
In the DINO code study notes (1), the parameters before inputting the transformer have been processed.
In the DINO code study notes (2), the encoder part is stroked again.
In the DINO code study notes (3), the decoder part has been reviewed, and the main part of DINO has been reviewed above. The default configuration of DINO_4scale.py is used, and the last part is the loss part.
Take DINO code study notes (3)
# deformable-detr-like anchor update
# reference_before_sigmoid = inverse_sigmoid(reference[:-1]) # n_dec, bs, nq, 4
outputs_coord_list = []
for dec_lid, (layer_ref_sig, layer_bbox_embed, layer_hs) in enumerate(zip(reference[:-1], self.bbox_embed, hs)):
layer_delta_unsig = layer_bbox_embed(layer_hs) # layer_bbox_embed Linear(256,256) Linear(256,256) Linear(256,4) [N,1100,4]
layer_outputs_unsig = layer_delta_unsig + inverse_sigmoid(layer_ref_sig)
layer_outputs_unsig = layer_outputs_unsig.sigmoid()
outputs_coord_list.append(layer_outputs_unsig)
outputs_coord_list = torch.stack(outputs_coord_list) # [6,N,1100,4]
outputs_class = torch.stack([layer_cls_embed(layer_hs) for
layer_cls_embed, layer_hs in zip(self.class_embed, hs)]) # layer_cls_embed Linear(256,91) outputs_class [6,N,1100,91]outputs_coord_list is to add the Δb obtained after the output of the current layer through Linear to the refence points output by the previous layer to obtain the output of the current layer. The dimension is [6,N,1100,4], which is the Look Forward mentioned in the paper. Twice; outputs_class is obtained after the output of each layer passes through Linear, and the dimension is [6, N, 1100, 91]. Then separate the denoising part and matching part through the dn_post_process function, where the denoising part is 200=single_pad * 2 * dn_number
def dn_post_process(outputs_class, outputs_coord, dn_meta, aux_loss, _set_aux_loss):
"""
post process of dn after output from the transformer
put the dn part in the dn_meta
"""
# 后处理过程中会将 denoising part和matching part分离,并将denoising part放到dn_meta中
if dn_meta and dn_meta['pad_size'] > 0:
output_known_class = outputs_class[:, :, :dn_meta['pad_size'], :]
output_known_coord = outputs_coord[:, :, :dn_meta['pad_size'], :]
outputs_class = outputs_class[:, :, dn_meta['pad_size']:, :]
outputs_coord = outputs_coord[:, :, dn_meta['pad_size']:, :]
out = {'pred_logits': output_known_class[-1], 'pred_boxes': output_known_coord[-1]}
if aux_loss:
out['aux_outputs'] = _set_aux_loss(output_known_class, output_known_coord)
dn_meta['output_known_lbs_bboxes'] = out
return outputs_class, outputs_coordAfter separation:
1、outputs_class[6,N,900,91],
2、outputs_coord_list[6,N,900,4]
There are more auxiliary losses to be calculated
if self.dn_number > 0 and dn_meta is not None:
outputs_class, outputs_coord_list = \
dn_post_process(outputs_class, outputs_coord_list,
dn_meta,self.aux_loss,self._set_aux_loss)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord_list[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord_list)
# for encoder output
if hs_enc is not None:
# prepare intermediate outputs
interm_coord = ref_enc[-1] # [N,900,4]
interm_class = self.transformer.enc_out_class_embed(hs_enc[-1]) # Linear(256,91) [N,900,91]
