(5 messages) mybatis-plus usage (1) - slag baby engineer's blog - CSDN blog
AR mode
ActiveRecord mode directly operates database tables by manipulating entity objects. It is somewhat similar to ORM.
The example is as follows
-
Let entity classes
Userinherit fromModel
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.time.LocalDateTime;
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model<User> {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = "%s > #{%s}")
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
-
Directly call the method on the entity object
@Test
public void insertAr() {
User user = new User();
user.setId(15L);
user.setName("我是AR猪");
user.setAge(1);
user.setEmail("[email protected]");
user.setManagerId(1L);
boolean success = user.insert(); // 插入
System.out.println(success);
}
-
result
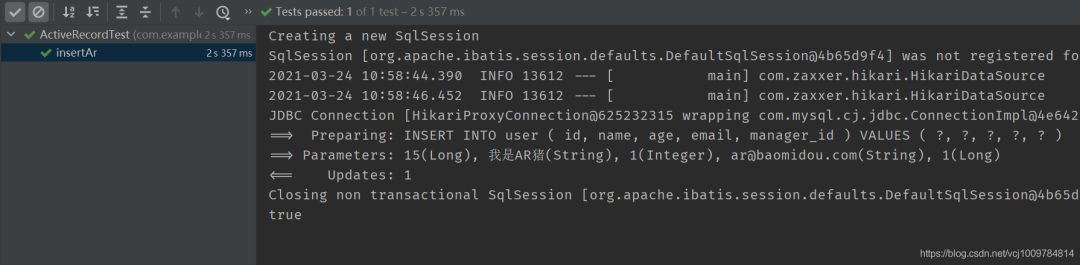
other examples
// 查询
@Test
public void selectAr() {
User user = new User();
user.setId(15L);
User result = user.selectById();
System.out.println(result);
}
// 更新
@Test
public void updateAr() {
User user = new User();
user.setId(15L);
user.setName("王全蛋");
user.updateById();
}
//删除
@Test
public void deleteAr() {
User user = new User();
user.setId(15L);
user.deleteById();
}
primary key strategy
When defining an entity class, use @TableIdthe specified primary key, and its typeattributes can specify the primary key strategy.
mp supports multiple primary key strategies, and the default strategy is the self-incrementing id based on the snowflake algorithm. All primary key strategies are defined in the enumeration class IdType, IdTypewith the following values
-
AUTOThe database ID is auto-incremented and depends on the database . When the insert operation generates a SQL statement, the column of the primary key will not be inserted
-
NONEPrimary key type not set. If the primary key is not manually set in the code, it will be automatically generated according to the global policy of the primary key (the default global policy of the primary key is based on the self-incrementing ID of the snowflake algorithm)
-
INPUTNeed to manually set the primary key, if not set. When an insert operation generates a SQL statement, the value of the primary key column will be
null. Oracle's serial primary key needs to use this method -
ASSIGN_IDWhen the primary key is not manually set, that is, the primary key attribute in the entity class is empty, it will be automatically filled, using the snowflake algorithm
-
ASSIGN_UUIDWhen the primary key attribute of the entity class is empty, it will be automatically populated, using UUID
-
.... (There are still several outdated, so I won't list them any more)
For each entity class, @TableIdannotations can be used to specify the primary key strategy of the entity class, which can be understood as a local strategy . If you want to adopt the same primary key strategy for all entity classes, it will be too troublesome to configure each entity class one by one. At this time, you can use the global strategy of the primary key . Just need application.ymlto configure it. For example, configure the global auto-increment primary key strategy
# application.yml
mybatis-plus:
global-config:
db-config:
id-type: auto
The following demonstrates the behavior of different primary key strategies
-
AUTOAnnotate the attribute on
Userthe above , and then modify the primary keyidof the MYSQL table to auto-increment.user
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model<User> {
@TableId(type = IdType.AUTO)
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = "%s > #{%s}")
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
test
@Test
public void testAuto() {
User user = new User();
user.setName("我是青蛙呱呱");
user.setAge(99);
user.setEmail("[email protected]");
user.setCreateTime(LocalDateTime.now());
userMapper.insert(user);
System.out.println(user.getId());
}
result
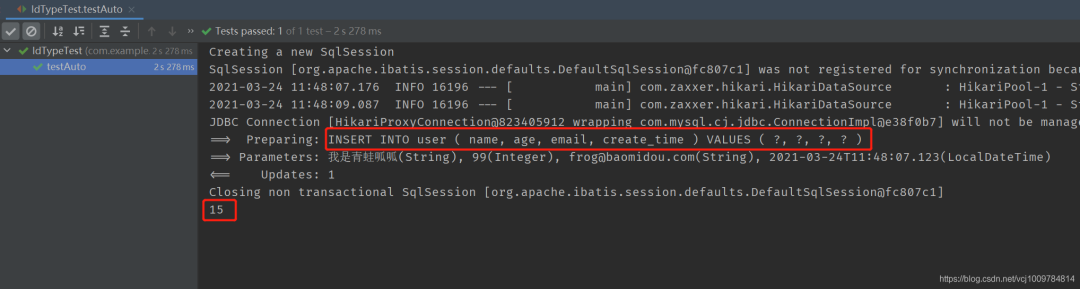
It can be seen that the primary key ID is not set in the code, and the primary key ID is not set in the issued SQL statement, and after the insertion is completed, the primary key ID will be written back to the entity object.
