Table of contents
1. Introduction to MHA
1. What is MHA
- MHA (MasterHigh Availability) is an excellent set of software for failover and master-slave replication in MySQL high availability environment
- The emergence of MHA is to solve the problem of MySQL single point
- During the MySQL failover process, MHA can automatically complete the failover operation within 0-30 seconds
- MHA can ensure data consistency to the greatest extent during the failover process to achieve high availability in the true sense
2. Composition of MHA
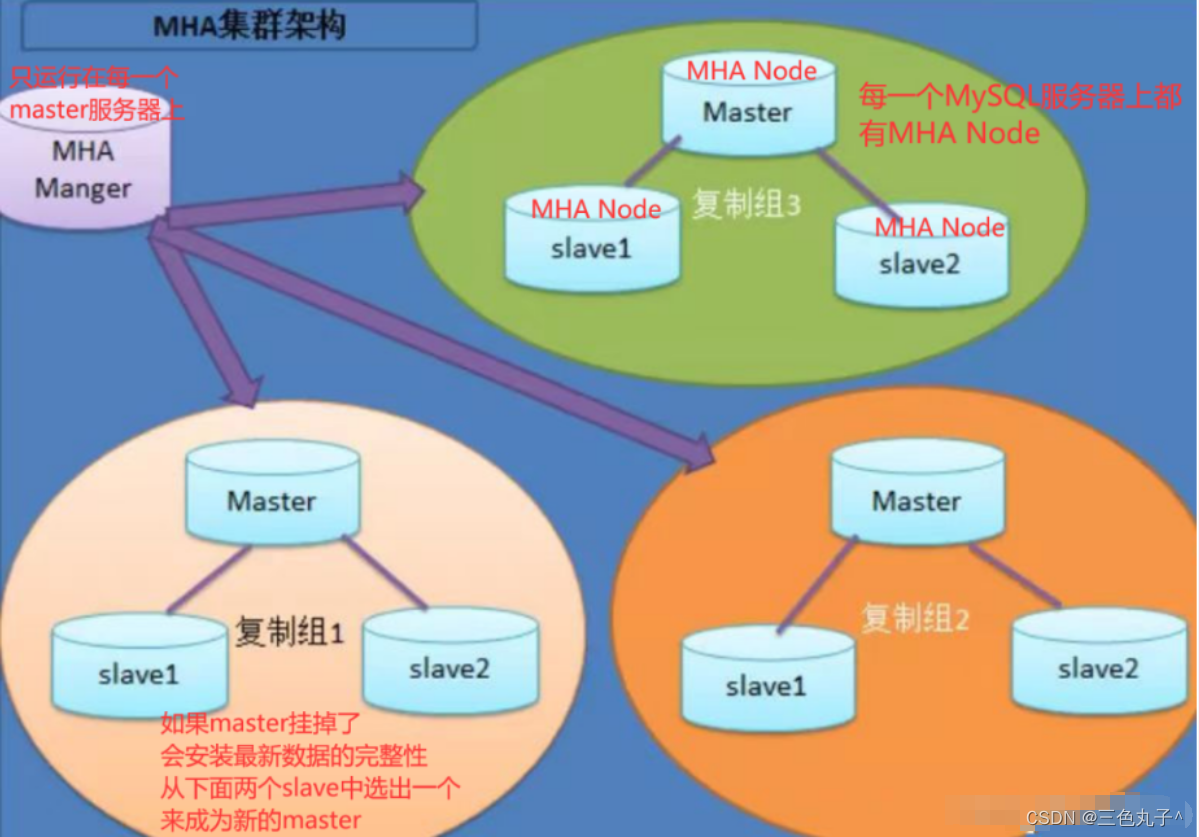
- MHA Node (data node)
- MHA Node runs on each MySQL server
- MHA Manager (management node)
- MHA Manager can be deployed on an independent machine to manage multiple master-slave clusters; it can also be deployed on a slave node
- MHA Manager will regularly detect the master node in the cluster. When the master fails, it can automatically promote the slave with the latest data to the new master, and then redirect all other slaves to the new master. The entire failover process is completely transparent to the application
3. Features of MHA
- During the automatic failover process, MHA tries to save the binary log from the downtime master server to ensure that the data is not lost to the greatest extent
- Using semi-synchronous replication can greatly reduce the risk of data loss. If only one slave has received the latest binary log, MHA can apply the latest binary log to all other slave servers, thus ensuring the data consistency of all nodes
- At present, MHA supports one master and multiple slave architecture, at least three servers, that is, one master and two slaves
4. Schematic diagram of MHA
2. Build MySQL's MHA High Availability
1. Experiment ideas
1.MHA架构
1)数据库安装
2)一主两从
3)MHA搭建
2.故障模拟
1)主库失效
2)备选主库成为主库
3)原故障主库恢复重新加入到MHA成为从库
MHA manager 节点服务器:CentOS7.4(64 位) manager/192.168.154.14 ,安装MHA node 和 manager 组件
Master 节点服务器:CentOS7.4(64 位) mysql1/192.168.154.11 ,安装mysql5.7、MHA node 组件
Slave1 节点服务器:CentOS7.4(64 位) mysql2/192.168.154.12 ,安装mysql5.7、MHA node 组件
Slave2 节点服务器:CentOS7.4(64 位) mysql3/192.168.154.13 ,安装mysql5.7、MHA node 组件
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
2. Experiment
- Modify the hostnames of Master, Slave1, and Slave2 nodes
hostnamectl set-hostname mysql1
hostnamectl set-hostname mysql2
hostnamectl set-hostname mysql3
- Modify the Mysql master configuration file /etc/my.cnf of the Master, Slave1, and Slave2 nodes
##Master 节点##
vim /etc/my.cnf
[mysqld]
server-id = 1
log_bin = mysql-bin
binlog_format = mixed
log-slave-updates = true
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
systemctl restart mysqld
##Slave1、Slave2 节点##
vim /etc/my.cnf
server-id = 2 #三台服务器的 server-id 不能一样
log_bin = mysql-bin
binlog_format = mixed
log-slave-updates = true
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
systemctl restart mysqld
- Create two soft links on the Master, Slave1, and Slave2 nodes
