This article refers to the link of bilibili: The first systematic AI painting class of station B! Learn Stable Diffusion with zero foundation, this is definitely the easiest AI painting tutorial you have ever seen | SD WebUI Nanny Level Raiders_哔哩哔哩_bilibili
Table of contents
3. Weight distribution of prompt words
2. WebUI parameter description
3. InPaint partial redrawing and parameters
(4) Hypernetwork super network
2. Model classification and top model name
4. Tools for resolution magnification
5. AI painting entry-level extension plug-in
1. Chinese localization language pack
3. Prompt word auto-completion
6. Partial refinement and redrawing
7. Semantic segmentation of prompt words
8. Unlimited zoom animation video
3. Comparing five ControlNet models of manifolds
First, a few fun nouns:
Alchemy : Training AI to learn image generation model
Mantra : prompt prompt word
1. Prompt prompt words
1. Overview
Included content: the theme of the work, style of painting, image characteristics and some specific elements included
Grammatical rules for prompt words:
- Prompt words need to be written in English
- Prompt words take phrases as units
2. Prompt classification
(1) Characters and main characteristics
Clothing wear: white dress
Hair color: blonde hair, long hair
Features of facial features: small eyes, big mouth
Facial expression: smiling
Body movements: stretching arms
(2) Scene features
Indoor and outdoor: indoor / outdoor
Big scene: forest, city, street
Small details: tree, bush, white flower
(3) Ambient lighting
Day and night: day / night
Specific time period: morning, sunset
Light environment: sunlight, bright, dark
Sky: blue sky, starry sky
(4) Supplement: Frame Angle of View
Distance: close-up, distant
Character ratio: full body, upper body
Observation angle: from above, view of back
Lens type: wide angle, Sony A7 III
(5) Image quality
Universal HD:
Best quality the highest quality
Ultra-detailed super details
Masterpiece
Hires high resolution
8k 8k resolution
Specific high-resolution types:
Extremely detailed CG unity 8k wallpaper Ultra detailed 8K Unity game CG
Unreal engine rendered Unreal engine rendering
3. Weight distribution of prompt words
(1) Add numbers in brackets
(white flower:1.5) Adjust the weight of the white flower to 1.5 times the original (enhanced)
(white flower:0.8) Adjust the weight of the white flower to 0.8 times the original (weaken)
(2) Brackets
Parentheses: (((white flower))) One layer per set, extra *1.1 times
Braces: { { {white flower}}} One layer per set, extra *1.05 times
Square brackets: [[[white flower]]] One layer per set, extra *0.9 times
4. Reverse prompt word

It can identify the existing components of the image, and then summarize them into what is in the AI dictionary to help you describe something to AI more accurately.
DeepBooru and CLIP are two different image recognition algorithms, and DeepBooru has more advantages in speed and recognition accuracy.
5. Prompt word website
AI Drawing Prompt Word Generator - A Toolbox - All the useful online tools are here!