out['interm_outputs'] = {'pred_logits': interm_class, 'pred_boxes': interm_coord}
out['interm_outputs_for_matching_pre'] = {'pred_logits': interm_class, 'pred_boxes': init_box_proposal}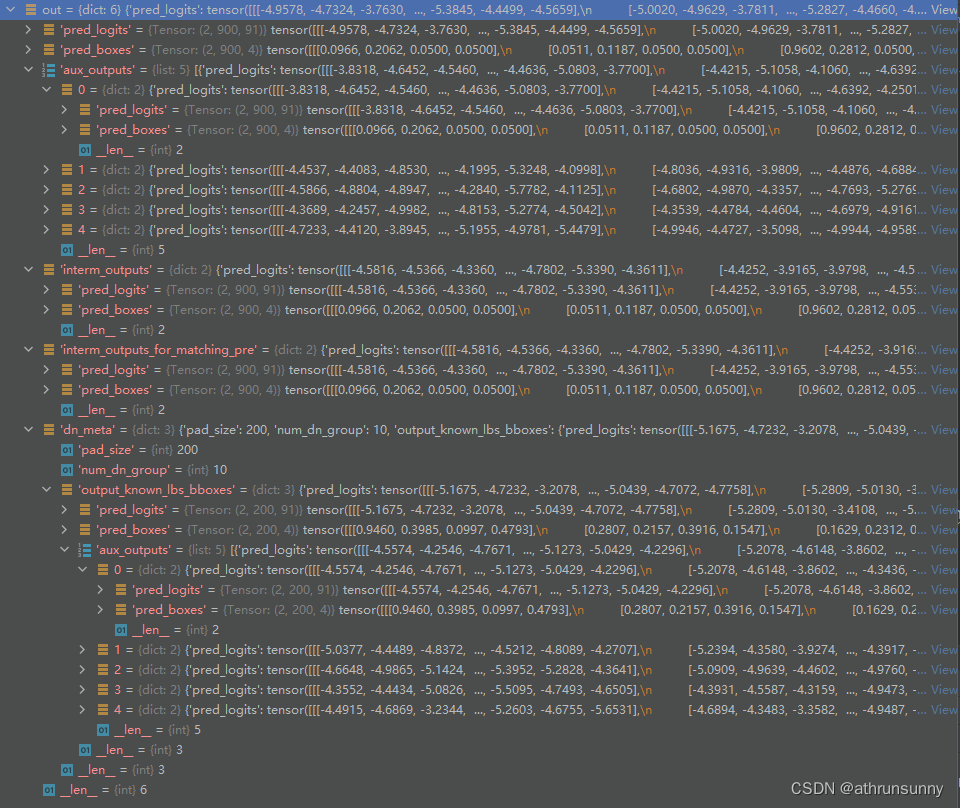
LOSS
The core of the Hungarian algorithm is to find the optimal match. For those who do not understand the algorithm, please refer to Understanding the Hungarian Algorithm
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
For efficiency reasons, the targets don't include the no_object. Because of this, in general,
there are more predictions than targets. In this case, we do a 1-to-1 matching of the best predictions,
while the others are un-matched (and thus treated as non-objects).
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1, focal_alpha=0.25):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
cost_bbox: This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
cost_giou: This is the relative weight of the giou loss of the bounding box in the matching cost
"""
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
self.focal_alpha = focal_alpha
@torch.no_grad()
def forward(self, outputs, targets):
""" Performs the matching
Params:
outputs: This is a dict that contains at least these entries:
"pred_logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
"pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i is the indices of the selected predictions (in order)
- index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds:
len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
bs, num_queries = outputs["pred_logits"].shape[:2] # 假设batch为2,num_queries=900(预设)
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes # 将目标的ground truth id和bbox在batch维度合并,假设此处label个数共有13个(假设第一个batch上有3个类,另一个batch上10个)那么tgt_ids的shape为13,tgt_bbox的shape为[13,4]
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost.
alpha = self.focal_alpha
gamma = 2.0
neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log()) # [1800,91]
pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log()) # [1800,91]
cost_class = pos_cost_class[:, tgt_ids] - neg_cost_class[:, tgt_ids] # [1800,13] 因为gt总共有13个label
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1) # 计算out_bbox和tgt_bbox的L1距离,此时cost_bbox的shape为[1800,13]
# Compute the giou cost betwen boxes
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox),
box_cxcywh_to_xyxy(tgt_bbox)) # 计算giou,此时cost_giou的shape为[1800,13]
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu() # C [1800,13]->[2,900,13]
# 匈牙利算法的实现,指派最优的目标索引,输出一个二维列表,第一维是batch为0,即一个batch中第一张图像通过匈
# 牙利算法计算得到的最优解的横纵坐标,第二维是batch为1,即一个batch中第二张图像,后面的batch维度以此类推
# 假设batch0 :(array([444, 555, 819], dtype=int64), array([0, 2, 1], dtype=int64))
# batch1 :(array([233, 365, 368, 395, 429, 438, 824, 869, 889, 897], dtype=int64), array([8, 9, 2, 4, 5, 0, 6, 3, 1, 7], dtype=int64))
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]Then there are classification and bbox loss
class SetCriterion(nn.Module):
""" This class computes the loss for Conditional DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, focal_alpha, losses):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
losses: list of all the losses to be applied. See get_loss for list of available losses.
