Table of contents
2. Zipper watch business background
2.1 Problems caused by data synchronization
3. Design and principle of zipper watch
3.1 Functions and Application Scenarios
3.3.1 Create a table and load data
3.3.2 Simulating incremental data changes
I. Introduction
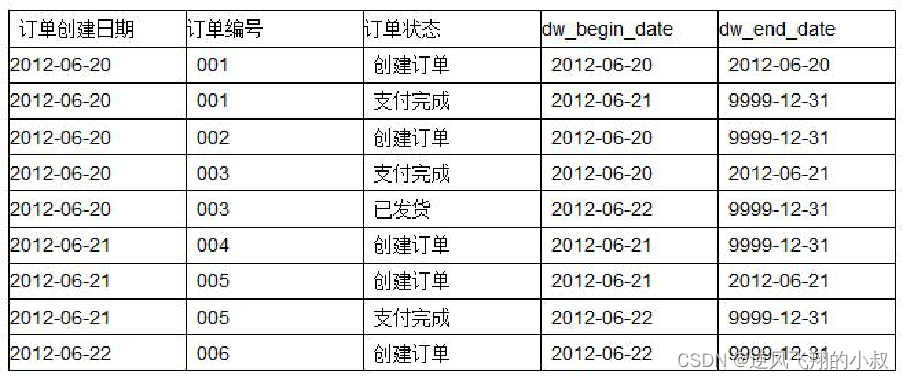
Students who have done e-commerce development should be familiar with the business of orders. For example, for an order data, there is usually a field similar to status to identify the complete life cycle of the order. From the perspective of stored data, a A table only needs to store this piece of data.
But for data analysis, in order to track the complete process of the entire life cycle of this order, this is not a very good design. If the order has been paid but not shipped, and it stops at the undelivered step It takes a long time. For big data analysis scenarios, this is an important analysis scenario, but for the order table stored in mysql, this is somewhat redundant. That is to say, when mysql designs tables, it will fully consider the performance problems caused by the amount of redundant data.
2. Zipper watch business background
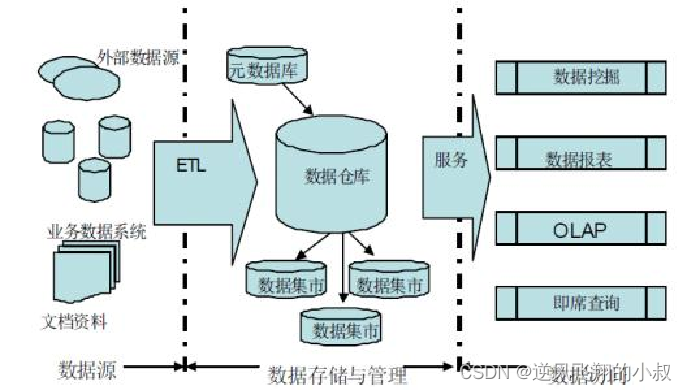
We know that Hive is mainly used to build an offline data warehouse in actual work, periodically collect data from various data sources into Hive synchronously, and provide data to other applications on the upper layer through hierarchical conversion.
For example: There is a scheduled task to synchronize the latest order information, user information, store information, etc. from MySQL to the data warehouse every day, so as to perform order analysis, user analysis, etc.
As shown in the figure below, it is a simple business flow chart of a data warehouse;
2.1 Problems caused by data synchronization
There is the following user table tb_user. Students who have experience in development should be familiar with similar order tables. For example, after each user is registered, a new piece of data will be generated in the table, recording the user’s id , mobile phone number, user name, gender, address and other information.

