Suddenly, I turned to the code that I just started learning deep learning a few years ago, took it out and recorded it, and then matched it with the pictures I found on Baidu, so that I can look back and look at some models when I have time in the future.
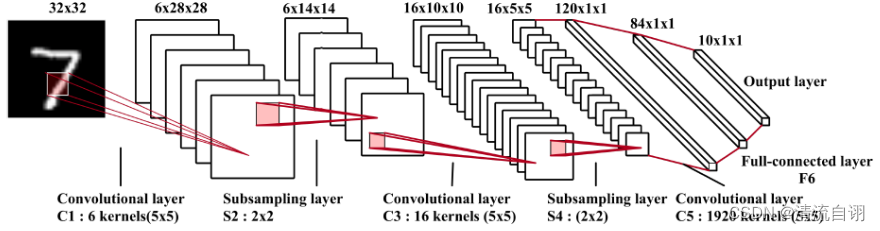
LeNet
class LeNet ( nn. Module) :
def __init__ ( self) :
super ( LeNet, self) . __init__( )
self. conv1 = nn. Conv2d( 3 , 6 , 5 )
self. pool = nn. MaxPool2d( 2 , 2 )
self. conv2 = nn. Conv2d( 6 , 16 , 5 )
self. fc1 = nn. Linear( 16 * 5 * 5 , 120 )
self. fc2 = nn. Linear( 120 , 84 )
self. fc3 = nn. Linear( 84 , 10 )
self. sigmoid = nn. Sigmoid( ) def forward ( self, x) :
x = self. pool( self. conv1( x) )
x = self. pool( self. conv2( x) )
x = x. view( - 1 , 16 * 5 * 5 )
x = self. sigmoid( self. fc1( x) )
x = self. sigmoid( self. fc2( x) )
x = self. fc3( x)
return x= LeNet( )
VggNet
def vgg_block ( num_convs, in_channels, out_channels) :
net = [ nn. Conv2d( in_channels, out_channels, kernel_size= 3 , padding= 1 ) , nn. ReLU( True ) ] for i in range ( num_convs - 1 ) :
net. append( nn. Conv2d( out_channels, out_channels, kernel_size= 3 , padding= 1 ) )
net. append( nn. ReLU( True ) )
net. append( nn. MaxPool2d( 2 , 2 ) )
return nn. Sequential( * net) def vgg_stack ( num_convs, channels) :
net = [ ]
for n, c in zip ( num_convs, channels) :
in_c = c[ 0 ]
out_c = c[ 1 ]
net. append( vgg_block( n, in_c, out_c) )
return nn. Sequential( * net) = vgg_stack( ( 1 , 1 , 2 , 2 , 2 ) , ( ( 3 , 64 ) , ( 64 , 128 ) , ( 128 , 256 ) , ( 256 , 512 ) , ( 512 , 512 ) ) )
print ( net) '''
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(3): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(4): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
'''
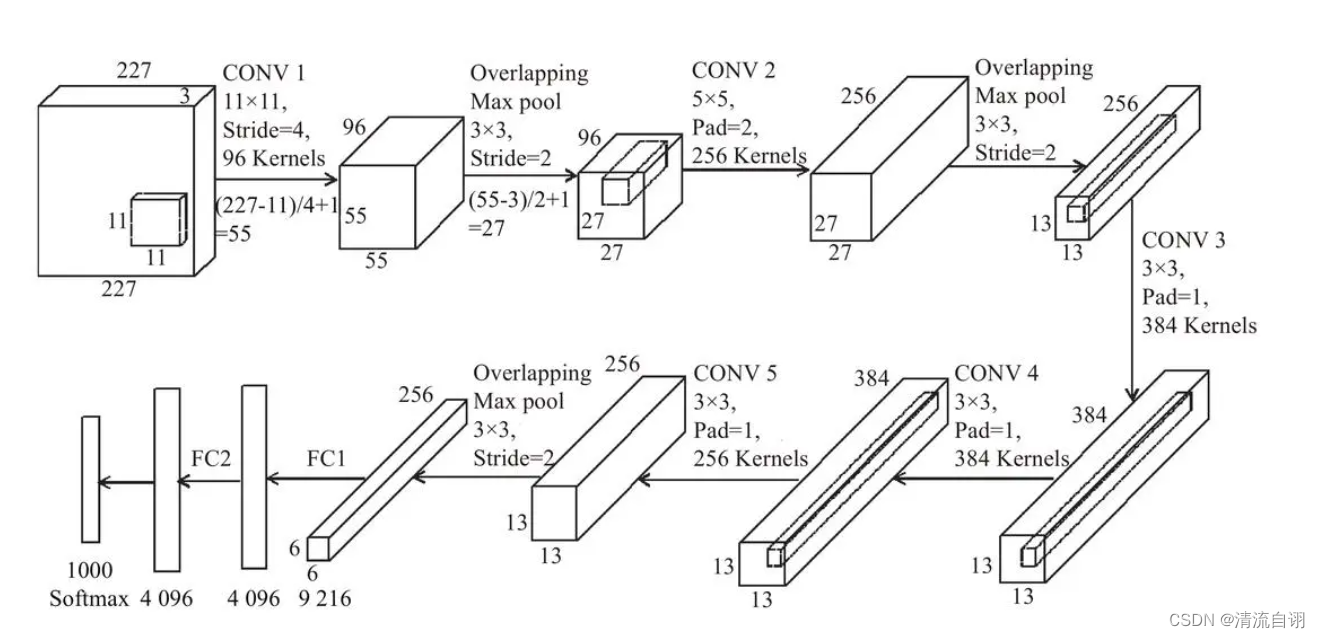
AlexNet
class AlexNet ( nn. Module) :
def __init__ ( self) :
super ( AlexNet, self) . __init__( )
self. conv1 = torch. nn. Sequential(
