| Xiaoxi, Python
If you are a novice with a large model, how would you feel when you first saw the weird combination of words such as GPT, PaLm, and LLaMA ? If you go deeper and see strange words like BERT, BART, RoBERTa, ELMo popping up one after another, I wonder if I, as a novice, will go crazy ?
Even an old bird who has lived in the small circle of NLP for a long time, with the explosive development speed of the large model, may not be able to keep up with this large model that is chasing new ideas and changing rapidly. martial arts . At this time, it may be necessary to invite a large model review to help! This large-scale model review " Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond " launched by researchers from Amazon, Texas A&M University and Rice University combs for us by building a "family tree" The past, present, and future of large models represented by ChatGPT are described, and starting from the task, it builds a very comprehensive practical guide for large models, introduces the advantages and disadvantages of large models in different tasks, and finally points out the advantages and disadvantages of large models. Model current risks and challenges.
论文题目:
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Paper link:
https://arxiv.org/pdf/2304.13712.pdf
Project home page:
https://github.com/Mooler0410/LLMsPracticalGuide
Large model research test portal
ChatGPT Portal (wall-free, can be tested directly):
https://yeschat.cn
GPT-4 Portal (free of wall, can be tested directly, in case of browser warning point advanced/continue to visit):
https://gpt4test.com
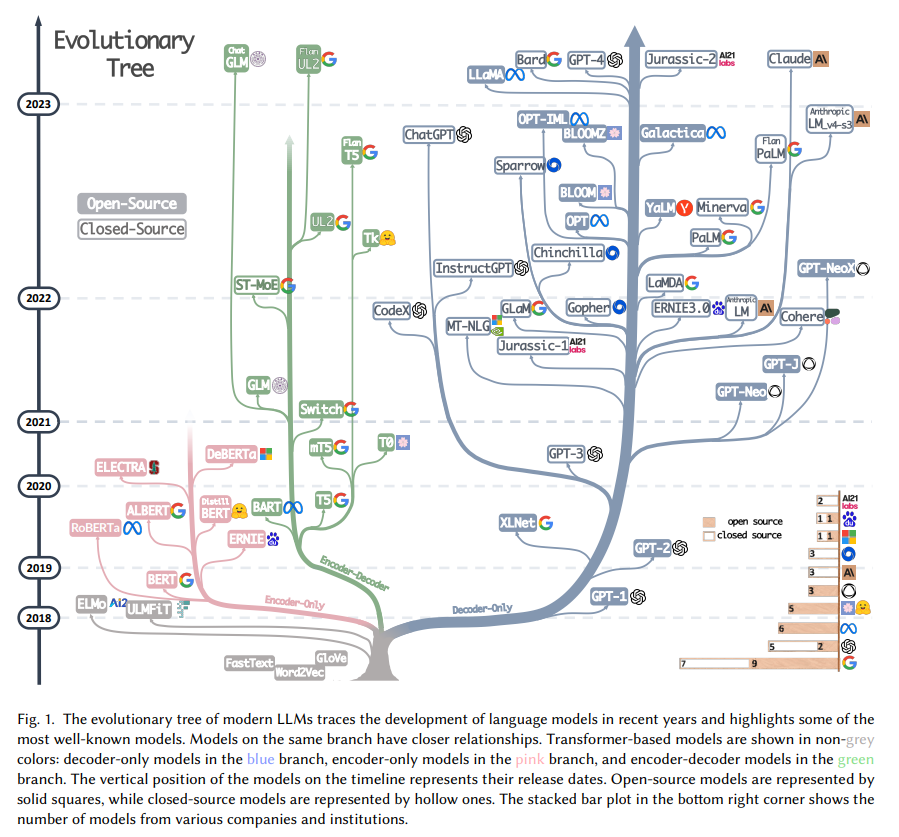
Family tree - the past and present of the big model
Pursuing the "source of all evil" of the large model should probably start from the article "Attention is All You Need", based on the machine translation model Transformer composed of multiple sets of Encoder and Decoder proposed by the Google machine translation team, the large model The development of Encoder has generally embarked on two paths. One path is to abandon the Decoder part and only use the Encoder as the pre-training model of the encoder. The most famous representative is the Bert family . These models began to try the "unsupervised pre-training" method to make better use of large-scale natural language data that is easier to obtain than other data, and the "unsupervised" method is the Masked Language Model (MLM), through Let Mask drop some words in the sentence, and let the model learn the ability to use the context to predict the words dropped by Mask . Where Bert came out, it is also considered a bomb in the NLP field. At the same time, it has reached SOTA in many common tasks of natural language processing such as sentiment analysis and named entity recognition. The outstanding representatives of the Bert family are in addition to Bert and ALBert proposed by Google. In addition, there are Baidu's ERNIE, Meta's RoBERTa, Microsoft's DeBERTa and so on.