2. WebUI parameter description
1. Vincent graph parameters
(1) The number of sampling iteration steps: the number of denoising iterations, generally more than 20 times, the improvement will not be large
(2) Resolution: If the resolution is too large, there may be many people with multiple hands and feet. The resolution of the pictures used by AI in training is generally relatively small. If the resolution is too large, it will be considered as multiple pictures. The pictures are stitched together. If you need a high-resolution picture, first draw a 512*512 picture, and then perform high-definition restoration through "hires.fix".
(3) "restore faces" face repair, using some confrontational algorithms to identify and repair the faces of people.
(4) "Tiling" tiling, used to generate textured pictures that can seamlessly fill the entire screen
(5) Generate batches: In order to pursue a perfect picture, a set of prompt words may be used to generate multiple times. Through this function, multiple pictures can be generated at one time. It provides a preview of all pictures combined and each picture .
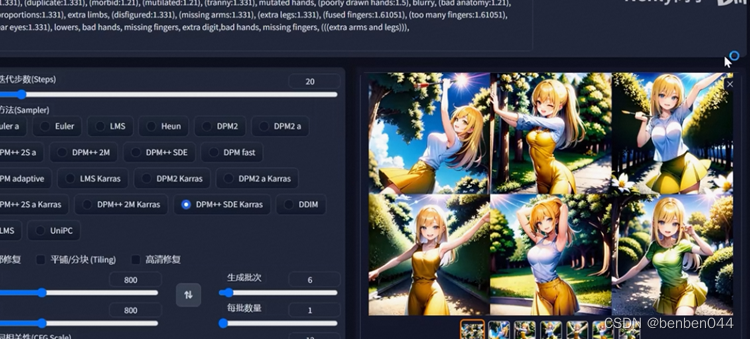
2. Graphic parameters
Denoising strength: the redrawing range, how much it resembles the weight of the original image
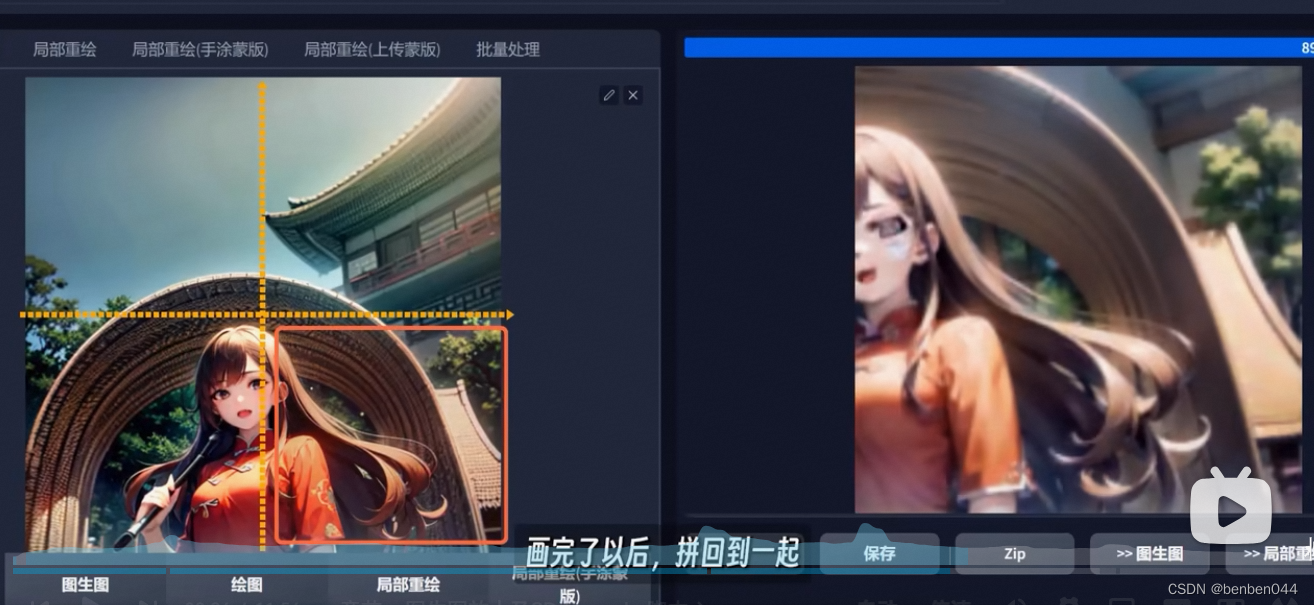
3. InPaint partial redrawing and parameters
It is like the correction fluid and correction tape we use when writing homework. It can cover and redraw a certain area in a large picture. It can not only correct mistakes, but also avoid tearing up the whole paper and redrawing it again.
It redraws the part by using the method of image generation, and then puts it back into the original image.
Mask: generally refers to some range objects used to limit the processing area. A plate that covers certain key areas.
Inpaint Sketch: Draw. The painted colored lines will simultaneously form a part of the picture and participate in the process of drawing the picture.

