table of Contents
One, sort command
- Sort the contents of the file by row, or according to different data types
Syntax format:
sort [选项] 参数
cat file | sort 选项
| Common options | Features |
|---|---|
| -f | Ignore case |
| -b | Ignore leading blank space |
| -M | Sort by three-character month |
| -n | Sort by number |
| -r | Reverse sort |
| -u | Equivalent to uniq, which means that only one row of the same data is displayed |
| -t | Specify the field separator, use [Tab] to separate by default |
| -k | Specify sort field |
| -o <output file> | Export the sorted results to the specified file |
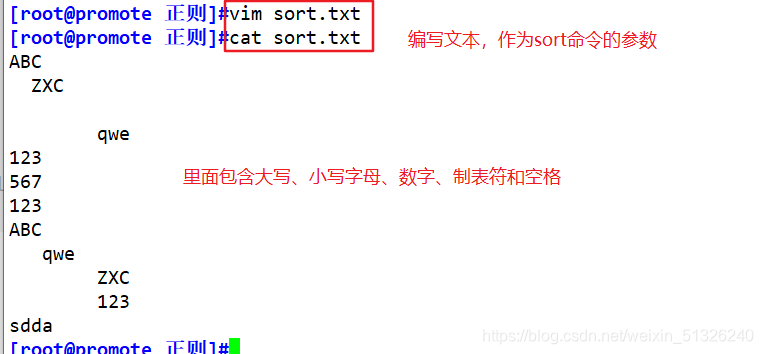

According to local variables, if the local environment variables are not the same, the sorting may also be different




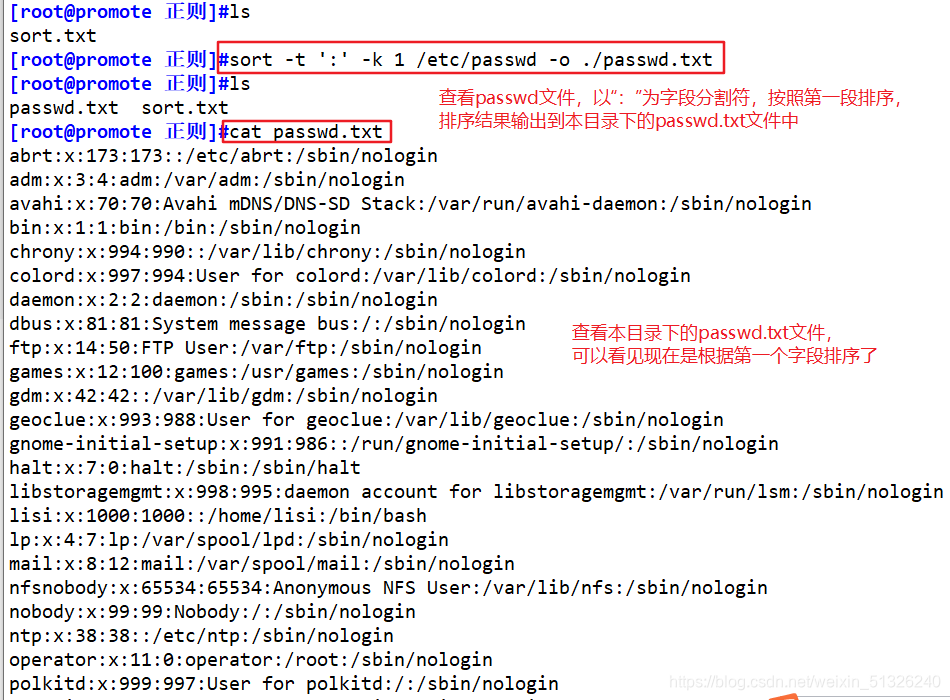
sort -t ':' -k 1 /etc/passwd -o ./passwd.txt
du -ah | sort -nr -o du.txt

Two, uniq command
- Used to report or ignore consecutive repeated lines in a file, often combined with the sort command
Syntax format:
uniq [选项] 参数
cat file | uniq 选项
| Common options | Features |
|---|---|
| -c | Count and delete repeated lines in the file |
| -d | Show only duplicate rows |
| -u | Show only lines that occur once |

Three, tr command
- Commonly used to replace, compress and delete characters from standard input
Syntax format:
tr [选项] [参数]
| Common options | effect |
|---|---|
| -c | Characters in character set 1 are reserved, and other characters (including newline \n) are replaced with character set 2 |
| -d | Delete all characters belonging to character set 1 |
| -s | Compress repetitive strings into one string; replace character set 1 with character set 2 |
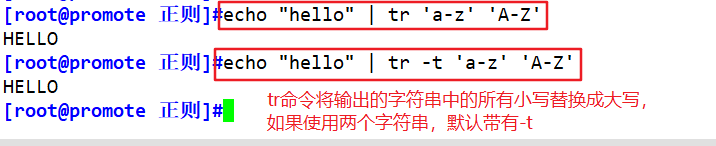
| -t | Character set 2 replaces character set 1, and the result is the same without options. |
| parameter | effect |
|---|---|
| Character set 1 | Specify the original character set to be converted or deleted. When performing a conversion operation, you must use the parameter "Character Set 2" to specify the target character set for conversion. But when executing the delete operation, the parameter "Character Set 2" is not required; |
| Character set 2 | Specify the target character set to be converted. |
echo "hello" | tr 'a-z' 'A-Z'
echo "hello" | tr 'a-z' -t 'A-Z'
echo abccabacca | tr -c "ab\n" "0"

echo "abcdefg" | tr -d "de"

echo "abbcccddddaaaaa" | tr -s "abcd"