The specific usage scenarios of this table in business are as follows:
- Every day, users register and generate new user information;
- The user data in MySQL needs to be synchronized to the Hive data warehouse every day;
- Statistical analysis of user information is required, such as the number of new users, user gender distribution, regional distribution, operator distribution and other indicators;
The process of data synchronization is roughly as follows
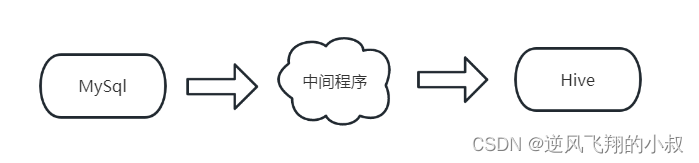
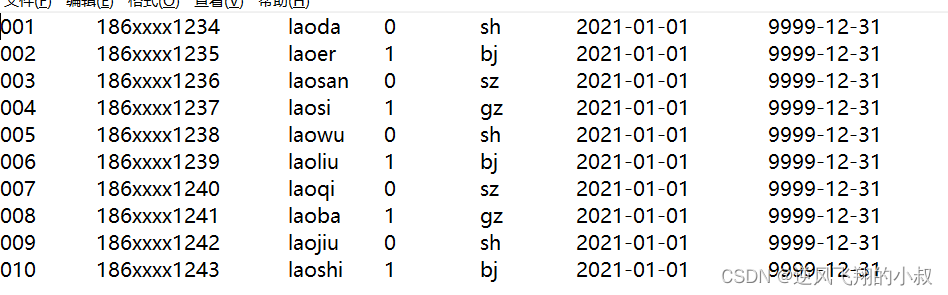
For example, on the day 2021-01-01, there are 10 user information in MySQL;

