Table of contents
- 1 Environment preparation
- 2 Didi Operation Analysis
-
- 2.1 Requirements Description
- 2.2 Environment preparation
- 2.3 Data ETL storage
- 2.4 Index query analysis
-
- 2.4.1 Development steps
- 2.4.2 Loading Hudi table data
- 2.4.3 Indicator 1: Order Type Statistics
- 2.4.4 Indicator 2: Order Timeliness Statistics
- 2.4.5 Indicator 3: Order Traffic Type Statistics
- 2.4.6 Indicator 4: Order Price Statistics
- 2.4.7 Indicator 5: Order Distance Statistics
- 2.4.8 Indicator 6: Weekly order statistics
- 2.5 Integrated Hive query
- 3 Write structured stream to Hudi
- 4 Integrating SparkSQL
1 Environment preparation

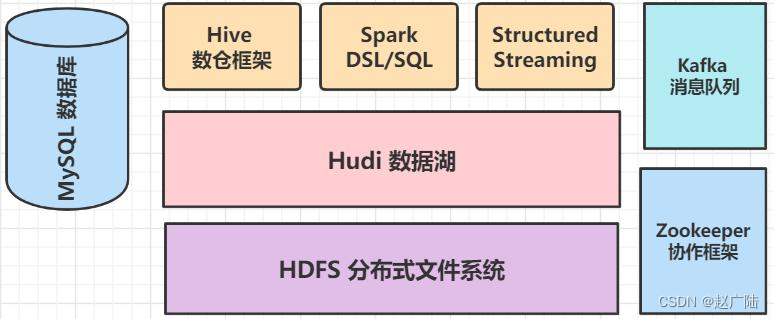
Hudi data lake framework, started to integrate with Spark analysis engine framework, save data to Hudi table through Spark, use Spark to load Hudi table data for analysis, not only support batch processing and flow computing, but also integrate Hive for data analysis, install big data and others Framework: MySQL, Hive, Zookeeper and Kafka, which is convenient for case integration and integration.
1.1 Install MySQL 5.7.31
Use tar to install the MySQL database. The specific commands and related instructions are as follows
1. 检查系统是否安装过mysql
rpm -qa|grep mysql
2. 卸载CentOS7系统自带mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs.xxxxxxx
3. 删除etc目录下的my.cnf ,一定要删掉,等下再重新建
rm /etc/my.cnf
4. 创建mysql 用户组和用户
groupadd mysql
useradd -r -g mysql mysql
5. 下载安装,从官网安装下载,位置在/usr/local/
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
6. 解压安装mysql
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local/
mv mysql-5.7.31-linux-glibc2.12-x86_64 mysql
7. 进入mysql/bin/目录,编译安装并初始化mysql,务必记住数据库管理员临时密码
cd mysql/bin/
./mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql
8. 编写配置文件 my.cnf ,并添加配置
vi /etc/my.cnf
[mysqld]
datadir=/usr/local/mysql/data
port = 3306
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
symbolic-links=0
max_connections=400
innodb_file_per_table=1
lower_case_table_names=1
9. 启动mysql 服务器
/usr/local/mysql/support-files/mysql.server start
10. 添加软连接,并重启mysql 服务
ln -s /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
service mysql restart
11. 登录mysql ,密码就是初始化时生成的临时密码 X_j&N*wy1q7<
mysql -u root -p
12、修改密码,因为生成的初始化密码难记
set password for root@localhost = password('123456');
13、开放远程连接
use mysql;
update user set user.Host='%' where user.User='root';
flush privileges;
14. 设置开机自启
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
Finally, use the MySQL database client to remotely connect to the database to test whether it is successful.
1.2 Install Hive 2.1
Directly decompress the Hive framework tar package, configure HDFS dependencies and metadata storage MySQL database information, and finally start the metadata service Hive MetaStore and HiveServer2 services.
