I. Introduction
Object detection classification is a machine learning task aimed at identifying objects in images or videos and classifying them into different categories. Different from traditional object classification tasks, object detection classification can not only determine the category of objects in an image, but also determine their locations and bounding boxes in the image.
Object detection classification typically involves the following steps:
-
Data collection and labeling: collect image or video data containing different categories of objects, and label them, including the category and bounding box information of each object.
-
Feature extraction: Use image processing and computer vision techniques to extract useful features from collected images. These features can include color histograms, texture features, shape descriptors, etc.
-
Model training: Use machine learning algorithms or deep learning models to train the extracted features with labeled categories and bounding boxes. Commonly used deep learning models include Convolutional Neural Networks (CNN) and target detection models, such as Faster R-CNN, YOLO, etc.
-
Model evaluation and tuning: Evaluate the performance of the model by evaluating the performance of the model on the test set, such as accuracy, recall, precision and other indicators. If the model performs poorly, it can be tuned, such as increasing training data, adjusting model parameters, etc.
-
Prediction and application: Use the trained model to predict new images or videos, identify and classify objects in them, and generate bounding boxes and corresponding category labels.
Object detection and classification are widely used in many application domains, including autonomous driving, video surveillance, object recognition, and image search, among others. It can help computers understand the content of objects in images and provide solutions to various practical problems.
The convolutional neural network training target detection model is greatly affected by resources such as machines and graphics cards, and is unfriendly to many people. Here is an online tool, Teachable Machine , which helps users create their own machine learning models without writing code. The goal of Teachable Machine is to make machine learning technology more accessible and understandable, so that more people can use machine learning to solve various problems.
2. Teachable Machine
The use of Teachable Machine is simple, as follows:
1. Homepage
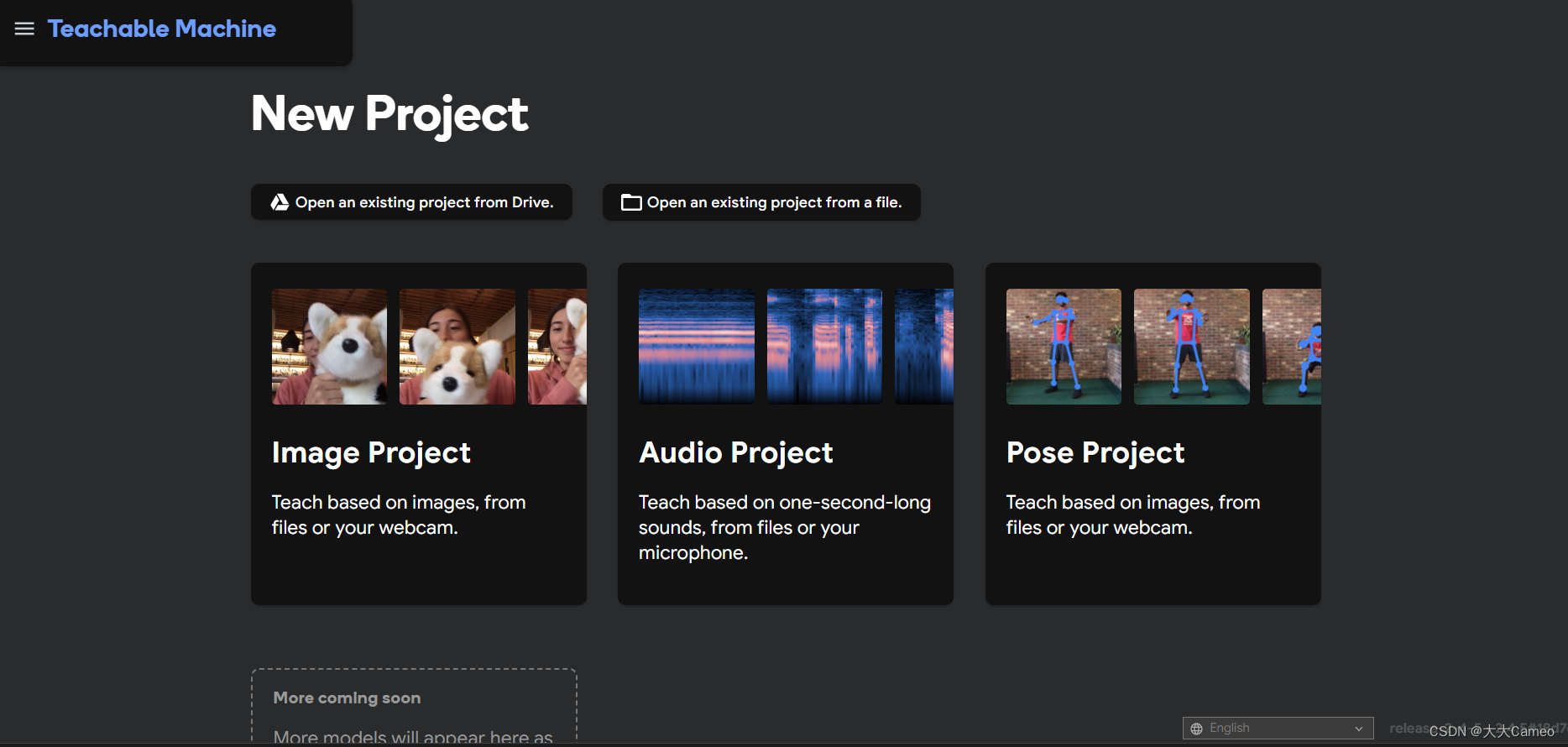
2. Training
You can use Teachable Machine to create custom models to classify images, recognize objects, detect poses, recognize sounds, and more.
