Article directory
I. Introduction
To learn target detection, of course, you must learn R-CNN, the pioneering work in the field of target detection. This article is a personal note.

2. Principle steps of R-CNN
R-CNN is divided into four steps:
1. About 1-2k candidate boxes are generated by the SS algorithm.
2. Input the candidate frame into the deep network to extract features.
3. Use the SVM classifier to get the score of each candidate box belonging to each category.
4. Use the regressor to correct the position of the candidate frame
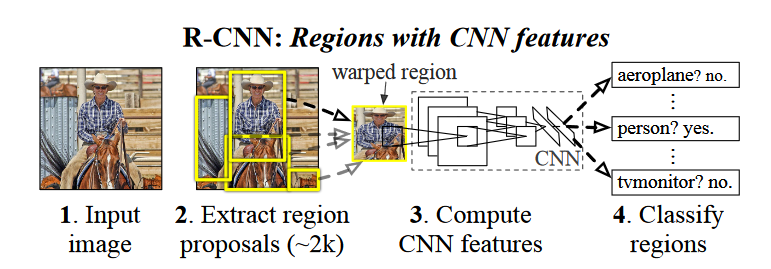
2.1.Selective Search generates target detection frame
Regarding the principle of Selective search, you can read another blog post I wrote for details . Briefly speaking: the general meaning is to first initialize the division area according to the image segmentation algorithm,
Then calculate the similarity and merge sub-regions according to different color modes, target colors, textures, sizes, shapes and other characteristics, so that the regions are less than the exhaustive method, saving computing resources and improving efficiency.
At the same time, it can have a good recall rate, so that the generated candidate boxes can well cover all the targets to be detected.
2.2. Use deep network to extract features for candidate regions
