1. The overall structure of the yolov4 network
The network components of yolov4:
Backbone: CSPDarknet53
Neck: SPP, PAN
Head: YOLOv3
The following figure is the overall structure of yolov4:

2. CSPDarknet53 main network architecture
The CSPDarknet53 network joins CSP on the basis of Darknet53. Let's first understand the CSPNet network. The full name of CSP is Cross Stage Partial. It can enhance the learning ability of CNN and can effectively improve the accuracy rate under the condition of lightweight, low calculation and low memory access cost. (Paper: https://arxiv.org/pdf/1911.11929.pdf)
The following figure is CSPNet added to ResNet(X)t:

Let's see the Darknet53 network again, the structure is shown in the figure below:

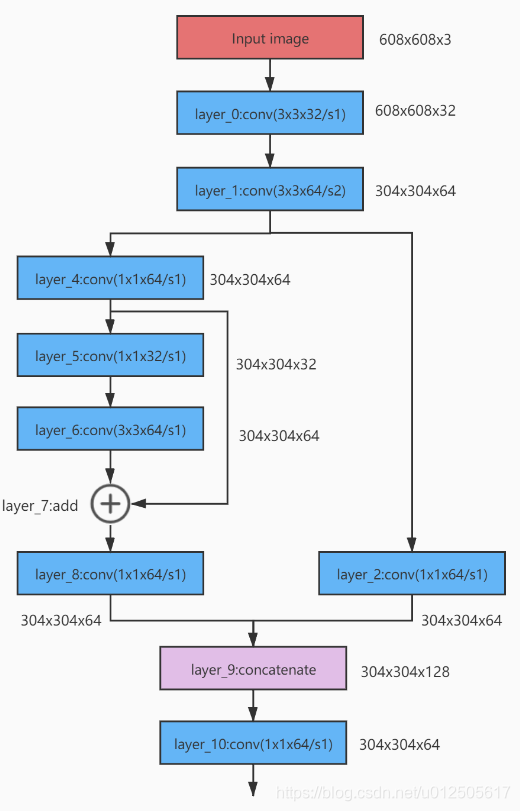

The convolution of kernel=3x3, stride=2 is used in front of the network CSPResNe(x)t residual block, and the size W and H of the feature map will be halved. After the residual block, concat is used to splice the channels.
code show as below:
import torch
import torch.nn.functional as F
import torch.nn as nn
import math
from collections import OrderedDict
#-------------------------------------------------#
# MISH激活函数
#-------------------------------------------------#
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
#-------------------------------------------------#
# 卷积块
# CONV+BATCHNORM+MISH
#-------------------------------------------------#
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = Mish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
#---------------------------------------------------#
# CSPdarknet的结构块的组成部分
# 内部堆叠的残差块
#---------------------------------------------------#
class Resblock(nn.Module):
def __init__(self, channels, hidden_channels=None, residual_activation=nn.Identity()):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x+self.block(x)
#---------------------------------------------------#
# CSPdarknet的结构块
# 存在一个大残差边
# 这个大残差边绕过了很多的残差结构
#---------------------------------------------------#
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2)
if first:
self.split_conv0 = BasicConv(out_channels, out_channels, 1)
self.split_conv1 = BasicConv(out_channels, out_channels, 1)
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels//2),
BasicConv(out_channels, out_channels, 1)
)
self.concat_conv = BasicConv(out_channels*2, out_channels, 1)
else:
self.split_conv0 = BasicConv(out_channels, out_channels//2, 1)
self.split_conv1 = BasicConv(out_channels, out_channels//2, 1)
self.blocks_conv = nn.Sequential(
*[Resblock(out_channels//2) for _ in range(num_blocks)],
BasicConv(out_channels//2, out_channels//2, 1)
)
self.concat_conv = BasicConv(out_channels, out_channels, 1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
x = torch.cat([x1, x0], dim=1)
x = self.concat_conv(x)
return x
class CSPDarkNet(nn.Module):
def __init__(self, layers):
super(CSPDarkNet, self).__init__()
self.inplanes = 32
self.conv1 = BasicConv(3, self.inplanes, kernel_size=3, stride=1)
self.feature_channels = [64, 128, 256, 512, 1024]
self.stages = nn.ModuleList([
Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True),
Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False),
Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False),
Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False),
Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False)
])
self.num_features = 1
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.stages[0](x)
x = self.stages[1](x)
out3 = self.stages[2](x)
out4 = self.stages[3](out3)
out5 = self.stages[4](out4)
return out3, out4, out5
def darknet53(pretrained, **kwargs):
model = CSPDarkNet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
3. SPP, PAN module
The full name of SPP is SPATIAL Pyramid Pooling, spatial pyramid pooling, and the network structure is shown in the figure below:

The role of SPP in YOLOv4 is to increase the receptive field of the network. Three different scale pooling 5x5, 9x9, 13x13 are used in the network, so that more abundant features will be obtained. After pooling, the output of the three pooling layers is concatenated by concat, and after splicing, the feature dimensionality is reduced through the 1x1 conv layer.

