regular expressions, shell scripts
1. Regular expression
1. What is a regular expression?
Simply put, a regular expression is a set of rules and methods defined for processing a large number of strings. With the assistance of these defined special symbols, the system administrator can quickly filter, replace or output the desired string. Linux regular expressions are generally processed in units of lines.
2. Why do we need to learn regular expressions
In enterprise work, in the linux operation and maintenance work we do every day, we will always face a large number of text configurations, programs, command output and log files with strings, and we often have There is an urgent need to find a specific string that meets the needs of the work from a large number of string content, which depends on regular expressions. Therefore, it can be said that regular expressions are born to meet the needs of filtering such strings!
Commonly used commands grep (egrep) sed awk or regular expression function ()
. Represents and can only represent any character (excluding blank lines)
- Repeat any preceding 0 or more characters
. * Matches all characters. (Including blank lines)
Use \1 to take out the results in parentheses of the previous regular match and operate them later.
^ means what to start with, ^bqh starts with bqh
what $ ends with
^$ means a blank line.
\ Example. It only represents the dot itself, the escape symbol, let the character with a special identity move, take off the vest, restore the original $ ^
.* starts with any number of characters.
. $ Ends with any number of characters.
(. ) Matches from the first character to a space,
[abc] matches any character in the character set [a-zA-Z]
[^abc] matches the content of any character that does not include the following; the brackets are Negate, pay attention to the difference between starting with....
a{n,m} Repeat n to m times, the previous repeated character. If useful egrep/sed -r can remove the slash.
{n,} Repeat at least n times, the previous repeated character. If useful egrep/sed -r can remove the slash.
{n} Repeat n times, the previous repeated character. If useful egrep/sed -r can remove the slash.
①^word search starts with word; vi ^ starts a line;
②word$ searches for word ends; vi $ starts a line;
③^$ indicates a blank line.
- Repeat one or more preceding characters
? Repeat 0 or a character in front of 0
| Use or to find multiple matching strings
() Find the "user group" string
^ Match the beginning of a line, but depends on the context, may be represented in a regular expression Negate the meaning of a character set
[…] Match any character in the set such as "[xyz]" Match the character x, y, or z
[^...] Match any character that does not belong to the set
^, $ Match the beginning and end of the line
<, > is used to denote word boundaries. < matches the beginning of the word, > the end of the word, such as "<the>" matches the word "the"
... regular expression grouping. It is very useful to use together for substring extraction.
\n The nth group content
\ escapes (escapes) a special character, so that this character represents the original literal meaning. "$" represents the original literal meaning "$", not the meaning of matching the end of the line expressed in the regular expression. "\" is also interpreted as the literal meaning "" { } indicates that the previous regular expression
matches The number of times.
The escape is because the curly braces just mean their literal meaning if they are not escaped. This usage is only technical and not the content of the basic regular expression. "[0-9]{5}" Exact match 5 digits (numbers from 0 to 9).
| "or", the regularization operator is used to match an optional set of characters
{n} n is a non-negative integer. Match determined n times. For example, ''o{2}'' would not match the ''o'' in "Bob", but would match the two o's in "food".
{n,} n is a non-negative integer. Match at least n times. For example, ''o{2,}'' would not match 'o'' in "Bob", but would match all o's in "foooood". ''o{1,}'' is equivalent to ''o+''. ''o{0,}'' is equivalent to ''o*''.
{n,m} Both m and n are non-negative integers, where n<=m. Match at least n times and at most m times. For example, "o{1,3}" will match the first three o's in "fooooood". ''o{0, 1}'' is equivalent to ''o?''. Note that there can be no spaces between the comma and the two numbers.
\b matches a word boundary, that is, the position between a word and a space. For example, ''er\b'' would match ''er'' in "never", but not ''er'' in "verb".
\B matches a non-word boundary. ''er\B'' matches ''er'' in "verb", but not ''er'' in "never". \w matches
any word character including underscore. Equivalent to ''[A-Za-z0-9_]''.
\W matches any non-word character. Equivalent to ''[^A-Za-z0-9_]''.
\d matches a single digit character. Equivalent to [0-9].
\D matches a non-digit character. Equivalent to [^0-9].
\f matches a form feed character. Equivalent to \x0c and \cL.
\n matches a newline character. Equivalent to \x0a and \cJ.
\r matches a carriage return. Equivalent to \x0d and \cM.
\s matches any whitespace character, including spaces, tabs, form feeds, and so on. Equivalent to [\f\n\r\t\v].