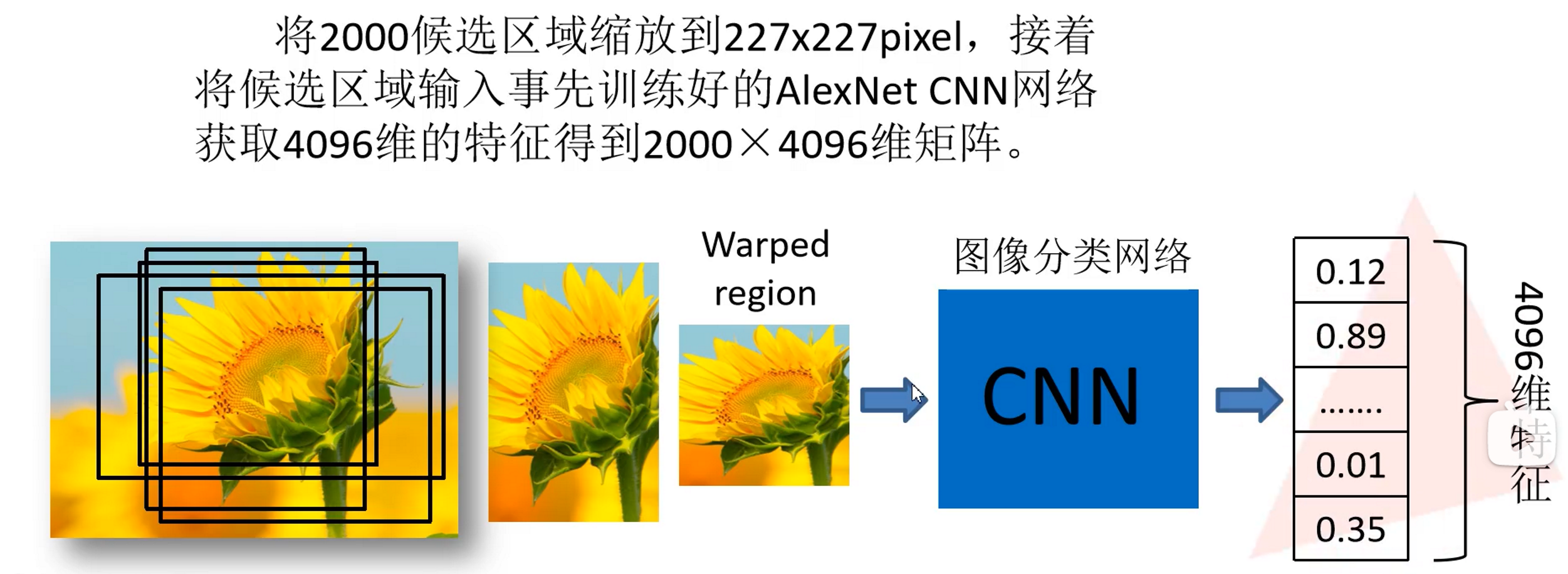
The difference from before is that AlexNet here removes the following fully connected layer and only keeps one layer of fully connected
2.3. SVM classification
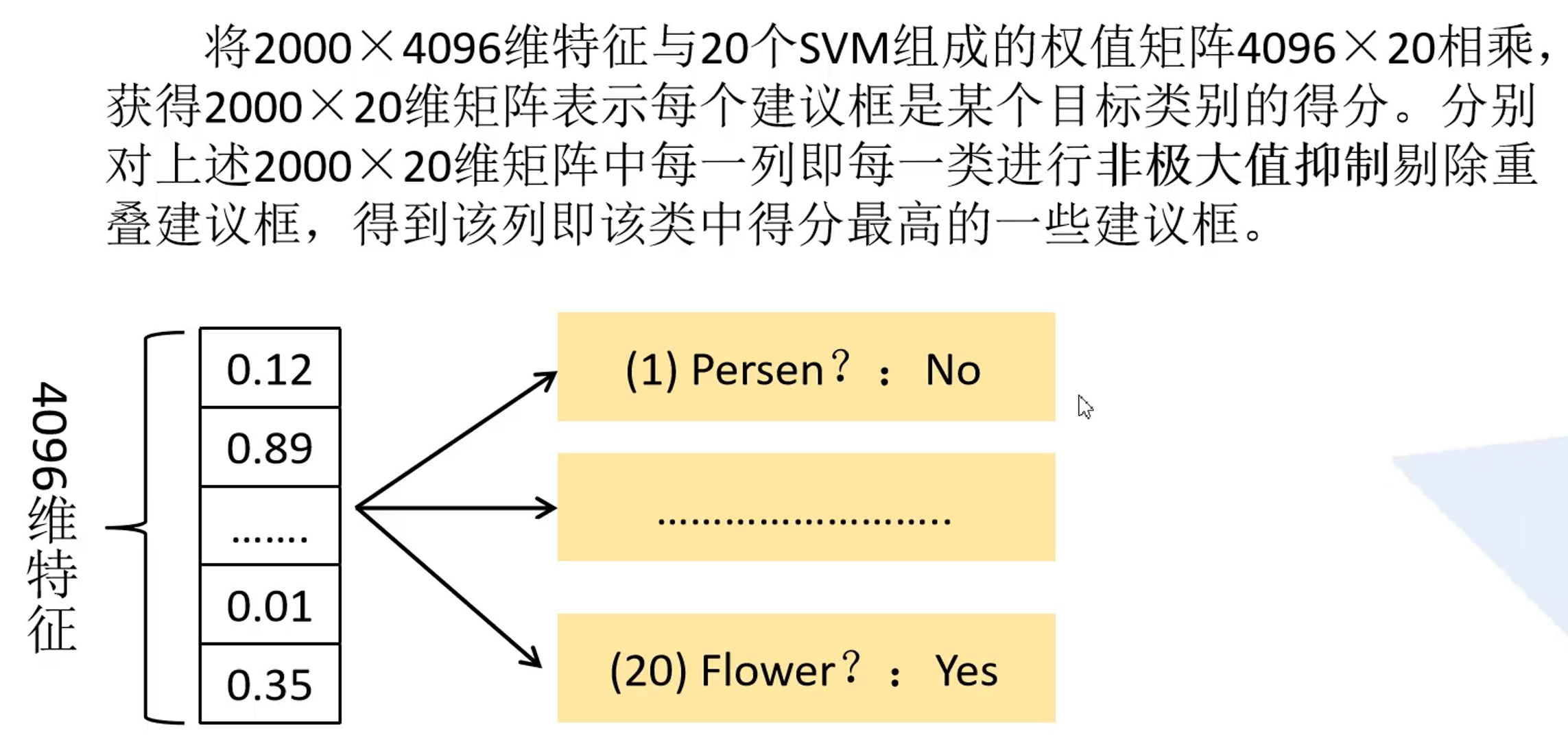
Because the PASCAL VOC dataset is used here, there are finally 20 SVM classifiers
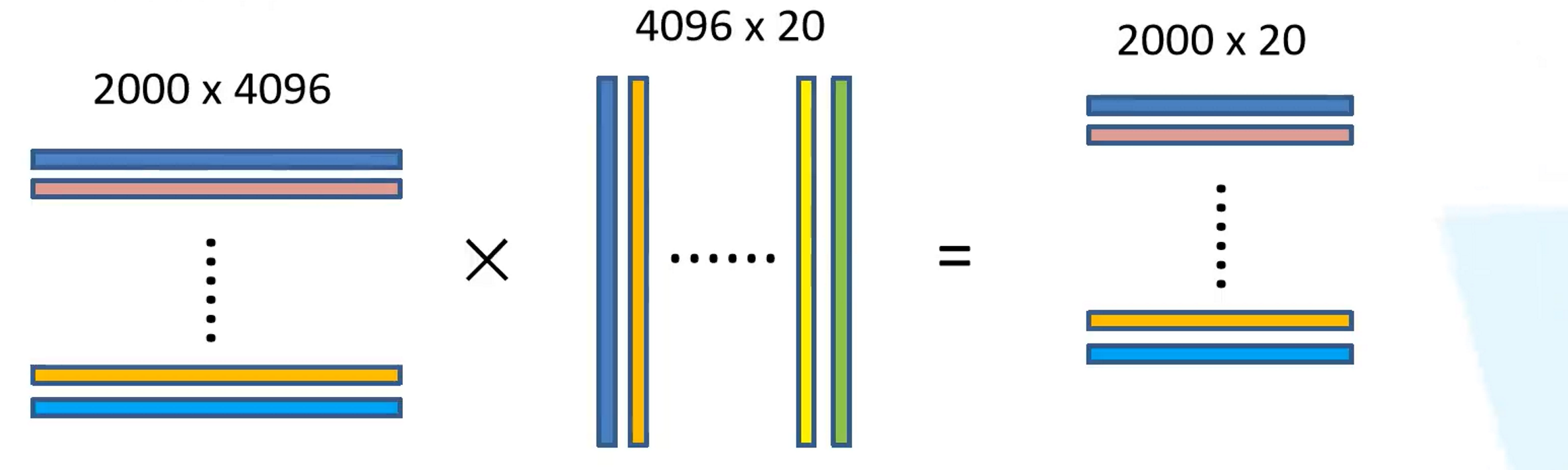
As shown above, the feature matrix of 2000✖4096 represents the features extracted from 2000 candidate frames after passing through the deep convolutional network. For each candidate frame, that is, for each 4096-dimensional feature vector, we need to use SVM to judge its category. , for each category needs to be judged, there are 20 categories in total, so the weight matrix is 2000✖20, and the final probability matrix of 2000✖20 is obtained. Each row represents the probability distribution that it belongs to these 20 categories. For each For a 20-dimensional probability vector, the probability of each position in it represents the probability that the candidate frame target belongs to the corresponding position category.
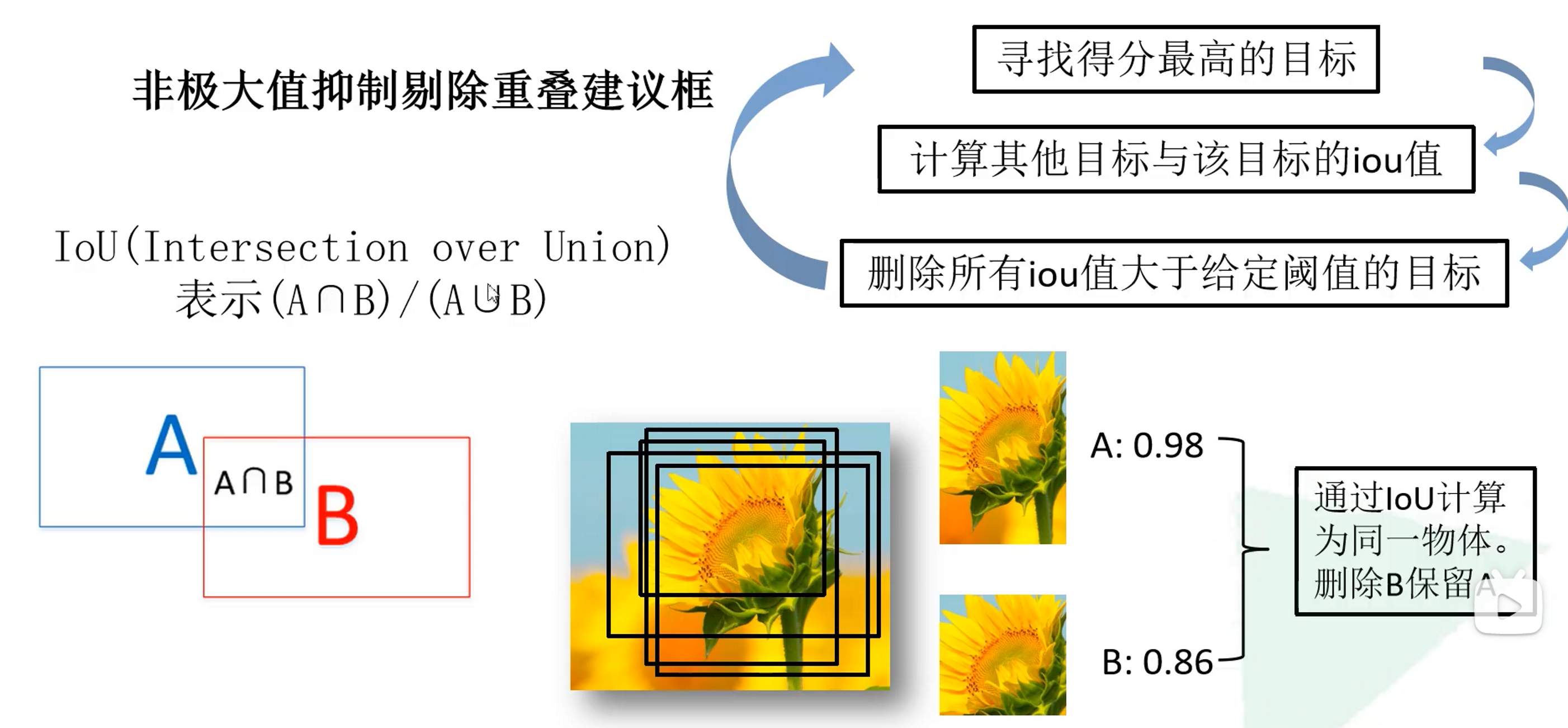
After obtaining the category scores of all candidate boxes, non-maximum value suppression is performed to eliminate some overlapping candidate boxes
