Image scaling refers to the process of reducing or increasing the size of an image, that is, reducing or increasing the number of pixels in the source image data. Image scaling will cause information loss to a certain extent, so it is necessary to consider an appropriate method for operation.
The following introduces the principle and implementation of two commonly used image scaling methods
1. Extract image scaling based on equal intervals
Equally spaced extraction Image scaling is done by uniformly sampling the source image. For the source image data f(x,y), its resolution is M*N, if its resolution is changed to m*n, for equal interval sampling, its width scaling factor k1=m/M, height scaling factor k2=n/N, for the image, the equal interval sampling in the horizontal direction of the image scaling is k1, and the equal interval sampling in the vertical direction is k2. If k1=k2 is satisfied, the source image data will be proportionally scaled, otherwise the width and height of the source image data will be scaled to different degrees, resulting in image deformation and distortion
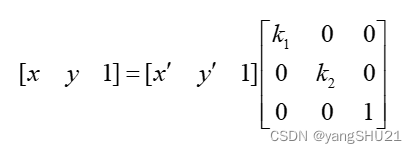
2. Image scaling based on regional subblocks
Regional sub-block extraction Image scaling is achieved by dividing the source image into regional sub-blocks, and then extracting the pixel values in the sub-blocks as sampling pixels to form a new image. Commonly used methods for extracting sub-block pixel values include calculating the median value of sub-block pixels and calculating the mean value of sub-block pixels. There are also many different methods for regional division of the source image. The common method is to extract sub-blocks according to the scaling factor and the adaptive factor to extract sub-blocks. Assuming that the resolution of the source image data f(x,y) is 8*8, The resolution of the image g(x, y) is 2*2, and the region sub-block extraction method is as follows:
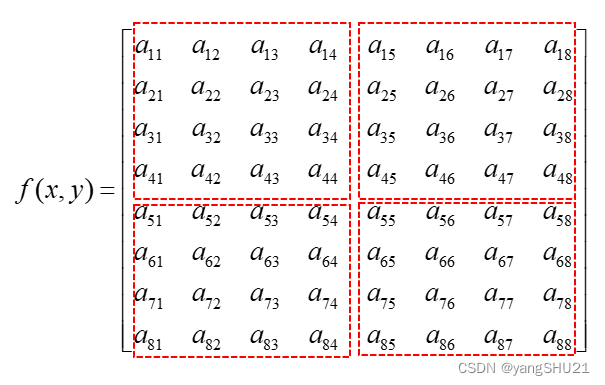
After the sub-block area is extracted, g(x,y) is the following formula
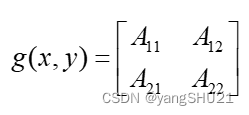
The following two methods are implemented to zoom the image
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/core/core.hpp>
#include<opencv2/highgui/highgui.hpp>
#include<iostream>
using namespace std;
using namespace cv;
//基于等间隔提取图像缩放
Mat imgReduction1(Mat& src, float kx, float ky)
{
//获取输出图像分辨率
int nRows = cvRound(src.rows * kx);
int nCols = cvRound(src.cols * ky);
Mat result(nRows, nCols, src.type());
for (int i = 0; i < nRows; ++i)
{
for (int j = 0; j < nCols; ++j)
{
//根据水平因子计算坐标
int x = static_cast<int>((i + 1) / kx + 0.5) - 1;
//根据垂直因子计算坐标
int y = static_cast<int>((j + 1) / ky + 0.5) - 1;
result.at<Vec3b>(i, j) = src.at<Vec3b>(x, y);
}
}
return result;
}
Vec3b areaAverage(const Mat& src, Point_<int> leftPoint, Point_<int> rightPoint)
{
int temp1 = 0, temp2 = 0, temp3 = 0;
//计算区域子块像素点个数
int nPix = (rightPoint.x - leftPoint.x + 1) * (rightPoint.y - leftPoint.y + 1);
//对于区域子块各个通道对像素值求和
for (int i = leftPoint.x; i <= rightPoint.x; i++)
{
for (int j = leftPoint.y; j <= rightPoint.y; j++)
{
temp1 += src.at<Vec3b>(i, j)[0];
temp2 += src.at<Vec3b>(i, j)[1];
