Introduction
Why do you need a thread pool:
when doing high concurrency, the creation and destruction of threads are costly, so create the thread pool in advance, and then fetch it from the thread pool when you use it. 16 threads are a shared task
list Yes, mutual exclusion access must be done before adding tasks
1. Start the thread pool
In the mian() function, first create a thread pool object:
XThreadPool pool;
Call the initialization function init() of the thread, and pass the parameter n to init() to assign a value to the thread number member of the thread pool:
this->thread_num_ = num;
Use start() to start the thread, first judge whether the thread pool is initialized in run, and then judge whether the thread is started:
Then create thread_num_ threads, and the thread entry of each thread is run()
auto th = make_shared<thread>(&XThreadPool::Run, this);
threads_.push_back(th);
To point to the type of object, creating a new thread object requires an entry function. Since this function is a class member function, it also needs a this pointer. The return type is a pointer th, and then a thread list threads_ is used to manage this th:
std::vector< std::shared_ptr<std::thread> > threads_;
At this point the thread pool has started:
2. The thread pool starts to serve users
main() is followed by an infinite loop after starting the thread, interacting with the user on the terminal,
(1) call task_run_count() of the thread pool when L is input, and return the task count, the task count is +1 before the task run, and at the end Subtract 1,
(2) When inputting e, directly break to end the infinite loop
(3) When inputting v, start video transcoding: first use make_shared to create a task object, input video source, output size, save information, etc. Throw this information to the created task object, then throw this task into the thread pool, and use the thread pool to judge the start time of the task
//线程池线程的入口函数
void XThreadPool::Run()
{
cout << "begin XThreadPool Run " << this_thread::get_id() << endl;
while (!is_exit())
{
auto task = GetTask();
if (!task)continue;
++task_run_count_;
try
{
auto re = task->Run();
//task->SetValue(re);
}
catch (...)
{
}
--task_run_count_;
}
cout << "end XThreadPool Run " << this_thread::get_id() << endl;
}
Because a thread error cannot affect the operation of this thread pool, it is necessary to catch the exception
The threads in the thread pool have no tasks themselves, and each thread repeats three things in while()
(the first thing) to obtain the tasks in the task list tasks_ in the thread pool through GetTask():
unique_lock<mutex> lock(mux_);
if (tasks_.empty())
{
cv_.wait(lock);
}
if (is_exit())
return nullptr;
if (tasks_.empty())
return nullptr;
auto task = tasks_.front();
tasks_.pop_front();
return task;
Users may input a large number of tasks. If they do not use multi-threading, they can only process one task at a time. The efficiency is very low, and they do not want to create unlimited threads to process them. This may cause the system to crash, so the thread pool is used to specify that only 16 tasks can be processed at a time. Tasks , unprocessed tasks are queued in the task queue tasks_. When the task queue is empty, it will always be blocked at cv_.wati(lock), until the user enters the task at the terminal and passes cv.notify to run the following
(The second thing) Call the run() of the task just obtained, and combine the instructions entered by the user in the terminal into a command line capable of ffmpeg, for example:
ffmpeg -y -i test.mp4 -s 400x300 400. mp4 >log.txt 2>&1, and then use system() to directly make a system call:
int XVideoTask::Run()
{
//ffmpeg -y -i test.mp4 -s 400x300 400.mp4 >log.txt 2>&1
stringstream ss;
ss << "ffmpeg.exe -y -i " << in_path<<" ";
if (width > 0 && height > 0)
ss << " -s " << width << "x" << height<<" ";
ss << out_path;
ss << " >" << this_thread::get_id() << ".txt 2>&1";
return system(ss.str().c_str());
}
Third, the thread pool exits
When the input e exits, call stop() of the thread pool
/// 线程池退出
void XThreadPool::Stop()
{
is_exit_ = true;
cv_.notify_all();
for (auto& th : threads_)
{
th->join();
}
unique_lock<mutex> lock(mux_);
threads_.clear();
}
Note:
combined with the thread entry function to understand:
//线程池线程的入口函数
void XThreadPool::Run()
{
cout << "begin XThreadPool Run " << this_thread::get_id() << endl;
while (!is_exit())
{
auto task = GetTask();
if (!task)continue;
++task_run_count_;
try
{
auto re = task->Run();
//task->SetValue(re);
}
catch (...)