torch. nn. Conv2d( in_channels= 3 , out_channels= 96 , kernel_size= 11 , stride= 4 , padding= 0 ) ,
torch. nn. ReLU( ) ,
torch. nn. MaxPool2d( kernel_size= 3 , stride= 2 )
)
self. conv2 = torch. nn. Sequential(
torch. nn. Conv2d( 96 , 256 , 5 , 1 , 2 ) ,
torch. nn. ReLU( ) ,
torch. nn. MaxPool2d( 3 , 2 )
)
self. conv3 = torch. nn. Sequential(
torch. nn. Conv2d( 256 , 384 , 3 , 1 , 1 ) ,
torch. nn. ReLU( ) ,
)
self. conv4 = torch. nn. Sequential(
torch. nn. Conv2d( 384 , 384 , 3 , 1 , 1 ) ,
torch. nn. ReLU( ) ,
)
self. conv5 = torch. nn. Sequential(
torch. nn. Conv2d( 384 , 256 , 3 , 1 , 1 ) ,
torch. nn. ReLU( ) ,
torch. nn. MaxPool2d( 3 , 2 )
) . classifier = torch. nn. Sequential(
torch. nn. Linear( 9216 , 4096 ) ,
torch. nn. ReLU( ) ,
torch. nn. Dropout( 0.5 ) ,
torch. nn. Linear( 4096 , 4096 ) ,
torch. nn. ReLU( ) ,
torch. nn. Dropout( 0.5 ) ,
torch. nn. Linear( 4096 , 50 )
)
def forward ( self, x) :
conv1_out = self. conv1( x)
conv2_out = self. conv2( conv1_out)
conv3_out = self. conv3( conv2_out)
conv4_out = self. conv4( conv3_out)
conv5_out = self. conv5( conv4_out)
res = conv5_out. view( conv5_out. size( 0 ) , - 1 )
out = self. classifier( res)
return out= AlexNet( )
print ( net) '''
AlexNet是LeNet的升级版,大胆地采用了更深的网络结构、Relu、dropout、数据增强等。同时图片变大了,
感受野和步长也随之变大。
AlexNet(
(conv1): Sequential(
(0): Conv2d(3, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv3): Sequential(
(0): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conv4): Sequential(
(0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conv5): Sequential(
(0): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=9216, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=50, bias=True)
)
)
'''
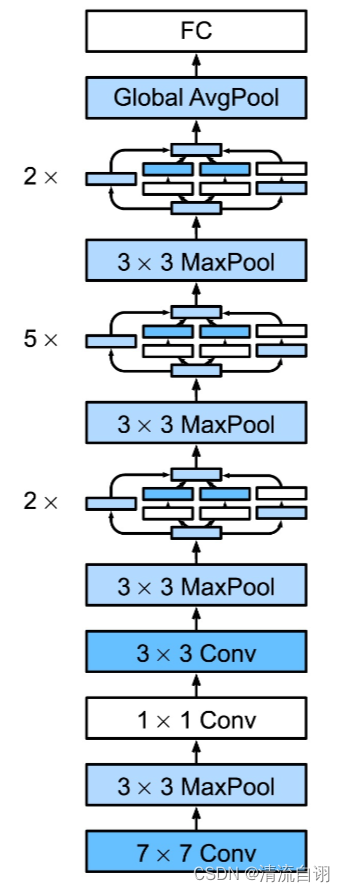
GoogLeNet
def conv_relu ( in_channel, out_channel, kernel, stride= 1 , padding= 0 ) :
layer = nn. Sequential(
nn. Conv2d( in_channel, out_channel, kernel, stride, padding) ,
nn. BatchNorm2d( out_channel, eps= 1e-3 ) ,
nn. ReLU( True )
)
return layerclass inception ( nn. Module) :