Then it is synchronized to the following Hive table through the intermediate program (or other means);
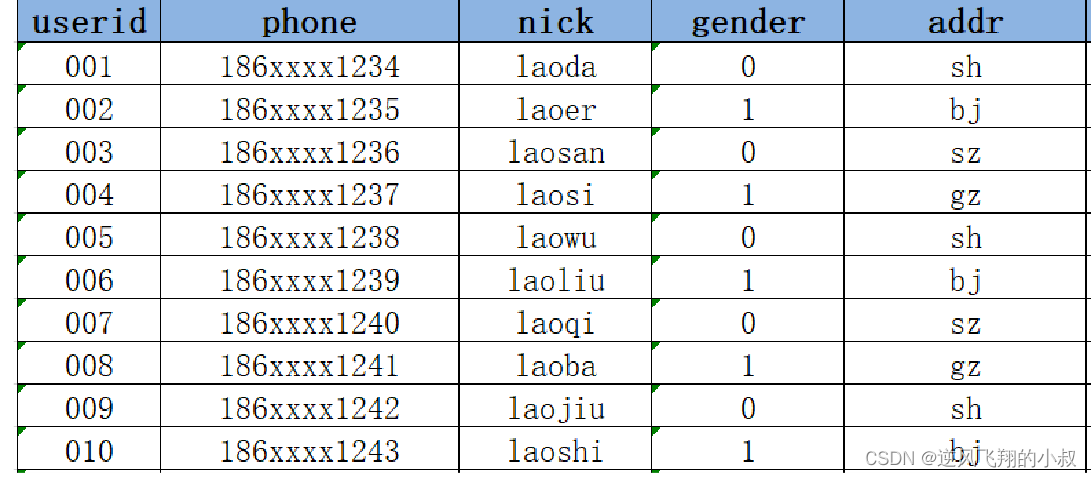
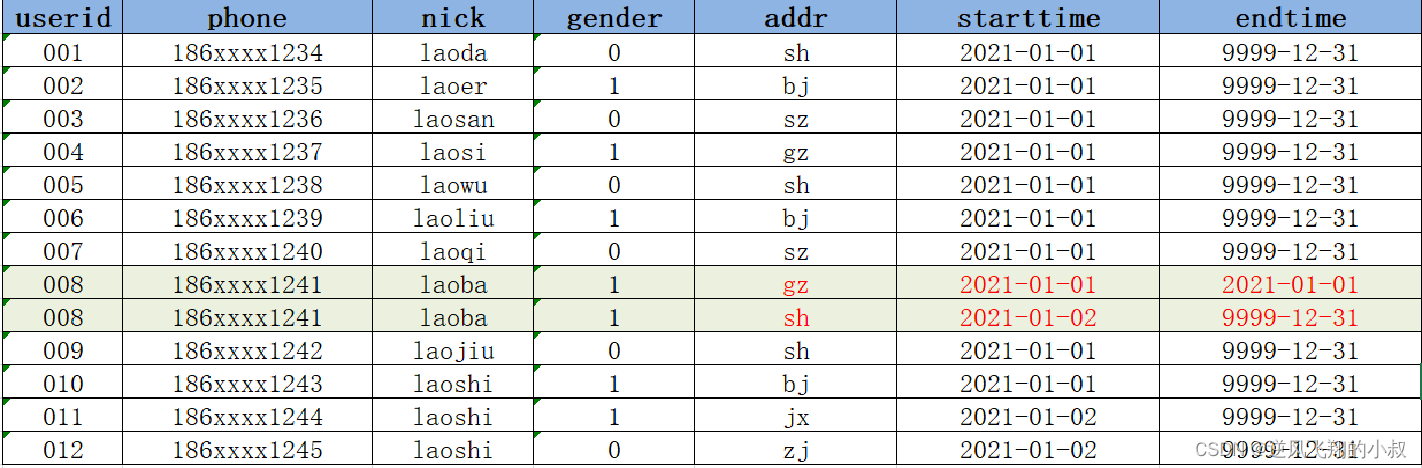
Now, if on the day of 2021-01-02, on the basis of the previous day, MySQL added 2 new user registration data, and one of the user data was updated,
- Add two new user data 011 and 012;
- The addr of 008 has been updated, from gz to sh;
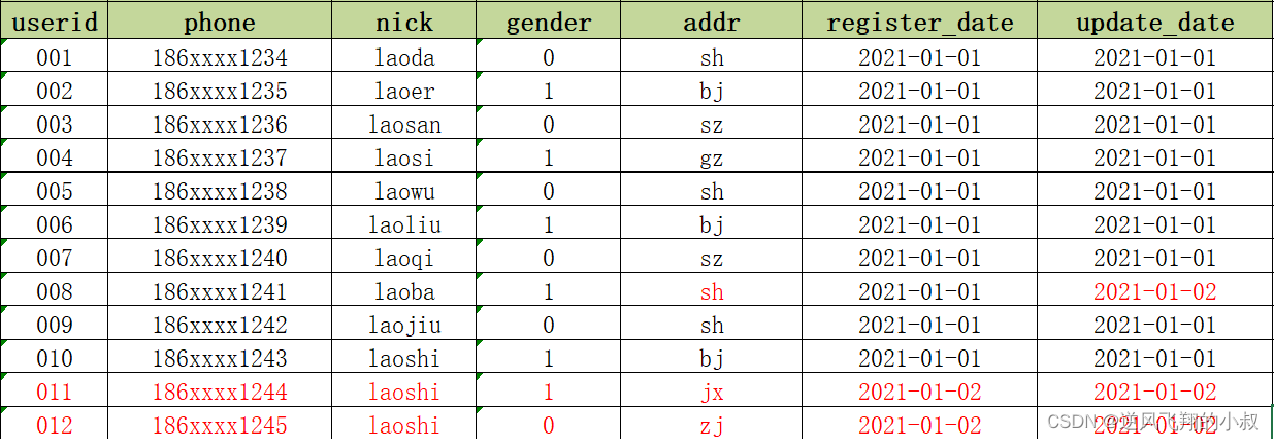
On the day of 2021-01-03, Hive needs to update the data of No. 2 synchronously. At this time, the problem comes:
Newly added data will be directly loaded into the Hive table, but how is the updated data stored in the Hive table?