-
NONEIn the MYSQL
usertable, remove the primary key auto-increment. Then modifyUserthe class (if@TableIdthe annotation is not configured, the default primary key strategy is alsoNONE)
@TableId(type = IdType.NONE)
private Long id;
When inserting, if the primary key ID of the entity class has a value, use it; if the primary key ID is empty, use the primary key global strategy to generate an ID.
-
The rest of the strategies are similar and will not be repeated
summary
AUTORelying on the auto-increment primary key of the database, when inserting, the entity object does not need to set the primary key. After the insertion is successful, the primary key will be written back to the entity object.
INPUT relies entirely on user input. What is the primary key ID in the entity object, and what is set when it is inserted into the database. If there is a value, set the value, if it is null, set null
The remaining strategies are automatically generated when the primary key ID in the entity object is empty.
NONEIt will follow the global strategy, ASSIGN_IDadopt the snowflake algorithm, and ASSIGN_UUIDuse UUID
For global configuration, application.ymlyou can do it in ; for local configuration of a single entity class, you @TableIdcan use it. For an entity class, if it has a local primary key strategy, it will be adopted; otherwise, it will follow the global strategy.
configuration
mybatis plus has many configurable items, which can application.ymlbe configured in, such as the global primary key strategy above. Some configuration items are listed below
basic configuration
-
configLocation: If there is a separate mybatis configuration, use this annotation to specify the configuration file of mybatis (the global configuration file of mybatis) -
mapperLocations: The location of the xml file corresponding to mybatis mapper -
typeAliasesPackage: mybatis alias package scan path -
.....
advanced configuration
-
mapUnderscoreToCamelCase: Whether to enable automatic camel case naming rule mapping. (enabled by default) -
dbTpe: Database type. Generally, no configuration is required, and it will be automatically identified according to the database connection url -
fieldStrategy: (Obsolete) Field validation strategy. This configuration item can no longer be found in the latest version of the mp document , and is subdivided intoinsertStrategy,updateStrategy,selectStrategy. The default value isNOT_NULL, that is, only non-null fields in the entity object will be assembled into the final SQL statement.
There are several optional configurations as follows, interview book: https://www.yoodb.com
This configuration item can application.ymlbe configured globally in , or locally configured@TableField with annotations for a field in an entity class
What is the use of this field validation strategy? It can be reflected in the UPDATE operation. If an Userobject is used to perform an UPDATE operation, we hope that only Usernon-null attributes in the object will be updated in the database, and other attributes will not be updated, which NOT_NULLcan meet the requirements.
If updateStrategyit is configured as IGNORED, then no non-null judgment will be made, and all the attributes in the entity object will be assembled into SQL truthfully. In this way, when UPDATE is executed, some fields that do not want to be updated may be set to NULL.
-
IGNORED: Ignore validation. That is, no verification is performed. All fields in the entity object, no matter what the value is, are faithfully assembled into the SQL statement (the firstNULLfield is assembled in the SQL statementNULL). -
NOT_NULL: non-NULLverification. Only non-fields willNULLbe assembled into the SQL statement -
NOT_EMPTY: non-null checksum. When a field is a string type, only a non-empty string is assembled; for other types of fields, it is equivalent toNOT_NULL -
NEVER: Do not join SQL. All fields are not added to the SQL statement -
tablePrefix: Add table name prefix
for example
mybatis-plus:
global-config:
db-config:
table-prefix: xx_
Then modify the table in MYSQL. But the Java entity classes remain the same (still are User).
test
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("name", "黄");
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
You can see the spliced SQL, adding a prefix in front of the table name

Code generator
mp provides a generator that can quickly generate a complete set of codes such as Entity entity class, Mapper interface, Service, and Controller.