Here we choose image detection classification:
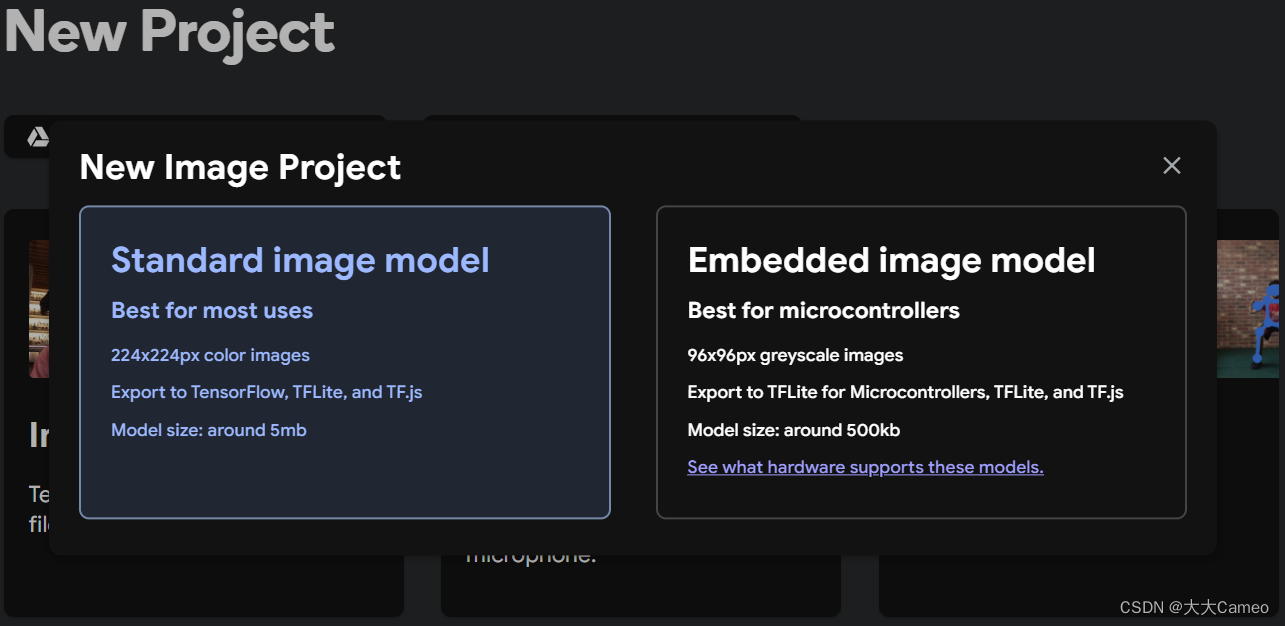
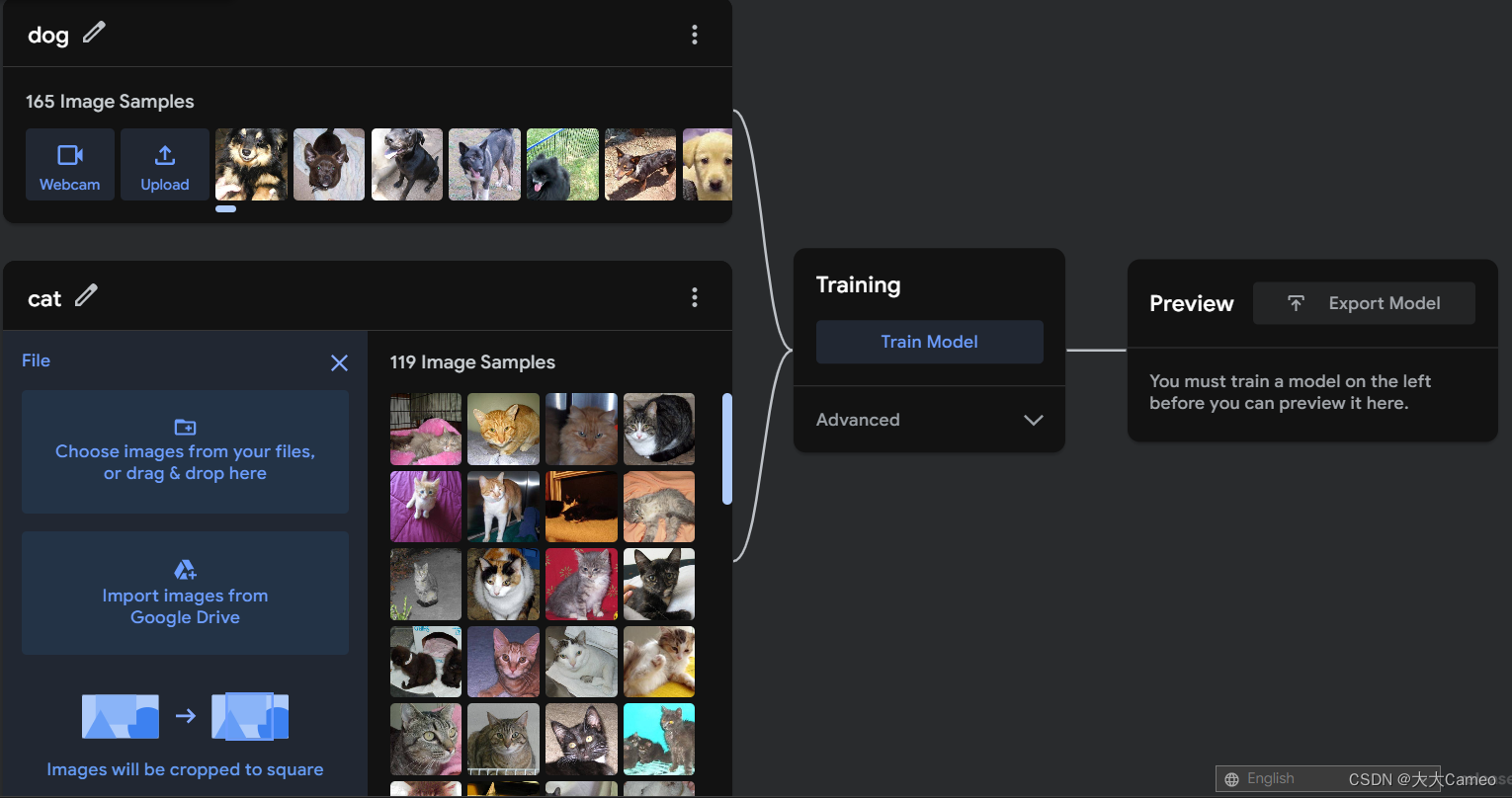
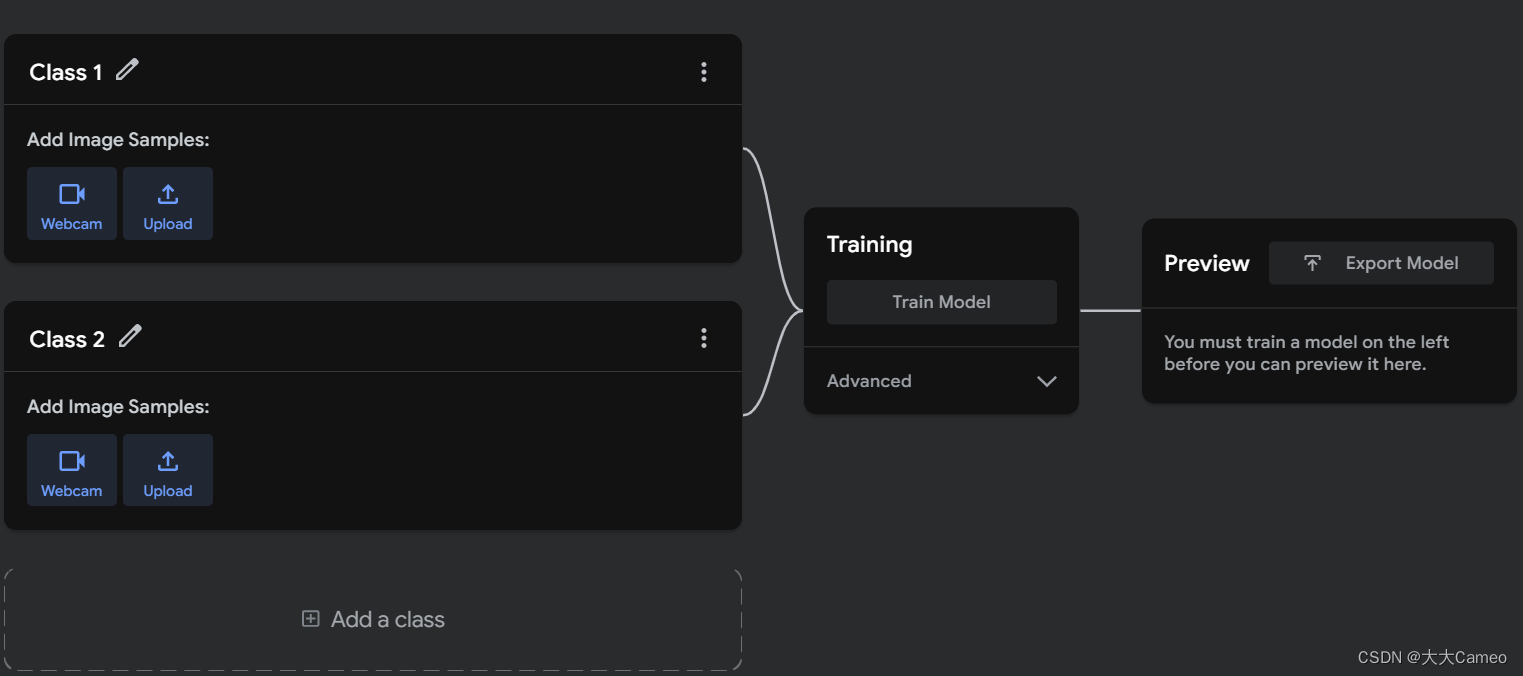 Next, import 100 (more and more accurate) images of cats and dogs for training.
Next, import 100 (more and more accurate) images of cats and dogs for training.
Click on Train Model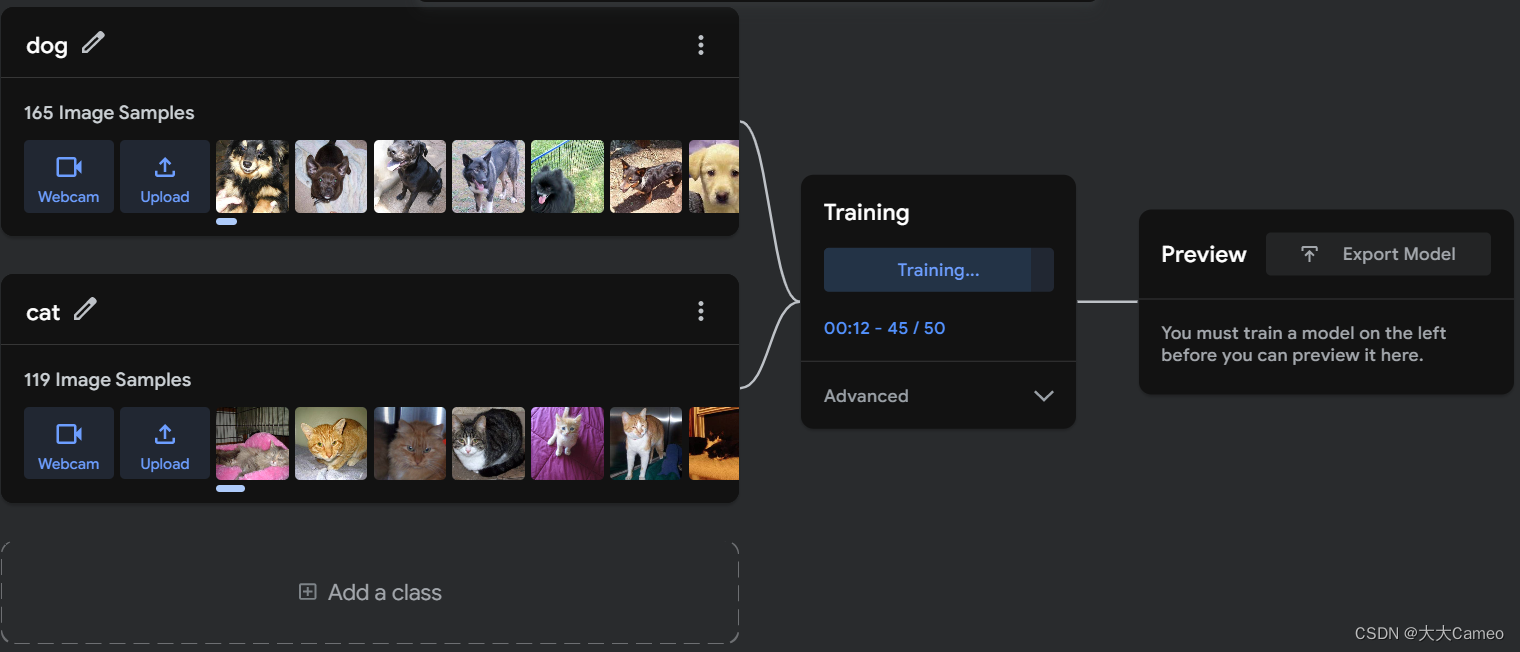
After the training is over, click Export Model, and then download the model as follows
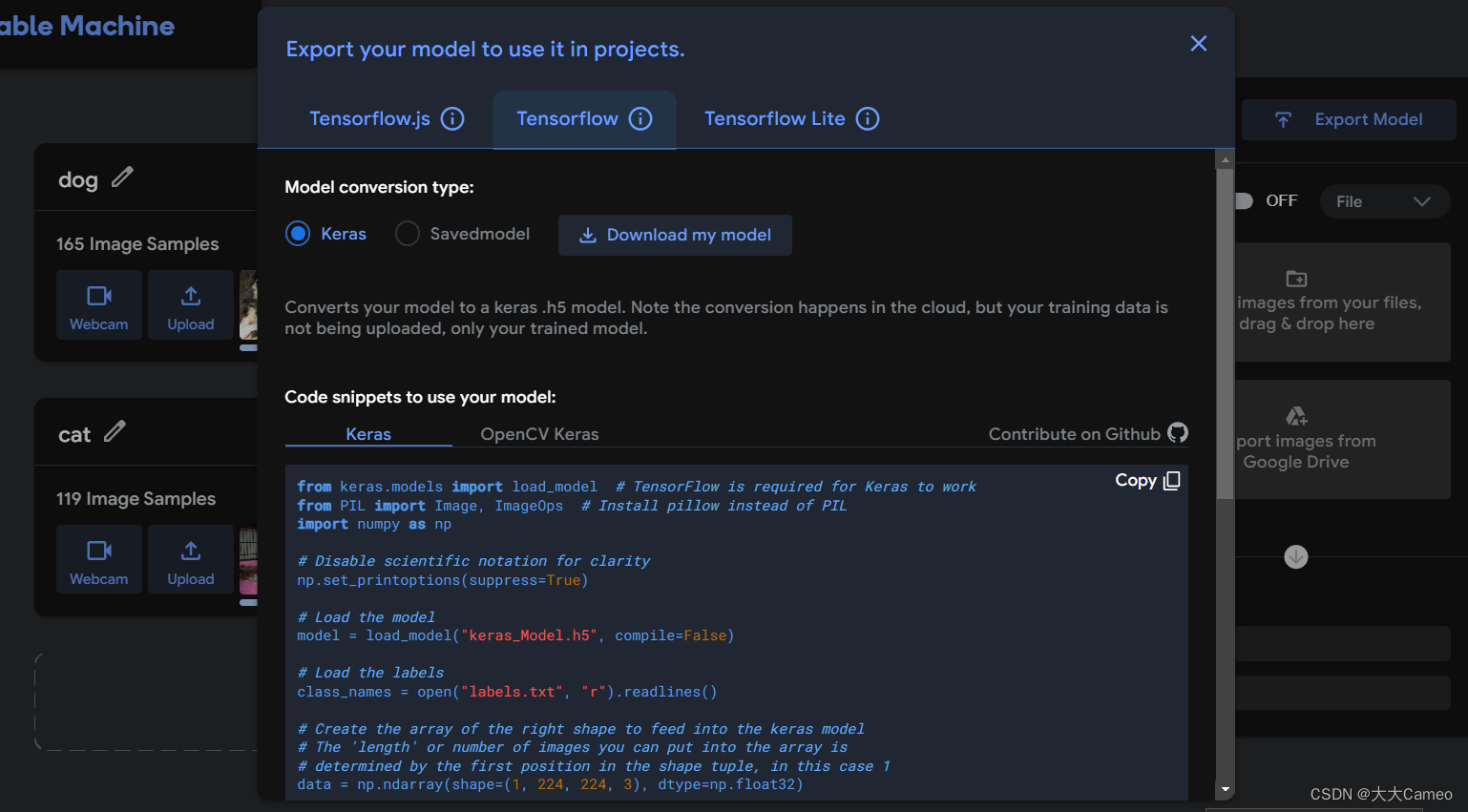