{
}
--task_run_count_;
}
}
01 Set is_exit_ = true; Let the run() of the thread stop the infinite loop
02 Why do you need cv_.notify_all();
If there is no such sentence, it will be stuck here when exiting:
even if there is no task coming in, there are 16 in the thread pool at this time A thread is running, and GetTask() is stuck in cv.wait(), waiting for cv to send him a signal. At this time, the thread will remain blocked, so it will be stuck here. 03 Why do all the threads join
( )
When a thread is joinable, calling the destructor will report an error (when it is joinable, even if it finishes running, the release of its thread resources needs other threads to complete through join())
Four, run
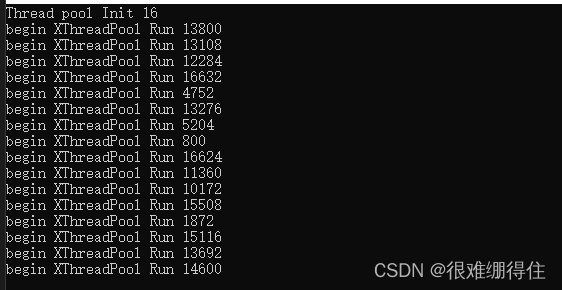
Start 16 threads first, followed by the thread number
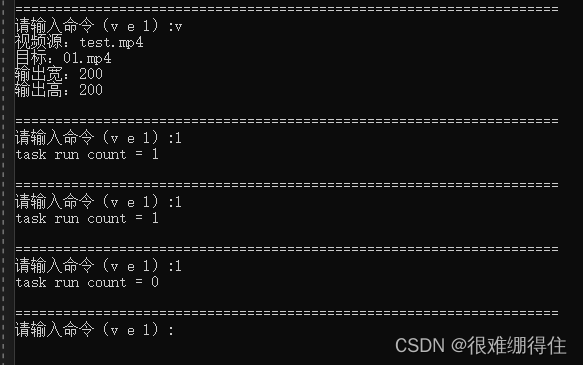
Enter a transcoding command, and then keep checking the number of currently running tasks, first it is 1, and after the operation is complete, it will display 0.
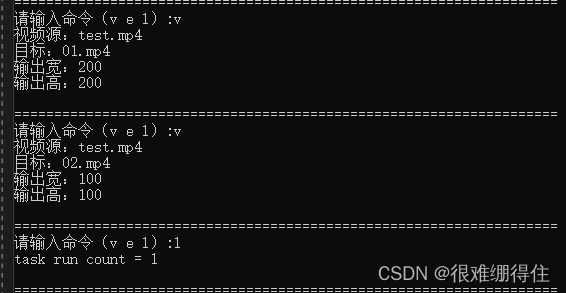
Because the test video is short and the hand speed is slow, the display is not good. out 2:
5. Points to note
(1) What did the stop() of the thread pool do:
1. First set the is_exit variable to true, so that the run of the thread in the thread pool no longer enters while()
2. Call cv_.notify_all(); let the thread pool The cv.wait() of the get_task of the thread skips
3. Let these join() in turn by managing the list of threads in the thread pool, waiting for them to exit (in fact, waiting for the release of these thread resources: such as the value in the register, every some space unique to each thread, etc.)
(2) Why std::vector< std::shared_ptr<std::thread> > threads_;it is used a list
of management threads: 1. The main purpose of managing threads is to join these threads in turn when exiting. You only need to traverse the list once and call join in turn. 2.
Use smart pointers to exit Sometimes without new
3. The method when creating the pointer value passed to the smart pointer list:
for (int i = 0; i < thread_num_; i++)
{
auto th = make_shared<thread>(&XThreadPool::Run, this);
//shared_ptr<thread>th(new thread(&XThreadPool::Run, this));
threads_.push_back(th);
}
Both make_shared and shared_ptr can be used, but there is a small difference:
the benefits of using make_shared instead of share_ptr x(new xxx()):
①Better performance: new to construct shared_ptr pointer, then the process of new is a memory allocation on the heap, and when constructing a shared_ptr object, since the reference count shared on the heap needs to be used, memory needs to be allocated on the heap again , that is, memory needs to be allocated twice, and if you use the make_shared function, you only need to allocate memory once, and the performance will be much better.
②Safer: When shared_ptr is constructed, it includes two steps, (1) new a heap memory, (2) allocates a reference count area to manage the memory space, and does not guarantee the atomicity of these two steps, when the first (1) ) step, if the second step is not done, if the program throws an exception, it will cause a memory leak, so it is more recommended to use make_shared to allocate memory.
③ Disadvantages: make_shared's one-time allocation of heap memory may lead to delayed release of memory when it is released, because if there is a weak_ptr holding a pointer, the reference count will not be released, and the reference count and the actual object are allocated in the same heap Memory, so the object cannot be released. If the two pieces of memory are applied separately, the problem of delayed release does not exist.
Summary:
Therefore, make_shared and the traditional shared_ptr construction have their own advantages and disadvantages. Usually, it is recommended to use make_shared because it is more efficient and safe. When it is sensitive to memory release, the ordinary shared_ptr construction should be used.