1. 上传,解压
[root@node1 ~]# cd /export/software/
[root@node1 server]# rz
[root@node1 server]# chmod u+x apache-hive-2.1.0-bin.tar.gz
[root@node1 server]# tar -zxf apache-hive-2.1.0-bin.tar.gz -C /export/server
[root@node1 server]# cd /export/server
[root@node1 server]# mv apache-hive-2.1.0-bin hive-2.1.0-bin
[root@node1 server]# ln -s hive-2.1.0-bin hive
2. 配置环境变量
[root@node1 server]# cd hive/conf/
[root@node1 conf]# mv hive-env.sh.template hive-env.sh
[root@node1 conf]# vim hive-env.sh
HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
3. 创建HDFS目录
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
[root@node1 ~]# hdfs dfs -mkdir -p /tmp
[root@node1 ~]# hdfs dfs -mkdir -p /usr/hive/warehouse
[root@node1 ~]# hdfs dfs -chmod g+w /tmp
[root@node1 ~]# hdfs dfs -chmod g+w /usr/hive/warehouse
4. 配置文件hive-site.xml
[root@node1 ~]# cd /export/server/hive/conf
[root@node1 conf]# vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1.oldlu.cn:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.oldlu.cn:9083</value>
</property>
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>123456</value>
</property>
</configuration>
5. 添加用户权限配置
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop
[root@node1 hadoop] vim core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
6. 初始化数据库
[root@node1 ~]# cd /export/server/hive/lib
[root@node1 lib]# rz
mysql-connector-java-5.1.48.jar
[root@node1 ~]# cd /export/server/hive/bin
[root@node1 bin]# ./schematool -dbType mysql -initSchema
7. 启动HiveMetaStore服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# nohup bin/hive --service metastore >/dev/null &
8. 启动HiveServer2服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/hive --service hiveserver2 >/dev/null &
9. 启动beeline命令行
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/beeline -u jdbc:hive2://node1.oldlu.cn:10000 -n root -p 123456
After the service starts successfully, use the beeline client to connect, create databases and tables, import data and query tests.
1.3 Install Zookeeper 3.4.6
Upload Zookeeper software to the installation directory, decompress and configure the environment, the command is as follows:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software]# rz
zookeeper-3.4.6.tar.gz
给以执行权限
[root@node1 software]# chmod u+x zookeeper-3.4.6.tar.gz
解压tar包
[root@node1 software]# tar -zxf zookeeper-3.4.6.tar.gz -C /export/server
创建软链接
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s zookeeper-3.4.6 zookeeper
配置zookeeper
[root@node1 ~]# cd /export/server/zookeeper/conf
[root@node1 conf]# mv zoo_sample.cfg zoo.cfg
[root@node1 conf]# vim zoo.cfg
修改内容:
dataDir=/export/server/zookeeper/datas
[root@node1 conf]# mkdir -p /export/server/zookeeper/datas
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@node1 ~]# source /etc/profile
Start the Zookeeper service and check the status. The command is as follows:
启动服务
[root@node1 ~]# cd /export/server/zookeeper/
[root@node1 zookeeper]# bin/zkServer.sh start
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Mode: standalone
1.4 Install Kafka 2.4.1
Upload the Kafka software to the installation directory, decompress and configure the environment, the command is as follows:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software~]# rz
kafka_2.12-2.4.1.tgz
[root@node1 software]# chmod u+x kafka_2.12-2.4.1.tgz
解压tar包
[root@node1 software]# tar -zxf kafka_2.12-2.4.1.tgz -C /export/server
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s kafka_2.12-2.4.1 kafka
配置kafka
[root@node1 ~]# cd /export/server/kafka/config
[root@node1 conf]# vim server.properties
修改内容:
listeners=PLAINTEXT://node1.oldlu.cn:9092 log.dirs=/export/server/kafka/kafka-logs
zookeeper.connect=node1.oldlu.cn:2181/kafka
创建存储目录
[root@node1 ~]# mkdir -p /export/server/kafka/kafka-logs
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export KAFKA_HOME=/export/server/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@node1 ~]# source /etc/profile
Start the Kafka service and check the status. The command is as follows:
启动服务
[root@node1 ~]# cd /export/server/kafka
[root@node1 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
[root@node1 kafka]# jps
2188 QuorumPeerMain
2639 Kafka
2 Didi Operation Analysis
The emergence of Internet car-hailing platforms led by Didi has not only reconstructed the offline car-hailing market, but also provided more profit possibilities for other idle resources in the market. Since the merger with Kuaidi and the acquisition of Uber China, Didi has firmly occupied the No. 1 position in the domestic travel market. While developing rapidly, it also continues to provide diversified services to users and continuously optimizes the resource allocation of social car travel. question. This sample is a random selection of Didi order data in Haikou City from May to October 2017, with a total of 14,160,162 orders.