Example: Suppose we get some candidate boxes for sunflowers in the above picture, extract features by inputting a deep convolutional network, and then use the SVM classifier, we finally get the scores of these candidate boxes for the sunflower category, and we find the highest score candidate box,Calculate the IOU between the candidate box and other candidate boxes. If the IOU is greater than a certain threshold, we can consider the two boxes to be the same and delete the candidate box.. We can consider the remaining multiple candidate frames as candidate frames for sunflowers, but the positions are different, that is to say, there are multiple sunflowers in the picture.
Question 1: Some people may be thinking why not directly retain the candidate frame with the maximum score. If a threshold is greater than a certain score, can multiple candidate frames be retained?
Answer: This understanding is actually wrong, because we cannot guarantee that the candidate frame is not detecting the same target. If the same target is detected and the scores are greater than this threshold, wouldn’t it be that multiple prediction frames of the same target are retained? Here, the non-maximum value suppression personal understanding is to delete redundant candidate boxes of the same target, that is to say, we think that the last remaining candidate boxes are not the same target.
Question 2: How do the loop operations in the figure work?
Answer: I personally think that we first find the detection frame with the largest score, and thenCalculate other boxes and its IOU, delete the detection box that detects the same target as it detects, keep the largest detection frame ( this detection frame will not be added to the calculation later ), and then continue to find a detection frame with the highest score, and delete the detection frame that is the same target as it detects but has a lower score than it, and so on analogy.
2.4. Use the regressor to fine-tune the position of the candidate frame

The further screening here refers to: it is necessary to calculate the IOU between the candidate frame and the real frame filtered in the previous step, and retain the candidate frame with the IOU greater than a certain threshold, in order to delete the candidate frame that is too different from the real frame. After that, the regressor is also used to regress and correct the position of the candidate frame, and getThe x, y offset of the corrected center point and the x, y direction scaling。
3. Summary


Reference blog and learning video
B station up main video (forced push)
original paper address
code address