#---------------------------------------------------#
# SPP结构,利用不同大小的池化核进行池化
# 池化后堆叠
#---------------------------------------------------#
class SpatialPyramidPooling(nn.Module):
def __init__(self, pool_sizes=[5, 9, 13]):
super(SpatialPyramidPooling, self).__init__()
self.maxpools = nn.ModuleList([nn.MaxPool2d(pool_size, 1, pool_size//2) for pool_size in pool_sizes])
def forward(self, x):
features = [maxpool(x) for maxpool in self.maxpools[::-1]]
features = torch.cat(features + [x], dim=1)
return features
PANet is mainly to solve the multi-scale problem in target detection and improve the detection ability of objects of different sizes. Its function is somewhat similar to FPN. Compared with FPN, its structure adds a layer of downsample operation behind FPN, as shown in the figure:

4. Head module
After the feature map is output by PANet, three outputs will be obtained. These three outputs will pass through the YOLOv3 head. The YOLOv3 head is composed of two conv layers. Its structure is shown in the figure below. Then get three prediction results predict1, predict2, predict3, where the dimension of predict is: wxhx 3*(4 + 1 + class_num), class_num represents the number of categories.

Code for the whole frame:
#---------------------------------------------------#
# 最后获得yolov4的输出
#---------------------------------------------------#
def yolo_head(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 3),
nn.Conv2d(filters_list[0], filters_list[1], 1),
)
return m
#---------------------------------------------------#
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, config):
super(YoloBody, self).__init__()
self.config = config
# backbone
self.backbone = darknet53(None)
self.conv1 = make_three_conv([512,1024],1024)
self.SPP = SpatialPyramidPooling()
self.conv2 = make_three_conv([512,1024],2048)
self.upsample1 = Upsample(512,256)
self.conv_for_P4 = conv2d(512,256,1)
self.make_five_conv1 = make_five_conv([256, 512],512)
self.upsample2 = Upsample(256,128)
self.conv_for_P3 = conv2d(256,128,1)
self.make_five_conv2 = make_five_conv([128, 256],256)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter2 = len(config["yolo"]["anchors"][2]) * (5 + config["yolo"]["classes"])
self.yolo_head3 = yolo_head([256, final_out_filter2],128)
self.down_sample1 = conv2d(128,256,3,stride=2)
self.make_five_conv3 = make_five_conv([256, 512],512)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter1 = len(config["yolo"]["anchors"][1]) * (5 + config["yolo"]["classes"])
self.yolo_head2 = yolo_head([512, final_out_filter1],256)
self.down_sample2 = conv2d(256,512,3,stride=2)
self.make_five_conv4 = make_five_conv([512, 1024],1024)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter0 = len(config["yolo"]["anchors"][0]) * (5 + config["yolo"]["classes"])
self.yolo_head1 = yolo_head([1024, final_out_filter0],512)
def forward(self, x):
# backbone
x2, x1, x0 = self.backbone(x)
P5 = self.conv1(x0)
P5 = self.SPP(P5)
P5 = self.conv2(P5)
P5_upsample = self.upsample1(P5)
P4 = self.conv_for_P4(x1)
P4 = torch.cat([P4,P5_upsample],axis=1)
P4 = self.make_five_conv1(P4)
P4_upsample = self.upsample2(P4)
P3 = self.conv_for_P3(x2)
P3 = torch.cat([P3,P4_upsample],axis=1)
P3 = self.make_five_conv2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample,P4],axis=1)
P4 = self.make_five_conv3(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample,P5],axis=1)
P5 = self.make_five_conv4(P5)
out2 = self.yolo_head3(P3)
out1 = self.yolo_head2(P4)
out0 = self.yolo_head1(P5)
return out0, out1, out2
Reference:
Pytorch builds YoloV4 target detection platform
with the most detailed analysis of YOLOv4 network structure