Preface
As the current advanced deep learning target detection algorithm YOLOv8, a large number of tricks have been collected, but there is still room for improvement and improvement. Different improvement methods can be used for detection difficulties in specific application scenarios. The following series of articles will focus on how to improve YOLOv8 in detail. The purpose is to provide meager help and reference for those students engaged in scientific research who need innovation or friends who engage in engineering projects to achieve better results. Since YOLOv8, YOLOv7, and YOLOv5 algorithms have emerged in 2020, a large number of improved papers have emerged. Whether it is for students engaged in scientific research or friends who are already working, the value and novelty of the research are not enough. In order to keep pace with the times In the future, the improved algorithm will be based on YOLOv7. The previous YOLOv5 improvement method is also applicable to YOLOv7, so continue the serial number of the YOLOv5 series improvement. In addition, the improved method can also be applied to other target detection algorithms such as YOLOv5 for improvement. Hope to be helpful to everyone.
1. Solve the problem
The method proposed in this paper mainly replaces layer-by-layer stacking with parallel sub-networks. This helps to effectively reduce depth while maintaining high performance. Try to use the proposed method to improve the target detection algorithm and improve the target detection effect.
2. Basic principles
Original link: 2110.07641.pdf (arxiv.org)
Code link: GitHub - imankgoyal/NonDeepNetworks: Official Code for "
Abstract: Depth is the hallmark of deep neural networks. However, more depth means more sequential computations and higher latency. This begs the question: is it possible to build high-performance "non-deep" neural networks? We show that this is possible. To do this, we use parallel sub-networks instead of layer-by-layer stacking. This helps to effectively reduce depth while maintaining high performance. By exploiting parallel substructures, we show for the first time that only a network of depth 12 can achieve more than 80% top-1 accuracy on ImageNet, 96% accuracy on CIFAR10, and 81% accuracy on CIFAR100 . We also show that a low-depth (12) backbone can achieve 48% AP on MS-COCO. We analyze the expansion rules we devise and show how performance can be improved without changing the depth of the network. Finally, we provide a proof-of-concept showing how to build a low-latency recognition system using non-deep networks.
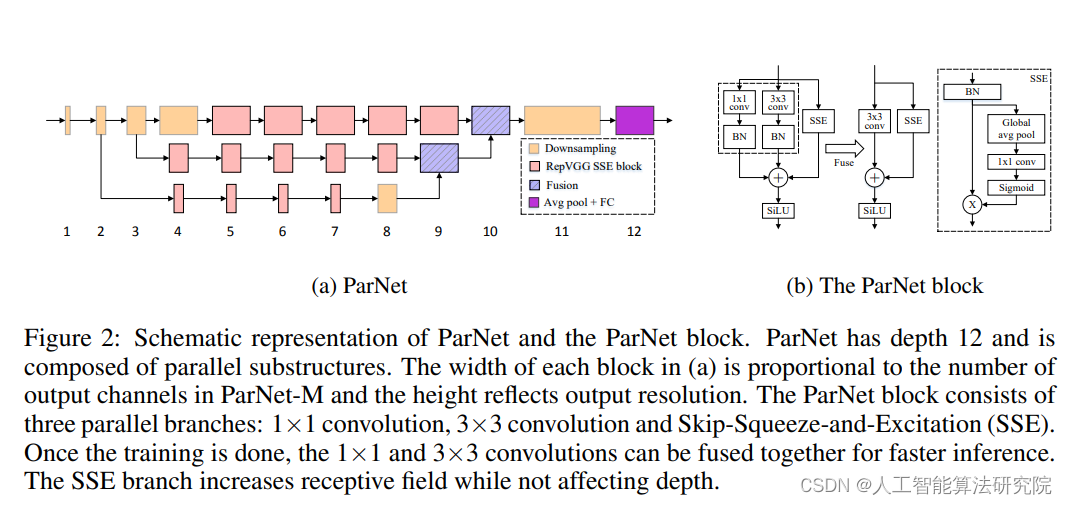
3. Add method
Part of the reference source code proposed in the original paper is as follows:
class FeatureHookNet(nn.ModuleDict):
""" FeatureHookNet
Wrap a model and extract features specified by the out indices using forward/forward-pre hooks.
If `no_rewrite` is True, features are extracted via hooks without modifying the underlying
network in any way.
If `no_rewrite` is False, the model will be re-written as in the
FeatureList/FeatureDict case by folding first to second (Sequential only) level modules into this one.
FIXME this does not currently work with Torchscript, see FeatureHooks class
"""
def __init__(
self, model,
out_indices=(0, 1, 2, 3, 4), out_map=None, out_as_dict=False, no_rewrite=False,
feature_concat=False, flatten_sequential=False, default_hook_type='forward'):
super(FeatureHookNet, self).__init__()
assert not torch.jit.is_scripting()
self.feature_info = _get_feature_info(model, out_indices)
self.out_as_dict = out_as_dict
layers = OrderedDict()
hooks = []
if no_rewrite:
assert not flatten_sequential
if hasattr(model, 'reset_classifier'): # make sure classifier is removed?
model.reset_classifier(0)
layers['body'] = model
hooks.extend(self.feature_info.get_dicts())
else:
modules = _module_list(model, flatten_sequential=flatten_sequential)
remaining = {f['module']: f['hook_type'] if 'hook_type' in f else default_hook_type
for f in self.feature_info.get_dicts()}
for new_name, old_name, module in modules:
layers[new_name] = module
for fn, fm in module.named_modules(prefix=old_name):
if fn in remaining:
hooks.append(dict(module=fn, hook_type=remaining[fn]))
del remaining[fn]
if not remaining:
break
assert not remaining, f'Return layers ({remaining}) are not present in model'
self.update(layers)
self.hooks = FeatureHooks(hooks, model.named_modules(), out_map=out_map)
def forward(self, x):
for name, module in self.items():
x = module(x)
out = self.hooks.get_output(x.device)
return out if self.out_as_dict else list(out.values())The number of network layers and parameters after the improvement are as follows. The blogger is training and testing on the NWPU VHR-10 remote sensing dataset, and the experiment has an improvement effect. For specific methods of obtaining, you can private message to obtain the Baidu link of the improved YOLO project.


Four. Summary
A preview: the next article will continue to share related improvement methods for deep learning algorithms. Interested friends can pay attention to me, if you have any questions, you can leave a message or chat with me privately
PS: This method is not only suitable for improving YOLOv5, but also can improve other YOLO networks and target detection networks, such as YOLOv7, v6, v4, v3, Faster rcnn, ssd, etc.
Finally, please pay attention to private message me if you need it. Pay attention to receive free learning materials for deep learning algorithms!