The example is as follows
public class GeneratorTest {
@Test
public void generate() {
AutoGenerator generator = new AutoGenerator();
// 全局配置
GlobalConfig config = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
// 设置输出到的目录
config.setOutputDir(projectPath + "/src/main/java");
config.setAuthor("yogurt");
// 生成结束后是否打开文件夹
config.setOpen(false);
// 全局配置添加到 generator 上
generator.setGlobalConfig(config);
// 数据源配置
DataSourceConfig dataSourceConfig = new DataSourceConfig();
dataSourceConfig.setUrl("jdbc:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai");
dataSourceConfig.setDriverName("com.mysql.cj.jdbc.Driver");
dataSourceConfig.setUsername("root");
dataSourceConfig.setPassword("root");
// 数据源配置添加到 generator
generator.setDataSource(dataSourceConfig);
// 包配置, 生成的代码放在哪个包下
PackageConfig packageConfig = new PackageConfig();
packageConfig.setParent("com.example.mp.generator");
// 包配置添加到 generator
generator.setPackageInfo(packageConfig);
// 策略配置
StrategyConfig strategyConfig = new StrategyConfig();
// 下划线驼峰命名转换
strategyConfig.setNaming(NamingStrategy.underline_to_camel);
strategyConfig.setColumnNaming(NamingStrategy.underline_to_camel);
// 开启lombok
strategyConfig.setEntityLombokModel(true);
// 开启RestController
strategyConfig.setRestControllerStyle(true);
generator.setStrategy(strategyConfig);
generator.setTemplateEngine(new FreemarkerTemplateEngine());
// 开始生成
generator.execute();
}
}
After running, you can see that a complete set of code is generated as shown in the figure below
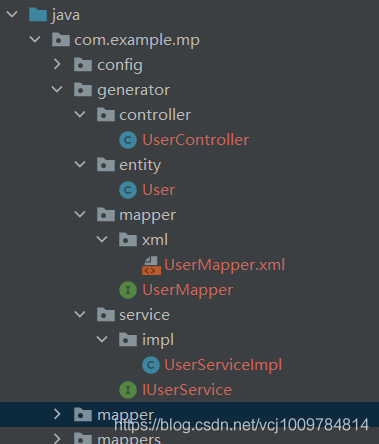
Advanced Features
Demonstration of advanced features requires a new tableuser2
DROP TABLE IF EXISTS user2;
CREATE TABLE user2 (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT '主键id',
name VARCHAR(30) DEFAULT NULL COMMENT '姓名',
age INT(11) DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
manager_id BIGINT(20) DEFAULT NULL COMMENT '直属上级id',
create_time DATETIME DEFAULT NULL COMMENT '创建时间',
update_time DATETIME DEFAULT NULL COMMENT '修改时间',
version INT(11) DEFAULT '1' COMMENT '版本',
deleted INT(1) DEFAULT '0' COMMENT '逻辑删除标识,0-未删除,1-已删除',
CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user2(id)
) ENGINE = INNODB CHARSET=UTF8;
INSERT INTO user2(id, name, age, email, manager_id, create_time)
VALUES
(1, '老板', 40 ,'[email protected]' ,NULL, '2021-03-28 13:12:40'),
(2, '王狗蛋', 40 ,'[email protected]' ,1, '2021-03-28 13:12:40'),
(3, '王鸡蛋', 40 ,'[email protected]' ,2, '2021-03-28 13:12:40'),
(4, '王鸭蛋', 40 ,'[email protected]' ,2, '2021-03-28 13:12:40'),
(5, '王猪蛋', 40 ,'[email protected]' ,2, '2021-03-28 13:12:40'),
(6, '王软蛋', 40 ,'[email protected]' ,2, '2021-03-28 13:12:40'),
(7, '王铁蛋', 40 ,'[email protected]' ,2, '2021-03-28 13:12:40')
And create the corresponding entity classUser2
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
and the Mapper interface
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User2;
public interface User2Mapper extends BaseMapper<User2> { }
Tombstone
First of all, why have tombstones? Can't you just delete it? Of course you can, but if you want to restore or need to view these data in the future, you can't do it. Logical deletion is a solution to facilitate data recovery and protect the value of data itself .