3. Model
1. Model type
Model download website: hugging face / civitai
(1) Large model
Checkpoint checkpoint or key point model, called ckpt large model, generally between 2~7GB
Safetensor is usually 1~2GB, and it is also a large model, which is specially developed by trainers to make the model more reliable and efficient
(2)Embeddings
Text embedding, corresponding to the Model type of station C is "Textual Inversion", that is, text inversion
Embeddings files are very small, generally dozens of KB
If checkpoint is a large dictionary, then Embeddings is like a small "bookmark" on it, which can accurately point to the meaning of individual words and words, thus providing an extremely efficient index.
Embeddings themselves do not contain information, just a markup.
Embeddings can point us to a specific image
The file suffix is pt, and after downloading, place it in the folder embeddings with the same name next to the models folder.
Embeddings do not require additional calls, only need to use a specific prompt in the prompt to call it
(3) LoRa: Low rank model
The role of LoRa is to convey and describe an image with accurate features and clear subjects to AI.
It is possible to make the AI learn something that does not exist in its world.
If embeddings are a bookmark, then Lora is a coloring page. It directly writes on the paper the characteristics of the image and how it can be presented.
The location of Lora is the Lora subfolder under models.
To use lora, just enter directly in the prompt box:

The minimum requirement for training a large model is to have more than 12G of video memory, but training a LoRA model may only require 8G or even lower. Conventional large models will occupy at least 2 G of storage space, but the largest LoRA model will not exceed 200M.
It needs to be used in conjunction with checkpoint to achieve "fine-tuning" of this checkpoint in some aspects.
(4) Hypernetwork super network
It can achieve the same effect as Lora.
It is possible to make the AI learn something that does not exist in its world.
Hypernetwork is generally used to improve the overall style of generated images. It is not necessary to use it, just use LORA directly later
2. Model classification and top model name

(1) Two-dimensional model
Anything V5: Graphic styles for anime, illustrations, character portraits, etc.
Counterfeit: Illustration-style model with high detail restoration
Dreamlike Diffusion: Comic illustration style model to create dreamlike and fantasy pictures and works
(2) Real system model
Deliberate: Super upgraded SD official model, very detailed and comprehensive realistic style
Realistic Vision: Simple and with a living space, used to make portraits, food, animal pictures, and make some fake news photos with a sense of reality
LOFI: Exquisite photo-level portrait model, with more refined facial processing than the previous two
(3) 2.5D style model
NeverEnding Dream: very suitable for "three-dimensional" 2.5D models, combined with Lora for secondary creation of anime and game characters
Photorealism: Excellent photo effects and room for creativity
Guofeng3: an exquisite model of national style to realize "cultural output"
4. Tools for resolution magnification
1. HD repair Hires.fix
Upscale by: magnification, refers to how much the image is enlarged from the original resolution
Hires steps: High-definition repair sampling times, HD repair needs to be redrawn once, so you need to set the number of sampling steps. Keep the default value of 0, which will be consistent with the number of sampling iterations we set (20).
Denoising strength: Redrawing strength, which is equivalent to the redrawing strength in the graph.
Generation process: SD will first draw a low-resolution image, and then draw a second high-resolution image based on it. Its essence is to take this low-resolution finished "picture image" once, and send it back to the latent space for re-denoising, so as to obtain a larger image.
The essence of high-definition restoration: call back and redraw, and make another one! Fits a Vincent diagram .
- Advantage:
Does not change the frame composition (fixed via random seed);
Stably overcome the problems caused by resolution of multiple people and multiple heads;
The operation is simple, clear and intuitive.
- defect:
Still limited by the maximum video memory;
The calculation speed is relatively slow, and drawing once is equal to drawing two to three times under normal circumstances
Occasionally "add drama", there are inexplicable additional elements
2、SD UpScale
A good helper for enlarging the image resolution in the graph.
Screenplay:
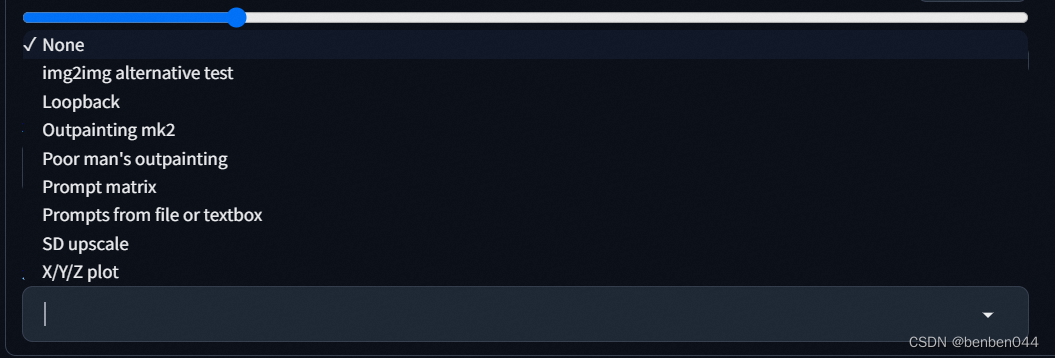
Select SD upscale
Its drawing process: It is completely different from the "returning and redrawing" of high-definition restoration. It is drawn by cutting the picture evenly into 4 pieces, drawing 4 pieces one by one and then putting them together.
If it is only cut into 4 pieces mechanically, there will definitely be a very blunt transition edge at the seams between adjacent tiles, so the pixel overlap through tile overlap will play the role of a "buffer".

