
8. Guidelines on how to use data modeling tools.
9. Guidelines for preparing and leading design reviews.
10. Data Model Versioning Guidelines.
11. A list of things that are prohibited or to be avoided.
【Review data model and database design quality】
【Manage data model version and integration】
Why. Why the project or situation needs to change.
What. What to change and how.
When. Time for change approval.
Who. who made the changes.
Where. The location where the change was made.
2. Metrics
Metrics:
1. To what extent does the model reflect the business needs?
2. How complete is the model? (Requirement Integrity. Metadata Integrity)
3. How well does the model match the schema?
4. How is the structure of the model?
5. How general is the model?
6. How well does the model follow the naming standard?
7. How readable is the model?
8. How is the model defined? (clear/complete/accurate)
9. How consistent is the model with the enterprise data architecture?
10. How well does it match the metadata
For the convenience of understanding, organize the mind map of this part as follows:

To be continued~
I also organized a CDMP self-study exchange group here, only for students who want to learn data governance and students who intend to take the CDMP certification exam .
(Because more than 200 people cannot enter directly, if you need to enter, please add my WeChat invitation to enter and note CDMP )
My own self-control is too weak, so I chose to enroll in a DAMA official training class. The training class will provide a complete video explanation course, as well as teaching materials and handouts, online Q&A, exam registration and other services. Students who are interested in studying with the class can also contact me, and fans of the big data official account can contact me to apply for discounts.
Recommendation of Popular Articles on Big Data Flow
Big Data Data Governance | WeChat Exchange Group~
What exactly is CDMP - a super-comprehensive introduction to the international certification of data governance
Open Source Data Quality Solutions - Apache Griffin Getting Started
One-stop Metadata Governance Platform - Datahub Getting Started
Pre-research on data quality management tools - Griffin VS Deequ VS Great expectations VS Qualitis
Thousand-character long text - Datahub offline installation manual
Metadata Management Platform Datahub2022 Annual Review
Big data flow: big data, real-time computing, data governance, and data visualization practice self-media. Regularly publish data governance and metadata management implementation technology practice articles, and share relevant technologies and materials for data governance implementation implementation.
Provide learning exchange groups such as big data introduction, data governance, Superset, Atlas, Datahub, etc.
Big data flows, and the learning of big data technology will never stop.
Long press, identify the QR code, follow us!