Original link: https://blog.csdn.net/XiaoH0_0/article/details/101791274
4...Is it possible to use std::vector< std::unique_ptrstd::thread > threads_;
The answer is yes, first look at the direct modification to uniq_ptr:
for (int i = 0; i < thread_num_; i++)
{
//auto th = new thread(&XThreadPool::Run, this);
//auto th = make_shared<thread>(&XThreadPool::Run, this);
//shared_ptr<thread>th(new thread(&XThreadPool::Run, this));
unique_ptr<thread>th(new thread(&XThreadPool::Run, this));
//threads_.push_back(move(th));
threads_.push_back(th);
}

The reason for the error is that unique_ptr is an improvement of auto_ptr. When auto_ptr transfers the ownership of the object, the space of the original ptr may be accessed and cause a runtime error. Unique_ptr improves this shortcoming. At compile time, the operation of transferring the ownership of the object is considered to be illegal (compile phase error is safer than a potential program crash), while the transfer of the object will be called when inserting it into threads_, and an error will be reported
If you want to use unique_ptr, you need to use move() to turn it into an rvalue (the benefit of move is not that programmers can write code that uses rvalue references, but library code that can use rvalue references to implement move semantics) :
for (int i = 0; i < thread_num_; i++)
{
//auto th = new thread(&XThreadPool::Run, this);
//auto th = make_shared<thread>(&XThreadPool::Run, this);
//shared_ptr<thread>th(new thread(&XThreadPool::Run, this));
unique_ptr<thread>th(new thread(&XThreadPool::Run, this));
//threads_.push_back(move(th));
threads_.push_back(move(th));
}
The role of rvalue references:
Suppose there is a class data, which has a pointer member pt, which overloads +, and can add the data pointed to by pt of data1 to the data pointed to by pt of data2, and then the pt of the new object Pointing to the added data, if two data objects are added together as a parameter of the copy constructor (create data3), the overloaded + will be called first to obtain an object, and then the copy constructor will be called, which is a waste of memory, so the The concept of move semantics is introduced , let the object pointed to by the pt of the object created by + stay in the original place, and the pt of data3 points to the data of the pt of this object.
To achieve move semantics, let the compiler know when to call copy construction and when not to, and this is where rvalue references come into play.
Move constructor using move semantics:
data(data&&d)
{ pt=d.pt; d.pt=nullptr; } When data data3(data1+data2) is called again, since data1+data2 is an rvalue, the move constructor will be called directly Instead of a copy constructor, saving memory.
5. Why do you need to unlock first and then notify
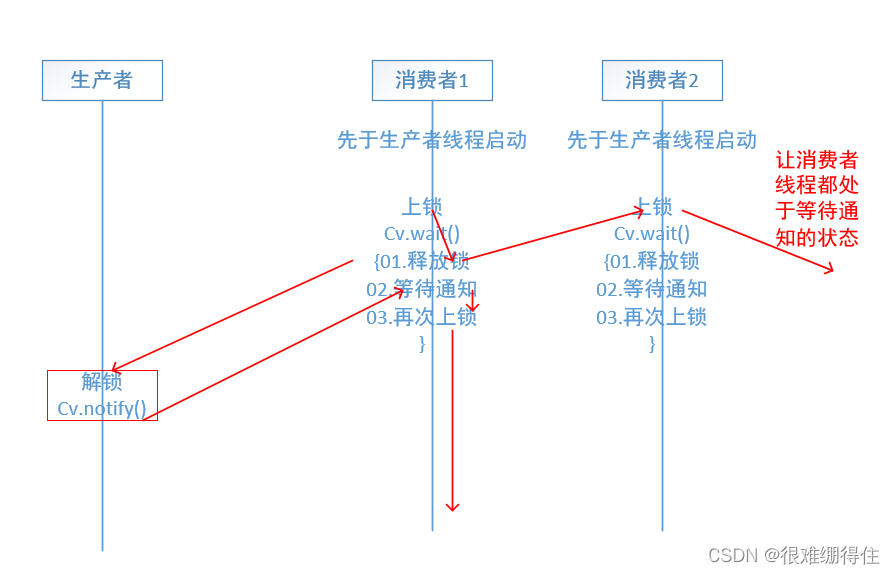
It is also possible to notify first and then unlock, but relatively speaking, it will waste time and efficiency. This is because the consumer thread is started first, and all consumer threads are stuck in the wait place waiting for the producer thread to issue a notification, waiting for a certain consumer thread The next step after receiving the notification is to lock. If you notify first and then unlock, the consumer thread may have to try to acquire the lock multiple times, which will waste some resources.
6. Why get_task needs to judge whether the queue is empty twice:
unique_lock<mutex> lock(mux_);
if (tasks_.empty())
{
cv_.wait(lock);
}
if (is_exit())
return nullptr;
if (tasks_.empty())
return nullptr;
auto task = tasks_.front();
tasks_.pop_front();
return task;
This is a common double-checked locking pattern, and it is also used in the thread-safe lazy pattern in the singleton pattern.
The first judgment is for performance issues. If the task queue is not empty, there is no need to try to lock it. The second
judgment is for mutual exclusion access. When two threads with empty task queues enter here, they need to be mutually exclusive. denial of access