ln -s /usr/local/mysql/bin/mysql /usr/sbin/
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
- Configure mysql one master and two slaves
(1)所有数据库节点进行 mysql 授权
mysql -uroot -p
grant replication slave on *.* to 'myslave'@'192.168.154.%' identified by '123'; #从数据库同步使用
grant all privileges on *.* to 'mha'@'192.168.154.%' identified by 'manager'; #manager 使用
grant all privileges on *.* to 'mha'@'mysql1' identified by 'manager'; #防止从库通过主机名连接不上主库
grant all privileges on *.* to 'mha'@'mysql2' identified by 'manager';
grant all privileges on *.* to 'mha'@'mysql3' identified by 'manager';
flush privileges;
(2)在 Master 节点查看二进制文件和同步点
show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 1215 | | | |
+-------------------+----------+--------------+------------------+-------------------+
(3)在 Slave1、Slave2 节点执行同步操作
change master to master_host='192.168.154.11',master_user='myslave',master_password='123',master_log_file='mysql-bin.000001',master_log_pos=1215;
start slave;
(4)在 Slave1、Slave2 节点查看数据同步结果
show slave status\G
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
(5)两个从库必须设置为只读模式:
set global read_only=1;
(6)插入数据测试数据库同步
##在 Master 主库插入条数据,测试是否同步##
create database test_db;
use test_db;
create table test(id int);
insert into test(id) values (1);
- Install MHA software
(1)所有服务器上都安装 MHA 依赖的环境,首先安装 epel 源
yum install epel-release --nogpgcheck -y
yum install -y perl-DBD-MySQL \
perl-Config-Tiny \
perl-Log-Dispatch \
perl-Parallel-ForkManager \
perl-ExtUtils-CBuilder \
perl-ExtUtils-MakeMaker \
perl-CPAN
(2)安装 MHA 软件包,先在所有服务器上必须先安装 node 组件
对于每个操作系统版本不一样,这里 CentOS7.4 必须选择 0.57 版本。
在所有服务器上必须先安装 node 组件,最后在 MHA-manager 节点上安装 manager 组件,因为 manager 依赖 node 组件。
cd /opt
tar zxvf mha4mysql-node-0.57.tar.gz
cd mha4mysql-node-0.57
perl Makefile.PL
make && make install
(3)在 MHA manager 节点上安装 manager 组件
cd /opt
tar zxvf mha4mysql-manager-0.57.tar.gz
cd mha4mysql-manager-0.57
perl Makefile.PL
make && make install
After the manager component is installed, several tools will be generated under /usr/local/bin, mainly including the following:
- masterha_check_ssh Check the SSH configuration status of MHA
- masterha_check_repl check MySQL replication status
- masterha_manger script to start the manager
- masterha_check_status detects the current MHA running status
- masterha_master_monitor detects whether the master is down
- masterha_master_switch controls failover (automatic or manual)
- masterha_conf_host Add or delete configured server information
- masterha_stop closes the manager
After the #node component is installed, several scripts will be generated under /usr/local/bin (these tools are usually triggered by the script of MHAManager, no manual operation is required), mainly as follows:
- save_binary_logs save and copy master's binary log
- apply_diff_relay_logs identifies differential relay log events and applies their differential events to other slaves
