table of Contents
Second, the advantages of hash tables.
3. Compare the hash table with the array.
Method 2: Multiplication of powers
Five, method two improvement-hashing
One: Chain address method (zipper method).
1. Linear detection method: linearly find blank places for storage.
4. Random detection and hashing.
Four: Establish a public overflow area
1. What is a hash table?
Copy the explanation of the hash table on Baidu Encyclopedia: hash table (Hash table, also called a hash table), is the basis of the key value (Key value) and direct access to the data structure . In other words, it accesses the record by mapping the key code value to a location in the table to speed up the search. This mapping function is called a hash function , and the array storing records is called a hash table .
Second, the advantages of hash tables.
- It can provide very fast insert-delete-search operations.
- Regardless of the amount of data, the time required to insert and delete values is close to a constant, that is , the time level of O(1) . In fact, it only takes a few machine instructions to complete.
- The speed of the hash table is faster than that of the tree , and the element you want to find can be found instantly.
- The principle of the hash table may be more complicated, but the code will be much easier to write.
3. Compare the hash table with the array.
- The data in the hash table is in no order
- Under normal circumstances, the key value in the hash table is not allowed to be repeated, and the same key value cannot be placed, so the same element cannot be stored.
- For arrays.
- When inserting, the efficiency is extremely low.
- If it is a search operation, if the search is based on the index, the efficiency is quite high, if it is not (such as searching based on the content), the efficiency is very low.
- The efficiency of the array deletion operation is also very low.
Hash table is based on array optimization (transformation of subscript values)
eg: If I now want to store the names of multiple people in an array, with their contact numbers. If I am looking for a contact phone number, I can quickly find it through the subscript value.

4. Data storage.
: For example, a word (string) is converted into a number and stored as a subscript value.
Method 1: Sum of ASCII codes
But there is a limitation here, because the string is composed of multiple characters, so to convert the string to the corresponding number, you need a corresponding function to convert it. We reduce it, the space is 0, a is, 1, b is 2, and so on. For example, give can be converted into a number: 7+9+22+5=43. But there is a new problem here: there are still many words with the same number corresponding to the give we converted, such as tin, was and so on.
The resulting small numbers will produce high-frequency repetitions.
Method 2: Multiplication of powers
The subscript value can be expressed by the continuous multiplication of powers:
For example: 5987 = 5 * 10^3 + 9 * 10^2 + 8 * 10 + 7
The above method can be used 7 * 27^3 + 9 * 27^2 + 22 * 27 + 5 = 144941 (which guarantees the uniqueness of the data to a large extent, that is, it will not be repeated with other words)
The large numbers obtained take up a lot of space and cause a lot of waste of space.
Five, method two improvement-hashing
For example, if you want to store 10,000 words, you may need to define an array with a length of 10,000, but in fact, a larger space is often needed to store these words, because we cannot have a word in every position, or There will be two or more words.
At this time, it is necessary to compress the excessively large numbers.
Hashing: The process of converting large numbers into subscripts within the array range
Hash function: The code to be implemented for hashing big numbers is placed in a function, and this function is the hash function.
Hash table: Insert elements into the array through a hash function, and the resulting structure is called a hash table.
Method: Take the remainder operator, the function is to get a remainder after being divisible by another number .
The concrete realization of the remainder operator:

Here is an example of compressing the numbers from 0 to 100 into 0 to 9 using the remainder of numbers and 10.
Problem: Even if the space is large and the number is large, the compression values obtained may be repeated. For example, 0 and 100, 25 and 35 in the above figure, their compression values are all 5, which creates a conflict.
6. Resolve conflicts
Conflicts are inevitable, and we can only resolve them. Even if the possibility of conflict is relatively small, we still need to consider this situation.
One: Chain address method (zipper method).


Inside the array is an array or a linked list.
The choice between an array or a linked list depends on the specific business choice. When a conflict occurs, if the position to be inserted is at the beginning, use a linked list; if you need to insert to the end, you can consider using an array or a linked list.
Two: Open address method.
1. Linear detection method: linearly find blank places for storage.


