"Machine Learning 100 Days" complete table of contents: table of contents
100 days of machine learning, today's talk is: Linear Support Vector Machine - Formula Derivation!
First of all, let’s look at such a problem. On a two-dimensional plane, we need to find a straight line to divide the positive and negative classes.
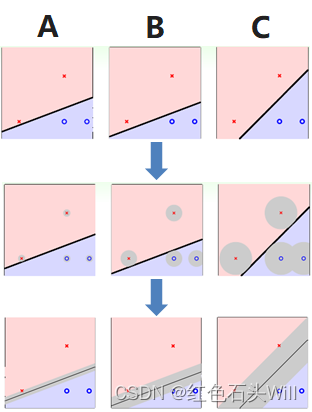
We found three straight lines A, B, and C. All three lines correctly classify all training samples. But which straight line is best? Intuitively, we will choose the straight line C, because this straight line is not only classified correctly, but also far away from the positive and negative samples. The benefit of this is increased fault tolerance and robustness of the classification line. Because if you want to ensure that the unknown test data can be correctly classified, it is best to have a certain distance between the classification line and the points of the positive and negative classes. This makes the circular area around each sample point "safe". The larger the circular area, the higher the tolerance of the classification line to the measurement data error, and the more "safe".
Therefore, the greater the distance between the point closest to the classification line and the classification line, the better the classification model. This is the core idea of the support vector machine algorithm.
First, we define the distance between the point closest to the classification line and the classification line as the maximum distance, which is represented by margin.

Our goal is to maximize the margin. The condition that must be met is: each training sample must be classified correctly. That is, the inequality is satisfied: