background
Represented by the Stable Diffusion model, AI Generated Content (AIGC) models and applications are showing a blowout growth trend. In previous work, the Alibaba Cloud machine learning PAI team has open-sourced the PAI-Diffusion series of models (see here ), including a series of text and image generation models for general scenarios and specific scenarios, such as ancient poems with pictures, two-dimensional animation, magic reality, etc. . In addition to the standard Diffusion Model, the pipeline of these models also integrates the Chinese CLIP cross-modal alignment model previously proposed by the PAI team (see here) so that the model can generate high-definition large images in various scenarios that conform to Chinese text descriptions. In addition, because the inference speed of the Diffusion model is relatively slow and requires more hardware resources, we combine the compilation and optimization tool PAI-Blade independently developed by PAI to support the end-to-end export and inference acceleration of the PAI-Diffusion model. Under the machine, a large Chinese image can be generated within 1s (see here ). In this work, we have significantly upgraded the previous PAI-Diffusion Chinese model. The main function extensions include:
- Significantly improved image generation quality and diversified styles: Through massive processing and filtering of model pre-training data, as well as optimization of the training process, the images generated by the PAI-Diffusion Chinese model greatly surpass the previous ones in terms of quality and style Version;
- Rich refined model fine-tuning functions: In addition to the standard fine-tuning of the model, the PAI-Diffusion Chinese model supports various fine-tuning functions of the open source community, including LoRA, Textual Inversion, DreamBooth, ControlNet, etc., and supports various image generation and editing functions;
