
Set the primary key id to auto-increment and name to be a unique index
1. Avoid repeated insertion
insert ignore into (with unique index)
Keyword/sentence: insert ignore into, if the inserted data will cause UNIQUE索引or PRIMARY KEYconflict/duplication, ignore this operation/do not insert data, for example:
INSERT IGNORE INTO `student`(`name`,`age`) VALUES(`Jack`,18);
-- row(s) affected
The data with name='Jack" already exists here, so the newly inserted data will be ignored, the number of affected rows is 0, and the table data remains unchanged
Note that the primary key will auto-increment
When using insert ignore into to add new data, some versions of mysql will auto-increment the primary key even if it is not inserted.
For example, there was data 1 (id is 1), and you inserted data 1 again, but did not insert it again, and then inserted data 2. At this time, the primary key of data 2 is 3 instead of 2. mysql5.7.26 will not auto-
increment , 8.0 will auto-increment
How to avoid self-increment?
When doing INSERT IGNORE in MySQL5.7, it is found that even if the INSERT is not executed successfully, the auto-increment primary key of the table is automatically increased by 1. In some cases, this behavior needs to be avoided. The variable that needs to be modified is to set it to innodb_autoinc_lock_mode0 After that, the primary key will not be auto-incremented when the INSERT is not executed successfully.
The default value of innodb_autoinc_lock_mode in each version of MySQL
According to the official MySQL manual:
There are three possible settings for the innodb_autoinc_lock_mode configuration parameter. The settings are 0, 1, or 2, for “traditional”, “consecutive”, or “interleaved” lock mode, respectively. As of MySQL 8.0, interleaved lock mode (innodb_autoinc_lock_mode=2) is the default setting. Prior to MySQL 8.0, consecutive lock mode is the default (innodb_autoinc_lock_mode=1).
In MySQL8, the default value is 2 (interleaved, interleaved), before MySQL8, precisely before 8, after 5.1, the default value is 1 (consecutive, continuous), in earlier versions it is 0
Description of innodb_autoinc_lock_mode
This value is mainly used to balance performance and security (master-slave data consistency), insert mainly has the following types
simple insert 如insert into t(name) values(‘test’)
bulk insert 如load data | insert into … select … from …
mixed insert 如insert into t(id,name) values(1,‘a’),(null,‘b’),(5,‘c’);
innodb_autoinc_lock_mode = 0:
Backward compatibility with later versions of MySQL
In this mode, all insert statements must obtain a table-level auto_inc lock at the beginning of the statement, and release the lock at the end of the statement. A transaction may contain One or more statements
can guarantee the predictability, continuity, and repeatability of value distribution, which also ensures that the insert statement can generate the same value as the master when it is copied to the slave (it guarantees Security based on statement replication)
Since the auto_inc lock is kept until the end of the statement in this mode, this affects concurrent insertion
innodb_autoinc_lock_mode = 1:
This mode optimizes the simple insert. Since the number of values inserted at one time by simple insert can be determined immediately, mysql can generate several consecutive values at a time for this insert statement. Generally speaking, this is also safe for replication (Guaranteeing the security based on statement replication)
This mode is also the default mode before MySQL8.0. The advantage of this mode is that the auto_inc lock does not keep until the end of the statement, as long as the statement gets the corresponding value, the lock can be released in advance
innodb_autoinc_lock_mode = 2:
Since there is no auto_inc lock in this mode, the performance in this mode is the best, but it also has a problem, that is, for the same statement, the auto_incremant value it gets may not be continuous. Now mysql has recommended
binary The format of the format is set to row, so this mode can achieve the best performance when binlog_format is not a statement
insert if not exists (no unique index)
The data field does not have a primary key or a unique index . When inserting data, first determine whether this data exists. If there is no normal insertion, it will be ignored if it exists. Now I have removed both primary key and unique index. The full sql is
# 示例一:插入多条记录,假设有一个主键为 client_id 的 clients 表,可以使用下面的语句:
INSERT INTO clients (client_id,client_name,client_type)
SELECT supplier_id,supplier_name,’advertising’
FROM suppliers
WHERE not exists
(select * from clients
where clients.client_id = suppliers.supplier_id);
#示例二:插入单条记录
INSERT INTO clients(client_id,client_name,client_type)
SELECT 10345,’IBM’,’advertising’
FROM dual
WHERE not exists
(select*from clients
where clients.client_id=10345
);
2. Insert if it does not exist, and update if it exists
on duplicate key update
If the inserted data will cause conflict/duplication of UNIQUE index or PRIMARY KEY, execute UPDATE statement, for example:
#name 有唯一索引
INSERT INTO `student`(`name`, `age`) VALUES('Jack', 19)
ON DUPLICATE KEY UPDATE `age`=19;
-- If will happen conflict, the update statement is executed
-- 2 row(s) affected
The number of rows affected here is 2, because there is data with name='Jack' in the database, if this data does not exist, the number of rows affected is 1
possible deadlock
The bug has been fixed in versions 5.7.26 and 8.0.15. When inserting data, no gap lock will be formed
But this method also has pitfalls. If there is more than one unique index in the table, it is easy to generate dead lock (deadlock) in a specific version of mysql
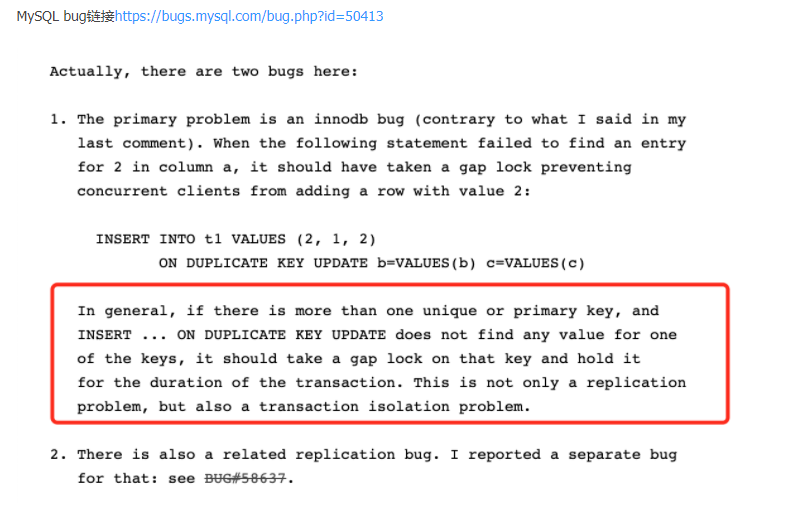
When mysql executes the INSERT of INSERT ON DUPLICATE KEY, the storage engine checks whether the inserted row will generate a duplicate key error. If so, it
returns the existing row to mysql, which updates it and sends it back to the storage engine. This statement is sensitive to the order in which the storage engine checks the keys when the table has more than one unique or primary key. According to this order,
the storage engine can determine different rows of data to mysql, so mysql can update different rows. The order in which the storage engine checks keys is not deterministic.
For example, InnoDB examines keys in the order that indexes were added to the table.
insert … on duplicate key When executing, the innodb engine will first judge whether the inserted row has a duplicate key error. If so, add an S (shared lock) lock to the existing row. If the row data is returned to mysql, Then mysql executes the update operation after the duplicate, then adds X (exclusive lock) to the record, and finally writes the update.
If two transactions execute the same statement concurrently, a death lock will be generated
The official description of mysql is very simple
An INSERT … ON DUPLICATE KEY UPDATE statement against a table having more than one unique or primary key is also marked as unsafe. (Bug #11765650, Bug #58637)
insert on duplicate key update If it hits the primary key or unique key index, add a row lock, and if it misses a gap lock, it will block the insertion of data Process analysis
insert
... on duplicate key When executing, the innodb engine will first determine whether the inserted row is duplicated key error, if it exists, add an S (shared lock) lock to the existing row, if the row data is returned to mysql, then mysql executes the update operation after the duplicate, and then adds an X (exclusive lock) to the record ), and finally write the update.