Haikou is a big tourist city in the south. Didi has a long history of business development here and has accumulated a large amount of business order data. Here, we use its order data for the second half of 2017 to do some simple statistical analysis. Didi’s business development in Haikou during that period and tried to reveal some of the travel characteristics of Haikou users.
■ Express travel is the mainstream order type in Didi's operation process;
■ Among Didi Chuxing orders, reservation car market share is very low, and real-time reservations are still the main ones;
■ Pick-up and drop-off orders only account for 4% of the total order volume;
■ The distance of most orders is concentrated in 0-15 kilometers, and the price is concentrated in 0-100 yuan;
During weekdays, residents' demand for online car-hailing travel decreases, but it is relatively strong on weekends;

2.1 Requirements Description
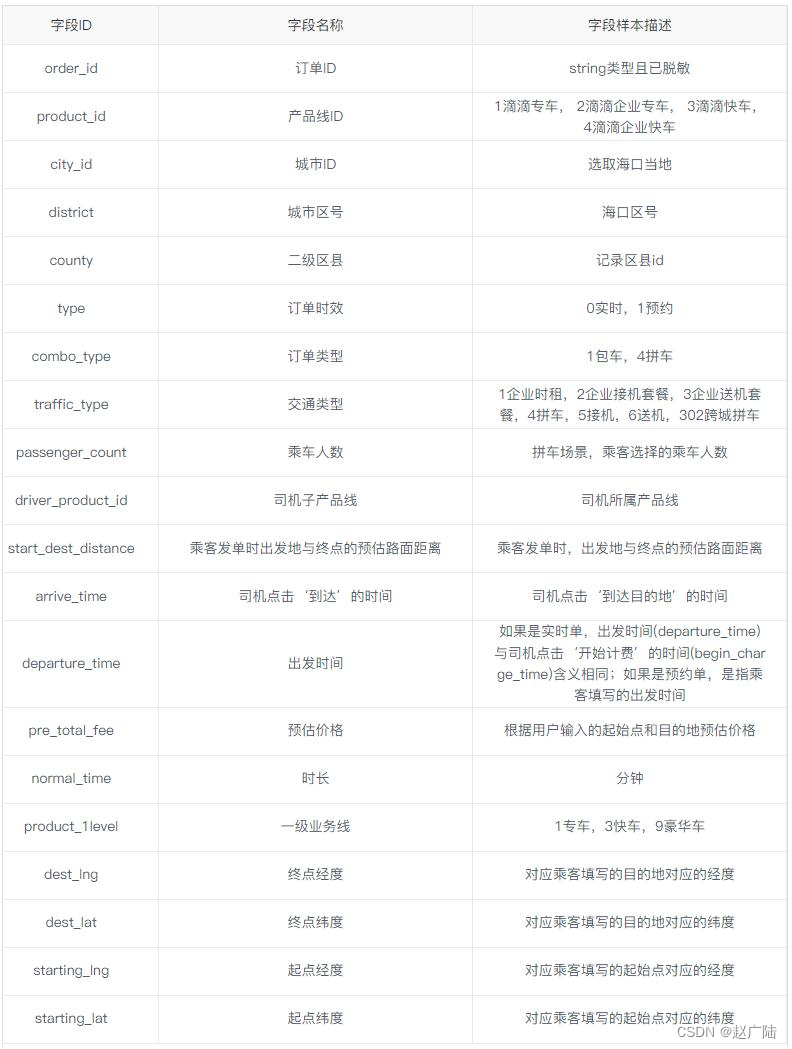
The data of Didi Chuxing is the daily order data of Haikou City from May 1st to October 31st, 2017 (half a year), including the latitude and longitude of the start and end points of the order, as well as order attribute data such as order type, travel category, and number of passengers. The meanings of the specific fields are as follows:
According to the data of Didi Chuxing in Haikou, statistical analysis is performed according to the following requirements:

2.2 Environment preparation
Based on the previous Maven Project, create relevant directories and packages. The structure is shown in the following figure:
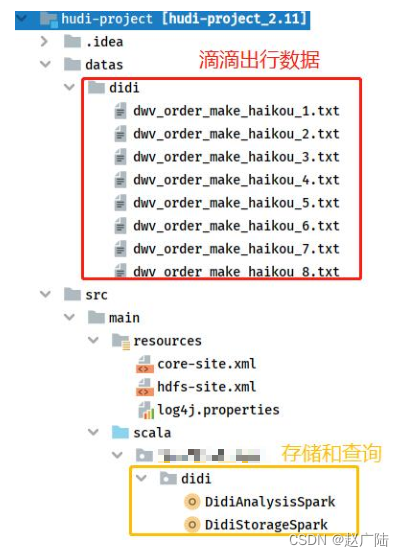
Among them, Didi Chuxing data is placed in the Maven Project project [datas] under the local file system directory. For Didi Chuxing analysis, the program is divided into two parts: data storage Hudi table [DidiStorageSpark] and indicator calculation statistical analysis [DidiAnalysisSpark].
