What is a Graph?
It looks like the following abstract structure:
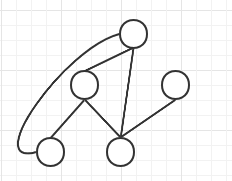
This does look a bit abstract  ̄□ ̄||. .
Let's look at another one:
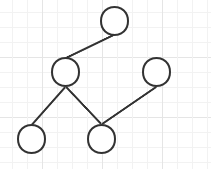
This is a binary tree. I subtracted a few "connections" from the previous diagram to become a tree.
So to a certain extent, the graph can be understood as an extension of the tree (the graph further breaks the "rules" of the tree).
The "graph" in the program
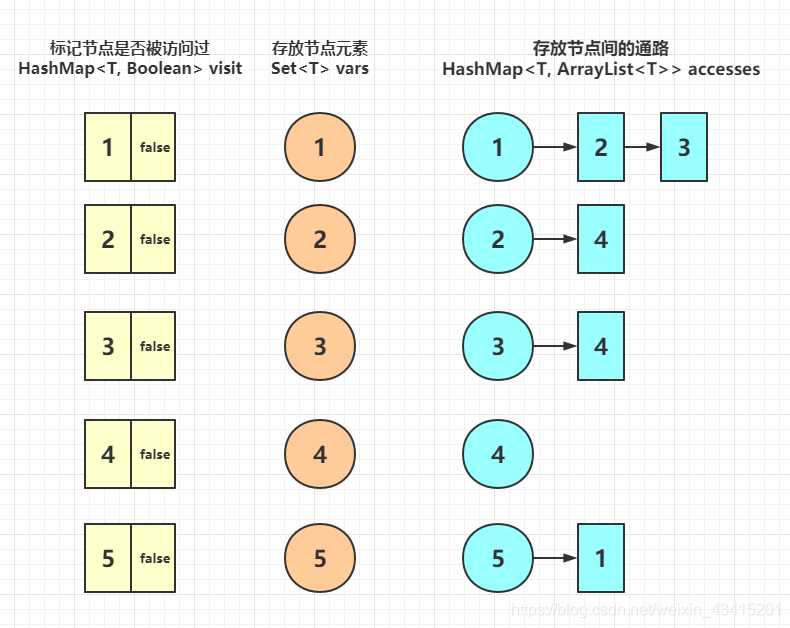
graph storage
- A collection (Set) is needed to store our node elements.
- A map (HashMap) is needed to store whether the node has been visited.
- A HashMap<T, ArrayList> is required to store paths between nodes.
As shown below:
Code
The DFS depth-first traversal algorithm is also included.
import java.util.*;
/**
* @ClassName ArrayGraph
* @Description 自定义“有向图”class,不允许有重复的元素
* @Author SkySong
* @Date 2021-05-16 17:14
*/
public class ArrayGraph<T> {
//存放节点元素
private Set<T> vars;
//标记节点是否被访问过
private HashMap<T, Boolean> visit;
//节点间的通路
private HashMap<T, ArrayList<T>> accesses = new HashMap<>();
/**
* 清空访问
*/
public void clearVisit() {
try {
vars.forEach((k) -> visit.put(k, false));
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 初始化节点集合
*
* @param vars 节点集合
*/
public ArrayGraph(Set<T> vars) {
this.vars = vars;
visit = new HashMap<>();
clearVisit();
}
/**
* 添加节点间通路
*
* @param from 出发节点
* @param to 目的节点
*/
public void addAccess(T from, T to) {
if (!vars.contains(from) && !vars.contains(to)) {
return;
}
ArrayList<T> ts = accesses.get(from);
if (ts == null) {
ts = new ArrayList<>();
}
ts.add(to);
accesses.put(from, ts);
}
/**
* DFS 深度优先遍历
*
* @param head 起始节点
* @return 图 “变” 数组
*/
public List<T> DFSOrder(T head) {
if (!vars.contains(head)) {
return null;
}
//创建一个list,用来存放最终的有序 序列
ArrayList<T> list = new ArrayList<>();
//毫无疑问,第一个遍历的节点元素一定是 我们传进去的 head
list.add(head);
//确定 head 的通路(head通向的节点)
ArrayList<T> ts = accesses.get(head);
if (ts == null || ts.isEmpty()){
visit.put(head,true);
return list;
}
//改变 head 的访问状态
visit.put(head,true);
Stack<T> stack = new Stack<>();
stack.push(head);
while (!stack.isEmpty()){
int index = 0;
for (T t : ts) {
//如果此节点已经访问过了,我们就不做任何操作
if (visit.get(t)){
continue;
}
//如果此节点没有访问过,访问之
list.add(t);
//改变节点访问状态
visit.put(t,true);
//探寻此节点的下一层“通路”
ts = accesses.get(t);
if (ts != null){
//如果此节点下一层有“通路”,便将此节点放入栈中
stack.push(t);
//并改变标志位,跳过出栈操作
index++;
}
break;
}
//如果此节点没有下一层可以访问,则触发出栈操作,去上一层寻找
if (index == 0){
T pop = stack.pop();
ts = accesses.get(pop);
}
}
return list;
}
}
For this DFS, we roughly elaborate on the idea.
First of all, it is clear that the traversal of the graph needs to determine a starting node. (This is also the parameter of our DFS method).
-
First of all, we need a stack, which is the main tool to complete our "depth first"
What is "depth first", when we encounter a branch during the access process, we first select the branch of the next layer for access.
We use the "first-in, last-out" feature of the stack to save the "superiors" of the current node layer by layer. Make sure we can find them layer by layer.
-
We start to visit, visit one node at each layer and then go down to the next layer. When we find that we can’t go down (the nodes connected to the current node have been visited), we go up one layer, and then repeat the above process.
test
public static void main(String[] args) {
ArrayGraph<Integer> graph = new ArrayGraph<>(Sets.newHashSet(1,2,3,4,5));
graph.addAccess(1,2);
graph.addAccess(1,3);
graph.addAccess(2,4);
graph.addAccess(3,4);
graph.addAccess(5,1);
System.out.println(graph.DFSOrder(5).toString());
}
result:
[5, 1, 2, 4, 3]
Attach the picture, and everyone can verify it by themselves:
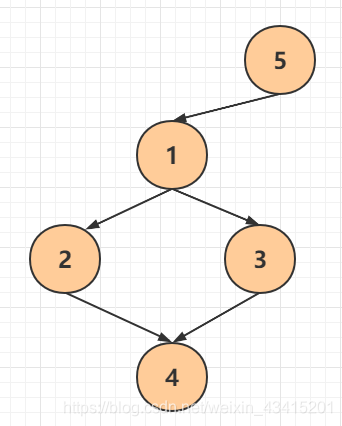
expand
This example is about a directed graph, but it can also be used as an undirected graph:
When we add the "passage", by the way, add the reverse, and it can be realized.
This example says that repeated elements are not allowed. In fact, you can think about this problem in a different direction.
In the practical application of graphs, elements are often reference objects, which are relatively complex data structures. They may have the same content, but their reference addresses are different, so "sameness" can also be achieved to a certain extent.
That’s all,thank you ! ! !