The content of this article is excerpted from the Paxi.ai article sharing. Paxi.ai is an AI tool based on GPT-4 to help users quickly use AI. Friends who are interested in the content can check their official website.
Since the release of GPT by OpenAI, AI projects, especially those represented by LLM, have developed rapidly. I believe everyone has understood the charm of large language models. We can develop many applications based on the capabilities of large language models. When it comes to these applications, there is a high probability that the vector database is inseparable. The vector database is the most important link in the sentence correlation calculation of the large language model. The vector database on the market has also sprung up with the popularity of AI, such as: Annoy, AtlasDB, AnalyticDB, DeepLake, DocArrayHnswSearch, DocArrayInMemorySearch, FAISS, LanceDB , Milvus, MyScale, OpenSearch, PGVector, SuperbaseVectorStore, Tair, Waviate, Qdrant, Pincone, Chroma, ElasticSearch, Redis, Typesense, Zilliz…
Some of these are already very mature commercial products, and some are just small community projects on Github. After careful research, we selected 5 of the most representative products for research. In the order of introduction they are: Pincone, Qdrant, Waviate, Milvus, Chroma. Introduce Pincone first today

Pincone
Pincone can be regarded as the hottest commercial vector database product at present. It recently received a B round of financing of 100 million US dollars, with a valuation of 750 million US dollars. It is also the vector database officially launched by OpenAI.
Their company will launch its own vector database product in 2021, which can be regarded as a very young company. The goal is to bring long-term memory capabilities to large language models. Paying customers include Shopify, Gong, HubSpot, Paxi, and Zapier.
Its logic is as follows:
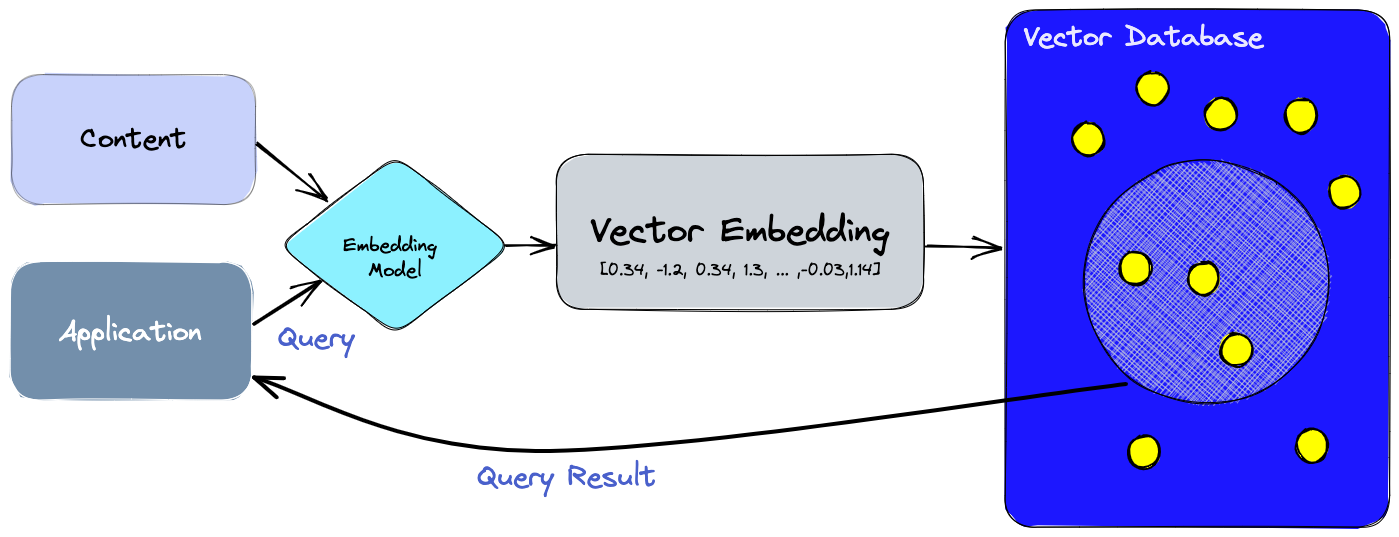
After the user enters the text content, the vector data corresponding to the text is calculated through the embedding model. Bring the vector data into the vector database and use the distance function to calculate the content with similar distances in the high-dimensional space, which is what we often call semantic search. Finally, the result is returned to the application layer for processing and then fed back to the user.
Pincone has the following characteristics
- high performance search
Pincone only provides network deployment. Through high-performance servers and self-developed index search algorithms, the similarity between content can be quickly calculated. Even if there are billions of orders of content, Pincone can respond with low latency and provide users with the best experience.
- Provide an easy-to-use API
Provides Python, NodeJS, and RestFulAPI for easy data management.
- full function management
Through the unique index generation algorithm, the index can be updated in real time for added, edited or deleted data, which takes effect immediately. Data changes can be seen in real time through the provided WebUI terminal. In addition, the vector data and metadata are bound and combined to quickly find the corresponding content.
- Easy expansion
Fully hosted on AWS or Google's high-performance computing platform, automatic expansion, no need to worry about architecture or algorithm, and no need to arrange a professional operation and maintenance team, all this will be done automatically for you. Free capacity is provided at the beginning, and only after the free capacity is exceeded, it is charged according to the usage, and the cost can be adjusted at any time according to the operating status of the product.
What can Pincone do?
When you gradually understand the capabilities of ChatGPT, you will eagerly hope that it can have long-term memory capabilities, so the vector database does this. After using the vector database, many functions can be realized, such as:
- Search: including semantic search, product search, multimodal search and question answering.