2.2.1 Tool class SparkUtils
Regardless of data ETL saving or data loading statistics, it is necessary to create a SparkSession instance object, so write the tool class SparkUtils, and create a method [createSparkSession] to build an instance. The code is as follows:
package cn.oldlu.hudi.didi
import org.apache.spark.sql.SparkSession
/**
* SparkSQL操作数据(加载读取和保存写入)时工具类,比如获取SparkSession实例对象等
*/
object SparkUtils {
/**
* 构建SparkSession实例对象,默认情况下本地模式运行
*/
def createSparkSession(clazz: Class[_],
master: String = "local[4]", partitions: Int = 4): SparkSession = {
SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.master(master)
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.shuffle.partitions", partitions)
.getOrCreate()
}
}
2.2.2 Date conversion week
In the query analysis index, the value of the date and time field needs to be converted to the week, so as to facilitate the statistics of Didi trips on working days and rest days. The test code is as follows, and the date and time string is passed and converted to the week.
package cn.oldlu.hudi.test
import java.util.{
Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
/**
* 将日期转换星期,例如输入:2021-06-24 -> 星期四
* https://www.cnblogs.com/syfw/p/14370793.html
*/
object DayWeekTest {
def main(args: Array[String]): Unit = {
val dateStr: String = "2021-06-24"
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd")
val calendar: Calendar = Calendar.getInstance()
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek: String = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
println(dayWeek)
}
}
Analyze and write the code, load the Didi Chuxing data into the local file system, store it in the Hudi table, and finally analyze it according to the indicators.
2.3 Data ETL storage
Load Didi Chuxing data in Haikou City from the local file system LocalFS, perform corresponding ETL conversion, and finally store the Hudi table.