In daily life, after we delete a file in the computer, we just put the file into the recycle bin, and we can view or restore it if necessary in the future. When we determine that a file is no longer needed, it can be completely deleted from the recycle bin. This is also a similar reason.
The tombstone provided by mp is very simple to implement
You only need to application.ymlconfigure the logical deletion in
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局逻辑删除的实体字段名
logic-delete-value: 1 # 逻辑已删除值(默认为1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为0)
# 若逻辑已删除和未删除的值和默认值一样,则可以不配置这2项
test code
package com.example.mp;
import com.example.mp.mappers.User2Mapper;
import com.example.mp.po.User2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class LogicDeleteTest {
@Autowired
private User2Mapper mapper;
@Test
public void testLogicDel() {
int i = mapper.deleteById(6);
System.out.println("rowAffected = " + i);
}
}
result
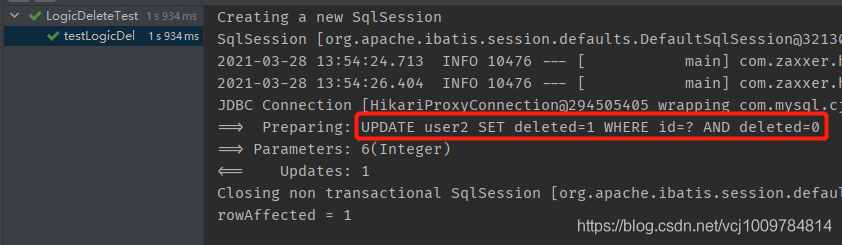
As you can see, the SQL issued is no longer DELETE, butUPDATE
At this point we execute againSELECT
@Test
public void testSelect() {
List<User2> users = mapper.selectList(null);
}
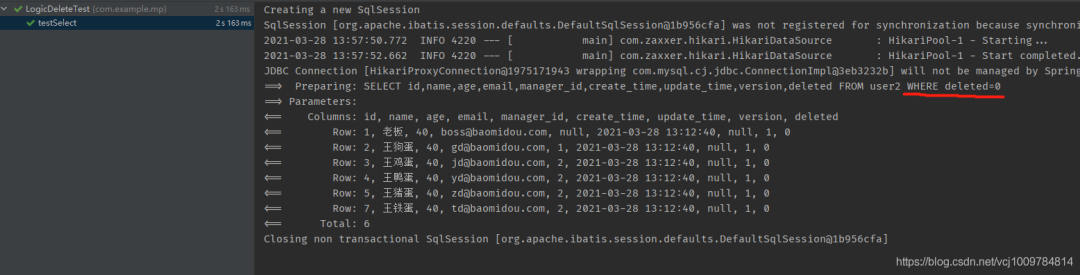
It can be seen that the issued SQL statement will automatically splice the logic undeleted condition after WHERE. In the query results, there is no Wang Ruandan with id 6.
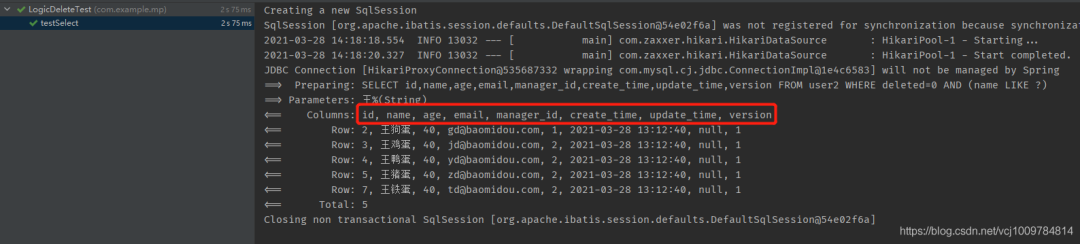
If you want the column of SELECT, excluding the column of logical deletion, you can @TableFieldconfigure it in the entity class by
@TableField(select = false)
private Integer deleted;
You can see that in the execution result in the figure below, the deleted column is no longer included in the SELECT
application.ymlThe configuration done in front is global. Generally speaking, for multiple tables, we will also unify the names of logically deleted fields, and unify the values of logically deleted and undeleted values, so global configuration is sufficient. @TableLogicOf course, if you want to configure some tables separately, you can use them on the corresponding fields of the entity class
@TableLogic(value = "0", delval = "1")
private Integer deleted;
summary
After the tombstone of mp is enabled, it will have the following impact on SQL
-
INSERT statement: no effect
-
SELECT statement: append WHERE condition, filter out deleted data
-
UPDATE statement: Append WHERE condition to prevent updating to deleted data
-
DELETE statement: converted to UPDATE statement
Note that the above effects only take effect for the SQL automatically injected by mp. If it is a custom SQL manually added by yourself, it will not take effect. for example
public interface User2Mapper extends BaseMapper<User2> {
@Select("select * from user2")
List<User2> selectRaw();
}
Call this selectRaw, the tombstone of mp will not take effect. Interview Book: https://www.yoodb.com
In addition, tombstones can application.ymlbe configured globally in or @TableLogiclocally configured in entity classes.