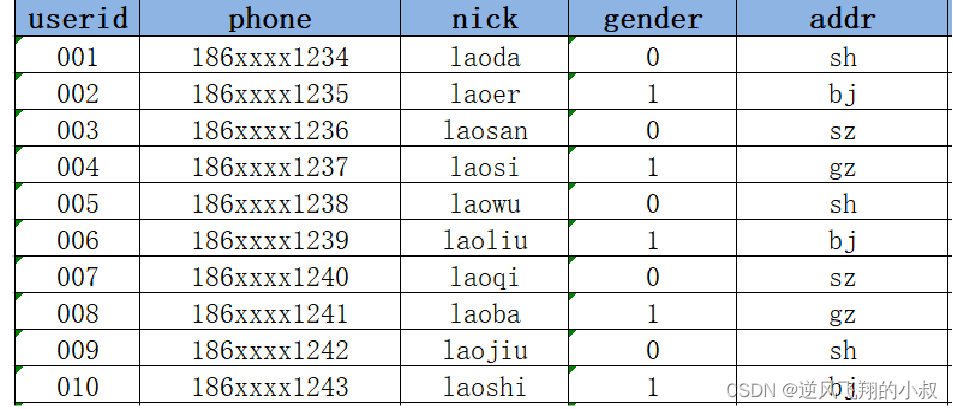

2.1.1 Solution 1
Overwrite the old addr of 008 with the new addr in Hive, update directly
The advantages of doing this are: the easiest to implement and the most convenient to use, but the disadvantages are also obvious. There is no historical state. The address of 008 is in sh on January 2, but it is in gz before January 2. If you want If you query the addr before January 2 of 008, you cannot query it, and you cannot use sh instead;
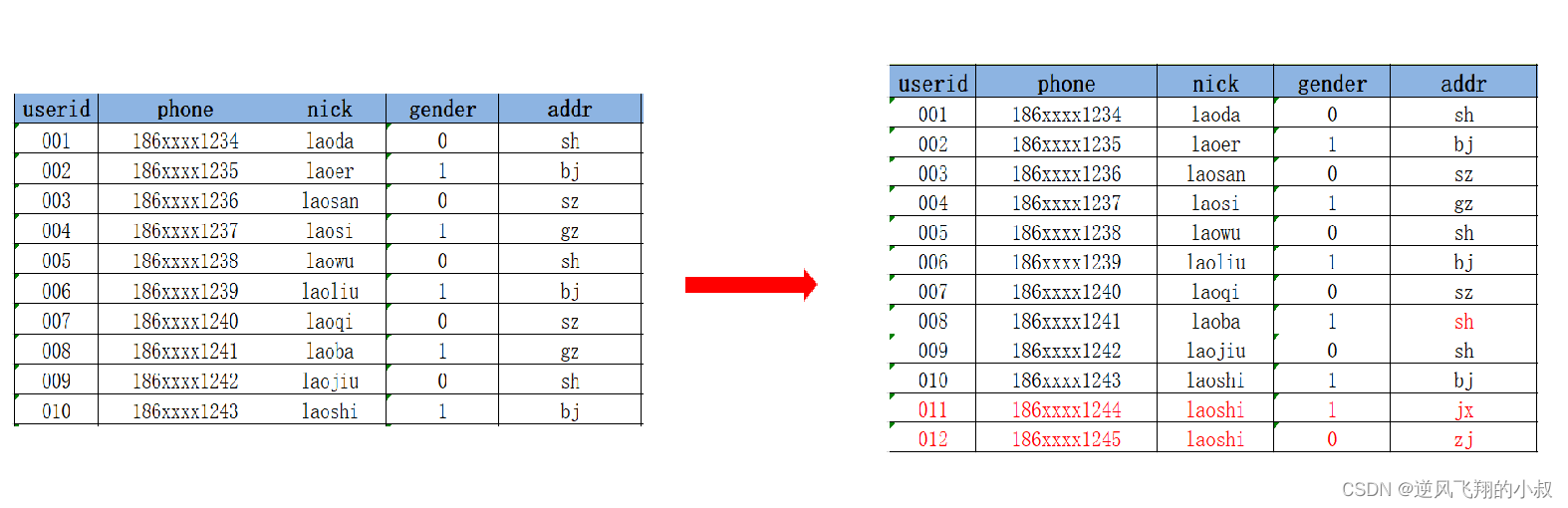
2.1.2 Solution 2
Every time the data changes, build a full snapshot table according to the date, one table per day
The advantage of this is: the state of all data at different times is recorded. The disadvantage: a lot of data that has not changed is redundantly stored, resulting in an excessively large amount of stored data;
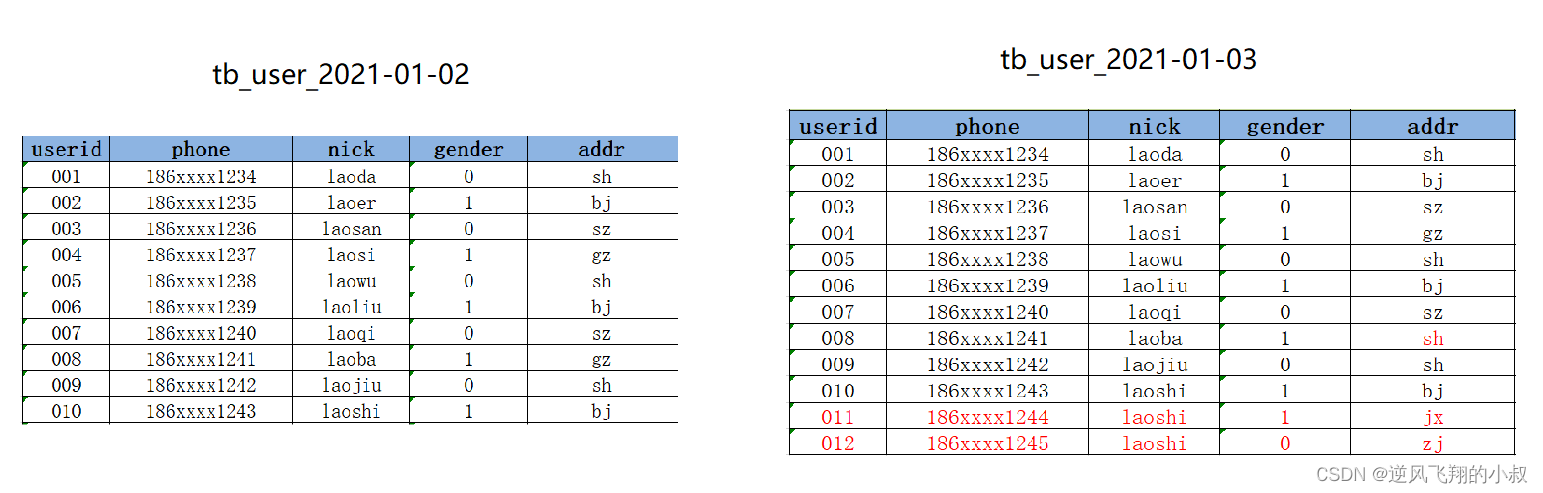
2.1.3 Solution 3
Build a zipper table and mark the time period of each state of the changed data by time, as shown in the data in the following chart. Its general meaning is that when the key business identification field in a piece of data is changed, a new piece of data will be added, and the The expiration time of this piece of data is set very large. As the boundary of this piece of data, when the data of the same primary key comes over again, only the changed fields need to be recorded in a new record; about the zipper table, the following will do a detailed narrative;
3. Design and principle of zipper watch
3.1 Functions and Application Scenarios
The zipper table is specially used to solve the problem of how to realize data storage when the data changes in the data warehouse.
The design of the zipper table is to record the status of the updated data. The data that has not been updated will not be stored in the status. It is used to store all the statuses of all data at different times. The life cycle of each status is marked by time. When querying, According to the requirements, the data of the status of the specified time range can be obtained. By default, the maximum value such as 9999-12-31 is used to represent the latest status.