2.3.1 Development steps
Write a SparkSQL program to realize data ETL conversion and storage, which is divided into the following 5 steps:
■step1. 构建SparkSession实例对象(集成Hudi和HDFS)
■step2. 加载本地CSV文件格式滴滴出行数据
■step3. 滴滴出行数据ETL处理
■stpe4. 保存转换后数据至Hudi表
■step5. 应用结束关闭资源
数据ETL转换保存程序:DidiStorageSpark,其中MAIN方法代码如下:
package cn.oldlu.hudi.didi
import org.apache.spark.sql.{
DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用 SparkSQL 操作数据,先读取 CSV 文件,保存至 Hudi 表。
* -1. 数据集说明
* 2017 年 5 月 1 日 -10 月 31 日海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的
订单属性数据。
* 数据存储为 CSV 格式,首行为列名称
* -2. 开发主要步骤* step1. 构建 SparkSession 实例对象(集成 Hudi 和 HDFS )
* step2. 加载本地 CSV 文件格式滴滴出行数据
* step3. 滴滴出行数据 ETL 处理
* stpe4. 保存转换后数据至 Hudi 表
* step5. 应用结束关闭资源
*/
object DidiStorageSpark {
// 滴滴数据路径
val datasPath: String = "datas/didi/dwv_order_make_haikou_2.txt"
// Hudi中表的属性
val hudiTableName: String = "tbl_didi_haikou"
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit = {
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass)
import spark.implicits._
// step2. 加载本地CSV文件格式滴滴出行数据
val didiDF: DataFrame = readCsvFile(spark, datasPath)
// didiDF.printSchema()
// didiDF.show(10, truncate = false)
// step3. 滴滴出行数据ETL处理并保存至Hudi表
val etlDF: DataFrame = process(didiDF)
//etlDF.printSchema()
//etlDF.show(10, truncate = false)
// stpe4. 保存转换后数据至Hudi表
saveToHudi(etlDF, hudiTableName, hudiTablePath)
// stpe5. 应用结束,关闭资源
spark.stop()
}
Implement three methods in MAIN respectively: load csv data, data etl conversion and save data.
2.3.2 Load CSV data
The writing method encapsulates SparkSQL to load Didi travel data in CSV format. The specific code is as follows:
/**
* 读取CSV格式文本文件数据,封装到DataFrame数据集
*/
def readCsvFile(spark: SparkSession, path: String): DataFrame = {
spark.read
// 设置分隔符为逗号
.option("sep", "\\t")
// 文件首行为列名称
.option("header", "true")
// 依据数值自动推断数据类型
.option("inferSchema", "true")
// 指定文件路径
.csv(path)
}
2.3.3 Data ETL Transformation
The writing method is to add fields [ts] and [partitionpath] to the ETL conversion of Didi Chuxing data, so as to specify the field name when saving the data to the Hudi table. The specific code is as follows:
/**
* 对滴滴出行海口数据进行ETL转换操作:指定ts和partitionpath 列
*/
def process(dataframe: DataFrame): DataFrame = {
dataframe
// 添加分区列:三级分区 -> yyyy/MM/dd
.withColumn(
"partitionpath", // 列名称
concat_ws("/", col("year"), col("month"), col("day")) //
)
// 删除列:year, month, day
.drop("year", "month", "day")
// 添加timestamp列,作为Hudi表记录数据与合并时字段,使用发车时间
.withColumn(
"ts",
unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")
)
}
2.3.4 Save data to Hudi
Write the method to save the data after ETL conversion to the Hudi table, using the COW mode, the specific code is as follows:
/**
* 将数据集DataFrame保存值Hudi表中,表的类型:COW
*/
def saveToHudi(dataframe: DataFrame, table: String, path: String): Unit = {
// 导入包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
// 保存数据
dataframe.write
.mode(SaveMode.Overwrite)
.format("hudi") // 指定数据源为Hudi
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性设置
.option(RECORDKEY_FIELD_OPT_KEY, "order_id")
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
// 表的名称和路径
.option(TABLE_NAME, table)
.save(path)
}
2.3.5 Hudi table storage structure
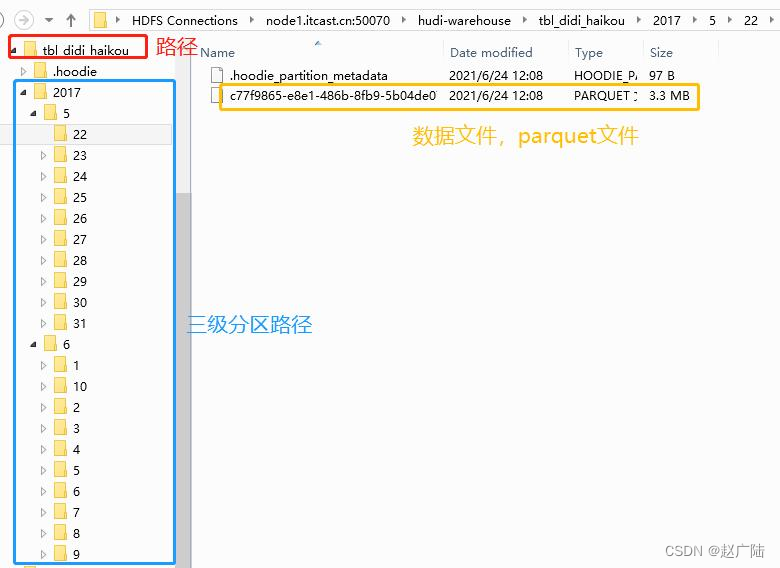
Run the Spark program, read the CSV format data, save it to the Hudi table after ETL conversion, and view the HDFS directory structure as follows:
2.4 Index query analysis
According to the query analysis indicators, load data from the Hudi table, perform group aggregation statistics, analyze the results, and give conclusions.

