Algorithm special Hash, BitMap, Set, Bloom filter, Chinese word segmentation, Lucene inverted index
Hash
think:
- Give you N (1<N<10) natural numbers, and the range of each number is (1~100). Now let you judge whether a certain number is within these N numbers at the fastest speed, and you must not use the packaged class. How to achieve it
- Give you N (1<N<10) natural numbers, and the range of each number is (1~10000000000). Now let you judge whether a certain number is within these N numbers at the fastest speed, and you must not use the packaged class, how to achieve it. A[] = new int[N+1]?
hash table
The hash table is Hash Table in English, which is what we often call the hash table. You must have heard it often. In fact, the example we just mentioned above is solved by using the idea of the hash table.
The hash table uses the feature that the array supports random access to data according to the subscript. 散列表其实就是数组的一种扩展,由数组演化而来。It can be said that if there is no array, there will be no hash table
In fact, this example has already used the idea of hashing. In this example, N is a natural number and forms a one-to-one mapping with the subscript of the array, so the feature of random access based on the subscript of the array is used
The time complexity of the search is O(1), which can quickly determine whether the element exists in the sequence
Hash conflict
Open addressing: The core idea of the open addressing method is that if there is a hash collision, we will re-detect a free location and insert it
When we insert data into the hash table, if a certain data is hashed by the hash function and the storage location is already occupied, we start from the current location and search backwards one by one to see if there is a free location until we find it. .
shortcoming:
- Deletion requires special handling
- If too much data is inserted, it will cause many conflicts in the hash table. The search may degenerate into traversal
Link address: use a linked list, the linked list method is a more commonly used hash conflict resolution method, which is much simpler than the open addressing method
Linked list optimization of HashMap Hash conflict
Since the structure of the linked list does have some shortcomings, it has been optimized in our JDK and a more efficient data structure has been introduced:
red black tree
-
Initial size: The default initial size of HashMap is 16. This default value can be set. If you know the approximate data volume in advance, you can reduce the number of dynamic expansions by modifying the default initial size, which will greatly improve the performance of HashMap.
-
Dynamic expansion: the maximum loading factor is 0.75 by default. When the number of elements in the HashMap exceeds
0.75*capacity(capacity indicates the capacity of the hash table), the expansion will start, and each expansion will expand to twice the original size -
Hash conflict resolution: JDK1.7 uses the linked list method at the bottom. In the JDK1.8 version, in order to further optimize the HashMap, we introduced a red-black tree. And when the length of the linked list is too long (default exceeds 8), the linked list is converted into a red-black tree. We can use the characteristics of red-black tree to quickly add, delete, modify and check to improve the performance of HashMap. When the number of red-black tree nodes is less than 8, the red-black tree will be converted into a linked list. Because in the case of a small amount of data, the red-black tree needs to maintain balance, and the performance advantage is not obvious compared with the linked list.
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小,最好使用2的整数倍
}
Design an efficient enterprise-level hash table
Here you can learn from the design ideas of HashMap:
- It must be efficient: that is, insertion, deletion and lookup must be fast
- Memory: Do not take up too much memory, consider using other structures, such as B+Tree, HashMap 1 billion, algorithm for storing hard disk: mysql B+tree
- Hash function: This should be considered according to the actual situation.%
- Expansion: It is to estimate the size of the data. The default space of HashMap is 16? I know I need to save 10000 numbers,
2^n > 10000 or 2^n-1 - How to solve the Hash conflict: linked list array
Hash application
- Encryption: MD5 hash algorithm, irreversible
- Determine whether the video is repeated
- similarity detection
- load balancing
- Distributed sub-database and sub-table
- distributed storage
- Lookup Algorithm HashMap
Problems with Hash expansion algorithm in multithreading
- Multi-threaded put operation, get will infinite loop (). This can indeed be optimized. For example, when expanding capacity, we open a new array instead of using the shared array.
- Multi-threaded put may cause get value error
Why is there an infinite loop?
- When there is a hash conflict, we will use a chain structure to save the conflicting value. If we are traversing the linked list itself like this 1->2->3->null
- If we traverse to 3 itself, it should be null. At this time, someone just calculated the value of this null, null => 1->3, and this is over. The original 3 was supposed to point to the end of null, and now it changes again. Cheng points to 1, and this 1 just points to 3, so it will continue to loop
BitMap
Scenes
- Data weight judgment
- Sort without repeating data
shortcoming
- data cannot be repeated
- There is no advantage when the amount of data is small
- Unable to handle string hash collisions
Thinking: How to judge whether a certain number exists among 300 million integers (0~200 million)? Memory limit 500M, one machine
- Divide:
- Bloom Filters: Artifacts
- Redis
- Hash: Open 300 million spaces, HashMap (200 million)?