As shown in the figure below, the complete life cycle of some orders is recorded;
3.2 Implementation steps
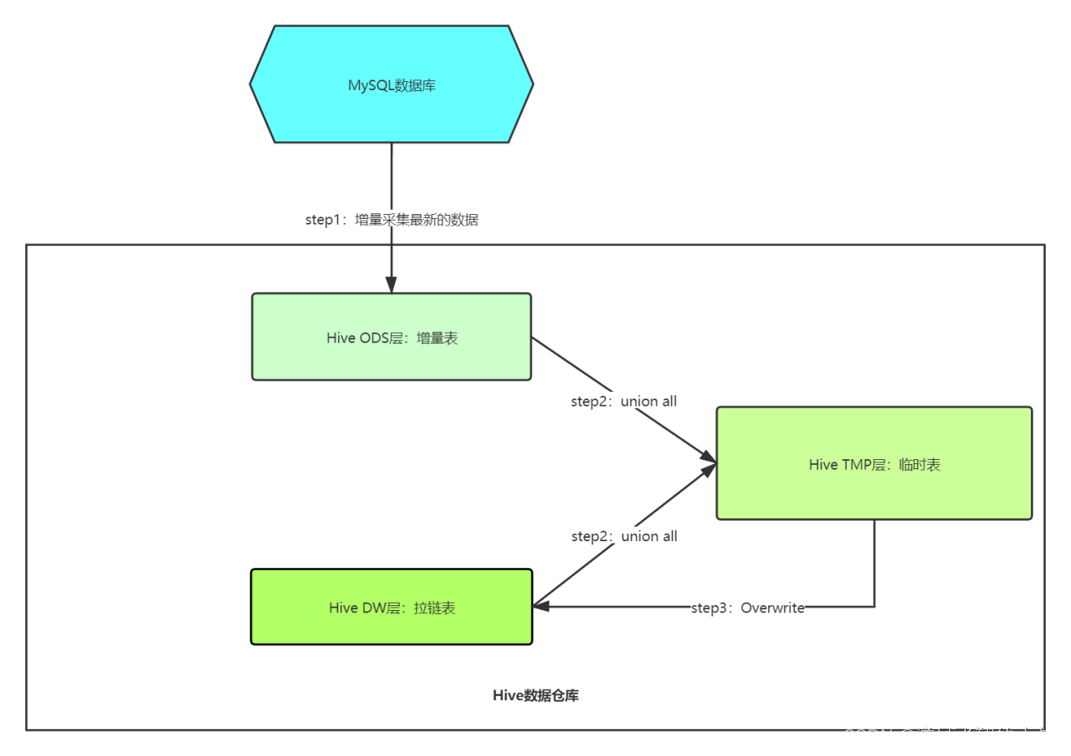
Use the following picture to illustrate its complete implementation process
Specifically, the operation steps are as follows:
3.2.1 Step1
Incrementally collect change data and put it into the incremental table.

3.2.2 Step2
Merge the data in the zipper table in Hive and the temporary table, and write the merged result into the temporary table.
3.2.3 Step3
Overwrite the data of the temporary table into the zipper table.
3.3 Operation Demonstration
Prepare a raw data, the content is as follows
3.3.1 Create a table and load data
--创建拉链表
create table dw_zipper(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) row format delimited fields terminated by '\t';
--加载模拟数据
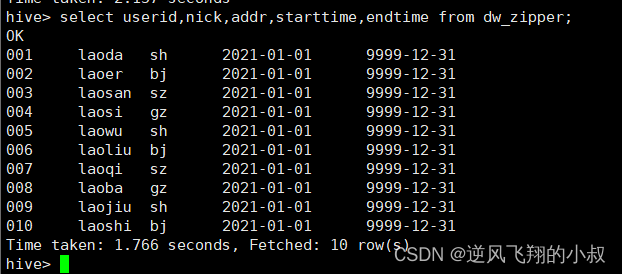
load data local inpath '/usr/local/soft/selectdata/zipper.txt' into table dw_zipper;Implementation process
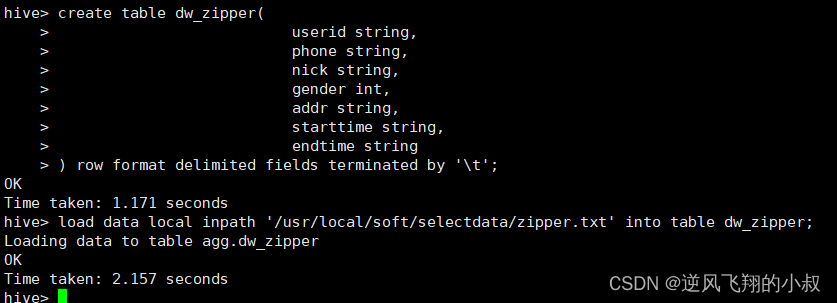
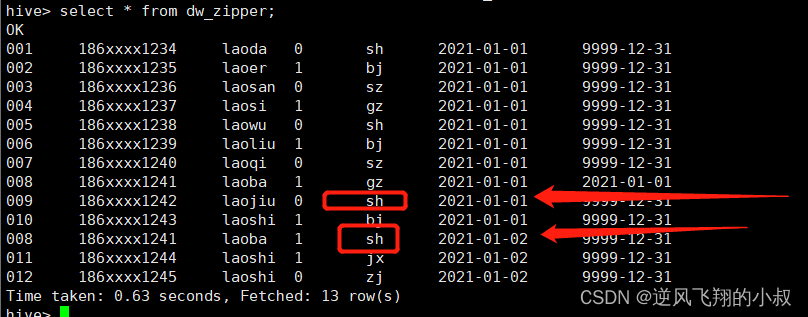
Check if the data is loaded
3.3.2 Simulating incremental data changes
The following are two new data and one changed data

Create an incremental table and load data
create table ods_zipper_update(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) row format delimited fields terminated by '\t';
