Level 1: Use the URL to get the hypertext file and save it locally
Implementation code:
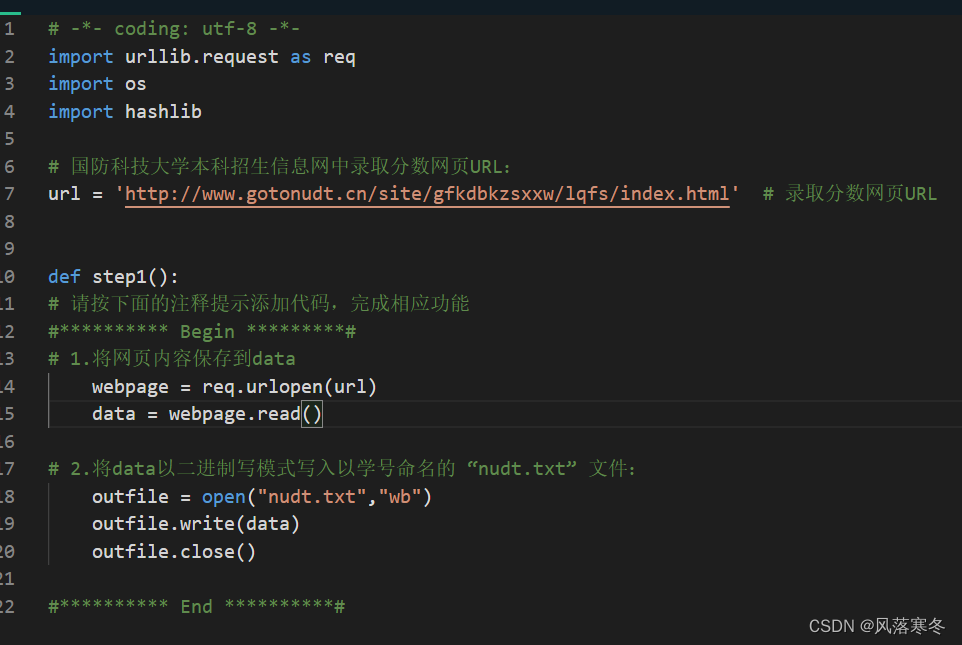
# -*- coding: utf-8 -*-
import urllib.request as req
import us
import hashlib
# National University of Defense Technology Undergraduate Admissions Information Network Admission Score Webpage URL:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # Admission score page URL
def step1():
# Please follow the comment below to add code to complete the corresponding function
#********** Begin *********#
# 1. Save the web page content to data
webpage = req.urlopen(url)
data = webpage.read()
# 2. Write the data in binary writing mode to the "nudt.txt" file named after the student number:
outfile = open("nudt.txt","wb")
outfile.write(data)
outfile.close()
#********** End **********#
Pass 2: Extract sublinks
Implementation code:
# -*- coding: utf-8 -*-
import urllib.request as req
# National University of Defense Technology Undergraduate Admissions Information Network Admission Score Webpage URL:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # Admission score page URL
webpage = req.urlopen(url) # Open the webpage as a class file
data = webpage.read() # Read all the data of the webpage at one time
data = data.decode('utf-8') # Decode the byte type data into a string (otherwise, it will be processed separately later)
def step2():
# Create an empty list urls to save the urls of sub-pages
urls = []
# Please follow the comment below to add code to complete the corresponding function
#********** Begin *********#
# Extract the 2016 to 2012 fraction line sub-site address for each year from the data and add it to the urls list
years = [2016, 2015, 2014, 2013,2012]
for year in years:
index = data.find("National University of Defense Technology %s year admission score statistics" %year)
href = data[index-80:index-39] # Extract url substrings according to each characteristic string
website = 'http://www.gotonudt.cn'
urls.append(website+href)
#********** End **********#
return urls

Level 3: Web page data analysis
Implementation code:
# -*- coding: utf-8 -*-
import urllib.request as req
import re
# URL of the 2016 admission score web page in the National University of Defense Technology Undergraduate Admissions Information Network:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html'
webpage = req.urlopen(url) # Visit the linked webpage according to the hyperlink
data = webpage.read() # read hyperlink web page data
data = data.decode('utf-8') # decode byte type to string
# Get all the content in the first table in the webpage:
table = re.findall(r'<table(.*?)</table>', data, re.S)
firsttable = table[0] # Get the first table in the web page
# Data cleaning, remove , \u3000, and spaces in the table
firsttable = firsttable.replace(' ', '')
firsttable = firsttable.replace('\u3000', '')
firsttable = firsttable.replace(' ', '')
def step3():
score = []
# Please add code according to the comment below to complete the corresponding function. To view the detailed html code, you can open the url in the browser to view the source code of the page.
#********** Begin *********#
# 1. Press the tr tag to get all the rows in the table and save them in the list rows:
rows = re.findall(r'<tr(.*?)</tr>', firsttable, re.S)
# 2. Iterate over all elements in rows, get the data in the td tag of each row, and form the data into an item list, and add each item to the scorelist list:
scorelist = []
for row in rows:
items = []
tds = re.findall(r'<td.*?>(.*?)</td>', row, re.S)
for td in tds:
rightindex = td.find('</span>') # return -1 means not found
leftindex = td[:rightindex].rfind('>')
items.append(td[leftindex+1:rightindex])
scorelist.append(items)
# 3. Save the 7-element list consisting of provinces and scores (if the score does not exist, replace it with \) as an element in the new list score, do not save redundant information
for record in scorelist[3:]:
record.pop()
score.append(record)
#********** End **********#
return score