- filter_mysqlbinlog removes unnecessary ROLLBACK events (MHA no longer uses this tool)
- purge_relay_logs purges relay logs (does not block SQL thread)
- Configure passwordless authentication on all servers
(1)在 manager 节点上配置到所有数据库节点的无密码认证
ssh-keygen -t rsa #一路按回车键
ssh-copy-id 192.168.154.11
ssh-copy-id 192.168.154.12
ssh-copy-id 192.168.154.13
(2)在 mysql1 上配置到数据库节点 mysql2 和 mysql3 的无密码认证
ssh-keygen -t rsa
ssh-copy-id 192.168.154.12
ssh-copy-id 192.168.154.13
(3)在 mysql2 上配置到数据库节点 mysql1 和 mysql3 的无密码认证
ssh-keygen -t rsa
ssh-copy-id 192.168.154.11
ssh-copy-id 192.168.154.13
(4)在 mysql3 上配置到数据库节点 mysql1 和 mysql2 的无密码认证
ssh-keygen -t rsa
ssh-copy-id 192.168.154.11
ssh-copy-id 192.168.154.12
- Configure MHA on the manager node
1)在 manager 节点上复制相关脚本到/usr/local/bin 目录
cp -rp /opt/mha4mysql-manager-0.57/samples/scripts /usr/local/bin
//After copying, there will be four executable files
/usr/local/bin/scripts/
- master_ip_failover #Script for VIP management during automatic switching
- master_ip_online_change # VIP management when switching online
- power_manager #Script to shut down the host after a failure occurs
- send_report #Script to send alarm after failover
(2)复制上述的自动切换时 VIP 管理的脚本到 /usr/local/bin 目录,这里使用master_ip_failover脚本来管理 VIP 和故障切换
cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin
(3)修改内容如下:(删除原有内容,直接复制并修改vip相关参数。可在拷贝前输入 :set paste 解决vim粘贴乱序问题)
vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#############################添加内容部分#########################################
my $vip = '192.168.154.200'; #指定vip的地址
my $brdc = '192.168.154.255'; #指定vip的广播地址
my $ifdev = 'ens33'; #指定vip绑定的网卡
my $key = '1'; #指定vip绑定的虚拟网卡序列号
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; #代表此变量值为ifconfig ens33:1 192.168.154.200
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; #代表此变量值为ifconfig ens33:1 192.168.154.200 down
my $exit_code = 0; #指定退出状态码为0
#my $ssh_start_vip = "/usr/sbin/ip addr add $vip/24 brd $brdc dev $ifdev label $ifdev:$key;/usr/sbin/arping -q -A -c 1 -I $ifdev $vip;iptables -F;";
#my $ssh_stop_vip = "/usr/sbin/ip addr del $vip/24 dev $ifdev label $ifdev:$key";
##################################################################################
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
## A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
(4)创建 MHA 软件目录并拷贝配置文件,这里使用app1.cnf配置文件来管理 mysql 节点服务器
#创建相关目录(所有节点)
mkdir -p /opt/mysql-mha/mha-node
# manager节点
mkdir -p /opt/mysql-mha/mha
#编写配置文件
vim /opt/mysql-mha/mysql_mha.cnf
[server default]
manager_log=/opt/mysql-mha/manager.log #指定manager日志路径
manager_workdir=/opt/mysql-mha/mha #指定manager工作目录
master_binlog_dir=/usr/local/mysql/data #指定master保存binlog的位置,这里的路径要与master里配置的binlog的路径一致,以便MHA能找到
master_ip_failover_script=/usr/local/bin/master_ip_failover #设置自动failover时候的切换脚本,也就是上面的那个脚本
master_ip_online_change_script=/usr/local/bin/master_ip_online_change #设置手动切换时候的切换脚本
user=mha #设置mha访问数据库的账号
password=manager #设置mha访问数据库的账号密码