- Generation: Includes chatbots, text generation, image generation, and more.
- Security: anomaly detection, fraud identification, bot/threat detection, authentication.
- Personalization: recommendations, rankings, ads, alternates, and more.
- Analytics and machine learning: data labeling, model training, molecular search, generative artificial intelligence.
- Data management: pattern matching, deduplication, grouping, tagging.
At present, 80% of AI products need to use these capabilities provided by the vector database.
How to access Pincone
First open the official website: Vector Database for Vector Search | Pinecone , click "Free Registration" in the upper right corner
 After filling in the email password, enter the WebUI management background.
After filling in the email password, enter the WebUI management background.
Here there are 5 functions on the left, namely:
project:
A free account can only create one default project to share the hardware performance of the device with other users. It is enough to do testing and debugging. If you want to commercialize the application, it is better to pay.
index:
The index here can be understood as a traditional database concept. An index is a database. In addition, the vector database does not have the concept of a table, so an index here is also a table. Later, we will introduce how to implement multiple tables in an index.
Clicking on the index will let you create a: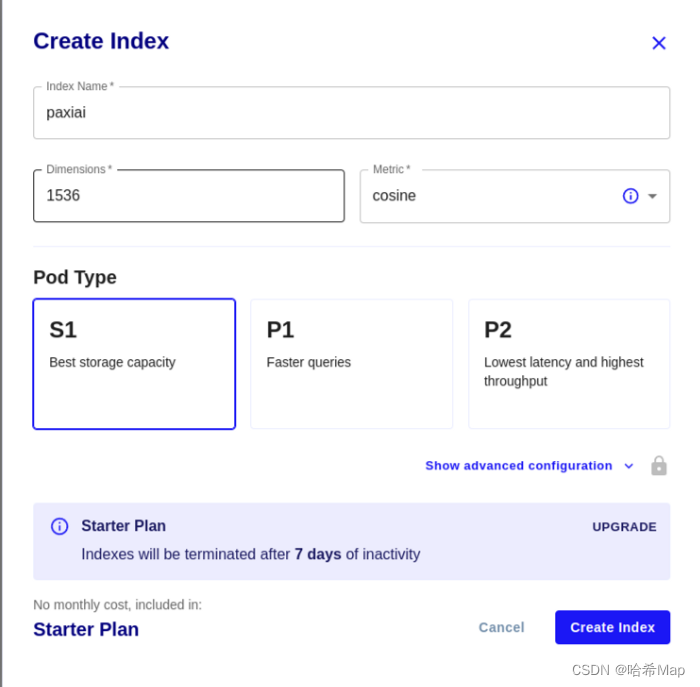
Fill in the database name for the index name here, and you can also fill in the project name, such as "paxi", which will require all lowercase.
Dimension: Fill in your embedded data dimension here. If you use chatGPT, it will be 1536 dimensions. The specific dimensions of each model are different, so you need to carefully study the model you use.
The distance function can be checked according to your needs, and the cosine function is selected by default.
The type of Pod is selected according to your needs.
S1: high storage
P1: high performance
P2: top match
Something to note here is:
Free users will be cleared if there is no interaction within 7 days
This is what it looks like after creation.
gather:
A collection is a snapshot of the indexed database.
Creating a collection is very simple, just give it a name
A snapshot can be understood as an index backup at that time, which is used to restore data at any time, and can also be used as a data backup of various versions. Free users can only create one collection.
APIKey:
Use Python, NodeJS, and RestFul API to add, delete, check, and modify the database. The usage of APIKey is not demonstrated here. For specific examples, please refer to the official documentation. Overview
member:
Invite other members to co-manage the project.
data management
The data management part introduces how to use WebUI to manage data. In fact, its API is also quite simple, which is the basic RestFulAPI call, which will not be introduced here.
The index name, index URL, configuration environment, distance algorithm, Pod type, dimension, usage, etc. are displayed here.
 The Indexes section shows the current total number of vectors, namespaces, and the number of indexes for each namespace. The namespace here can correspond to the table concept in the traditional database.
The Indexes section shows the current total number of vectors, namespaces, and the number of indexes for each namespace. The namespace here can correspond to the table concept in the traditional database.
The Metrics section is used to view data usage.
The bottom part is to operate the database
UPSERT adds or modifies data
QUERY query data
UPDATEModify data
FETCH to get data
DELETEDelete data
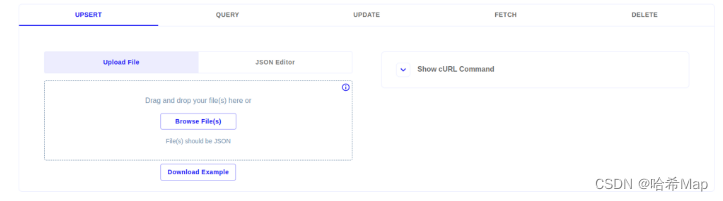
These operations all support file batch operations, Json editor submission, and cURL calls.
It is worth mentioning that the batch operation of files is not friendly to Chinese, uploading Chinese content will become garbled characters, JSON editor and cURL operations do not have this problem
Summarize
Frankly speaking, Pincone is indeed an easy-to-use and beginner-friendly vector database. The free space it provides is enough for most scenarios. The convenient API, simple WebUI, no need for deployment, and automatic expansion are all very easy to use. The only downside is that compared to other products, the starting cost is higher. For partners who are new to the vector database, it is highly recommended!