(In the past, I shouldn’t have thought that Likou is so simple. I really should read the official solution. The idea is so good. I was wrong and I learned it.)
Title:
The conversion sequence from the words beginWord and endWord in the dictionary wordList is a sequence formed according to the following specification: beginWord -> s1 -> s2 -> … -> sk: each pair of
adjacent words differs by only one letter.
For 1 <= i <= k, each si is in wordList. Note that beginWord does not need to be in wordList.
sk == endWord
gives you two words beginWord and endWord and a dictionary wordList, returns the number of words in the shortest transition sequence from beginWord to endWord. Returns 0 if no such conversion sequence exists.
Problem solution:
Don’t consider optimization first, just consider passing this problem
First put beginWord into wordList for easy processing
, then take a look at the data, 1 <= wordList.length <= 5000, well, the complexity of the algorithm should be controlled at O(n^2), so let’s not say much directly, just type the table, if true if only one character differs between the two strings, otherwise false
Then we require the shortest sequence, which is the shortest path, and then the weight of each side is 1, and the bfs goes through it again, and the
code show as below:
class Solution {
public:
bool flag[5005][5005];
bool fff[5005];
int n;
queue<pair<int, int> > temp;
int solve(int a, int p) {
fff[a] = true;
temp.push(make_pair(a, 1));
while(!temp.empty()) {
pair<int, int> t = temp.front();
temp.pop();
for(int i = 0; i < n; i++) {
if(i == p && flag[t.first][i]) return t.second + 1;
if(!fff[i] && flag[t.first][i]) {
fff[i] = true;
temp.push(make_pair(i, t.second + 1));
}
}
}
return 0;
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
wordList.insert(wordList.begin(), beginWord);
int f = -1;
n = wordList.size();
for(int i = 0; i < wordList.size(); i++) {
if(wordList[i] == endWord) f = i;
flag[i][i] = false;
for(int j = i + 1; j < wordList.size(); j++) {
int t = 0;
for(int k = 0; k < beginWord.size(); k++) {
if(wordList[i][k] != wordList[j][k]) t++;
}
if(t == 1) flag[i][j] = flag[j][i] = true;
else flag[i][j] = flag[j][i] = false;
}
}
cout << n << endl;
if(f == -1) return 0;
return solve(0, f);
}
};
Then I took a look at the official problem solution, and it feels really good, two optimizations:
① Optimizing the construction of the map
(the number of strings should not be so small, otherwise people like me will definitely use pairwise comparisons, and they will not consider other methods)
In our case, every two data comparisons are O(n^2), but will our efficiency be too low?
Consider, can we use space for efficiency? How to change it?
For example, "abcde", can we save " bcde", "a cde", "ab de"..., if we save it like this, will all the strings corresponding to "a cde" be the same by changing one character?
Finally, we put each "a*cde" In this way, the corresponding strings are paired to make an edge
Consider that "a*cde" has at most 26 corresponding strings, because * corresponds to different letters, so it will not time out
But is there a better way? After all, two-two operations are somewhat wasteful.
Of course, if we connect the strings corresponding to "a cde" with "a cde", then it is not equivalent to having a path between each string, but the path length changes from the original 1. into 2, and finally divide the result by 2, which is obviously better
(Note, how do we save the string corresponding to "a*cde", this must be a map, the key is a string, and the value is a vector, but we use unordered_map is better, and the unsorted hash table is faster. )
② Optimize bfs
(borrow the official map, understand it at a glance)
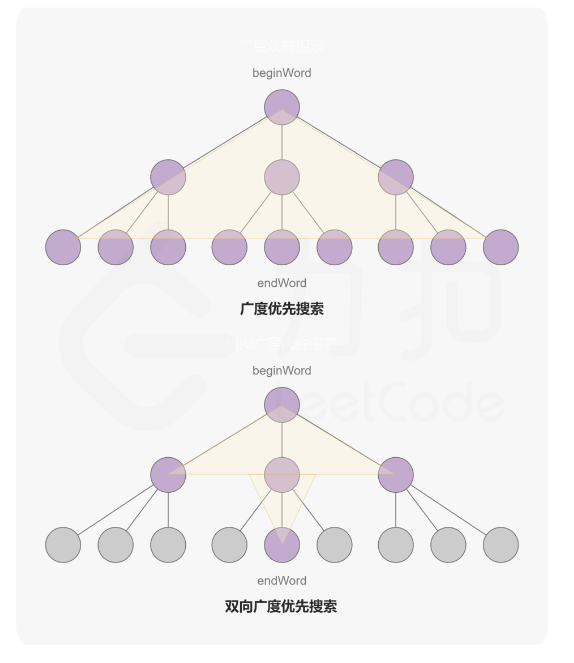
conduct a wide search from the starting point and the end point respectively, and end the search when the same point is encountered
(How to make sure that we have encountered the same point? Use an unordered_map to store the currently traversed point and the length of the path. If the key already exists in the unordered_map, it means that it has been traversed, so you can judge that you have encountered the same point , the search ends at this point)