- Easy-to-use scenario customization solution: In addition to training Chinese models in various general scenarios, we have also made a lot of attempts and explorations in vertical scenarios. Through scenario customization, these models can be used in various products. Including Diffuser API, WebUI, etc.
In the following, we detail the new functions and features of the PAI-Diffusion Chinese model.
art Gallery
Before introducing the PAI-Diffusion Chinese model and its functions in detail, we first take you to visit our art gallery. All the pictures below are generated using the PAI-Diffusion Chinese model.
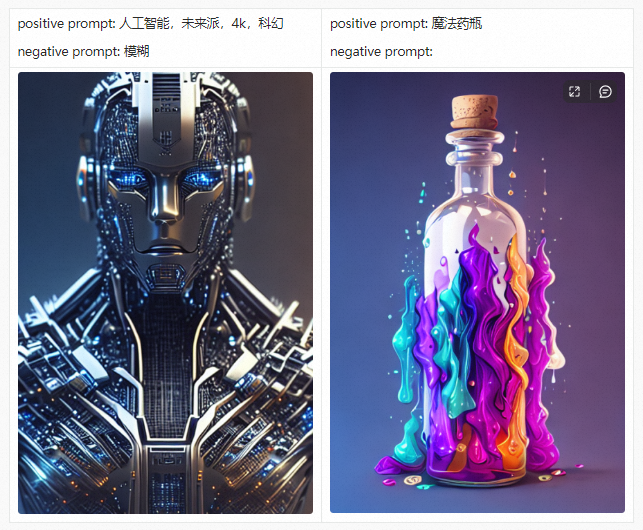

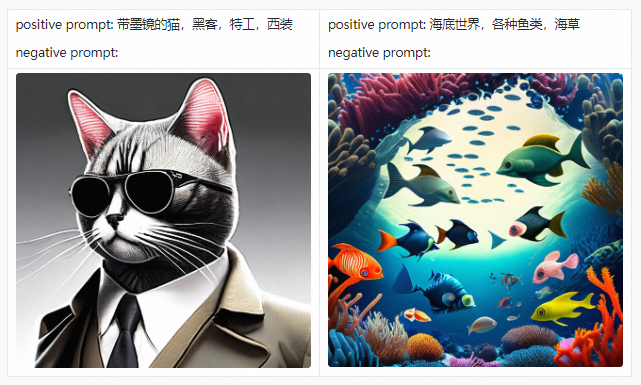
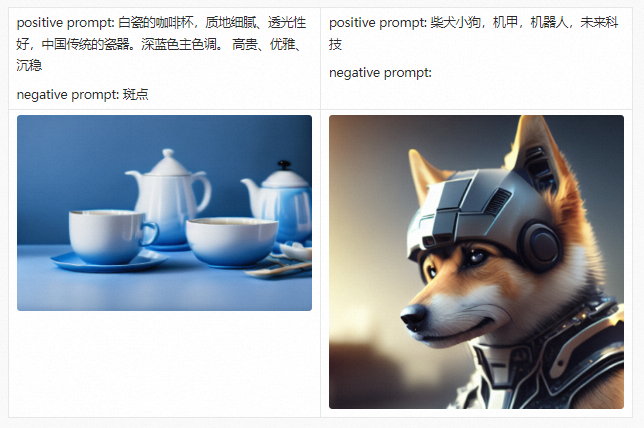
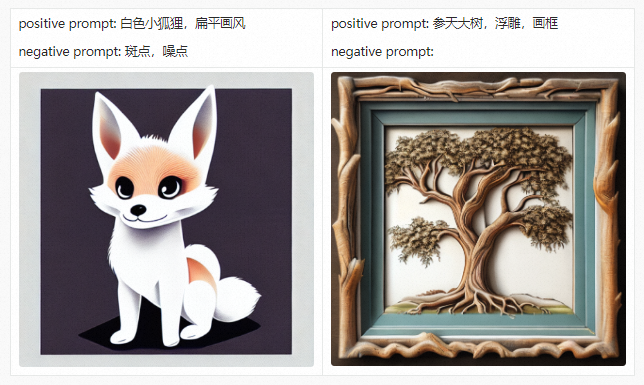

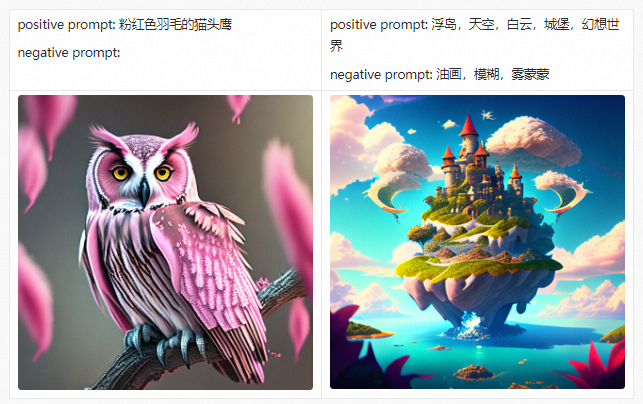


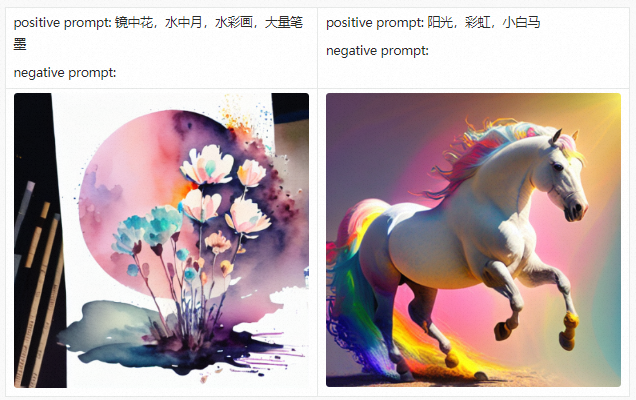
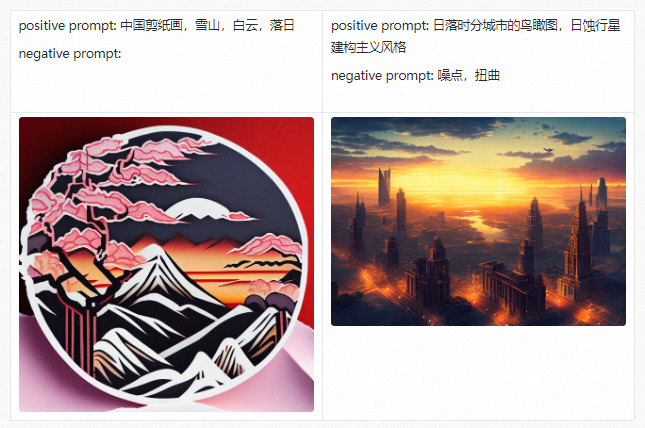
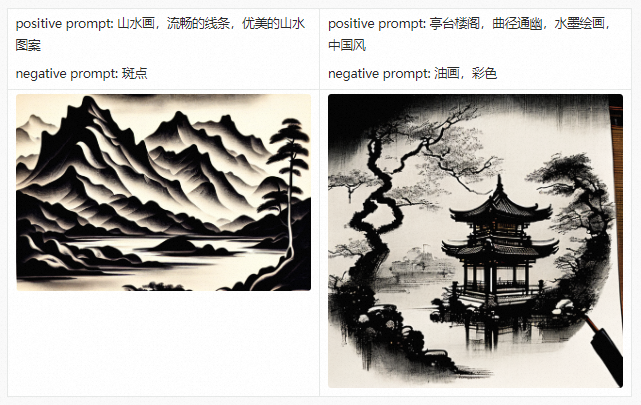
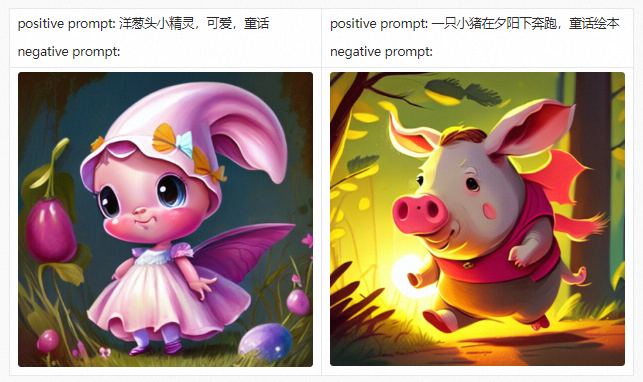




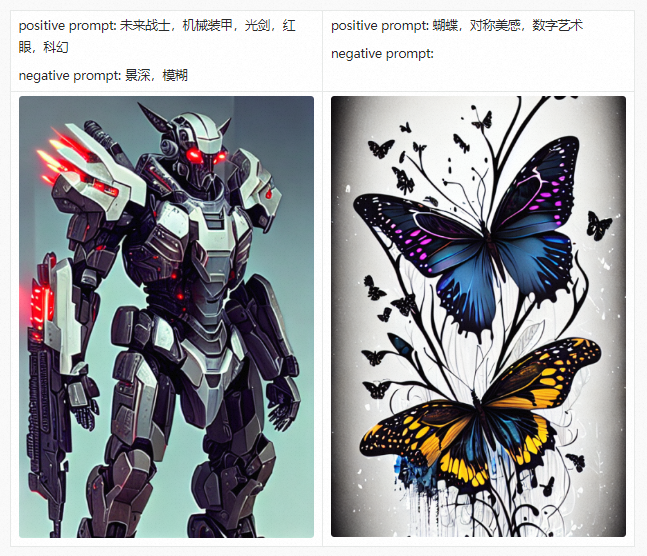
PAI-Diffusion ModelZoo
We have trained multiple Diffusion Chinese models with a large number of Chinese image-text pairs, and the number of parameters is about 1 billion. This time we open source the following two models. An overview is as follows:
| model name | scenes to be used |
|---|---|
| pai-diffusion-artist-large-zh | Chinese text image generation art model, the default supported image resolution is 512*512 |
| pai-diffusion-artist-xlarge-zh | Chinese text image generation art model (larger resolution), the default supported image resolution is 768*768 |