- Arrays: age question; data[200000000]?
- Bit: bitMap, bitmap;
Type basis: the smallest memory unit in computing is bit, which can only represent 0, 1
- 1Byte = 8bit
- 1int = 4byte 32bit
- Float = 4byte 32bit
- Long=8byte 64bit
- Char 2byte 16bit
Int a = 1, how is this 1 stored in the calculation?
0000 0000 0000 0000 0000 0000 0000 0001 toBinaryString (1) =1
operator base
shift left<<
8 << 2 = 8 * (2 ** 2) = 8 * 4 = 328 << 1 = 8 * (2 ** 1) = 8 * 2 = 16
0000 0000 0000 0000 0000 0000 0000 1000
<< 2
0000 0000 0000 0000 0000 0000 0010 0000
Move right>>
8 >> 2 = 8 / (2 ** 2) = 8 / 4 = 28 >> 1 = 8 / (2 ** 1) = 8 / 2 = 4
0000 0000 0000 0000 0000 0000 0000 1000
>> 2
0000 0000 0000 0000 0000 0000 0000 0010
bit and &
8 & 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 0000 = 0
bit or |
8 | 7
0000 0000 0000 0000 0000 0000 0000 1000 = 8
&
0000 0000 0000 0000 0000 0000 0000 0111 = 7
=
0000 0000 0000 0000 0000 0000 0000 1111 = 23 + 22 + 21 + 20 = 8+4+2+1=15
BitMap
An int occupies 32 bits. If we use the value of each of the 32 bits to represent a number, can it represent 32 numbers, that is to say, 32 numbers only need the space occupied by an int, and it can be done in an instant Reduce the space by 32 times
For example, suppose we have the largest number of N{2, 3, 64} MAX, then we only need to open int[MAX/32+1]an int array to store the data. For details, see the following structure:
Int a : 0000 0000 0000 0000 0000 0000 0000 0000Here are 32 positions, we can use 0 or 1 in each position to indicate whether the number in this position exists, so we can get the following storage structure:
Data[0]: 0~31 32位
Data[1]: 32~63 32位
Data[2]: 64~95 32位
Data[MAX / 32+1]
/**
* 解决:
* 1. 数据去重
* 2. 对没有重复的数据排序
* 3. 根据1和2扩展其他应用,比如不重复的数,统计数据
* 缺点: 数据不能重复、字符串hash冲突、数据跨多比较大的也不适合
*
* 求解2亿个数,判断某个数是否存在
*
* 最大的数是64 data[64/32] = 3
* data[0] 0000 0000 0000 0000 0000 0000 0000 0000 0~31
* data[1] 0000 0000 0000 0000 0000 0000 0000 0000 32~63
* data[2] 0000 0000 0000 0000 0000 0000 0000 0000 64~95
*
* 数字 2 65 2亿分别位置
* 2/32=0 说明放在data[0]数组位置, 2%32=2说明放在数组第3个位置
* 65/32=2 说明放在data[2]数组位置, 65%32=1说明放在数组第2个位置
*
* 2亿=M
* 开2亿个数组 2亿*4(byte) / 1024 /1024 = 762M
* 如果用BitMap: 2亿*4(byte)/32 / 1024 /1024 = 762/32 = 23M (int数组)
* 判断66是否存在 66/32=2 -> 66%32=2 -> data[2]里面找第三个位置是否是1
*/
public class BitMap {
byte[] bits; //如果是byte那就是只能存8个数
int max; //最大的那个数
public BitMap(int max) {
this.max = max;
this.bits = new byte[(max >> 3) + 1]; // max / 8 + 1
}
public void add(int n) {
//添加数字
int bitsIndex = n >> 3; // 除8就可以知道在哪一个byte
int loc = n % 8; // n % 8 与运算可以标识求余 n & 8
//接下来要把bit数组里面bitsIndex下标的byte里面第loc个bit位置设置为1
// 0000 0100
// 0000 1000
// 或运算(|)
// 0000 1100
bits[bitsIndex] |= 1 << loc;
}
public boolean find(int n) {
int bitsIndex = n >> 3;
int loc = n % 8;
int flag = bits[bitsIndex] & (1 << loc);
if (flag == 0) {
return false; //不存在
} else {
return true; //存在
}
}
public static void main(String[] args) {
BitMap bitMap = new BitMap(100);
bitMap.add(2);
bitMap.add(3);
bitMap.add(65);
bitMap.add(64);
bitMap.add(99);
System.out.println(bitMap.find(2));
System.out.println(bitMap.find(5));
System.out.println(bitMap.find(64));
}
}
Set
Comparison of various containers
- List:
Objects can be stored repeatedly.