ping_interval=1 #设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
remote_workdir=/opt/mysql-mha/mha-node #指定mha在远程节点上的工作目录
repl_user=myslave #设置主从复制的用户
repl_password=123 #设置主从复制的用户密码
report_script=/usr/local/send_report #设置发生故障切换的时候发送邮件提醒
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.154.12 -s 192.168.154.13 #指定检查的从服务器IP地址
shutdown_script="" #设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机防止发生脑裂,这里没有使用)
ssh_user=root #设置ssh的登录用户名
[server1]
hostname=192.168.154.11
port=3306
[server2]
hostname=192.168.154.12
port=3306
candidate_master=1
#设置为候选master,设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个从库不是集群中最新的slave
check_repl_delay=0
#默认情况下如果一个slave落后master 超过100M的relay logs的话,MHA将不会选择该slave作为一个新的master, 因为对于这个slave的恢复需要花费很长时间;通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=192.168.154.13
port=3306
- The first configuration needs to manually open the virtual IP on the Master node
/sbin/ifconfig ens33:1 192.168.154.200/24
- Test the ssh passwordless authentication on the manager node. If it is normal, it will output successfully at last, as shown below.
masterha_check_ssh -conf=/opt/mysql-mha/mysql_mha.cnf
Tue Nov 26 23:09:45 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Nov 26 23:09:45 2020 - [info] Reading application default configuration from /opt/mysql-mha/mysql_mha.cnf..
Tue Nov 26 23:09:45 2020 - [info] Reading server configuration from /opt/mysql-mha/mysql_mha.cnf..
Tue Nov 26 23:09:45 2020 - [info] Starting SSH connection tests..
Tue Nov 26 23:09:46 2020 - [debug]
Tue Nov 26 23:09:45 2020 - [debug] Connecting via SSH from [email protected](192.168.154.12:22) to [email protected](192.168.80.12:22)..
Tue Nov 26 23:09:46 2020 - [debug] ok.
Tue Nov 26 23:09:47 2020 - [debug]
Tue Nov 26 23:09:46 2020 - [debug] Connecting via SSH from [email protected](192.168.154.13:22) to [email protected](192.168.80.11:22)..
Tue Nov 26 23:09:47 2020 - [debug] ok.
Tue Nov 26 23:09:47 2020 - [info] All SSH connection tests passed successfully.
- Test the master-slave connection of mysql on the manager node, and the words MySQL Replication Health is OK appear at the end, indicating that it is normal. As follows.
masterha_check_repl-conf=/opt/mysql-mha/mysql_mha.cnf
Tue Nov 26 23:10:29 2020 - [info] Slaves settings check done.
Tue Nov 26 23:10:29 2020 - [info]
192.168.80.11(192.168.154.12:3306) (current master)
+--192.168.80.12(192.168.154.13:3306)
Tue Nov 26 23:10:29 2020 - [info] Checking replication health on 192.168.154.13..
Tue Nov 26 23:10:29 2020 - [info] ok.
Tue Nov 26 23:10:29 2020 - [info] Checking master_ip_failover_script status:
Tue Nov 26 23:10:29 2020 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.80.11 --orig_master_ip=192.168.80.11 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig ens33:1 down==/sbin/ifconfig ens33:1 192.168.154.200===
Checking the Status of the script.. OK
Tue Nov 26 23:10:29 2020 - [info] OK.