autofill
There are often fields such as "new time", "modified time", and "operator" in the table. The more primitive way is to set it manually every time it is inserted or updated. mp can be configured to automatically fill some fields, and the edible example is as follows
1. On some fields in the entity class, by @TableFieldsetting autofill
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
@TableField(fill = FieldFill.INSERT) // 插入时自动填充
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE) // 更新时自动填充
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
2. Implement an autofill handler
package com.example.mp.component;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component //需要注册到Spring容器中
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
// 插入时自动填充
// 注意第二个参数要填写实体类中的字段名称,而不是表的列名称
strictFillStrategy(metaObject, "createTime", LocalDateTime::now);
}
@Override
public void updateFill(MetaObject metaObject) {
// 更新时自动填充
strictFillStrategy(metaObject, "updateTime", LocalDateTime::now);
}
}
test
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("王一蛋");
user.setAge(29);
user.setEmail("[email protected]");
user.setManagerId(2L);
mapper.insert(user);
}
According to the results in the figure below, you can see that createTime is automatically filled
Note that autofill will only take effect when the field is empty. If the field is not empty, the existing value will be used directly. as follows
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("王一蛋");
user.setAge(29);
user.setEmail("[email protected]");
user.setManagerId(2L);
user.setCreateTime(LocalDateTime.of(2000,1,1,8,0,0));
mapper.insert(user);
}

Autofill when updating, test as follows
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("王一蛋");
user.setAge(99);
mapper.updateById(user);
}

Optimistic Lock Plugin
When concurrent operations occur, it is necessary to ensure that the data operations of each user do not conflict, and a concurrency control method is needed at this time. The method of pessimistic locking is to directly lock (the locking mechanism of the database) when modifying a record in the database, lock the data, and then operate; while optimistic locking, as its name suggests, first assumes that there is no Conflicts, and when actually performing data operations, check whether there are conflicts. A common implementation of optimistic locking is a version number , and there is also a version number-based concurrent transaction control called MVCC in MySQL.
Optimistic locking is more suitable for scenarios where more reads and fewer writes are performed, which can reduce the performance overhead caused by locking operations and improve system throughput.
In the scenario of writing more and reading less, pessimistic locks are more used, otherwise, due to optimistic lock failures and retries, it will lead to performance degradation.
Optimistic locking is implemented as follows:
-
When fetching records, get the current version
-
When updating, bring this version
-
When performing an update, set version = newVersion where version = oldVersion
-
If oldVersion is inconsistent with the version in the database, the update fails
This idea is very similar to CAS (Compare And Swap).