It is a pity that Bert's approach failed to break through Scale Law, and this is achieved by the main force of the current large-scale model, that is, another way of large-scale model development, by abandoning the Encoder part and based on the Decoder part of the GPT family . The success of the GPT family stems from the surprising discovery of a researcher: " Expanding the scale of the language model can significantly improve the ability of zero-shot and few-shot learning ", which is similar to the Bert family based on fine-tuning. There is a big difference, and it is also the source of the magical ability of the current large-scale language model. The GPT family is trained based on predicting the next word given the previous word sequence, so GPT initially appeared only as a text generation model, and the emergence of GPT-3 is a turning point in the fate of the GPT family. GPT-3 is the first It shows people the magical ability brought by large models beyond text generation itself, showing the superiority of these autoregressive language models. Starting from GPT-3, the current ChatGPT, GPT-4, Bard, PaLM, and LLaMA have flourished and contended, bringing the current prosperity of large models.

From merging the two branches of this family tree, we can see the early Word2Vec and FastText, and then to the early exploration of ELMo and ULFMiT in the pre-training model, and then to Bert’s smash hit, to the GPT family’s silent cultivation until GPT-3 is amazing On the stage, ChatGPT soared into the sky. In addition to the iteration of technology, we can also see that OpenAI silently insisted on its own technical path and finally became the undisputed leader of LLMs. We also saw Google’s major theoretical contributions to the entire Encoder-Decoder model architecture. , seeing Meta's continuous and generous participation in the open source business of large models, and of course seeing the trend of LLMs gradually tending to "closed" sources after GPT-3, it is very likely that most of the research in the future will have to become API-Based study .
Data - the power source of the big model
In the final analysis, does the magical ability of the large model come from GPT? I think the answer is no. Almost every capability leap of the GPT family has made important improvements in the quantity, quality, and diversity of pre-training data . The training data of the large model includes books, articles, website information, code information, etc. The purpose of inputting these data into the large model is to fully and accurately reflect the "human being". By telling the large model words, grammar, syntax and Semantic information allows models to gain the ability to recognize context and generate coherent responses to capture aspects of human knowledge, language, culture, and more.
Generally speaking, in the face of many NLP tasks, we can classify them into zero-sample, few-sample, and multi-sample from the perspective of data labeling information . Undoubtedly, zero-shot task LLMs are the most suitable method, and with few exceptions, large models far outperform other models on zero-shot tasks. At the same time, few-sample tasks are also very suitable for the application of large models. By displaying "question-answer" pairs for large models, the performance of large models can be enhanced. This method is generally called In-Context Learning. For multi-sample tasks, although large models can also be covered, fine-tuning may still be the best method. Of course, under some constraints such as privacy and computing, large models may still be useful.

At the same time, the fine-tuned model is likely to face the problem of changing the distribution of training data and test data. Significantly, the fine-tuned model generally performs very poorly on OOD data . Correspondingly, LLMs perform much better because they do not have an explicit fitting process. Typical ChatGPT reinforcement learning based on human feedback (RLHF) performs well in most out-of-distribution classification and translation tasks. It also performed well on DDXPlus, a medical diagnostic dataset designed for OOD evaluation.
