Decision Tree – Titanic Passenger Survival Prediction – Baseline
Project introduction: Use the decision tree model to predict the survival of passengers on the Titanic. This project is to establish a simple baseline model and sort out the entire process of machine learning in order to master the process framework of machine learning.
Data source: tannic data set on kaggle data set, if you are interested, you can download it for practical exercises.
Data introduction:
| Field Name | explain |
|---|---|
| PassengerId | Passenger ID |
| Pclass | passenger class |
| Name | passenger's name |
| Sex | gender |
| Age | age |
| SibSp | number of cousins |
| respect | Number of parents and children |
| Fare | fare |
| Cabin | cabin |
| Embarked | port of embarkation |
Project Flow
- get dataset
- Basic data processing
- view data set
- get feature value, target value
- missing value, outlier processing
- data set division - Feature Engineering Dictionary Feature Extraction
- Machine Learning Decision Tree Model Training
- Model prediction and evaluation
- Import required modules
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer #字典抽取模块
from sklearn.model_selection import train_test_split#数据集划分
from sklearn.tree import DecisionTreeClassifier,export_graphviz#决策树
- Get and view data
df = pd.read_csv('../input/titanic/train.csv')
df.head()

3. View the distribution of index values in each column
df.nunique()#查看各列值的分布情况
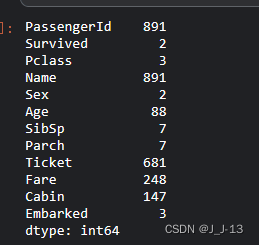
It is found that there are 891 passenger ids and names, there are 2 types of survival conditions, and 3 types of pclass passenger levels, indicating that there are 3 different passenger levels, and the gender distribution is 2 types, which is normal
- Check for missing values
df.isnull().sum()#查看缺失值
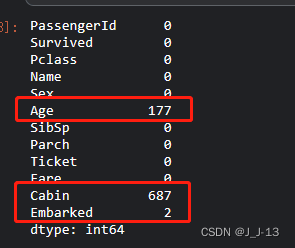
By checking, it is found that there are 177 missing values in the Age column, and the method of filling is considered. The Cabin column has 687 missing values. There are a large number of missing values in this column, which has no practical reference value. Delete the data in this column directly. There are 2 missing values in Embarked, which can be directly filled.
- Outlier view
df['Age'].unique() #发现年龄一列存在异常值,为小于0的小数
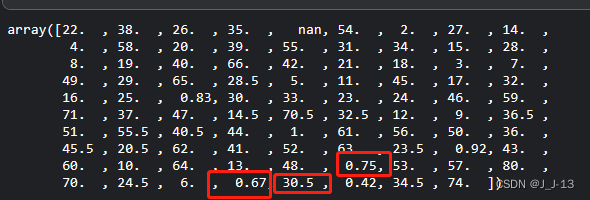
Through inspection, it is found that there are a large number of values less than 1 in the age column data, which is obviously unrealistic, and we need to delete them. At the same time, the Cabin column with too many missing values is deleted
df = df[df['Age']>=1]#取年龄大于1的正常数据
df1 = df.drop('Cabin',axis =1) #删除缺失值过多的列
After filtering and deleting the data in the age column and the cabin column, we checked the missing values again and found that there are no missing values at this time.
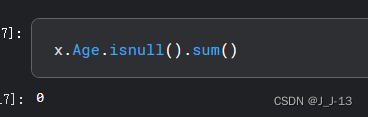
- Obtain eigenvalues and target values
The data set contains 12 index data including PassengerId, Survived, Pclass, Age, etc., among which Survived is the index basis for passenger survival, 0 means no, 1 means survival, which is the target value we need . And will the remaining 11 indicators have a great impact on the target value? In this project, we guess that Pclass passenger class, Age , and Sex will have a greater impact on survival. Because different passenger levels may have priority treatment, young and strong guys may be easier to escape or respect the old and love the young, women first, let them escape first. Therefore, this project selects Pclass passenger level, Age , and Sex as feature values for training.
# 确定特征值,目标值
x = df1[['Pclass','Age','Sex']]
y = df1['Survived']
- Dataset partition
#数据集划分,训练集与测试集八二分
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=22,test_size=0.2)
- Feature extraction
Since the value of the original data Sex is male and female , it is not the numerical data recognized by our computer, so it needs to be feature extracted and converted into a form that the computer can recognize. Here we use DictVectorizer Perform dictionary feature extraction
#特征工程 字典特征抽取
# 1.先转换为字典
x_train =x_train.to_dict(orient = 'records')
x_test = x_test.to_dict(orient = 'records')
#2. 特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
- Machine learning
After completing the feature engineering process, we enter the model training stage, where we use the decision tree model in machine learning for training
#机器学习
clf = DecisionTreeClassifier()
clf.fit(x_train,y_train)
- model evaluation
y_pre = clf.predict(x_test)
y_pre
score = clf.score(x_test,y_test)
score
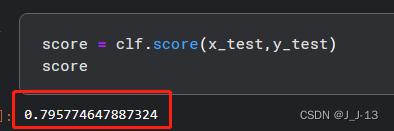
Finally, verify in the verification set, evaluate the score, and find that the accuracy rate is about 0.795 , which is okay as a baseline
Summarize
This concludes the case of predicting the survival of passengers on the Titanic based on a decision tree model. In this case, the entire machine learning process includes data reading, data viewing, data preprocessing (missing value processing, outlier processing), feature engineering, model training, and model evaluation. It is suitable for friends who are just learning machine learning to quickly get started with machine learning.
However, the prediction accuracy rate this time is only about 0.795 , which can only be used as a baseline, and there are still many shortcomings.
- For example, only three columns are selected as feature values, and other features are not considered. In fact, other features may also have a great influence
- The feature engineering part is too rough, only to digitize the features, and there is no deep connection between the features
- The decision tree model is too rough, no hyperparameters are passed in, and interested
friends can dig into the data set again, adopt more complex models and processing methods, make predictions, and improve prediction accuracy.