The order of insertion and the order of traversal are consistent. Common
implementation methods: linked list + array (ArrayList, LinkedList, Vector) - Set:
Duplicate objects are not allowed.
The order of insertion and output of each element cannot be guaranteed, an unordered container.
TreeSet is ordered and commonly
used implementation methods: HashSet, TreeSet, LinkedHashSet (forced to ensure that the output order and insertion order are consistent, doubly linked list, consuming space) - Map:
Map is stored in the form of key-value pairs, and there will be key+value:
Map does not allow the same key to appear, and it will overwrite
Map. sequence, its underlying structure is also a red-black tree)
Bloom filter (if it does not exist, it must not exist)
Implemented ideas:
- Insertion: Use K hash functions to perform k calculations on an inserted element, and set the subscript of the bit array corresponding to the obtained Hash value to 1
- Search: The same as insertion, use k functions to perform k calculations on the searched elements, find out the corresponding bit array subscript for the obtained value, and judge whether it is 1, if they are all 1, it means that the value may be in the sequence , otherwise it is definitely not in the sequence
Why is it possible in sequence? There is a false positive rate
- Delete: Tell you very clearly that this thing does not support deletion
/**
* 应用场景 -- 允许一定误差率 0.1%
* 1. 爬虫
* 2. 缓存击穿 小数据量用hash或id可以用bitmap
* 3. 垃圾邮件过滤
* 4. 秒杀系统
* 5. hbase.get
*/
public class BloomFilter {
private int size;
private BitSet bitSet;
public BloomFilter(int size) {
this.size = size;
bitSet = new BitSet(size);
}
public void add(String key) {
bitSet.set(hash_1(key), true);
bitSet.set(hash_2(key), true);
bitSet.set(hash_3(key), true);
}
public boolean find(String key) {
if (bitSet.get(hash_1(key)) == false)
return false;
if (bitSet.get(hash_2(key)) == false)
return false;
if (bitSet.get(hash_3(key)) == false)
return false;
return true;
}
public int hash_1(String key) {
int hash = 0;
for (int i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return hash % size;
}
public int hash_2(String key) {
int p = 16777169;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.length()) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash) % size;
}
public int hash_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash) % size;
}
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter(Integer.MAX_VALUE);//21亿/8/1024/1024=250M
System.out.println(bloomFilter.hash_1("1"));
System.out.println(bloomFilter.hash_2("1"));
System.out.println(bloomFilter.hash_3("1"));
bloomFilter.add("1111");
bloomFilter.add("1112");
bloomFilter.add("1113");
System.out.println(bloomFilter.find("1"));
System.out.println(bloomFilter.find("1112"));
}
}
Google Guava Test
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId> <!-- google bloomfilter 布隆过滤器 -->
<version>22.0</version>
</dependency>
public class GoogleGuavaBloomFilterTest {
public static void main(String[] args) {
int dataSize = 1000000; //插入的数据N
double fpp = 0.001; //0.1% 误判率
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), dataSize, fpp);
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
//测试误判率
int t = 0;
for (int i = 2000000; i < 3000000; i++) {
if (bloomFilter.mightContain(i)) {
t++;
}
}
System.out.println("误判个数:" + t);
}
}
Chinese participle
Trie tree
-
What is a Trie tree: The trie tree is what we usually call a dictionary tree. It is a data structure specially used to process string matching. It is especially suitable for quickly finding a specific string among many strings. prefix tree, huffman tree, prefix encoding
-
Trie data structure: Suppose we have the following English words: my name apple age sex, if we want to find out whether a certain string exists, how do you find it? Using the common prefix of the string, the repeated ones are combined to form a tree, which is the trie tree we are talking about
-
The construction of the Trie tree: We need to divide the word into letters one by one, and then insert them into the tree in turn. As shown on the right, the root node root, if we want to insert the app,
first divide the app into: a, p, p, and then start from the root point, inserting layer by layer, note that
P will be hung under a, behind A p of will hang on the previous p. At the end of the word we will use purple.
It should be noted here that the letters of each layer are in order when we insert them. -
Trie's search:
To search we start from the root point, then find the first letter on the first layer, and then find the word we want in turn.
