Article directory
foreword
Support vector machine (S support (Support(Support V e c t o r Vector Vector M a c h i n e , S V M ) Machine,SVM) Machine,SVM ) originated from statistical learning theory, is a binary classification model, and is the most concerned algorithm in machine learning. Yes, it is the "most", not one of them .
1. Margins and support vectors
The core idea of the support vector machine classification method is to find a hyperplane in the feature space as the decision boundary to divide the samples into positive and negative classes, and make the generalization error of the model on the unknown data set as small as possible.
Hyperplane: In geometry, a hyperplane is a subspace of a space, which is a space whose dimension is one less than the space in which it resides. If the data space itself is three-dimensional, its hyperplane is a two-dimensional plane, and if the data space itself is two-dimensional, its hyperplane is a one-dimensional line.
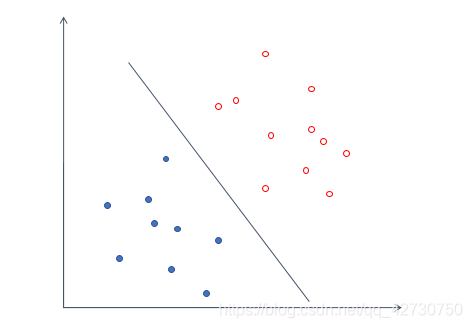
For example, the above set of data, we can easily draw a line to divide the above data into two categories, and the error is zero. For a data set, there may be many hyperplanes with an error of 0, such as the following:
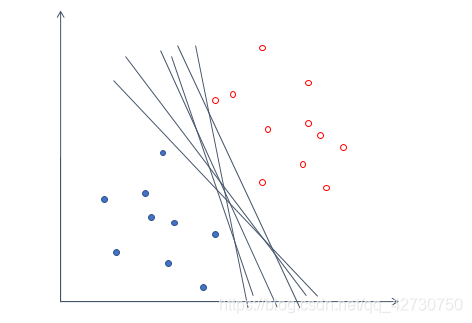
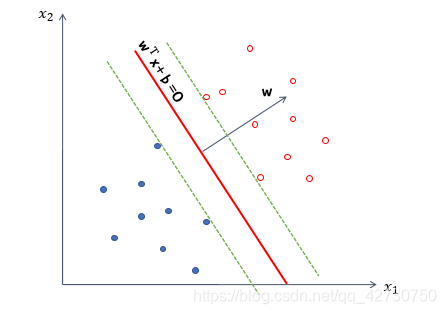
But such a model cannot guarantee good generalization performance, that is, it cannot guarantee that this hyperplane also performs well on unknown data sets. So we introduce a noun ------ 间隔( margin ) (margin)( ma r g in ) is to translate the hyperplane we found to both sides until it stops at the sample point closest to the hyperplane to form two new hyperplanes. The distance between the two hyperplanes is It is called "interval", and the hyperplane is in the middle of this "interval", that is, the distance between the hyperplane we choose and the two new hyperplanes after translation is equal. The few sample points closest to the hyperplane are called支持向量(support (support(support v e c t o r ) vector) vector)。
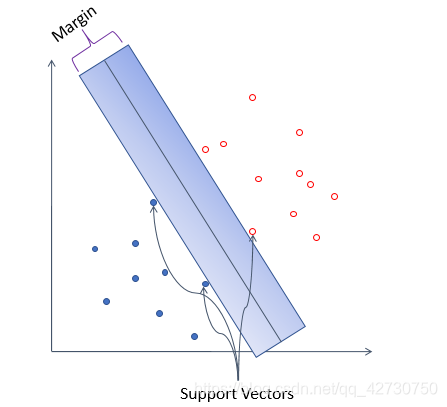

Comparing the above two figures, intuitively, the samples can be divided into two categories, but if some noise is added to it, it is obvious that the blue hyperplane has the best tolerance to local disturbances, because It's "wide enough", if you can't imagine it, look at the following example:
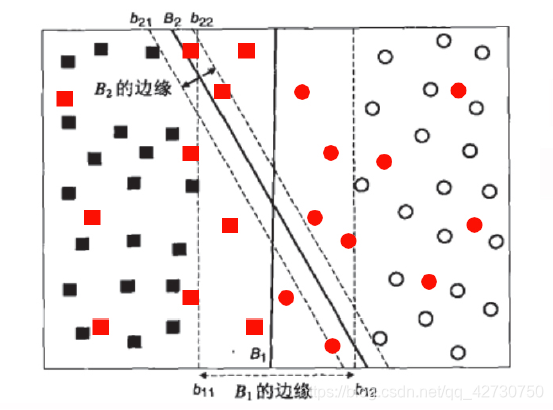
Obviously, after introducing some new data samples, B 1 B_1B1This hyperplane error is still 0, and the classification result is the most robust, B 2 B_2B2This hyperplane has a classification error because of the small interval. Therefore, when we are looking for a hyperplane, we hope that the larger the interval, the better.
The above is the support vector machine, that is, 通过找出间隔最大的超平面,来对数据进行分类the classifier of .