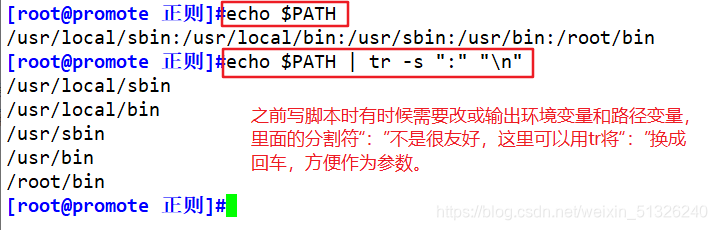
Replace the colon ":" in the path variable with a newline character "\n"
echo $PATH | tr -s ":" "\n"
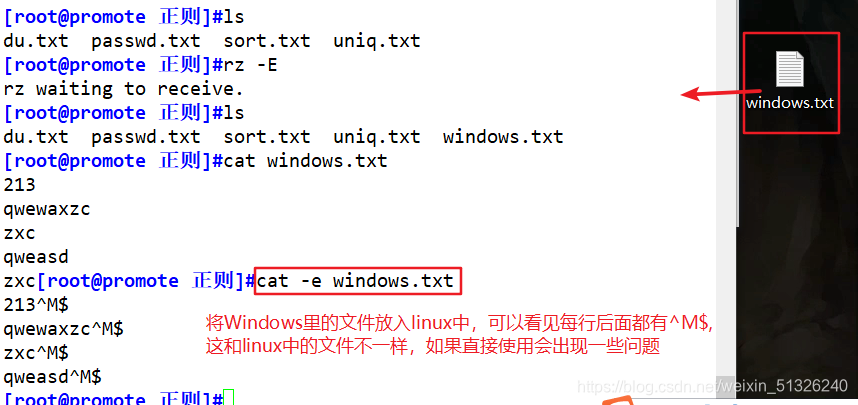
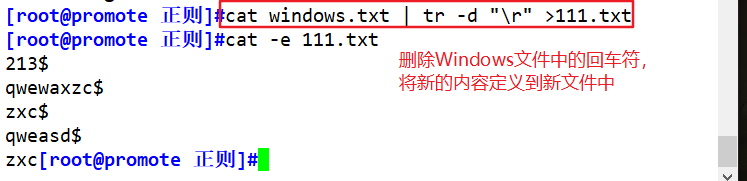
- Delete the "^M" character "caused" in Windows files
cat file | tr -s "\r" "\n" > new_file
或
cat file | tr -d "\r" > new_file
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作。
而windows中要回车符+换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。

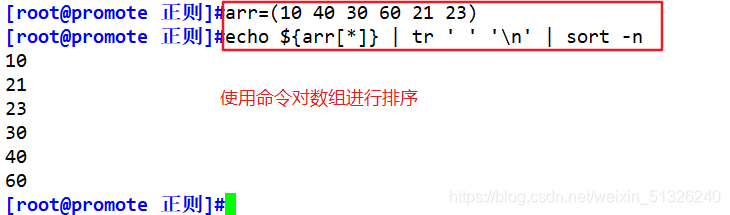
- Array sort
echo ${arr[*]} | tr ' ' '\n' | sort -n
Four, regular expressions (important)
- Usually used in judgment sentences to check whether a string meets a certain format
- Regular expression is composed of ordinary characters and metacharacters
- Common characters include uppercase and lowercase letters, numbers, punctuation marks and some other symbols
- Metacharacters refer to special characters with special meaning in regular expressions. They can be used to specify the appearance of the leading character (the character before the metacharacter) in the target object
(1) Basic regular expression
- Supported tools: grep, egrep, sed, awk
基础正则表达式常见元字符:
\ :转义字符,用于取消特殊符号的含义,例:\!、\n、\$等
^ :匹配字符串开始的位置,例:^a、^the、^#、^[a-z]
$ :匹配字符串结束的位置,例:word$、^$匹配空行
. :匹配除\n之外的任意的一个字符,例:go.d、g..d
* :匹配前面子表达式0次或者多次,例:goo*d、go.*d
[list] :匹配list列表中的一个字符,例:go[ola]d,[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字
[^list] :匹配任意非list列表中的一个字符,例:[^0-9]、[^A-Z0-9]、[^a-z]匹配任意一位非小写字母
\{
n\} :匹配前面的子表达式n次,例:go\{
2\}d、'[0-9]\{2\}'匹配两位数字
\{
n,\} :匹配前面的子表达式不少于n次,例:go\{
2,\}d、'[0-9]\{2,\}'匹配两位及两位以上数字
\{
n,m\} :匹配前面的子表达式n到m次,例:go\{
2,3\}d、'[0-9]\{2,3\}'匹配两位到三位数字
注:egrep、awk使用{
n}、{
n,}、{
n,m}匹配时“{
}”前不用加“\”
(2) Extended regular expression
- Supported tools: egrep, awk
扩展正则表达式元字符:
+ :匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、goood等
? :匹配前面子表达式0次或者1次,例:go?d,将匹配gd或god
() :将括号中的字符串作为一个整体,例1:g(oo)+d,将匹配oo整体1次以上,如good、gooood等
| :以或的方式匹配字条串,例:g(oo|la)d,将匹配good或者glad
(3) Use regular expressions
Here are two examples to demonstrate, the main thing is to see yourself understand and then use
- Match mobile phone numbers starting with 139
#以139开头,后面随机8位数字组合
"^139[0-9]{8}$"
egrep "^139[0-9]{8}$" shoujihao.txt
grep "^139[0-9]\{8\}$" shoujihao.txt

- Match E-mail address
用户名@ :^([a-zA-Z0-9_\-\.\+]+)@
子域名 :([a-zA-Z0-9_\-\.]+)
.顶级域名(字符串长度一般在2到5) :\.([a-zA-Z]\{
2,5\})$
egrep '^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$' email.txt
awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' email.txt