Note that the search of a word is completed only when the mark at the end is found. For example, app, we are looking for ap.
Although there is ap in the dictionary tree, but this p is not purple, then ap does not exist in the dictionary tree. -
Implementation of Trie tree: Trie tree is a multi-fork tree. Here we should think of B+Tree&B-Tree, which are somewhat similar.
The Trie tree cleverly uses the subscript of the array, because there are exactly 26 English letters, so we can open a 26-length array
A[] = new int[26];
A[0] = 'a' => the subscript is 'a'-97, which is just right here It is 0, using ascii calculation.
So its data structure should be
class TrieNode {
Char c;//存储当前这个字符
TrieNode child[26] = new TrieNode[];//存储这个字符的子节点
}
- Analysis of Trie tree:
- Time complexity: very efficient O(length of word)
- Space complexity: A data structure that trades space for efficiency. Because each word theoretically has 26 child nodes, its space complexity is 26^n, where n represents the height of the tree.
- optimization:
- Repeated letters do not repeat
- Because we have opened 26 spaces for each node to store nodes. But the actual situation may not need so many, so here we can actually consider using a hash table to implement it. Here you can
go to the source code of IK. When there are few child nodes, it is an array, but it is used when there are more than 3 nodes. hashMap, this can save a lot of space to a certain extent.
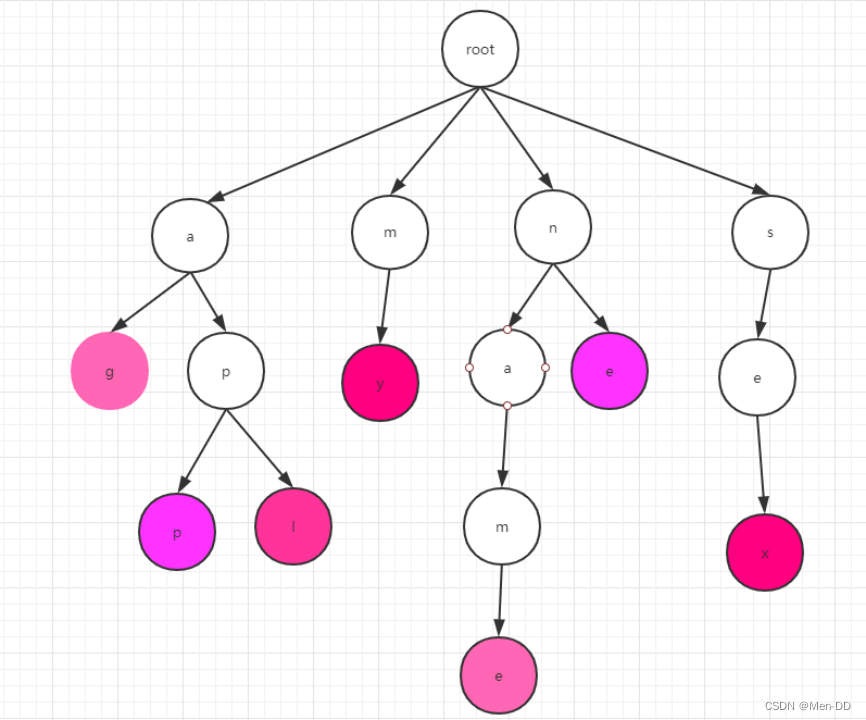
Chinese participle
-
The principle of word segmentation:
(1) English word segmentation: my name is WangLi
(2) Chinese word segmentation: I am Chinese -
Chinese word breaker IK
-
Special attention should be paid to Chinese word segmentation because it has two methods:
- Smart: Intelligent word segmentation, here will not separate all the situations of a sentence, for example, I am Chinese, it will be divided into me/is/Chinese
- The smallest particle (non-Smart): It will separate all the situations in a sentence, for example, if I am Chinese, it will be divided into I/Yes/China/Chinese/Chinese
-
Ambiguity in Chinese: using thesaurus, complex AI technology, machine learning algorithms, etc.