The model of support vector machine can be divided into the following three types from simple to complex:
∙ \bullet∙ Linearly Separable Support Vector Machines
∙ \bullet∙ Linear Support Vector Machines
∙ \bullet∙ Nonlinear SVM
Maximization via hard margin(hard (hard(hard m a r g i n margin margin m a x i m i z a t i o n ) maximization) max x imi z a t i o n ) , learn a linear classifier, that is, linearly separable support vector machine, also known as hard margin support vector machine; when the training data set is approximately linearly separable, maximize the(soft (soft(soft m a r g i n margin margin m a x i m i z a t i o n ) maximization) max x imi z a t i o n ) , also learn a linear classifier, that is, linear support vector machine, also known as soft margin support vector machine; when the training data set is linearly inseparable, by using the kernel technique (kernel (kernel(kernel t r i c k ) trick) t r ck k ) and soft margin maximization, learning nonlinear support vector machines.
Simplicity is the foundation of complexity, and it is also a special case of complexity.
2. Function equation description
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( xn , yn ) } , yi ∈ { − 1 , + 1 } D=\{(x_1,y_1 ) ),(x_2,y_2),\dots,(x_n,y_n)\},y_i \in \{-1,+1\}D={(x1,y1),(x2,y2),…,(xn,yn)},yi∈{
−1,+ 1 } , in the above sample space, any line can be expressed as: w T x + b = 0 \bm w^T\bm x+b=0wTx+b=0 其中 w = ( w 1 , w 2 , … , w d ) T \bm w=(w_1, w_2,\dots,w_d)^T w=(w1,w2,…,wd)T is the normal vector, which determines the direction of the hyperplane;bbb is the displacement term, which determines the distance between the hyperplane and the origin. Obviously, the hyperplane can also be normal vectorw \bm ww and displacementbbbOK .
For the convenience of derivation and calculation, we make the following regulations:
points above the hyperplane are marked as positive, and points below the hyperplane are marked as negative, that is, for( xi , yi ) ∈ D (x_i,y_i)\in D(xi,yi)∈D,若 y i = + 1 y_i=+1 yi=+1,则有 w T x i + b > 0 \bm w^T\bm x_i+b>0 wTxi+b>0;若 y i = − 1 y_i=-1 yi=−1,则有 w T x i + b < 0 \bm w^T\bm x_i+b<0 wTxi+b<0,表达式如下: { w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = − 1 \begin{cases} \bm w^T\bm x_i+b\geq+1, & y_i=+1\\ \\ \bm w^T\bm x_i+b\leq-1, & y_i=-1 \end{cases} ⎩
⎨
⎧wTxi+b≥+1,wTxi+b≤−1,yi=+1yi=−1 Among them, +1和-1表示两条平行于超平面的虚线到超平面的相对距离.
Then, any point x \bm x in the sample spaceThe distance from x to the hyperplane can be written as:r = ∣ w T + b ∣ ∣ ∣ w ∣ ∣ r=\frac {|\bm w^T+b|} {||\bm w||}r=∣∣w∣∣∣wT+b∣ From this, the sum of the distances from the support vectors of two different labels to the hyperplane, that is, the interval, can be expressed as: γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac {2} {||\bm w||}c=∣∣w∣∣2 Our goal is to find the hyperplane with the largest interval, that is, the parameter w \bm w that satisfies the following constraintsw andbbb , such thatγ \gammaγ最大,即 m a x w , b 2 ∣ ∣ w ∣ ∣ s u b j e c t t o y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , … , n \underset {\bm w,b} {max} \frac {2} {||\bm w||} \\[3pt] subject\ to \ y_i(\bm w^T\bm x_i+b)\geq1,i=1,2,\dots,n w,bmax∣∣w∣∣2subject to yi(wTxi+b)≥1,i=1,2,…,n Obviously, maximizing the intervalγ \gammaγ only needs to be minimized∣ ∣ w ∣ ∣ ||\bm w||∣∣ w ∣∣ is enough, so the constraints become as follows: minw , b 1 2 ∣ ∣ w ∣ ∣ 2 subject to yi ( w T xi + b ) ≥ 1 , i = 1 , 2 , … , n \underset { \bm w,b} {min} \frac {1} {2}||\bm w||^2 \\[3pt] subject\ to \ y_i(\bm w^T\bm x_i+b)\geq1 ,i=1,2,\dots,nw,bmin21∣∣w∣∣2subject to yi(wTxi+b)≥1,i=1,2,…,n
In fact, it is to take the reciprocal, so why add the square, as I said before, L 2 L_2L2Paradigm Well, adding a square is to eliminate the operation of square root and simplify the calculation process.
3. Parameter solution
To solve optimization problems with constraints, it is commonly used to introduce the Lagrange multiplier λ \lambdaλ constructs the Lagrangian function. In fact, this belongs to the conditional extremum problem of multivariate functions. You can refer to the conditional extremum of multivariate functions and the Lagrange multiplier method (standard\ Lagrange\ multiplier\ method)in the second volume of high mathematics.( s t and d a r d L a g r an g e m u lt i pl i er m e t h o d ) , let's briefly review it below.