2.4.1 Development steps
Create the object DidiAnalysisSpark, write the MAIN method, first load data from the Hudi table, and then group and aggregate according to the indicators.
package cn.oldlu.hudi.didi
import java.util.{
Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{
DataFrame, SparkSession}
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用SparkSQL操作数据,从加载Hudi表数据,按照业务需求统计。
* -1. 数据集说明
* 海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。
* 数据存储为CSV格式,首行为列名称
* -2. 开发主要步骤
* step1. 构建SparkSession实例对象(集成Hudi和HDFS)
* step2. 依据指定字段从Hudi表中加载数据
* step3. 按照业务指标进行数据统计分析
* step4. 应用结束关闭资源
*/
object DidiAnalysisSpark {
// Hudi中表的属性
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit = {
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass, partitions = 8)
import spark.implicits._
// step2. 依据指定字段从Hudi表中加载数据
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
// step3. 按照业务指标进行数据统计分析
// 指标1:订单类型统计
// reportProduct(hudiDF)
// 指标2:订单时效统计
// reportType(hudiDF)
// 指标3:交通类型统计
//reportTraffic(hudiDF)
// 指标4:订单价格统计
//reportPrice(hudiDF)
// 指标5:订单距离统计
//reportDistance(hudiDF)
// 指标6:日期类型:星期,进行统计
//reportWeek(hudiDF)
// step4. 应用结束关闭资源
spark.stop()
}
Among them, the Hudi table data and various indicator statistics will be loaded, and they will be encapsulated into different methods for easy testing.
2.4.2 Loading Hudi table data
Write a method to encapsulate SparkSQL to load data from the Hudi table, and filter the fields required for obtaining indicator statistics. The code is as follows:
/**
* 从Hudi表加载数据,指定数据存在路径
*/
def readFromHudi(spark: SparkSession, path: String): DataFrame = {
// a. 指定路径,加载数据,封装至DataFrame
val didiDF: DataFrame = spark.read.format("hudi").load({
path)
// b. 选择字段
didiDF
// 选择字段
.select(
"order_id", "product_id", "type", "traffic_type", //
"pre_total_fee", "start_dest_distance", "departure_time" //
)
}
2.4.3 Indicator 1: Order Type Statistics
For Didi Chuxing data in Haikou City, statistics are made according to order type, use field: product_id, median value [1 Didi special car, 2 Didi enterprise special car, 3 Didi express, 4 Didi enterprise express], encapsulation method: reportProduct, code as follows:
/**
* 订单类型统计,字段:product_id
*/
def reportProduct(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("product_id").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 1滴滴专车, 2滴滴企业专车, 3滴滴快车, 4滴滴企业快车
(productId: Int) => {
productId match {
case 1 => "滴滴专车"
case 2 => "滴滴企业专车"
case 3 => "滴滴快车"
case 4 => "滴滴企业快车"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("product_id")).as("order_type"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
Using the histogram to display the statistical results, it can be seen that Kuaiche Chuxing is the mainstream order type in the operation of Didi in Haikou City in 2017.