focal_alpha: alpha in Focal Loss
"""
super().__init__()
self.num_classes = num_classes
self.matcher = matcher
self.weight_dict = weight_dict
self.losses = losses
self.focal_alpha = focal_alpha
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (Binary focal loss)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits'] # [N,200,91]/ [N,900,91]
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2]+1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:,:,:-1] # one_hot编码 [N,200,91]/[N,900,91]
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
@torch.no_grad()
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
pred_logits = outputs['pred_logits']
device = pred_logits.device
tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device)
# Count the number of predictions that are NOT "no-object" (which is the last class)
card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1)
card_err = F.l1_loss(card_pred.float(), tgt_lengths.float())
losses = {'cardinality_error': card_err}
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx] # [130,4]/[13,4]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0) # [130,4]/[13,4]
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
# calculate the x,y and h,w loss
with torch.no_grad():
losses['loss_xy'] = loss_bbox[..., :2].sum() / num_boxes
losses['loss_hw'] = loss_bbox[..., 2:].sum() / num_boxes
return losses
def loss_masks(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
assert "pred_masks" in outputs
src_idx = self._get_src_permutation_idx(indices)
tgt_idx = self._get_tgt_permutation_idx(indices)
src_masks = outputs["pred_masks"]
src_masks = src_masks[src_idx]
masks = [t["masks"] for t in targets]
# TODO use valid to mask invalid areas due to padding in loss
target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
target_masks = target_masks.to(src_masks)
target_masks = target_masks[tgt_idx]
# upsample predictions to the target size
src_masks = interpolate(src_masks[:, None], size=target_masks.shape[-2:],
mode="bilinear", align_corners=False)
src_masks = src_masks[:, 0].flatten(1)
target_masks = target_masks.flatten(1)
target_masks = target_masks.view(src_masks.shape)
losses = {
"loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
"loss_dice": dice_loss(src_masks, target_masks, num_boxes),
}
return losses
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)]) # batch_idx得到的索引是属于batch中的哪一张图像
src_idx = torch.cat([src for (src, _) in indices]) # src_idx则表示横坐标信息
return batch_idx, src_idx
def _get_tgt_permutation_idx(self, indices):
# permute targets following indices
batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
tgt_idx = torch.cat([tgt for (_, tgt) in indices])
return batch_idx, tgt_idx
def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
loss_map = {
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
'masks': self.loss_masks,
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
def forward(self, outputs, targets, return_indices=False):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
return_indices: used for vis. if True, the layer0-5 indices will be returned as well.
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'}
device=next(iter(outputs.values())).device
indices = self.matcher(outputs_without_aux, targets)
if return_indices:
indices0_copy = indices
indices_list = []
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses
losses = {}
# prepare for dn loss
dn_meta = outputs['dn_meta']
if self.training and dn_meta and 'output_known_lbs_bboxes' in dn_meta:
output_known_lbs_bboxes,single_pad, scalar = self.prep_for_dn(dn_meta) # 取出denoising part中预测的label和bbox以及single_pad和分组scalar
dn_pos_idx = []
dn_neg_idx = []
for i in range(len(targets)): # 在batch上遍历,根据之前在cdn(prepare_for_cdn)中增加噪声的位置,获取每个target上增加噪声对应的索引
if len(targets[i]['labels']) > 0:
t = torch.range(0, len(targets[i]['labels']) - 1).long().cuda()
t = t.unsqueeze(0).repeat(scalar, 1) # [scalar,len(targets[i]['labels'])] [10,3]/[10,10]
tgt_idx = t.flatten() # [30]/[100]
output_idx = (torch.tensor(range(scalar)) * single_pad).long().cuda().unsqueeze(1) + t # [10,3]/[10,10]
output_idx = output_idx.flatten() # [30]/[100]
else:
output_idx = tgt_idx = torch.tensor([]).long().cuda()
dn_pos_idx.append((output_idx, tgt_idx))
dn_neg_idx.append((output_idx + single_pad // 2, tgt_idx))
output_known_lbs_bboxes=dn_meta['output_known_lbs_bboxes']
l_dict = {}
for loss in self.losses:
kwargs = {}
if 'labels' in loss:
kwargs = {'log': False}
l_dict.update(self.get_loss(loss, output_known_lbs_bboxes, targets, dn_pos_idx, num_boxes*scalar,**kwargs))
l_dict = {k + f'_dn': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['loss_bbox_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_giou_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_ce_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_xy_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_hw_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['cardinality_error_dn'] = torch.as_tensor(0.).to('cuda')
losses.update(l_dict)
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
if 'aux_outputs' in outputs:
for idx, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)
if self.training and dn_meta and 'output_known_lbs_bboxes' in dn_meta:
