Article directory
1. Key components in machine learning
1. Data
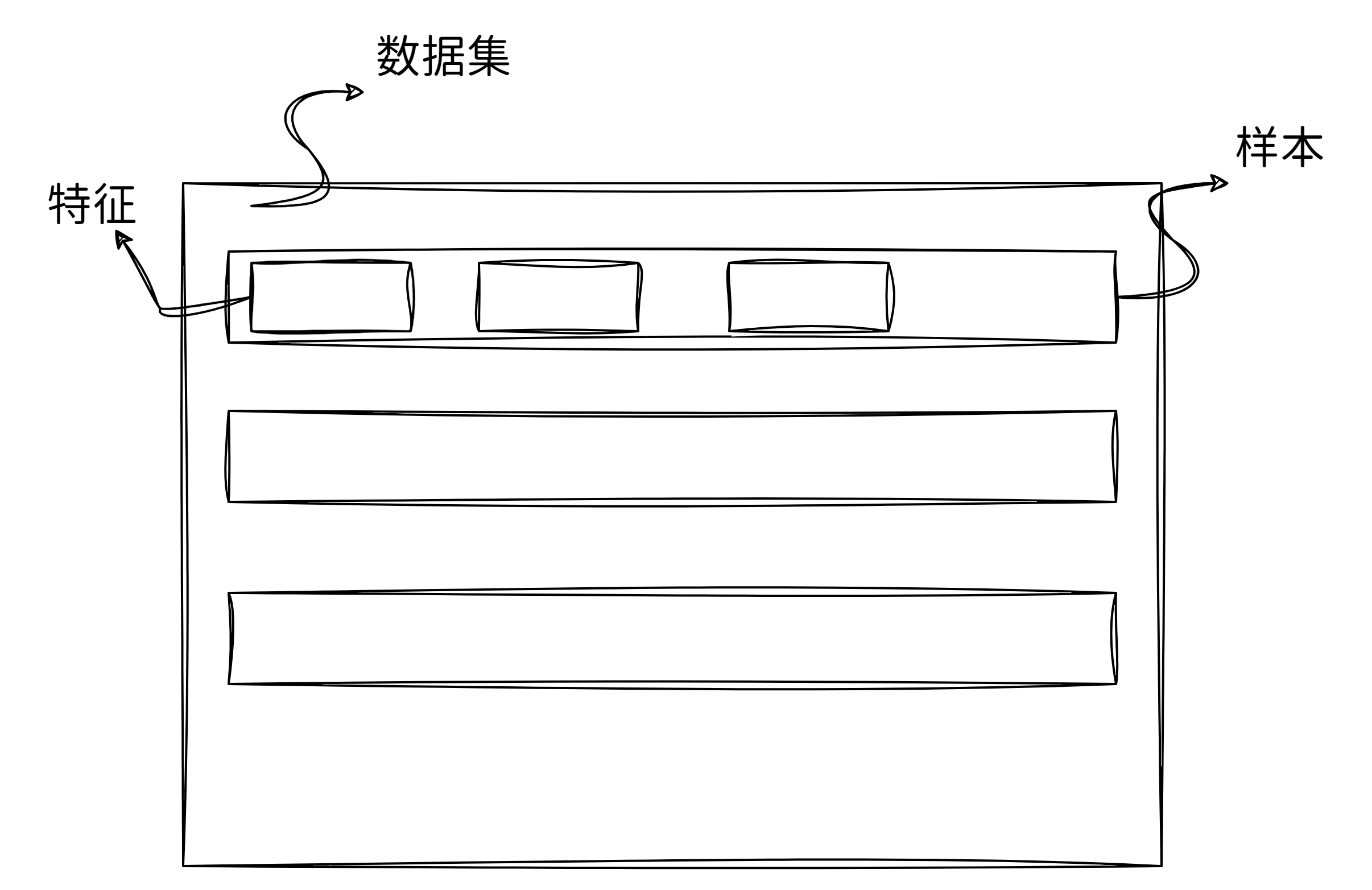
The collection of data is called 数据集, each data set is composed of one by one 样本(sample,example)(or called 数据点(data point)/ 数据实例(data instance)), and each sample is composed of a set of 特征(features,或协变量(covariates))attributes. The attributes that need to be predicted are called 标签(label 或目标(target).