load data local inpath '/usr/local/soft/selectdata/update.txt' into table ods_zipper_update;
Implementation process
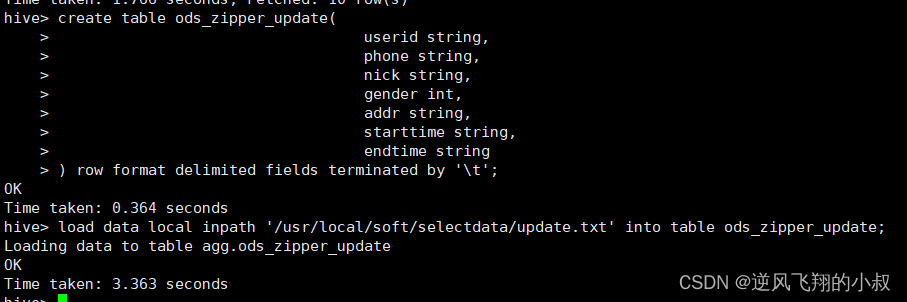
Check if the data is loaded successfully

3.3.3 Merge data
create a temporary table
create table tmp_zipper(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) row format delimited fields terminated by '\t';Implementation process

Merge zipper table and delta table
insert overwrite table tmp_zipper
select
userid,
phone,
nick,
gender,
addr,
starttime,
endtime
from ods_zipper_update
union all
--查询原来拉链表的所有数据,并将这次需要更新的数据的endTime更改为更新值的startTime
select
a.userid,
a.phone,
a.nick,
a.gender,
a.addr,
a.starttime,
--如果这条数据没有更新或者这条数据不是要更改的数据,就保留原来的值,否则就改为新数据的开始时间-1
if(b.userid is null or a.endtime < '9999-12-31', a.endtime , date_sub(b.starttime,1)) as endtime
from dw_zipper a left join ods_zipper_update b
on a.userid = b.userid ;Execute the above sql
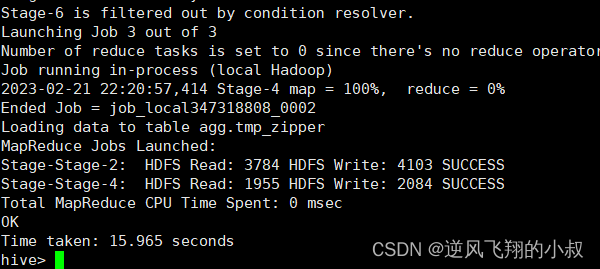
cover zipper table
insert overwrite table dw_zipper
select * from tmp_zipper;Implementation process

After the execution is completed, check the data of the zipper table, and you can see that 2 new pieces of data have been added, and at the same time, the time of the same piece of data has been updated;