In order to improve the quality of the image output by the model and avoid non-compliant or low-quality content to the greatest extent, we have collected a large number of open source image-text datasets, including the large-scale Chinese cross-modal pre-training dataset WuKong, and the large-scale multilingual Multimodal dataset LAION-5B et al. We have performed multiple cleaning methods on images and texts to filter out violations and low-quality data. The specific data processing methods include NSFW (Not Safe From Work) data filtering, watermark data removal, and using CLIP score and aesthetic value score to select the most suitable subset of pre-training data for training. Different from the Diffusion model in the English open source community, our CLIP Text Encoder adopts the Chinese CLIP model developed by EasyNLP ( https://github.com/alibaba/EasyNLP ), and its parameters are frozen during the Diffusion training process, making the model more accurate to Chinese Semantic modeling is more precise. It is worth noting that the image resolution in the above table refers to the image resolution during the training process, and different resolutions can be set during the model inference stage.
PAI-Diffusion model characteristics
In order to make it easier for users to use the PAI-Diffusion model, we introduce the characteristics of the PAI-Diffusion model in detail from the following aspects.
Rich and diverse model fine-tuning methods
The parameters of models such as PAI-Diffusion model and community Stable Diffusion are generally around one billion. The full parameter fine-tuning of these models often consumes a lot of computing resources. In addition to the standard model fine-tuning, the PAI-Diffusion model supports a variety of lightweight fine-tuning algorithms, allowing users to fine-tune the model in specific domains and scenarios with as little calculation as possible. Below, we also give two examples of lightweight fine-tuning.