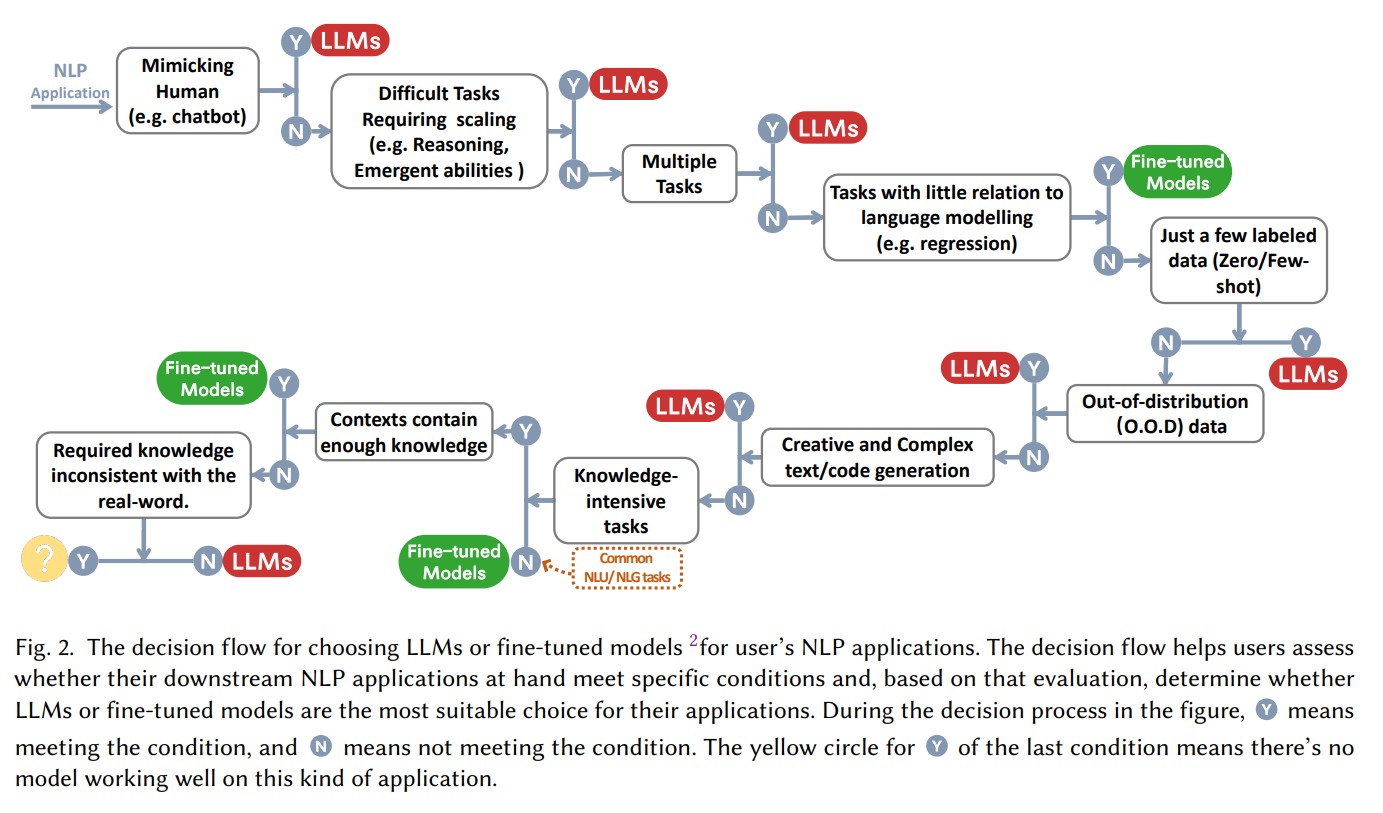
Practical Guide - Task-Oriented Getting Started Mockups
In many cases, "the big model is good!" This assertion is followed by the question of "how to use the big model and when?" When facing a specific task, should we choose to fine-tune or get started with the big model without thinking ? This paper summarizes a practical "decision flow", which helps us judge whether to use a large model based on a series of questions such as "whether it is necessary to imitate humans", "whether reasoning ability is required", "whether it is multi-tasking".