2. Model
In deep learning, a model is a mathematical function that maps input data to output data. This function usually consists of multiple layers, each containing one or more trainable parameters. These parameters are dynamically adjusted during training to minimize the difference between the output predicted by the model and the actual output (i.e. the loss function). The basic and common neural network models in deep learning include fully connected neural networks, convolutional neural networks, recurrent neural networks, and confrontation generation networks.
3. Objective function
目标函数It is a measure used to evaluate the quality of the model. Usually we hope that the smaller the value corresponding to the objective function, the better, so the objective function is also often called 损失函数(loss function).
4. Algorithms
Once we have some data sources and their representations, a model, and an appropriate loss function, then we need an algorithm that can search for the best parameters to minimize the loss function. In deep learning, most popular optimization algorithms are usually based on a basic method - gradient descent. In short, at each step, gradient descent examines each parameter to see in which direction the training set loss would move if only a small change was made to that parameter. Then, it optimizes the parameters in the direction that can reduce the loss.
2. Various machine learning problems
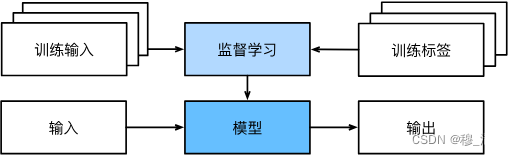
1. Supervised learning
The process of supervised learning is as follows:
1.1 regression
Regression problems refer to a class of forecasting problems in which we try to predict a continuous output variable using a functional model, such as predicting commodity prices, stock prices, house prices, and so on. The goal of regression analysis is to find a function that, given an input, accurately predicts a numerical output. The regression problem is to use the features (independent variables) in historical data and the corresponding target values (dependent variables) to build a model, and use the model to predict future data.
In regression problems, commonly used models include linear regression, polynomial regression, decision tree regression, random forest regression, support vector regression, neural network regression, etc. The goal of these models is to find a best-fit function that makes the most accurate match between the relationship between input features and output variables. In order to make accurate predictions on unknown data, we need to use the training data to train the model first, and evaluate and optimize the model performance to improve the predictive ability and generalization ability of the model.
1.2 Classification
Classification problems are a class of prediction problems in which we attempt to map input data to a finite, predefined discrete class . For example, classifying an email as spam or not spam based on the content of the message text, or classifying a patient's diagnosis as cancer and not cancer. The classification problem is to classify the given input into one or several of the predefined categories.
In classification problems, we need to learn the mapping relationship between input data and labels (categories) from the training data, and apply this experience to make predictions for new input data. In machine learning, commonly used classification methods include decision trees, support vector machines, naive Bayesian, logistic regression, artificial neural networks, etc.
1.3 Flagging issues
Labeling problems, also known as labeling problems or sequence labeling problems, refer to the problem of classifying each element in a sequence (such as natural language text) . For example, in natural language processing, labeling each word in a sentence as a noun, verb, adjective, or adverb, etc., is a labeling problem. The purpose of the labeling problem is to learn a model from existing labeled samples so that it can automatically label unlabeled samples.
In the labeling problem, commonly used algorithms include Hidden Markov Model (HMM), Conditional Random Field (CRF), Recurrent Neural Network (RNN) and Transformer (Transformer)**, etc. These algorithms usually use some statistical models or machine learning algorithms, use input data to construct features, and classify the constructed features.
1.4 Search
The search problem refers to the problem of finding the optimal solution or optimal decision in a large-scale search space . For example, in a chess game, it is a search problem to find the optimal solution by searching all possible moves in a given initial position. Search problems usually involve finding the optimal choice from a large number of possible choices, so more efficient algorithms such as heuristic search are often needed to solve them.
Search problems can be solved with search algorithms. Common search algorithms include breadth-first search, depth-first search, A algorithm, minimum cost search, and so on. In the search algorithm, some heuristic methods are usually used to help us search for the optimal solution more efficiently. For example, in Algorithm A, we guide the search direction by estimating at each search node the distance from that node to the goal state.
1.5 Recommendation system
The main goal of a recommendation system is to select products, services or information for users that best meet their needs based on their historical behavior, interests, and other characteristics, thereby improving user experience and increasing transaction volume . Machine learning techniques can make recommendation systems more accurate and personalized .