The implementation steps of optimistic locking are as follows
1. Configure the optimistic lock plugin
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/** 3.4.0以后的mp版本,推荐用如下的配置方式 **/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
/** 旧版mp可以采用如下方式。注意新旧版本中,新版的类,名称带有Inner, 旧版的不带, 不要配错了 **/
/*
@Bean
public OptimisticLockerInterceptor opLocker() {
return new OptimisticLockerInterceptor();
}
*/
}
2. Add annotations to the field representing the version in the entity class@Version
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@Version
private Integer version;
private Integer deleted;
}
test code
@Test
public void testOpLocker() {
int version = 1; // 假设这个version是先前查询时获得的
User2 user = new User2();
user.setId(8L);
user.setEmail("[email protected]");
user.setVersion(version);
int i = mapper.updateById(user);
}
Look at the database before executing
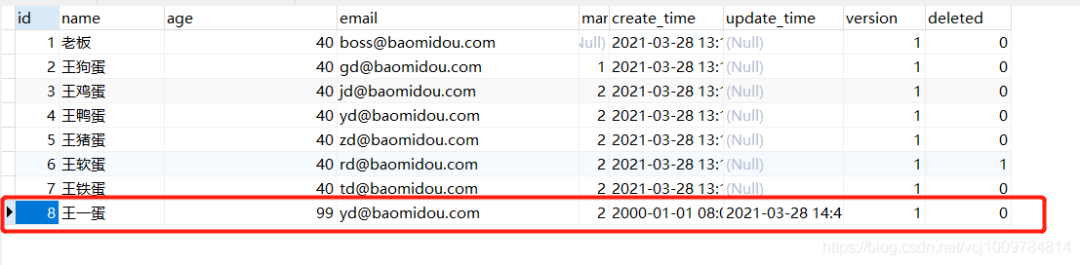
According to the execution results in the figure below, you can see that version-related operations have been added to the SQL statement
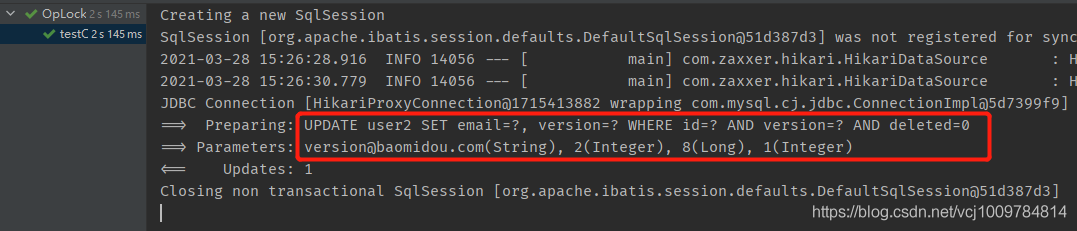
When UPDATE returns 1, it means that the number of affected rows is 1, and the update is successful. On the contrary, because the version behind WHERE is inconsistent with the database, no records can be matched, and the number of affected rows is 0, indicating that the update failed. After the update is successful, the new version will be encapsulated back into the entity object.
The version field in the entity class, the type only supports int, long, Date, Timestamp, LocalDateTime
Note that the optimistic lock plugin only supports the ** updateById(id)and update(entity, wrapper)method**
Note: If used wrapper, it wrappercannot be reused! The example is as follows
@Test
public void testOpLocker() {
User2 user = new User2();
user.setId(8L);
user.setVersion(1);
user.setAge(2);
// 第一次使用
LambdaQueryWrapper<User2> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User2::getName, "王一蛋");
mapper.update(user, wrapper);
// 第二次复用
user.setAge(3);
mapper.update(user, wrapper);
}
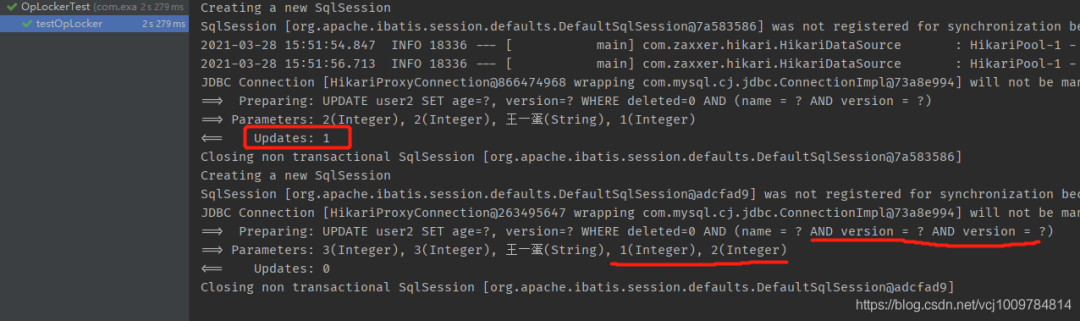
It can be seen that in the second reuse wrapper, in the spliced SQL, there are two versions in the subsequent WHERE statement, which is problematic.
Performance Analysis Plugin
The plug-in will output the execution time of the SQL statement for performance analysis and tuning of the SQL statement.
