Using some features of 4D millimeter wave radar, it can be accurately classified. Here, the number of points, distance, azimuth, length, and width are used as features, and the length and width are calculated by projecting the point cloud onto the orientation direction after estimating the orientation of the target.
Training uses python's sklearn, just import it directly
from sklearn.tree import DecisionTreeClassifierMore than 80,000 sets of data from three categories (cars, carts, and bicycles) are used here, 80% of which are used as training sets and 20% are used as test sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)Then call the function to train
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)Validate on the test set after training
y_train_pred = decision_tree.predict(X_train)
y_test_pred = decision_tree.predict(X_test)Validation accuracy
from sklearn.metrics import accuracy_score
print('decision tree train accurary socre:', accuracy_score(y_train, y_train_pred), 'test accurary socre:', accuracy_score(y_test, y_test_pred))
train_error_score = 1 - accuracy_score(y_train, y_train_pred)
test_error_score = 1 - accuracy_score(y_test, y_test_pred)
print('decision tree train error socre:', train_error_score, 'test error socre:', test_error_score)
If the default parameters are used, the accuracy of the training set is 100%, and the accuracy of the test set is 95%.
![]()
Obtain the depth of the decision tree, and found that there are 33 layers, and the number of leaves is 2179, which is too large
tree_depth = decision_tree.get_depth()
tree_leaves = decision_tree.get_n_leaves()
print('depth',tree_depth,',leaves:',tree_leaves)Call the decision tree visualization tool, you can see the result, because there are too many leaf trees, only small dots can be seen in full screen display

Zoom in to 100% to see details
 There is a risk of overfitting with so many layers and leaf trees, and the implementation code is also very complicated, so consider reducing the number of layers
There is a risk of overfitting with so many layers and leaf trees, and the implementation code is also very complicated, so consider reducing the number of layers
decision_tree = DecisionTreeClassifier(max_depth=9) When the decision tree model is generated, the maximum depth is set to 9, then the volume of the final generated decision tree is greatly reduced, the number of layers of the measured results is 9, and the number of leaf trees is 230.

The accuracy of the training set has decreased, but the test set has improved, indicating that overfitting has been reduced and generalization performance has been improved.
![]()
After the model is generated, it takes a lot of effort to write the code. Here, refer to the blogger's method and use the code to automatically generate it. However, there is a small problem with the python script, and you need to find out and modify it yourself to get the final result.
The m2cgen library can also be used to convert the model to c code. For details, please refer to m2cgen · PyPI
import m2cgen as m2c
code = m2c.export_to_c(decision_tree)
file = open('radar_tree_m2cgen_code.txt','w')
file.write(code)
file.close()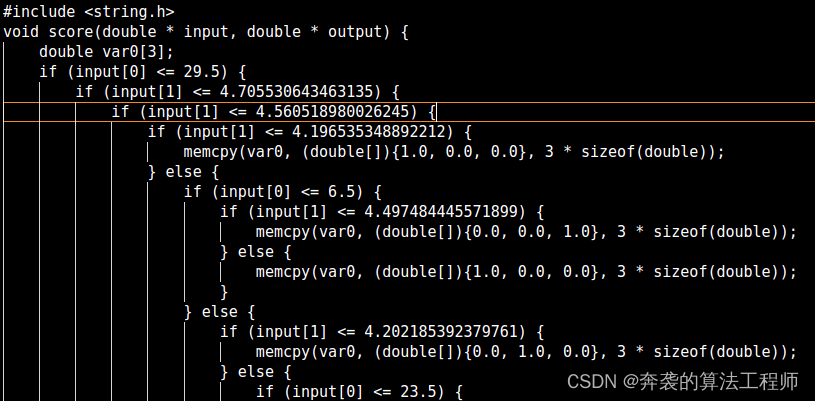
If you are not satisfied with the effect, you can use different feature combinations to conduct comparative experiments to obtain the desired results.