From the perspective of NLP task classification:
traditional natural language understanding
For many NLP tasks that currently have a large amount of rich labeled data, the fine-tuned model may still firmly control the advantage. In most data sets, LLMs are inferior to the fine-tuned model . Specifically:
- Text classification : In text classification, LLMs are generally inferior to fine-tuned models;
- Sentiment analysis : On IMDB and SST tasks, large models perform similarly to fine-tuned models, while in tasks such as toxicity monitoring, almost all large models are worse than fine-tuned models;
- Natural language reasoning : On RTE and SNLI, the fine-tuning model is better than LLMs, and in CB and other data, LLMs are similar to the fine-tuning model;
- Q&A : On SQuADv2, QuAC, and many other datasets, fine-tuned models have better performance, while on CoQA, LLMs perform similarly to fine-tuned models;
- Information retrieval : LLMs have not been widely used in the field of information retrieval, and the task characteristics of information retrieval make there is no natural way to model information retrieval tasks for large models;
- Named entity recognition : In named entity recognition, the large model is still significantly inferior to the fine-tuned model, and the performance of the fine-tuned model on CoNLL03 is almost twice that of the large model, but named entity recognition, as a classic NLP intermediate task, is very likely will be replaced by the larger model.
In summary, for most traditional natural language understanding tasks, fine-tuned models perform better. Of course, the potential of LLMs is limited by the Prompt project may not be fully released (in fact, the fine-tuning model has not reached the upper limit). At the same time, in some niche areas, such as Miscellaneous Text Classification, Adversarial NLI and other tasks, LLMs due to stronger The generalization ability thus has better performance, but for now, for data with mature labels, fine-tuning the model may still be the optimal solution for traditional tasks .
natural language generation
Compared with natural language understanding, natural language generation may be the stage for large models . The goal of natural language generation is mainly to create coherent, fluent, and meaningful sequences, which can usually be divided into two categories, one is the tasks represented by machine translation and paragraph information summarization, and the other is more open natural writing, Tasks like writing emails, writing news, creating stories, etc. in particular:
- Text summarization : For text summarization, if traditional automatic evaluation indicators such as ROUGE are used, LLMs do not show obvious advantages, but if human evaluation results are introduced, LLMs will perform significantly better than fine-tuning models. This actually shows that the current automatic evaluation indicators sometimes cannot fully and accurately reflect the effect of text generation;
- Machine translation : For machine translation, a task with mature commercial software, LLMs generally perform slightly worse than commercial translation tools, but in some unpopular language translations, LLMs sometimes show better results, such as in Romania In the task of translating English from Chinese to English, LLMs beat the SOTA of the fine-tuned model in the case of zero and few samples;
- Open generation : In terms of open generation, showing is what big models do best. News articles generated by LLMs are almost indistinguishable from real news written by humans. LLMs perform surprisingly well in areas such as code generation and code error correction. performance.
knowledge-intensive tasks
Knowledge-intensive tasks generally refer to tasks that strongly rely on background knowledge, domain-specific expertise, or general world knowledge. Knowledge-intensive tasks are different from simple pattern recognition and syntactic analysis, and require "common sense" of our real world and correct Use , specifically:
- Closed question answering : In the Closed-book Question-Answering task, the model is required to answer factual questions without external information. LLMs have shown better performance in many data sets such as NaturalQuestions, WebQuestions, TriviaQA, especially * *In TriviaQA, the zero-sample LLMs have shown better gender performance than the fine-tuning model;
- Large-scale multi-task language understanding : Large-scale multi-task language understanding (MMLU) contains 57 multiple-choice questions on different topics, and also requires the model to have general knowledge. The most impressive in this task is GPT -4, got 86.5% accuracy in MMLU.