temp3 += src.at<Vec3b>(i, j)[2];
}
}
//对每个通道求均值
Vec3b vecTemp;
vecTemp[0] = temp1 / nPix;
vecTemp[1] = temp2 / nPix;
vecTemp[2] = temp3 / nPix;
return vecTemp;
}
//基于区域子块图像缩放
Mat imgReduction2(const Mat& src, double kx, double ky)
{
//获取输出图像分辨率
int nRows = cvRound(src.rows * kx);
int nCols = cvRound(src.cols * ky);
Mat result(nRows, nCols, src.type());
//区域子块的左上角行列坐标
int leftRowCoordinate = 0;
int leftColCoordinate = 0;
for (int i = 0; i < nRows; ++i)
{
//根据水平因子计算坐标
int x = static_cast<int>((i + 1) / kx + 0.5) - 1;
for (int j = 0; j < nCols; ++j)
{
//根据垂直因子计算坐标
int y = static_cast<int>((j + 1) / kx + 0.5) - 1;
//求解区域子块的均值
result.at<Vec3b>(i, j) = areaAverage(src,
Point_<int>(leftRowCoordinate, leftColCoordinate), Point_<int>(x, y));
//更新下子块左上角的列坐标,行坐标不变
leftColCoordinate = y + 1;
}
leftColCoordinate = 0;
//更新下子块左上角的行坐标
leftRowCoordinate = x + 1;
}
return result;
}
int main()
{
Mat src = imread("C:\\Users\\32498\\Pictures\\16.png");
if (!src.data)
{
return -1;
}
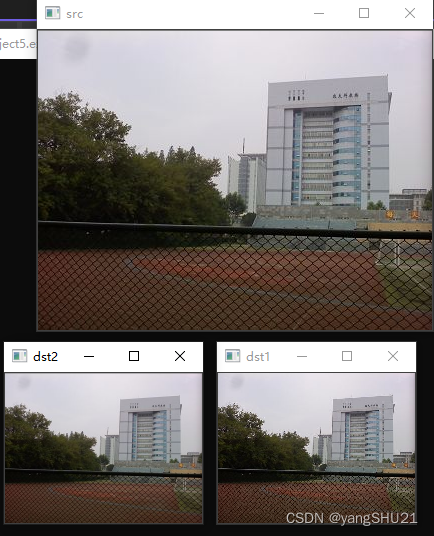
imshow("src", src);
Mat dst1 = imgReduction1(src, 0.5, 0.5);
imshow("dst1", dst1);
Mat dst2 = imgReduction2(src, 0.5, 0.5);
imshow("dst2", dst2);
waitKey();
return 0;
}
Make some comments on the code
- cvRound(): returns the integer value closest to the parameter, that is, rounded;
Similar functions are also
- cvFloor() : returns the largest integer value not greater than the parameter, that is, rounded down;
- cvCeil() : returns the minimum integer value not less than the parameter, that is, rounds up;
Point_<int>(x,y) There are three types of two-dimensional plane point coordinates built into opencv, which brings about a problem: that is, when we write image processing algorithms, sometimes we are not sure which coordinate point data type the caller needs, just write one. It may not be able to meet the needs. It is time-consuming and labor-intensive to implement all three types separately, and it does not make good use of the characteristics of C++ polymorphic generics. The template class in opencv cv::Point_can just solve this problem. In fact, the above three types of points are all cv::Point_specific instantiations. You can view them in opencv by going to the definition
typedef Point_<int> Point2i;
typedef Point_<int64> Point2l;
typedef Point_<float> Point2f;
typedef Point_<double> Point2d;
typedef Point2i Point;point_ is defined as follows:
template<typename _Tp> class Point_
{
public:
typedef _Tp value_type;
//! default constructor
Point_();
Point_(_Tp _x, _Tp _y);
Point_(const Point_& pt);
Point_(const Size_<_Tp>& sz);
Point_(const Vec<_Tp, 2>& v);
Point_& operator = (const Point_& pt);
//! conversion to another data type
template<typename _Tp2> operator Point_<_Tp2>() const;
//! conversion to the old-style C structures
operator Vec<_Tp, 2>() const;
//! dot product
_Tp dot(const Point_& pt) const;
//! dot product computed in double-precision arithmetics
double ddot(const Point_& pt) const;
//! cross-product
double cross(const Point_& pt) const;
//! checks whether the point is inside the specified rectangle
bool inside(const Rect_<_Tp>& r) const;
_Tp x; //!< x coordinate of the point
_Tp y; //!< y coordinate of the point
};