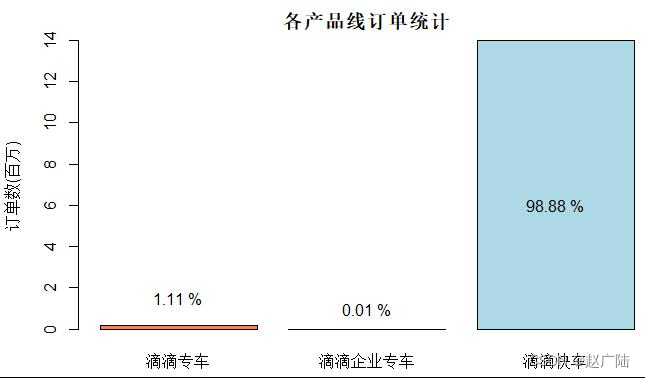
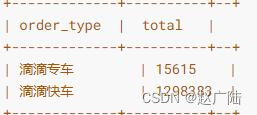
According to the Didi order data provided by the statistical sample, almost all the orders come from the Didi Express product line, and Didi’s special car only accounts for a small part of the order volume, compared with the order volume of the enterprise special car product line. Insignificant. Didi Express, as Didi’s traditional signature business, is the pillar of Didi. As for Didi Zhuanche, which was launched at the end of 2014 (later renamed "Licheng Zhuanche" in 2018), judging from the data in 2017, at least in Haikou City, the usage rate is not too high. This is also understandable. After all, the target audience of Didi Zhuanche is a smaller high-end business travel group. It aims to provide high-quality services for business travel. Compared with Didi Express, its higher price cannot become a general public. The public's first choice.
2.4.4 Indicator 2: Order Timeliness Statistics
According to the timeliness type of the user's order: type, group aggregation statistics, the code is as follows:
/**
* 订单时效性统计,字段:type
*/
def reportType(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 0实时,1预约
(realtimeType: Int) => {
realtimeType match {
case 0 => "实时"
case 1 => "预约"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("type")).as("order_realtime"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
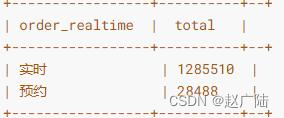
Using the histogram to display the results, it can be seen that among the orders of Didi Chuxing in Haikou City in 2017, the market share of reserved cars is extremely low, and real-time reservations are still the main ones.
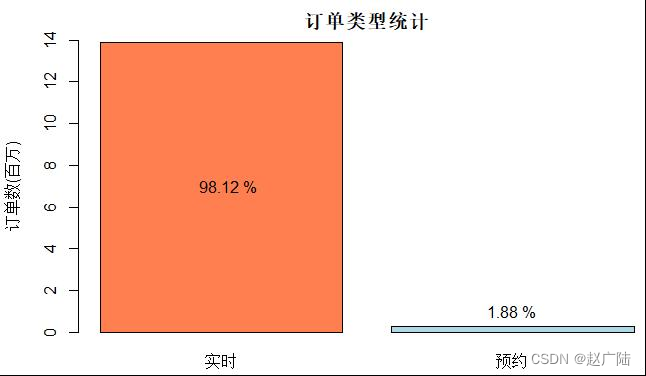
According to the Didi order data provided by the statistical sample, although Didi has already launched the car reservation business, the real-time demand is still the situation of most car orders, but this does not mean that the reservation car has no value. For consumers, real-time car use has higher flexibility, but car reservation provides the option of pre-arrangement to avoid being unable to get a car under special circumstances, allowing consumers to integrate car travel into their daily schedule .