In the recommendation system, machine learning technology can help us mine valuable information from massive data, build user interest models, product attribute models, user-product relationship models, etc., and realize intelligent recommendation strategies. Common machine learning algorithms include collaborative filtering, content-based filtering, deep learning, ensemble learning, and more. These algorithms can effectively deal with the cold start problem, data sparsity, timeliness and other problems in the recommendation system, and can learn and predict based on the user's historical behavior and other data sources to provide users with more accurate recommendation results.
1.6 Sequence Learning
Sequence learning refers to a learning method for sequence data (such as text, speech, time series data, etc.) in machine learning, including tasks such as sequence classification, sequence labeling, sequence generation, and sequence-to-sequence .
Sequence classification refers to the classification of sequence data, such as classifying a speech sequence as a specific word or classifying a text sequence as an emotion category. In sequence classification, the input is a sequence and the output is a predicted label or set of labels.
Sequence labeling refers to classifying each element in a sequence, such as labeling the text label corresponding to each moment in an audio file, or labeling the part of speech of each word in a text. In sequence annotation, the input is a sequence and the output is a sequence of sequence labels.
Sequence generation refers to giving an input sequence so that the algorithm can generate the corresponding output sequence, such as machine translation, image annotation, etc. In sequence generation, the input is a sequence and the output is also a sequence.
Sequence-to-sequence learning refers to the learning problem of mapping one sequence to another, such as machine translation and speech synthesis tasks. In sequence-to-sequence learning, the input is a sequence and the output is also a sequence.
In sequence learning, commonly used methods include recurrent neural network (RNN), long short-term memory network (LSTM), bidirectional RNN, attention mechanism, etc. These methods can extract contextual information from sequence data to improve learning performance. Sequence learning has a wide range of applications in natural language processing, speech recognition, image processing and other fields.
2. Unsupervised Learning
Unsupervised learning is for tasks that do not have very specific goals and need to be learned spontaneously. has:
-
Clustering problem : Can we classify data without labels? For example, given a set of photos, can we separate them into landscape photos, dogs, babies, cats, and mountain photos? Similarly, given a group of users' web browsing records, can we cluster users with similar behavior?
-
The principal component analysis problem : Can we find a small number of parameters that accurately capture the linearly dependent properties of the data? For example, the trajectory of a ball can be described by the ball's velocity, diameter, and mass. As another example, tailors have developed a small set of parameters that fairly accurately describe the shape of the human body to fit the clothes. Another example: is there a representation of an (arbitrarily structured) object in Euclidean space such that its symbolic properties are well matched? This could be used to describe entities and their relationships, e.g. "Rome" "
Italy "
France"
"Paris". -
The question of causality and probabilistic graphical models : Can we describe the root cause of much of the observed data? For example, if we have demographic data on housing prices, pollution, crime, geography, education, and wages, can we simply discover relationships between them based on empirical data?
-
Generative adversarial networks : Give us a way to synthesize data, even complex unstructured data like images and audio. The underlying statistical mechanisms are tests that check whether real and fake data are the same, and it is another important and exciting area of unsupervised learning.
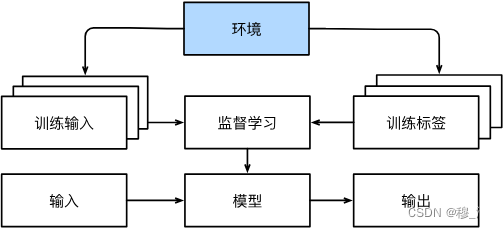
3. Interact with the environment
Interacting with the environment refers to the process by which a machine learning system collects information, learns, and improves its behavior by interacting with the external environment . In other words, a machine learning system learns and evolves in a dynamic, real-time environment, in which its output dynamically adjusts as inputs and the environment change.
The process of interacting with the environment often requires machine learning systems to have both sensing and execution capabilities. Sensing capabilities can enable machine learning systems to perceive changes in the environment, such as collecting data through sensors or cameras. Execution capability requires the machine learning system to be able to perform actions, such as manipulating the environment through a robotic arm or actuator.
Interacting with the environment is an important concept in machine learning, which is widely used in the real world, such as robotics, autonomous driving, smart home and other fields that require machine learning systems to have the ability to interact with the environment.