Tue Nov 26 23:10:29 2020 - [warning] shutdown_script is not defined.
Tue Nov 26 23:10:29 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
- Start MHA on the manager node
nohup masterha_manager \
--conf=/opt/mysql-mha/mysql_mha.cnf \
--remove_dead_master_conf \
--ignore_last_failover < /dev/null > /var/log/mha_manager.log 2>&1 &
- remove_dead_master_conf: This parameter means that when the master-slave switch occurs, the ip of the old master library will be removed from the configuration file.
- ignore_last_failover: By default, if MHA detects continuous downtimes and the interval between two downtimes is less than 8 hours, Failover will not be performed. The reason for this limitation is to avoid the ping-pong effect. This parameter means to ignore the files generated by the last MHA trigger switchover. By default, after the MHA switchover, it will be recorded in the app1.failover.complete log file. If the file exists in the directory when the switchover occurs next time, it will not be allowed Trigger switchover, unless the file is deleted after the first switchover, for convenience, here is set to –ignore_last_failover.
- Use & to run the program in the background: the result will be output to the terminal; use Ctrl+C to send the SIGINT signal, the program is immune; close the session and send the SIGHUP signal, the program is closed.
- Use nohup to run the program: the result will be output to nohup.out by default; use Ctrl+C to send the SIGINT signal, and the program will close; close the session and send the SIGHUP signal, and the program will be immune.
- Use nohup and & to start the program nohup ./test &: Simultaneously immune to SIGINT and SIGHUP signals.
- Check the MHA status, you can see that the current master is the mysql1 node.
masterha_check_status --conf=/opt/mysql-mha/mysql_mha.cnf
- Check the MHA log to see that the current master is 192.168.154.11, as shown below.
cat /opt/mysql-mha/manager.log | grep "current master"
- Check whether the VIP address 192.168.154.200 of mysql1 exists. This VIP address will not disappear because the manager node stops the MHA service.
ifconfig
//若要关闭 manager 服务,可以使用如下命令。
masterha_stop --conf=/opt/mysql-mha/mysql_mha.cnf
或者可以直接采用 kill 进程 ID 的方式关闭。
3. Fault simulation
#在 manager 节点上监控观察日志记录
tail -f /opt/mysql-mha/manager.log
#在 Master 节点 mysql1 上停止mysql服务
systemctl stop mysqld
或
pkill -9 mysql
#正常自动切换一次后,MHA 进程会退出。HMA 会自动修改 app1.cnf 文件内容,将宕机的 mysql1 节点删除。查看 mysql2 是否接管 VIP
ifconfig
Algorithm for failover of the standby master library:
- Generally, the slave library is judged from (position/GTID) to judge whether it is good or bad, and the data is different. The slave closest to the master becomes the candidate master.
- If the data is consistent, select an alternative main library according to the order of the configuration files.
- Set the weight (candidate_master=1), and the candidate master is forced to be designated according to the weight.
- By default, if a slave lags behind the master's relay logs by 100M, it will fail even if it has weight.
- If check_repl_delay=0, even if there are many logs behind, it is forced to be selected as the alternate master.
Troubleshooting steps:
- repair mysql
systemctl restart mysqld
- repair master-slave
#在现主库服务器 mysql2 查看二进制文件和同步点
show master status;
#在原主库服务器 mysql1 执行同步操作
change master to master_host='192.168.154.12',master_user='myslave',master_password='123',master_log_file='mysql-bin.000001',master_log_pos=1745;
start slave;
- Modify the configuration file app1.cnf on the manager node (add this record, because it will disappear automatically when it detects the failure)
vi /etc/masterha/app1.cnf
......
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.154.11 -s 192.168.80.13
......
[server1]
hostname=192.168.154.12
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=192.168.154.11
port=3306
[server3]
hostname=192.168.154.13
port=3306
- Start MHA on the manager node
nohup masterha_manager \
--conf=/opt/mysql-mha/mysql_mha.cnf \
--remove_dead_master_conf \
--ignore_last_failover < /dev/null > /var/log/mha_manager.log 2>&1 &
#解决中英字不兼容报错的问题
dos2unix /usr/local/bin/master_ip_failover