Note: After version 3.2.0, the performance analysis plug-in that comes with mp is officially removed, and it is recommended to use a third-party performance analysis plug-in
eating steps
1. Introduce maven dependency
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>3.9.1</version>
</dependency>
2. Modifyapplication.yml
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver #换成p6spy的驱动
url: jdbc:p6spy:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai #url修改
username: root
password: root
3. src/main/resourcesAdd in the resource directoryspy.properties
#spy.properties
#3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
# 真实JDBC driver , 多个以逗号分割,默认为空。由于上面设置了modulelist, 这里可以不用设置driverlist
#driverlist=com.mysql.cj.jdbc.Driver
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
#若要日志输出到文件, 把上面的appnder注释掉, 或者采用下面的appender, 再添加logfile配置
#不配置appender时, 默认是往文件进行输出的
#appender=com.p6spy.engine.spy.appender.FileLogger
#logfile=log.log
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2
# 执行时间设置, 只有超过这个执行时间的才进行记录, 默认值0, 单位毫秒
executionThreshold=10
Just run a test case, you can see that the execution time of the SQL is recorded
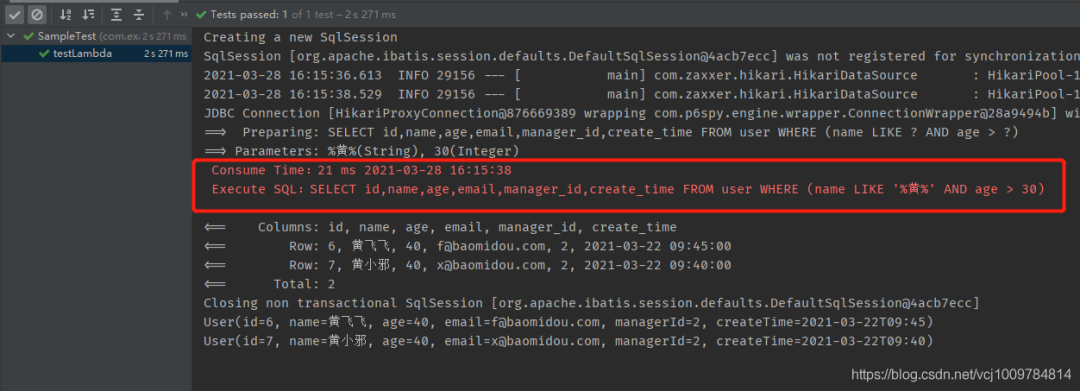
Multi-tenant SQL parser
The concept of multi-tenancy: Multiple users share a system, but their data needs to be relatively independent and maintain a certain degree of isolation.
Multi-tenant data isolation generally has the following methods:
-
Different tenants use different database servers
The advantages are: different tenants have different independent databases, which is helpful for expansion, and provides better personalization for different tenants, and it is easier to restore data when a failure occurs.
The disadvantages are: increase the number of databases, purchase costs, and higher maintenance costs
-
Different tenants use the same database server, but use different databases (different schemas)
The advantage is that the purchase and maintenance costs are lower, and the disadvantage is that data recovery is more difficult, because the data of different tenants are put together
-
Different tenants use the same database server, use the same database, share data tables, and add tenant ids to the tables for distinction
The advantage is that the acquisition and maintenance costs are the lowest, and the number of users is supported. The disadvantage is that the isolation is the lowest and the security is the lowest. Java technology advanced route: https://www.yoodb.com
Edible examples are as follows
Add multi-tenant interceptor configuration. After adding the configuration, when executing CRUD, the tenant id condition will be automatically spliced at the end of the SQL statement
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TenantLineHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor;
import net.sf.jsqlparser.expression.Expression;
import net.sf.jsqlparser.expression.LongValue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new TenantLineHandler() {
@Override
public Expression getTenantId() {
// 返回租户id的值, 这里固定写死为1
// 一般是从当前上下文中取出一个 租户id
return new LongValue(1);
}
/**
** 通常会将表示租户id的列名,需要排除租户id的表等信息,封装到一个配置类中(如TenantConfig)
**/
@Override
public String getTenantIdColumn() {
// 返回表中的表示租户id的列名
return "manager_id";
}
@Override
public boolean ignoreTable(String tableName) {
// 表名不为 user2 的表, 不拼接多租户条件
return !"user2".equals(tableName);
}
}));
// 如果用了分页插件注意先 add TenantLineInnerInterceptor 再 add PaginationInnerInterceptor
// 用了分页插件必须设置 MybatisConfiguration#useDeprecatedExecutor = false
return interceptor;
}
}
test code
@Test
public void testTenant() {
LambdaQueryWrapper<User2> wrapper = new LambdaQueryWrapper<>();
wrapper.likeRight(User2::getName, "王")