After downloading and decompressing, you can get the trained model keras_model.h5 and label.txt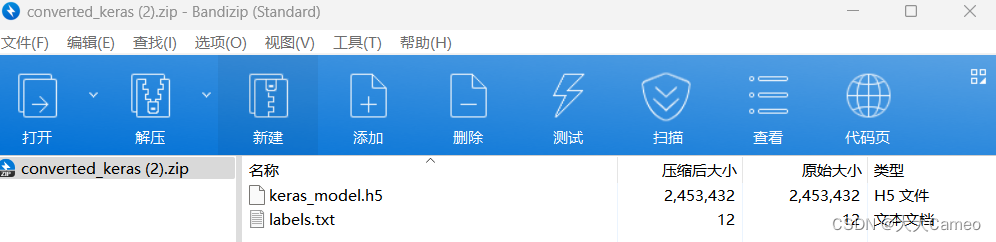
Three, actual combat
Project introduction: Use OpenCV and the above-mentioned trained model to quickly realize the detection and classification of cats and dogs. The effect is as follows:

1. Installation environment
pip install cvzone
pip install opencv-python
pip install tensorflow2. Code
import cv2
import os
import cvzone
from cvzone.ClassificationModule import Classifier
cap = cv2.VideoCapture('Wait_detection/dog.51.jpg') # 加载图片
# cap = cv2.VideoCapture(0) 视频检测
imgAnimalsList = [] # 物体列表
pathFolderAnimal = "animals" # 物体文件
pathlist = os.listdir(pathFolderAnimal)
# print(pathlist)
for path in pathlist:
print(path)
imgAnimalsList.append(cv2.imread(os.path.join(pathFolderAnimal, path), cv2.IMREAD_UNCHANGED))
maskClassifier = Classifier('model/keras_model.h5', 'model/labels.txt') # 引入模型
label_file = open('model/labels.txt', "r")