\S matches any non-whitespace character. Equivalent to [^\f\n\r\t\v].
\t matches a tab character. Equivalent to \x09 and \cI.
\v matches a vertical tab character. Equivalent to \x0b and \cK.
Some commonly used metacharacters are introduced here first.
awk

sed
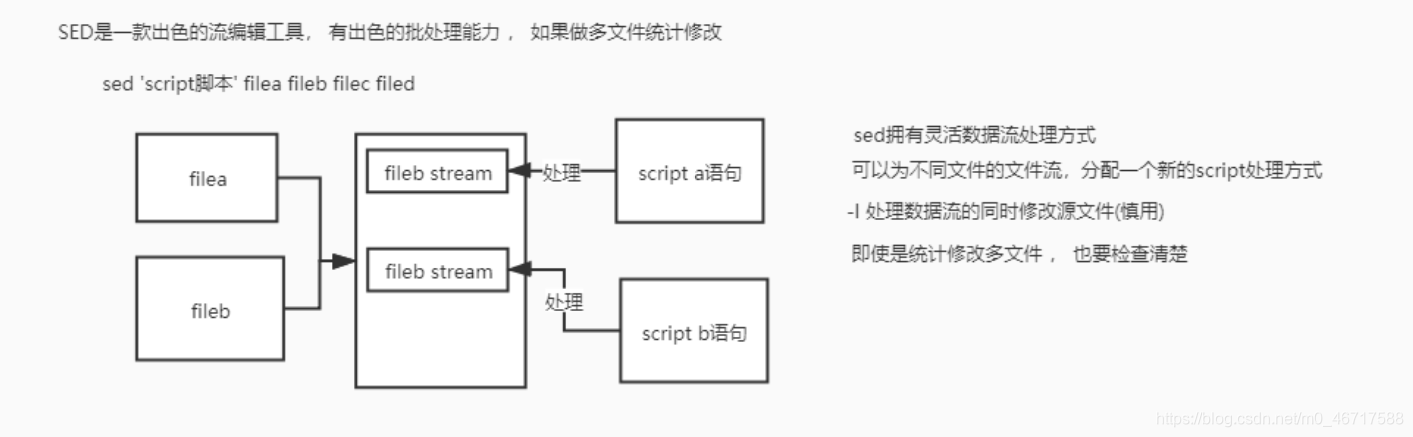
Regex regular function
Standard linux c and c++ do not support regular expressions;
use the Regex series functions in the POSIX function library to illustrate how to use regular expressions under Linux c:
1. Compile regular expressions:
Regcomp function to generate regex_t Data structure;
int Regcomp(regex_t *preg, const char *regex, int cflags);
parameter description:
preg: used to save the compilation result;
regex: string, representing the compiled regular expression;
cflags: compilation switch control details ;
REG_EXTEND means to use the extended regular expression mode;
REG_ICASE means to make the string in the rule case-insensitive;
REG_NOSUB only checks whether there is a substring that meets the rule
2. Match regular expressions:
use the data structure regex_t *preg generated by regcomp to call the regexec() function to complete pattern matching:
int regexec(
const regex_t *preg,
const char *string,
size_t match,
regmatch_t pmatch[],
int eflags
);
typedef struct { regoff_t rm_so; regoff_t rm_eo; } regmatch_t; Parameter description: preg: used for the compiled pattern matching data structure regex_t constant; string: string, indicating the matched string; nmatch: the number of matches; ( ) number of brackets + 1 sub-matching string + parent matching string pmatch: matching result array; rm_so indicates the starting offset of the substring satisfying the rule in the string rm_eo indicates the subsequent offset of the substring satisfying the rule in the string eflags: Whether the matching feature REG_NOTBOL is the first line REG_NOTEOL is the last line 3. Report error information
size_t regerror(int errcode, const regex_t *preg, char *errbuf, size_t errbuf_size);
parameter description:
errcode: error code from regcomp and regexec functions;
preg: regcomp compilation result;
errbuf: buffer error message string;
errbuf_size : The length of the error message string in the buffer area;
4. Release the regular expression:
void regfree(regex_t *preg);
no return result, release the regex_t pointer compiled by regcomp;
5. Regular expression framework:
int mymatch(char *buf)
{ const char regex = “href=”[^ >] ""; regex_t preg; const size_t nmatch = 10; regmatch_t pm[nmatch]; if ( regcomp(&preg , regex, 0) != 0) { /*Failed to compile regular expression*/ perror("regcomp"); exit(1); } int z, i; z = regexec(&preg, buf, nmatch, pm, 0 ); if (z == REG_NOMATCH)/*no match*/ { return 0; } else/*matched hyperlink*/ { for (i = 0; i < nmatch && pm[i].rm_so != -1; ++i)/ Extract all hyperlinks / { / Operation on matching links / }
}
regfree(&preg);/*释放正则表达式*/
}
Shell
is an application that connects users and the Linux kernel, allowing users to use the Linux kernel more efficiently, safely, and at low cost. This is the essence of Shell.