4. Reinforcement Learning
Reinforcement learning is an artificial intelligence algorithm that, by interacting with its environment, learns how to make optimal decisions to achieve a certain goal. In reinforcement learning, there is an agent (agent) and an environment (environment) . The agent affects the environment by performing certain actions and obtains corresponding rewards or punishments. The goal of the agent is to continuously interact with the environment. Learn how to make optimal decisions to maximize rewards and reach their goals.
Unlike supervised and unsupervised learning, reinforcement learning does not rely on labeled data or prior knowledge. Instead, it is a method of learning by interacting with the environment, and after many trials, the agent can improve the policy to achieve higher rewards. Reinforcement learning has achieved good results in various application fields such as games, robots, natural language processing, and recommendation systems.

3. The development of deep learning
Here is a brief list of some cases that promote the progress of deep learning.
-
New capacity control methods, such as dropout (Srivastava et al., 2014), help mitigate the danger of overfitting. This is achieved by applying noise injection (Bishop, 1995) throughout the neural network, replacing weights with random variables for training purposes.
-
The attention mechanism solves a problem that has plagued statistics for more than a century: how to increase the memory and complexity of the system without increasing the learnable parameters. Researchers found an elegant solution by using pointer structures that can only be viewed as learnable (Bahdanau et al., 2014). Instead of remembering the entire text sequence (e.g. for machine translation in a fixed-dimensional representation), all that needs to be stored are pointers to intermediate states of the translation process. This greatly improves accuracy on long sequences, as the model no longer needs to memorize the entire sequence before it starts generating new ones.
-
Multi-stage design. For example, memory networks (Sukhbaatar et al., 2015) and neural programmer-interpreters (Reed and De Freitas, 2015). They allow statistical modelers to describe iterative methods for inference. These tools allow repeated modification of the internal state of a deep neural network to execute subsequent steps in the inference chain, similar to how a processor modifies the memory used for computation.
-
Another key development was the invention of generative adversarial networks (Goodfellow et al., 2014). Traditionally, statistical methods for density estimation and generative models have focused on finding suitable probability distributions (often approximated) and sampling algorithms. Consequently, these algorithms are largely limited by the inherent flexibility of statistical models. The key innovation of generative adversarial networks is to replace the sampler with an arbitrary algorithm with differentiable parameters. This data is then adjusted so that the discriminator (actually a two-sample test) cannot distinguish fake data from real data. By the ability to generate data using arbitrary algorithms, it opens the door to density estimation for a variety of techniques. Examples of galloping zebras (Zhu et al., 2017) and pseudonymous human faces (Karras et al., 2017) demonstrate this progress. Even amateur doodlers can generate photorealistic images from sketches describing scene layouts ((Park et al., 2019)).
-
In many cases, a single GPU is insufficient to handle the large amount of data available for training. The ability to build parallel and distributed training algorithms has improved dramatically over the past decade. One of the key challenges in designing scalable algorithms is the workhorse of deep learning optimization - stochastic gradient descent, which relies on relatively small mini-batches of data to process. At the same time, small batches limit the efficiency of GPUs. Thus, training on 1024 GPUs with a mini-batch size of e.g. 32 images per batch equates to a total mini-batch of about 32000 images. Recent work, first by (Li, 2017), followed by (You et al., 2017) and (Jia et al., 2018), increased the observation size to 64000, and the ResNet-50 model on ImageNet The training time on the dataset is reduced to less than 7 minutes. For comparison - the initial training time is in days.
-
The ability to parallelize computing has also made a rather critical contribution to the progress of reinforcement learning. This has led to major advances in computers achieving superhuman performance in Go, the games of Atari, StarCraft, and physics simulations (for example, using MuJoCo). See e.g. (Silver et al., 2016) for an illustration of how this was implemented in AlphaGo. In short, reinforcement learning works best if a large number of (state, action, reward) triples are available, i.e. whenever it is possible to try many things to learn how they are related. Simulation provides such a path.
-
Deep learning frameworks have played a vital role in spreading ideas. First-generation frameworks that allow for easy modeling include Caffe, Torch, and Theano. Many seminal papers have been written using these tools. So far, they have been superseded by TensorFlow (often used through its high-level API Keras), CNTK, Caffe 2, and Apache MXNet. The third generation of tools, the imperative tools for deep learning, was arguably pioneered by Chainer, which uses a syntax similar to Python's NumPy to describe models. This idea was adopted by PyTorch, MXNet's Gluon API, and Jax.