.select(User2::getName, User2::getAge, User2::getEmail, User2::getManagerId);
user2Mapper.selectList(wrapper);
}
Dynamic table name SQL parser
When the amount of data is particularly large, we usually use sub-database and sub-table. At this time, there may be multiple tables with the same table structure but different table names. For example order_1, when querying, we may need to dynamically set the name of the table to be queried order_2. order_3mp provides a dynamic table name SQL parser, the edible example is as follows
user2First copy the table in mysql
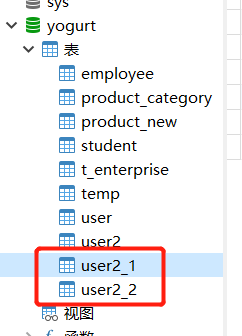
Configure dynamic table name interceptor
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Random;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor = new DynamicTableNameInnerInterceptor();
HashMap<String, TableNameHandler> map = new HashMap<>();
// 对于user2表,进行动态表名设置
map.put("user2", (sql, tableName) -> {
String _ = "_";
int random = new Random().nextInt(2) + 1;
return tableName + _ + random; // 若返回null, 则不会进行动态表名替换, 还是会使用user2
});
dynamicTableNameInnerInterceptor.setTableNameHandlerMap(map);
interceptor.addInnerInterceptor(dynamicTableNameInnerInterceptor);
return interceptor;
}
}
test
@Test
public void testDynamicTable() {
user2Mapper.selectList(null);
}
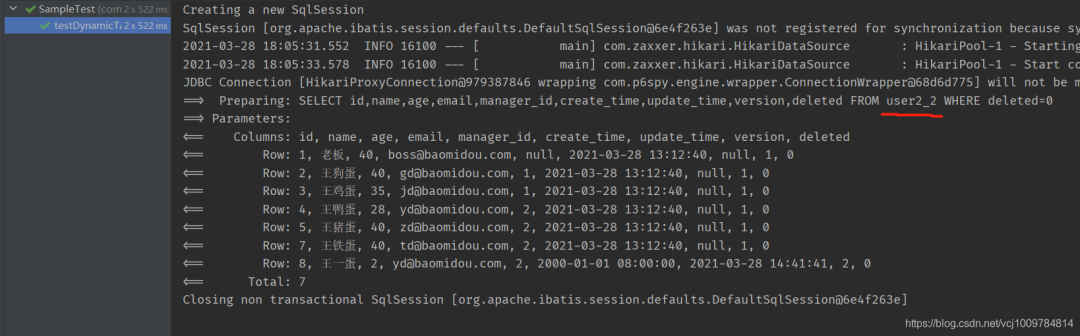
Summarize
-
The condition constructor
AbstractWrapperprovides multiple methods for constructing WHERE conditions in SQL statements, and its subclassesQueryWrapperprovide additionalselectmethods to select only specific columns, and subclassesUpdateWrapperprovide additionalsetmethods for setting SET statements in SQL . In addition to ordinary onesWrapper, there are lambda expression-based onesWrapper, such asLambdaQueryWrapper,LambdaUpdateWrapperwhen constructing WHERE conditions, they directly use method references to specify columns in WHERE conditions, whichWrapperis more elegant than specifying through strings. In addition, there is also a chained Wrapper , for exampleLambdaQueryChainWrapper, it encapsulatesBaseMapperand can obtain results more conveniently. -
The condition constructor uses chain calls to splice multiple conditions, and the conditions are
ANDconnected by default -
When the conditions after
ANDorORneed to be wrapped in parentheses, pass the conditions in the parentheses in the form of lambda expressions as parametersand()oror()
In particular, when ()it needs to be placed at the very beginning of the WHERE statement, nested()the method can be used
-
When a conditional expression needs to be passed in a custom SQL statement, or when a database function needs to be called, a
apply()method can be used for SQL splicing -
Each method in the condition constructor can use a
booleantype of variableconditionto flexibly splice the WHERE condition as needed (only whenconditionthetrueSQL statement is spliced) -
Using the lambda conditional constructor, you can directly use the attributes in the entity class for conditional construction through lambda expressions, which is more elegant than ordinary conditional constructors. In addition, the official account Java selection, reply to java interviews, and obtain interview materials.
-
If the method provided by mp is not enough, it can be extended and developed in the form of custom SQL (native mybatis)
-
When using mp for paging query, you need to create a paging interceptor (Interceptor), register it in the Spring container, and then query by passing in a paging object (Page object). When querying a single table, you can use
BaseMapperthe providedselectPageorselectMapsPagemethod. In complex scenarios (such as multi-table joint query), use custom SQL. -
AR mode can directly operate the database by manipulating entity classes. Let the entity class inherit
Modelfrom