Model lightweight fine-tuning using LoRA
The PAI-Diffusion model can use the LoRA (Low-Rank Adaptation) algorithm for lightweight fine-tuning, greatly reducing the amount of calculation. Calling the open source script train_text_to_image_lora.py , we can also realize the lightweight fine-tuning of the PAI-Diffusion Chinese model. An example training command is as follows:
export MODEL_NAME="model_name"
export TRAIN_DIR="path_to_your_dataset"
export OUTPUT_DIR="path_to_save_model"
accelerate launch train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIRAmong them, MODEL_NAME is the name or path of the PAI-Diffusion model used for fine-tuning, TRAIN_DIR is the local path of the training set, and OUTPUT_DIR is the local path of the model save (only contains the LoRA fine-tuning parameter part). After the lightweight fine-tuning of the model LoRA is completed, the following sample code can be used for text generation:
from diffusers import StableDiffusionPipeline
model_id = "model_name"
lora_path = "model_path/checkpoint-xxx/pytorch_model.bin"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe.unet.load_attn_procs(torch.load(lora_path))
pipe.to("cuda")
image = pipe("input text").images[0]
image.save("result.png")Among them, model_path is the local path saved by the fine-tuned model (only contains the LoRA fine-tuning parameter part), that is, the OUTPUT_DIR of the previous step; model_id is the original model that has not been fine-tuned by LoRA.
Lightweight fine-tuning of model customization using Textual Inversion
Since the PAI-Diffusion model is generally used to generate images in various general scenarios, Textual Inversion is a customized lightweight fine-tuning technology that enables the model to generate new concept-related images that the original model did not learn. The PAI-Diffusion model can use the Textual Inversion algorithm for lightweight fine-tuning. Similarly, we can run the script textual_inversion.py , the training command example is as follows:
export MODEL_NAME="model_name"
export TRAIN_DIR="path_to_your_dataset"
export OUTPUT_DIR="path_to_save_model"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--learnable_property="object" \
--placeholder_token="<小奶猫>" --initializer_token="猫" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=100 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIRAmong them, MODEL_NAME is the name of the PAI-Diffusion model used for fine-tuning, TRAIN_DIR is the local path of the aforementioned training set, and OUTPUT_DIR is the local path where the model is saved. Among them, placeholder_token is the text related to the new concept, and initializer_token is the word closely related to the new concept (used to initialize the parameters corresponding to the new concept). Here we take the little milk cat as an example. After the lightweight and fine-tuning of the model is completed, the following sample code can be used for text generation:
from diffusers import StableDiffusionPipeline
model_path = "path_to_save_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path).to("cuda")
image = pipe("input text").images[0]
image.save("result.png")Among them, model_path is the local path saved by the fine-tuned model, which is the OUTPUT_DIR of the previous step. Note that when using the fine-tuned model to generate an image containing a new concept, the new concept in the text is represented by the placeholder_token in step 2, for example:

Controllable image editing functions
The potential risk of the AIGC series of models is that it is easy to generate uncontrollable content with illegal information, which affects the application of these models in downstream business scenarios. The PAI-Diffusion Chinese model supports a variety of controllable image editing functions, allowing users to limit the content of the generated images, making the results more usable. The PAI-Diffusion Chinese model is fully compatible with StableDiffusionImg2ImgPipeline. This text-guided image editing pipeline allows the model to generate relevant images based on given input text and images. The sample script is as follows:
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("model_name").to("cuda")
image = pipe(prompt="input text", image=init_image, strength=0.75, guidance_scale=7.5).images[0]
image.save("result.png")An example of input and output is given below:

Functional support for scene customization
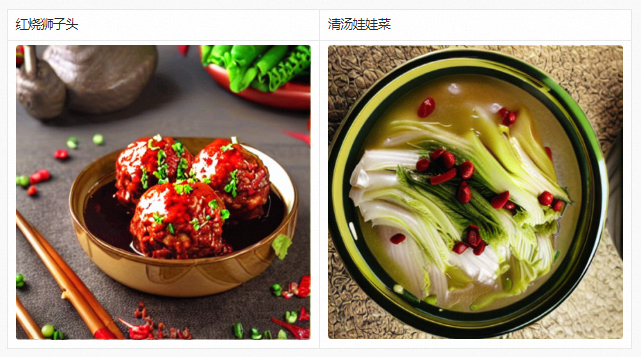
In addition to being used to generate large art images, we can also obtain a highly scene-oriented Chinese model by continuing to pre-train the PAI-Diffusion Chinese model. The following is the result of the PAI-Diffusion Chinese model after continuous pre-training on food data. It can be seen that as long as there is high-quality business data, Diffusion models for different business scenarios can be produced. These models can be further seamlessly combined with LoRA, ControlNet and other technologies to achieve image editing and generation that is more in line with business and more controllable.