Shell itself is not a part of the kernel, it is just an application program written on the basis of the kernel, it is no different from other software such as QQ, Thunder, Firefox, etc. However, the Shell also has its particularity, that is, it starts up immediately after booting and presents it to the user; the user uses the Linux through the Shell, and if the Shell is not started, the user cannot use Linux.
How does the shell connect the user and the kernel?
Shell can receive the command input by the user, process the command, and then feedback the result to the user after processing, such as outputting to the display, writing to a file, etc. This is what most readers know about Shell. You see, I have been using the Shell, how can I use the kernel? I don't see Shell linking me to the kernel? !
In fact, the functions of the Shell program itself are very weak, such as file operations, input and output, process management, etc. all have to rely on the kernel. When we run a command, in most cases, the shell will call the interface exposed by the kernel, which is to use the kernel, but this process is hidden by the shell, which runs silently behind the scenes, and we cannot see it.
The interface is actually a function one by one, and using the kernel is to call these functions. Is that all there is to using the kernel? um, yes! Apart from functions, you have no other way to use the kernel.
For example, we all know that you can view the contents of the log.txt file by entering the cat log.txt command in the Shell. However, where is the log.txt placed on the disk? Divided into several data blocks? where to start Where does it end? How to operate the probe to read it? The shell doesn't know these low-level details, it can only call the open() and read() functions provided by the kernel, tell the kernel that I want to read the log.txt file, please help me, and then the kernel will obediently follow the instructions of the shell Go read the file, and give the read file content to the Shell, and finally the Shell presents it to the user (in fact, it depends on the kernel to present it on the display). In the whole process, Shell is a "middleman", which "sells" data between the user and the kernel, but the user does not know it.
The shell can also connect to other programs
. Some commands entered in the shell are built-in commands of the shell itself, which are called built-in commands; some are other applications (a program is a command), which are called external commands.
The shell itself does not support many commands and its functions are limited, but the shell can call other programs, and each program is a command, which makes the number of shell commands infinitely expandable. As a result, the shell is very powerful and fully capable of Daily management of Linux, such as text or string retrieval, file search or creation, automatic deployment of large-scale software, changing system settings, monitoring server performance, sending alarm emails, crawling web content, compressing files, etc.
What's even more surprising is that Shell can also connect multiple external programs to easily transfer data between them, that is, the output of one program is passed to another program as input.
The powerful Shell that everyone says is not that the Shell itself is rich in functions, but that it is good at using and organizing other programs. Shell is a leader, and that's the beauty of Shell.
The position of the Shell in the entire Linux system can be described as shown in the figure below. Note that "user" and "other applications" are connected by a dotted line, because the user directly faces the shell after starting Linux, and other applications can only be run through the shell.
Shell also supports programming
Shell is not simply stacking commands, we can also program in Shell, and
also supports basic programming elements, such as:
if...else selection structure, case...in switch statement, for, while, until loop;
variables , arrays, strings, comments, addition, subtraction, multiplication, division, logic operations and other concepts;
functions, including user-defined functions and built-in functions (such as printf, export, eval, etc.).
From this perspective, Shell is also a programming language, and its compiler (interpreter) is the program Shell. The Shell we usually refer to sometimes refers to the program that connects the user and the kernel, and sometimes refers to Shell programming.
Shell is mainly used to develop some practical and automated gadgets, not to develop medium and large-scale software with complex business logic, such as detecting hardware parameters of computers, building a web operating environment, log analysis, etc., Shell is very suitable.
Shell is a scripting language.
Any code must be "translated" into binary form before it can be executed in the computer.
Some programming languages, such as C/C++, Pascal, Go language, assembly, etc., must translate all codes into binary form before the program runs, that is, generate executable files, and what the user gets is the final generated executable file , can not see the source code.
This process is called Compile. A programming language like this is called a compiled language, and the software that completes the compilation process is called a Compiler.