Advantage:
Can break through the memory limit to get a larger resolution
High-definition picture, excellent rich effect on details
defect:
The process of splitting and redrawing is relatively uncontrollable (semantic misleading and dividing line splitting)
Cumbersome and relatively unintuitive to operate
Occasionally "add drama", there are inexplicable additional elements
5. AI painting entry-level extension plug-in

All functions related to extensions are centrally stored and managed in this "Extensions" tab.
Plug-ins are uniformly installed in the "Extension" folder in the root directory, and each extension is a separate folder.
1. Chinese localization language pack

2. Gallery browser

GitHub - yfszzx/stable-diffusion-webui-images-browser: an images browse for stable-diffusion-webui
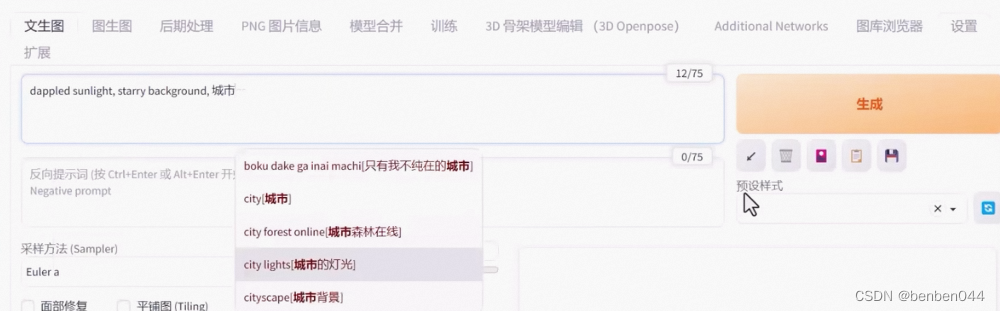
3. Prompt word auto-completion

https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
It is implemented based on a local Booru thesaurus.
This plug-in can also input in Chinese, and then switch to English for input.
4. Prompt words reversed

https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git
A more efficient inversion tool than CLIP and DeepBooru.
5. Upscale zoom in and out

https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
After the installation is complete, there is no independent tab, but it appears in the script.
6. Partial refinement and redrawing

https://github.com/hnmr293/sd-webui-llul
Compared with the fifth tool, it will not make the whole picture particularly large, but will "enlarge" some parts that are limited in size and cannot be made more refined.
It lies in bringing richer details to the picture without changing the original structure.
7. Semantic segmentation of prompt words

https://github.com/hnmr293/sd-webui-cutoff.git
Resolve mutual interference between cue words.
The principle of extension is as follows:

It will extract the "descriptive" component of each prompt word and process it separately, and then combine it back into the original painting.
8. Unlimited zoom animation video

https://github.com/v8hid/infinite-zoom-automatic1111-webui.git

We can imagine that its scene is constantly extending outward, and finally generates an animated video.
Six, ControlNet plug-in
1. General description
Prior to this, the "AI painting" based on the diffusion model was very difficult to control, and the process of de-diffusion of this picture was full of randomness.
In principle, ControlNet and LoRA have many similarities, and the positioning is an additional network that fine-tunes the large diffusion model. Its core role is to control the direction of diffusion based on some additional information.
For example, "posture", if you just input a "dance" through the prompt word, then the characters and characters in the screen may have countless dance postures. The essence of ControlNet is that you can input a record of a specific "pose" information The picture to guide it to draw. ControlNet can read the following information.
2. Installation
Plug-in download address: GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
After downloading, it can also be placed in the extensions directory. After restarting to take effect, you can see the plug-in at the bottom of the Wensheng diagram or the above diagram.
At this time, ControlNet cannot be used yet, because the corresponding control model needs to be downloaded to work. The download address of the corresponding model is:
lllyasviel/ControlNet-v1-1 · Hugging Face
After downloading a model, you need to put it in the models folder in the ControlNet folder. Note: the pth model file with the same name and the yaml configuration need to be placed together.
The Annotator function of the ControlNet plug-in can extract additional information useful to ControlNet from the picture.