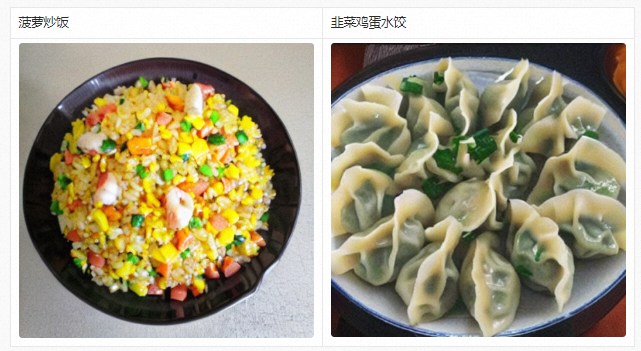
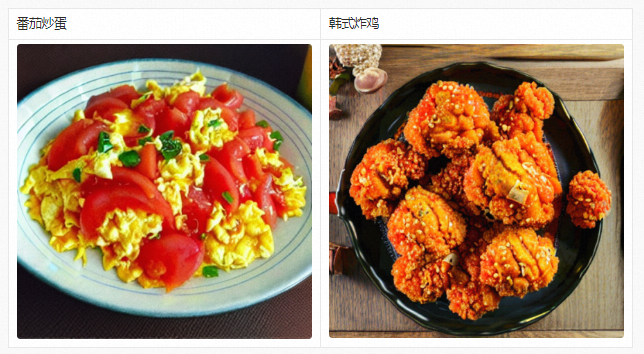
Model usage and download
Using the PAI-Diffusion Chinese Model in the Open Source Community
In order to facilitate the use of these models by the open source community, we have connected these two models to two well-known open source model sharing communities, HuggingFace and ModelScope. Taking HuggingFace as an example, we can use the following code for model inference:
from diffusers import StableDiffusionPipeline
model_id = "alibaba-pai/pai-diffusion-artist-large-zh"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
prompt = "雾蒙蒙的日出在湖面上"
image = pipe(prompt).images[0]
image.save("result.png")An example of using the interface in ModelScope is as follows:
from modelscope.pipelines import pipeline
import cv2
p = pipeline('text-to-image-synthesis', 'PAI/pai-diffusion-artist-large-zh', model_revision='v1.0.0')
result = p({'text': '雾蒙蒙的日出在湖面上'})
image = result["output_imgs"][0]
cv2.imwrite("image.png", image)In addition, we have also opened a Diffusion algorithm area ( link ) in the EasyNLP algorithm framework, providing scripts and tutorials for various PAI-Diffusio models.
Using the PAI-Diffusion Chinese model in PAI-DSW
PAI-DSW (Data Science Workshop) is an IDE on the cloud developed by the Alibaba Cloud machine learning platform PAI. It provides an interactive programming environment (documentation) for developers of different levels . In DSW Gallery, various Notebook examples are provided to facilitate users to easily get started with DSW and build various machine learning applications. We have also put the Sample Notebook using the PAI-Diffusion Chinese model on the DSW Gallery, welcome everyone to experience it!

Free collection: Alibaba Cloud machine learning platform PAI provides developers with free trial credits, including DSW, DLC, and EAS products. https://free.aliyun.com/?pipCode=learn
future outlook
In this phase of work, we have greatly expanded the effects and functions of the PAI-Diffusion Chinese model, which has greatly improved the quality of image generation and diversified styles. At the same time, we support a variety of refined model fine-tuning and editing functions including LoRA and Textual Inversion. In addition, we also demonstrated a variety of scenario-based customization solutions to facilitate users to train and use their own Diffusion Chinese models in specific scenarios. In the future, we plan to further extend the model capabilities for various scenarios.
Authors: Duan Zhongjie (End Tribulation), Liu Bingyan (Wu Shi), Wang Chengyu (Xiong Xi), Huang Jun (Presence)
This article is the original content of Alibaba Cloud and may not be reproduced without permission.