If two transactions execute the same statement concurrently, a death lock will be generated, such as:
the solution of the lower version
- Try not to use this statement for tables with multiple unique keys
- Do not use this statement when there is a possibility that concurrent transactions will execute the same content of the insert. Split the batch insert on duplicate key update into multiple statements. Make sure not to insert too many values in one transaction, turn multiple data into multiple sql, and execute the insertion. It can effectively reduce the occurrence of deadlock hits.
- Retry: Deadlock is not terrible. When a deadlock occurs, multiple retry operations can effectively ensure that the insertion is successful and the update is not lost.
- The multi-thread concurrent execution of the thread pool is changed to single-thread queuing processing.
replace into (delete and then insert)
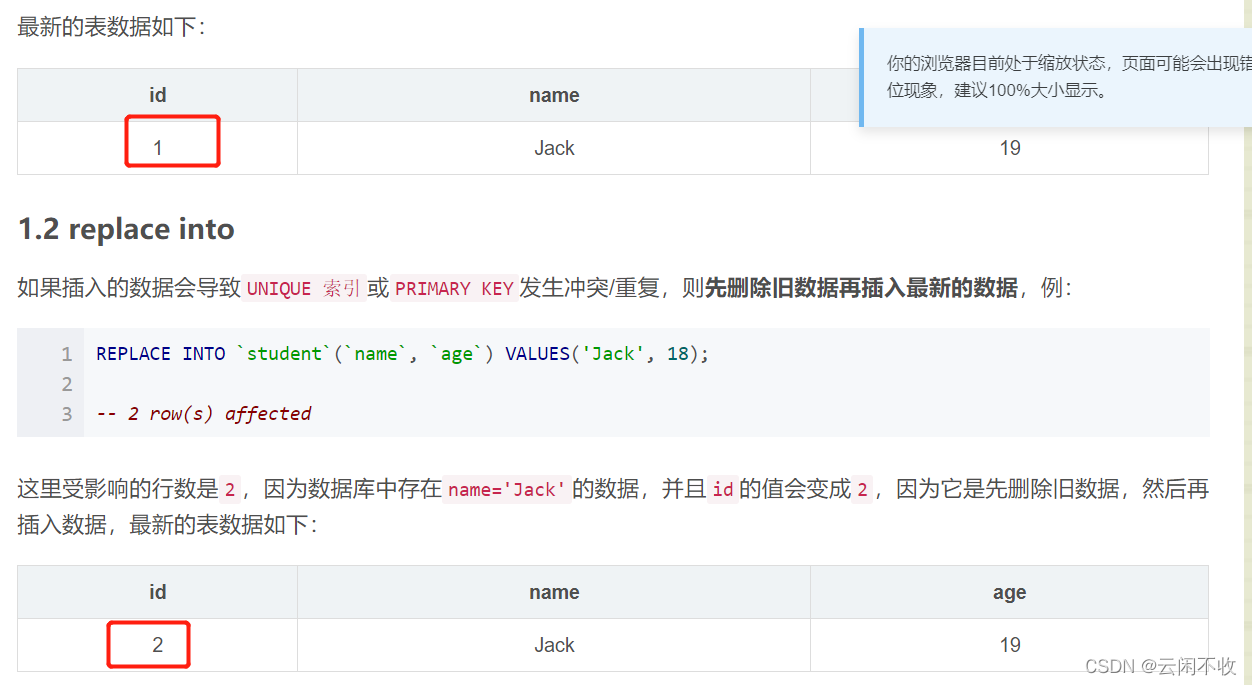
replace into will judge based on the unique index or primary key. If it exists, it will overwrite the written field, and if it does not exist, it will add it. This method has pitfalls. If the primary key is self-incrementing and the operation is performed through a unique index, the primary key will change. The bottom layer of this method is advanced delete. It is not recommended to use it if there is a sub-table dependency
in insert.