Control Weight: Determine the intensity of this control effect in the picture. The latter two options will affect when to join ControlNet in the process of continuous image diffusion. The default value of 0 to 1 means that it takes effect from beginning to end.
3. Comparing five ControlNet models of manifolds

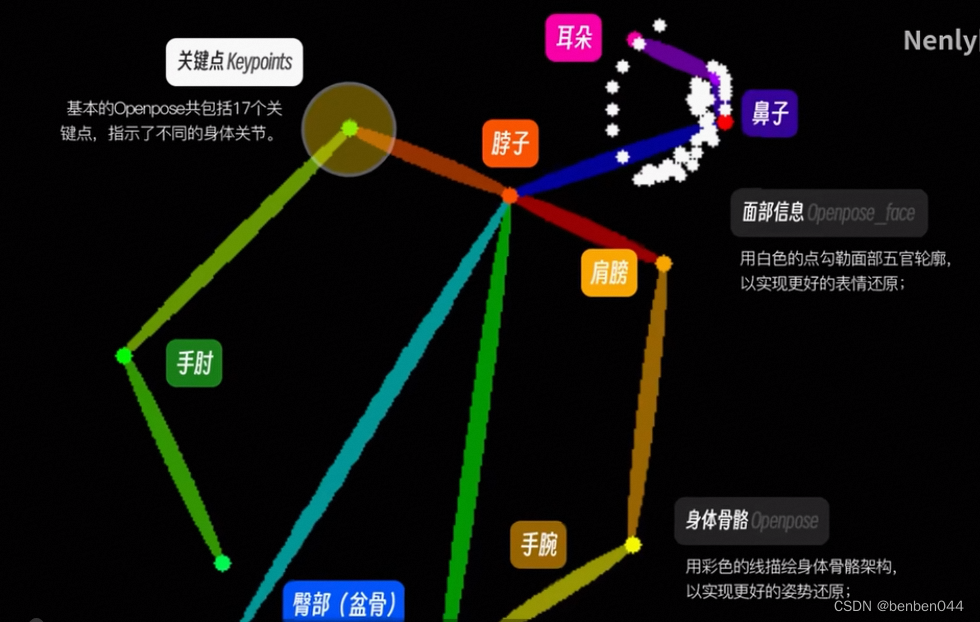
(1) Openpose model
Directly grasp the "lifeline" of the body posture presentation.
The picture below is openpose-hand

The following is openpose-face

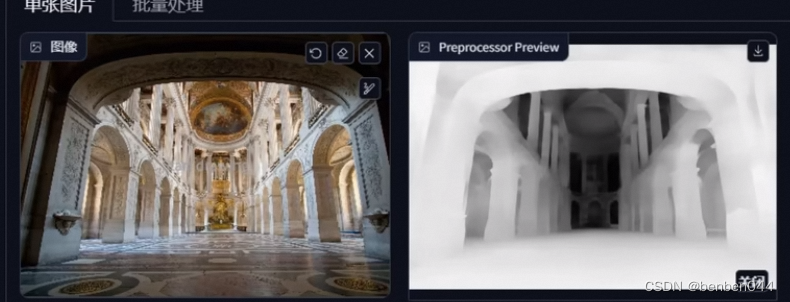
(2) Depth model
Its focus is on the depiction and restoration of the scene, especially the multi-level scene with a sense of space
(3) Canny model
An edge detection algorithm from the field of image processing.

(4) HED model
Overall edge line detection.

The input lines are more blurred than Canny. The comparison between the two is as follows:

Canny pays more attention to the internal details of the characters. HED processing will only preserve the large outlines, and the interior actually has more room for development.
(5) Scribble model
graffiti.
 get:
get:
3、MultiControlNet
Multiple ControlNet