aux_outputs_known = output_known_lbs_bboxes['aux_outputs'][idx]
l_dict={}
for loss in self.losses:
kwargs = {}
if 'labels' in loss:
kwargs = {'log': False}
l_dict.update(self.get_loss(loss, aux_outputs_known, targets, dn_pos_idx, num_boxes*scalar,
**kwargs))
l_dict = {k + f'_dn_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['loss_bbox_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_giou_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_ce_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_xy_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_hw_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['cardinality_error_dn'] = torch.as_tensor(0.).to('cuda')
l_dict = {k + f'_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)
# interm_outputs loss
if 'interm_outputs' in outputs:
interm_outputs = outputs['interm_outputs']
indices = self.matcher(interm_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, interm_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_interm': v for k, v in l_dict.items()}
losses.update(l_dict)
# enc output loss
if 'enc_outputs' in outputs:
for i, enc_outputs in enumerate(outputs['enc_outputs']):
indices = self.matcher(enc_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, enc_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_enc_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
if return_indices:
indices_list.append(indices0_copy)
return losses, indices_list
return losses
def prep_for_dn(self,dn_meta):
output_known_lbs_bboxes = dn_meta['output_known_lbs_bboxes']
num_dn_groups,pad_size=dn_meta['num_dn_group'],dn_meta['pad_size']
assert pad_size % num_dn_groups==0
single_pad=pad_size//num_dn_groups
return output_known_lbs_bboxes,single_pad,num_dn_groupsThe code is a bit long, in fact, it is loss_labels, loss_cardinality, loss_boxes several functions, data in out and target to calculate loss
1. First calculate the loss of the denoising part and target. In the backbone, prepare_for_cdn() divides the positive idx and negative idx. When calculating the loss, traverse and take them out on the batch
if self.training and dn_meta and 'output_known_lbs_bboxes' in dn_meta:
output_known_lbs_bboxes,single_pad, scalar = self.prep_for_dn(dn_meta) # 取出denoising part中预测的label和bbox以及single_pad和分组scalar
dn_pos_idx = []
dn_neg_idx = []
for i in range(len(targets)): # 在batch上遍历,根据之前在cdn(prepare_for_cdn)中增加噪声的位置,获取每个target上增加噪声对应的索引
if len(targets[i]['labels']) > 0:
t = torch.range(0, len(targets[i]['labels']) - 1).long().cuda()
t = t.unsqueeze(0).repeat(scalar, 1) # [scalar,len(targets[i]['labels'])] [10,3]/[10,10]
tgt_idx = t.flatten() # [30]/[100]
output_idx = (torch.tensor(range(scalar)) * single_pad).long().cuda().unsqueeze(1) + t # [10,3]/[10,10]
output_idx = output_idx.flatten() # [30]/[100]
else:
output_idx = tgt_idx = torch.tensor([]).long().cuda()
dn_pos_idx.append((output_idx, tgt_idx))
dn_neg_idx.append((output_idx + single_pad // 2, tgt_idx))
output_known_lbs_bboxes=dn_meta['output_known_lbs_bboxes']
l_dict = {}
for loss in self.losses:
kwargs = {}
if 'labels' in loss:
kwargs = {'log': False}
l_dict.update(self.get_loss(loss, output_known_lbs_bboxes, targets, dn_pos_idx, num_boxes*scalar,**kwargs))
l_dict = {k + f'_dn': v for k, v in l_dict.items()}
losses.update(l_dict)Second, calculate the loss of the decoder output and the target
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))3. Furthermore, calculate the loss between the intermediate process of the denoising part and the matching part and the target, that is, the output of the first 5 layers of the decoder (a total of six layers, the last layer of the matching part is in the upper two, and the last layer of the denoising part is in the upper one. )
if 'aux_outputs' in outputs:
for idx, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)
if self.training and dn_meta and 'output_known_lbs_bboxes' in dn_meta:
aux_outputs_known = output_known_lbs_bboxes['aux_outputs'][idx]
l_dict={}
for loss in self.losses:
kwargs = {}
if 'labels' in loss:
kwargs = {'log': False}
l_dict.update(self.get_loss(loss, aux_outputs_known, targets, dn_pos_idx, num_boxes*scalar,
**kwargs))
l_dict = {k + f'_dn_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['loss_bbox_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_giou_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_ce_dn']=torch.as_tensor(0.).to('cuda')
l_dict['loss_xy_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['loss_hw_dn'] = torch.as_tensor(0.).to('cuda')
l_dict['cardinality_error_dn'] = torch.as_tensor(0.).to('cuda')
l_dict = {k + f'_{idx}': v for k, v in l_dict.items()}
losses.update(l_dict)4. Finally calculate the bbox generated by the encoder select box and the loss of class and target
# interm_outputs loss
if 'interm_outputs' in outputs:
interm_outputs = outputs['interm_outputs']
indices = self.matcher(interm_outputs, targets)
if return_indices:
indices_list.append(indices)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, interm_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_interm': v for k, v in l_dict.items()}
losses.update(l_dict)Well, the overall process of DINO's code ends here