Wuhan Yangtze River Bridge- Wuhan City/Yangtze River Bridge
- Wuhan/Mayor/River Bridge
Lucene inverted index
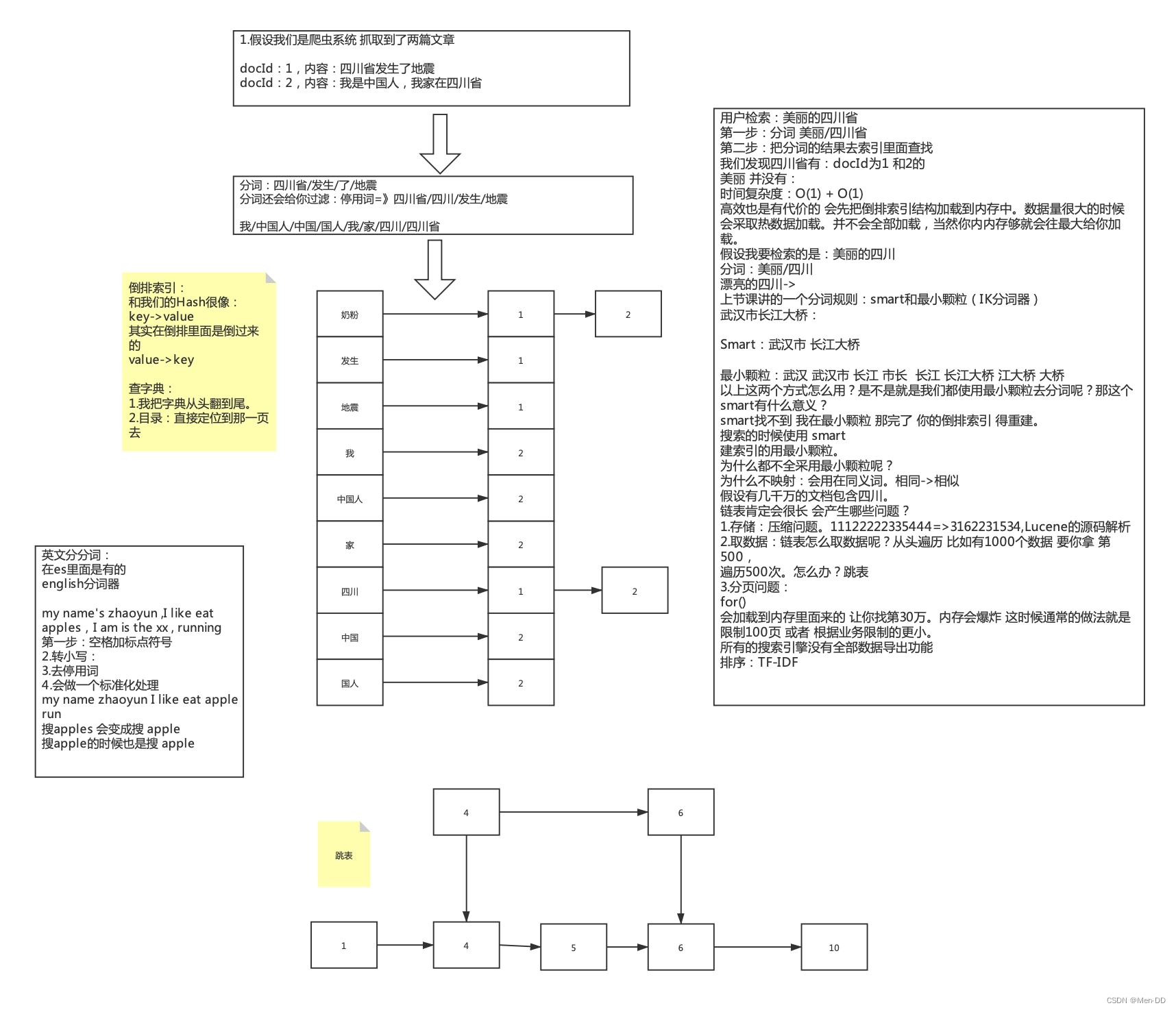
search engine
-
Data Structure: How many times the data structure appears in all documents. If there are 10 articles, data structures appear in all of them. Does it mean that there is no distinction
-
TF: Word Frequency How many words are included in a doc, the more it contains, the more relevant it is. Only count the number of documents
-
DF: The total number of documents whose document frequency contains this word, DF is counted once in a document
-
IDF: The inversion of DF is 1/DF; if there are fewer documents containing the word, that is, the smaller the DF and the larger the IDF, the greater the importance of the word to this document
-
TF-IDF: The main idea of TF*IDF is: if a word or phrase appears in an article with a high frequency of TF and rarely appears in other articles, it is considered that the word or phrase has a good category distinction ability, the higher the score of this article.
What is the problem? The length varies. An article has only 2 words. Searching for one of them is 50% of the weight. There is an article with 100 words and 48 words. -
Normalization processing: mainly for processing TF-IDF, according to the length of the article
-
Scoring custom bonus