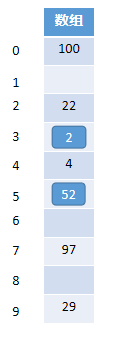
- Insertion for linear heuristics
The subscript value of the new element 2 in the figure after hashing is 2, and the corresponding position has the element 22. Therefore, element 2 adds 1 to its subscript value, finds the position where the subscript value is 3, and finds If there is no element, insert the element. When the element 52 needs to be inserted, its hashed subscript value is also 2, and then the next one is searched until it finds the position where the subscript value is 5.
- Search for linear heuristics
Find the existing element : when we want to find the element 52, we can use the hashed subscript value to find the corresponding position. If the current position is not 52, the subscript value is increased by 1 until the subscript value is 5 s position.
Find the element that does not exist: Then if we need to find the element 32, do we need to traverse the entire hash table at this time, of course not, because this is very inefficient, and also when we find the position where the subscript value is 5 , We add 1 to the subscript value and find that it is a blank position, then we can stop the search, because according to the insertion principle of the linear exploration method, the next 32 that needs to be stored should be stored in the position where the subscript value is 6. Now this The position is empty, indicating that the element 32 does not exist in the hash table.
Situation investigation : Now if we remove element 2, what should be set to the position where the subscript value is 3? If it is set to null, will it cause an error in the search?
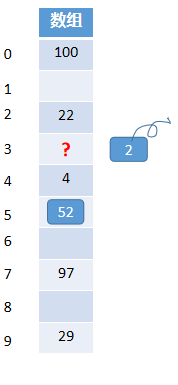
 Suppose the element 52 needs to be searched. When the position 3 is found, if it is set to null when deleting the element, it will stop according to the method just searched, but 52 does exist in the array. This involves the deletion operation of the linear heuristic.
Suppose the element 52 needs to be searched. When the position 3 is found, if it is set to null when deleting the element, it will stop according to the method just searched, but 52 does exist in the array. This involves the deletion operation of the linear heuristic.
- For the deletion of linear heuristics
Because setting it to null may affect other operations in the future, we usually need to be cautious when deleting data items in a position. At this time, the original position of the deleted element cannot be set to empty. We can perform special processing on it. , For example, it can be set to -1, in this case, there will be a distinction for searching in the future.
- The shortcomings of linear heuristics
For the following array that has stored several data

Store 31-32-33-34-35-36 in sequence, all of them will be stored in a continuous corresponding subscript value position, which means that there are elements at the position of subscript value 1-2-3-4-5-6. At 21 o'clock, it is necessary to explore multiple times to insert into the blank position. We call this series of filling units called aggregation . This aggregation phenomenon will affect the performance of the hash table, whether it is insertion, query or deletion. influences.
2. The second detection method, the first hashing produces a hash address conflict, and another hash function (hash function) is used to process the conflict result.
This method can be understood as an improvement to the linear detection method. Aiming at the aggregation phenomenon generated by the linear detection method, the method of adding 1 to the subscript value is no longer used for exploration, but the conflict result is processed through another hash function.

The main optimization of the second detection is the step length during detection. If the subscript value starts from x, then the linear detection will be: ![]() sequential detection, and the second detection is
sequential detection, and the second detection is ![]() , so that a relatively long distance can be detected at one time, thus This avoids the aggregation problem caused by this aspect. Expanded to find on both sides
, so that a relatively long distance can be detected at one time, thus This avoids the aggregation problem caused by this aspect. Expanded to find on both sides![]()
- Disadvantages of the second detection method
Any method will have its advantages and disadvantages. The second detection method can greatly improve the aggregation problem in the step size, but there will still be a situation when the above-mentioned inserted element is 11 or When it is 61, the results obtained by hashing them are all 1, so according to the second exploration, the positions to be explored will overlap, which increases the number of explorations in turn. That is to say, in this case, it will cause a kind of aggregation with different steps, and it will also affect the efficiency.
3. Re-hashing.
Solving the problems left over by the second detection, we can think of any way to make the hash function of the second hashing not fix a regular step every time?
Two requirements for secondary hashing:
- It is different from the first hash function because it will return to its original position.
- Can't output 0. In this case, the step length will be 0, which will make the next detection step in place, and the algorithm will enter an endless loop.
Then there is a formula: stepSize = constant-(key% constant) (where constant is a prime number and is less than the capacity of the array )
Re-hashing is to hash the keyword again with a different hash function, and use this result as the step size. For the specified keyword, the step size is constant during the detection process, which can be understood as Different keywords can use different step lengths , and the step length can be controlled.
4. Random detection and hashing.
di=Pseudo-random sequence
Three: Re- hashing method .
Hi=RHi(key),i=1,2,...,k RHi are all different hash functions, that is, when the synonym generates an address conflict, calculate the address of another hash function until the conflict no longer occurs. This method is not easy Produce "clustering", but increase the calculation time.
Four: Establish a public overflow area
When adding new data items, as long as the addresses obtained by the hash function conflict, they are all filled in the overflow table.