list_labels = [] # 可检测的物体名称列表
for line in label_file:
stripped_line = line.strip()
list_labels.append(stripped_line)
label_file.close()
# print(list_labels[1])
while True:
_, img = cap.read()
# imgresize = cv2.resize(img, (454, 340))
# 图像宽、高
w = int(cap.get(3))
h = int(cap.get(4))
imgbackgoround = cv2.imread('background.png') # 背景图片
predection = maskClassifier.getPrediction(img) # 检测
print(predection)
# print(predection[1])
id = predection[1] # 物体id
imgbackgoround = cvzone.overlayPNG(imgbackgoround, imgAnimalsList[id], (910, 150)) # 输出检测到的物体
imgbackgoround[148:148 + h, 159:159 + w] = img # 待检物体图片
cv2.putText(imgbackgoround, str(list_labels[id]),
(990, 120), cv2.FONT_HERSHEY_COMPLEX, 2, (0, 255, 1), 2) # 检测出的物体名称
print(list_labels[id])
# cv2.imshow("Image", img)
cv2.putText(imgbackgoround, 'result:', (830, 120), cv2.FONT_HERSHEY_PLAIN, 3, (0, 255, 0), 3)
cv2.imshow("Output", imgbackgoround)
cv2.waitKey(0) # 按任意键退出
Detect cats:

Finally, the full project documentation can also be referenced .