It is worth noting that in knowledge-intensive tasks, the large model is not a hundred-and-a-half-hundred-hundred-hundred-hundred-hundredth Worse than random guessing . For example, in the task of redefining mathematics (Redefine Math), the model is required to choose between the original meaning and the redefined meaning. This requires the ability to learn the opposite of the knowledge learned by the large-scale language model. Therefore, the performance of LLMs is not even as good as random guess.
reasoning task
The expansion ability of LLMs can greatly enhance the ability of pre-trained language models. When the model scale increases exponentially, some key abilities such as reasoning will gradually be activated with the expansion of parameters. Visible is exceptionally powerful in tasks like:
- Arithmetic reasoning : It is no exaggeration to say that GPT-4's arithmetic and reasoning ability surpasses any previous model. Large models on GSM8k, SVAMP and AQuA have breakthrough capabilities. It is worth pointing out that through the chain of thinking ( CoT) can significantly enhance the computing power of LLMs;
- Common-sense reasoning : Common-sense reasoning requires large models to memorize factual information and perform multi-step reasoning. In most datasets, LLMs maintain an advantage over fine-tuned models, especially in ARC-C (difficult science exam questions for grades 3-9) , the performance of GPT-4 is close to 100% (96.3%).
In addition to reasoning, as the size of the model grows, the model will also have some Emergent Abilities, such as consistent operations, logical derivation, conceptual understanding, and so on . But there is also an interesting phenomenon called "U-shaped phenomenon", which refers to the phenomenon that as the scale of LLMs increases, the performance of the model first increases and then begins to decline. The typical representative is the problem of redefining mathematics mentioned above. Such phenomena call for more in-depth and detailed research on the principles of large models.
Summary - Challenges and Future of Large Models
Large models must be part of our work and life for a long time in the future, and for such a "big guy" that interacts with our lives at the same frequency, in addition to issues such as performance, efficiency, and cost, the security issues of large-scale language models are almost It is the most important of all the challenges faced by the large model . The machine hallucination is the main problem that the large model does not yet have an excellent solution. The biased or harmful illusion output by the large model will cause serious harm to the user. as a result of. At the same time, as the "credibility" of LLMs is getting higher and higher, users may over-rely on LLMs and believe that they can provide accurate information. This predictable trend increases the security risk of large models.
In addition to misleading information, due to the high quality and low cost of the text generated by LLMs, LLMs may be used as a tool for attacks such as hatred, discrimination, violence, rumors, etc. LLMs may also be attacked to provide illegal information or Stealing privacy , according to reports, Samsung employees accidentally leaked top-secret data such as the source code attributes of the latest program, internal meeting minutes related to hardware, etc. when using ChatGPT for work.
In addition, the key to whether large models can be applied to sensitive fields, such as healthcare, finance, law, etc., lies in the "credibility" of large models. At present, the robustness of large models with zero samples often appears reduce . Meanwhile, LLMs have been shown to be socially biased or discriminatory, with many studies observing significant performance differences across demographic categories such as accent, religion, gender, and race. This can lead to "fairness" issues with large models .
Finally, if we break away from social issues and make a summary, we also look forward to the future of large-scale model research. The main challenges that large-scale models currently face can be classified as follows:
- Practice verification : the current evaluation data sets for large models are often more "toy" academic data sets, but these academic data sets cannot fully reflect the various problems and challenges in the real world, so there is an urgent need for actual data sets to be diversified. , Evaluate the model on complex real-world problems to ensure that the model can cope with real-world challenges;
- Model alignment : The power of the large model also raises another issue. The model should be aligned with human value choices to ensure that the model behavior meets expectations and does not "enhance" bad results. As an advanced complex system, if this is not handled carefully This kind of moral problem may brew a disaster for mankind;
- Potential safety hazards : The research on large models should further emphasize safety issues and eliminate potential safety hazards. Specific research is required to ensure the safe development of large models, and more efforts are needed to do a good job in model interpretability, supervision and management. Security issues should be model development. An important part of the design, rather than a dispensable decoration for icing on the cake;
- The future of the model : The performance of the model will increase with the increase of the model size. This question is estimated to be difficult for OpenAI to answer. Our understanding of the miraculous phenomena of large models is still very limited, and the fundamental insights of large models are still very precious.
This article is published by mdnice multi-platform