def __init__ ( self, in_channel, out1_1, out2_1, out2_3, out3_1, out3_5, out4_1) :
super ( inception, self) . __init__( )
self. branch1x1 = conv_relu( in_channel, out1_1, 1 ) . branch3x3 = nn. Sequential(
conv_relu( in_channel, out2_1, 1 ) ,
conv_relu( out2_1, out2_3, 3 , padding= 1 )
) . branch5x5 = nn. Sequential(
conv_relu( in_channel, out3_1, 1 ) ,
conv_relu( out3_1, out3_5, 5 , padding= 2 )
) . branch_pool = nn. Sequential(
nn. MaxPool2d( 3 , stride= 1 , padding= 1 ) ,
conv_relu( in_channel, out4_1, 1 )
) def forward ( self, x) :
f1 = self. branch1x1( x)
f2 = self. branch3x3( x)
f3 = self. branch5x5( x)
f4 = self. branch_pool( x)
output = torch. cat( ( f1, f2, f3, f4) , dim= 1 )
return outputclass googlenet ( nn. Module) :
def __init__ ( self, in_channel, num_classes) :
super ( googlenet, self) . __init__( )
self. block1 = nn. Sequential(
conv_relu( in_channel, out_channel= 64 , kernel= 7 , stride= 2 , padding= 3 ) ,
nn. MaxPool2d( 3 , 2 )
) . block2 = nn. Sequential(
conv_relu( 64 , 64 , kernel= 1 ) ,
conv_relu( 64 , 192 , kernel= 3 , padding= 1 ) ,
nn. MaxPool2d( 3 , 2 )
) . block3 = nn. Sequential(
inception( 192 , 64 , 96 , 128 , 16 , 32 , 32 ) ,
inception( 256 , 128 , 128 , 192 , 32 , 96 , 64 ) ,
nn. MaxPool2d( 3 , 2 )
) . block4 = nn. Sequential(
inception( 480 , 192 , 96 , 208 , 16 , 48 , 64 ) ,
inception( 512 , 160 , 112 , 224 , 24 , 64 , 64 ) ,
inception( 512 , 128 , 128 , 256 , 24 , 64 , 64 ) ,
inception( 512 , 112 , 144 , 288 , 32 , 64 , 64 ) ,
inception( 528 , 256 , 160 , 320 , 32 , 128 , 128 ) ,
nn. MaxPool2d( 3 , 2 )
) . block5 = nn. Sequential(
inception( 832 , 256 , 160 , 320 , 32 , 128 , 128 ) ,
inception( 832 , 384 , 182 , 384 , 48 , 128 , 128 ) ,
nn. AvgPool2d( 2 )
) . classifier = nn. Linear( 1024 , num_classes) def forward ( self, x) :
x = self. block1( x)
x = self. block2( x)
x = self. block3( x)
x = self. block4( x)
x = self. block5( x)
x = x. view( x. shape[ 0 ] , - 1 )
x = self. classifier( x)
return x= googlenet( 3 , 10 )