3.1 Lagrangian multipliers
To find the function z = f ( x , y ) z=f(x,y)z=f(x,y ) in the additional conditionφ ( x , y ) = 0 \varphi(x,y)=0φ ( x ,y)=For the possible extreme points under 0 , you can first make the Lagrangian function L ( x , y ) = f ( x , y ) + λ φ ( x , y ) L(x,y)=f(x,y) +\lambda \varphi(x,y)L(x,y)=f(x,y)+λ φ ( x ,y ) where,λ \lambdaλ is a parameter, find its pairxxx、yyy和λ \lambdaThe first partial derivative of λ , and make it zero, then the simultaneous equations : { fx ( x , y ) + λ φ x ( x , y ) = 0 fy ( x , y ) + λ φ y ( x , y ) = 0 φ ( x , y ) = 0 \begin{cases} f_x(x,y)+\lambda \varphi_x(x,y)=0\\ \\ f_y(x,y)+\lambda \varphi_y( x,y)=0\\ \\ \varphi(x,y)=0\\ \end{cases}⎩
⎨
⎧fx(x,y)+l fx(x,y)=0fy(x,y)+l fy(x,y)=0φ ( x ,y)=0 With this system of equations solve xxx、yyy和λ \lambdaλ , the obtained( x , y ) (x,y)(x,y ) is the functionf ( x , y ) f(x,y)f(x,y ) in the additional conditionφ ( x , y ) = 0 \varphi(x,y)=0φ ( x ,y)=Possible extreme points below 0 .
If the function has more than two independent variables and more than one additional condition, for example, the function u = f ( x , y , z , t ) u=f(x,y,z,t)u=f(x,y,z,t ) under the additional conditionφ ( x , y , z , t ) = 0 ψ ( x , y , z , t ) = 0 \varphi (x,y,z,t)=0 \\[3pt] \psi ( x,y,z,t)=0φ ( x ,y,z,t)=0ψ ( x ,y,z,t)=0 , you can first make the Lagrangian functionL ( x , y , z , t ) = f ( x , y , z , t ) + λ f ( x , y , z , t ) + μ f ( x , y , z , t ) L(x,y,z,t)=f(x,y,z,t)+\lambda f(x,y,z,t)+\mu f(x, y, z, t)L(x,y,z,t)=f(x,y,z,t)+λf(x,y,z,t)+μf(x,y,z,t ) among them,λ , μ \lambda,\mul ,μ is a parameter, find its pairxxx、yyy、 z z z、 t t t、λ \lambdaλ和μ \muμ 's first-order partial derivative, and make it zero, then solve the simultaneous equations to get( x , y , z , t ) (x,y,z,t)(x,y,z,t)。
Come, let's look at a small problem:
find the function u = x 2 + y 2 + z 2 u=x^2+y^2+z^2u=x2+y2+z2 in the constraintsz = x 2 + y 2 z=x^2+y^2z=x2+y2和 x + y + z = 4 x+y+z=4 x+y+z=The maximum and minimum values under 4 .

3.2 Lagrangian dual function
Convex optimization problems: the function itself is quadratic ( quadratic ) (quadratic)( q u a d r a tic ) , the constraints of the function are linear under its parameters, such a function is called a convex optimization problem .
First construct the Lagrange function of the support vector machine, that is, the loss function: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − yi ( w T xi + b ) ) ( α i ≥ 0 ) L(\bm w,b,\bm \alpha)=\frac {1} {2}||\bm w||^2+\sum_{i=1}^ m\alpha_i\bigg(1-y_i\big(\bm w^T\bm x_i+b\big)\bigg)\ (\alpha_i \geq0)L(w,b,a )=21∣∣w∣∣2+i=1∑mai(1−yi(wTxi+b ) ) ( a i≥0 ) among them,α = ( α 1 , α 2 , … , α n ) T \alpha=(\alpha_1,\alpha_2,\dots,\alpha_n)^Ta=( a1,a2,…,an)T. _
It can be seen that the Lagrange function is divided into two parts: the first part is the same as our original loss function, and the second part expresses our constraints. We hope that the constructed loss function can not only represent our original loss function and constraints, but also express that we want to minimize the loss function to solvew \bm ww andbbThe intention of b , so we have to start withα \alphaα is a parameter, solveL ( w , b , α ) L(\bm w,b,\alpha)L(w,b,α ) , thenw \bm ww andbbb is a parameter, solveL ( w , b , α ) L(\bm w,b,\alpha)L(w,b,α ) minimum value. Therefore, our goal can be written as follows: minw , b max α i ≥ 0 L ( w , b , α ) ( α i ≥ 0 ) \underset {\bm w,b} {min}\ \underset {\alpha_i \geq0} {max} \ L(\bm w,b,\alpha)\ (\alpha_i \geq0)w,bmin ai≥0max L(w,b,a ) ( a i≥0)