However, some programming languages, such as Shell, JavaScript, Python, PHP, etc., need to be translated while executing, and will not generate any executable files. Users must obtain the source code to run the program. After the program is running, it will be translated immediately, and part of the translation will be executed, without waiting for all the code to be translated.
This process is called interpretation, such a programming language is called an interpreted language or scripting language (Script), and the software that completes the interpretation process is called an interpreter.
The advantages of compiled languages are fast execution speed, low hardware requirements, and good confidentiality. They are suitable for developing operating systems, large-scale applications, and databases.
The advantages of the scripting language are flexible use, easy deployment, and good cross-platform performance, which is very suitable for Web development and the production of small tools.
Shell is a scripting language. After we write the source code, we don't need to compile it, just run the source code directly.
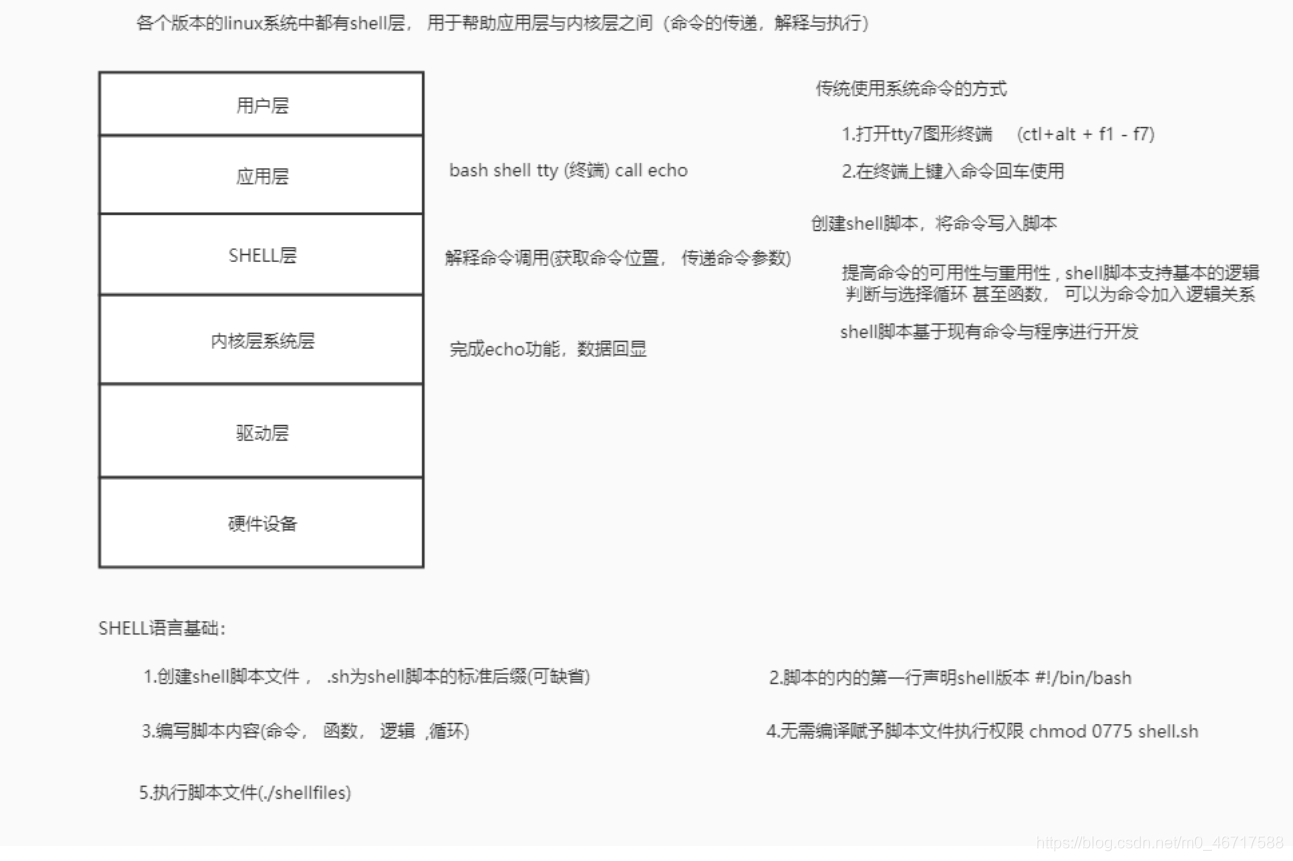
The specific content is introduced in detail at http://c.biancheng.net/view/706.html. (but some are paid)