2.4.5 Indicator 3: Order Traffic Type Statistics
For Didi travel data in Haikou City, according to the traffic type: traffic_type, aggregate statistics by group, the code is as follows:
/**
* 交通类型统计,字段:traffic_type
*/
def reportTraffic(dataframe: DataFrame): Unit = {
// a. 按照产品线ID分组统计
val reportDF: DataFrame = dataframe.groupBy("traffic_type").count()
// b. 自定义UDF函数,转换名称
val to_name = udf(
// 1企业时租,2企业接机套餐,3企业送机套餐,4拼车,5接机,6送机,302跨城拼车
(trafficType: Int) => {
trafficType match {
case 0 => "普通散客"
case 1 => "企业时租"
case 2 => "企业接机套餐"
case 3 => "企业送机套餐"
case 4 => "拼车"
case 5 => "接机"
case 6 => "送机"
case 302 => "跨城拼车"
case _ => "未知"
}
}
)
// c. 转换名称,应用函数
val resultDF: DataFrame = reportDF.select(
to_name(col("traffic_type")).as("traffic_type"), //
col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
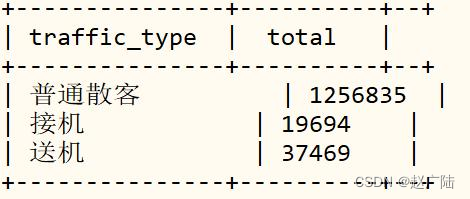
Using a histogram to display the results, it can be seen that pick-up and drop-off orders only account for 4% of the total order volume.
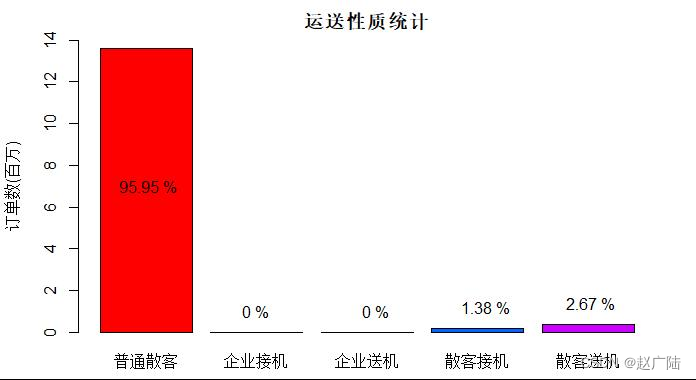
The connection of airport transportation is a potential market for Didi Chuxing. Among the orders recorded in the statistical sample, from May to November 2017, the pick-up and drop-off orders of individual passengers in Haikou City accounted for 4% of the total orders, about 56 million orders. However, there is no record of the corporate pick-up and drop-off business.
2.4.6 Indicator 4: Order Price Statistics
For the order data of Didi Chuxing, it is divided into different levels according to the price, and the statistics are grouped and aggregated. The code is as follows:
/**
* 订单价格统计,将价格分阶段统计,字段:pre_total_fee
*/
def reportPrice(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 价格:0 ~ 15
sum(
when(
col("pre_total_fee").between(0, 15), 1
).otherwise(0)
).as("0~15"),
// 价格:16 ~ 30
sum(
when(
col("pre_total_fee").between(16, 30), 1
).otherwise(0)
).as("16~30"),
// 价格:31 ~ 50
sum(
when(
col("pre_total_fee").between(31, 50), 1
).otherwise(0)
).as("31~50"),
// 价格:50 ~ 100
sum(
when(
col("pre_total_fee").between(51, 100), 1
).otherwise(0)
).as("51~100"),
// 价格:100+
sum(
when(
col("pre_total_fee").gt(100), 1
).otherwise(0)
).as("100+")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
Among them, the when conditional function and the sum accumulation function are used to skillfully perform conditional judgment and accumulation statistics. In addition, it can be seen from the results [the price is concentrated in 0-50 yuan].
2.4.7 Indicator 5: Order Distance Statistics
For the Didi Chuxing data, according to the travel distance of each order, divide different segment ranges, group aggregate statistics, the code is as follows:
/**
* 订单距离统计,将价格分阶段统计,字段:start_dest_distance
*/
def reportDistance(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// 价格:0 ~ 15
sum(
when(
col("start_dest_distance").between(0, 10000), 1
).otherwise(0)
).as("0~10km"),
// 价格:16 ~ 30
sum(
when(
col("start_dest_distance").between(10001, 20000), 1
).otherwise(0)
).as("10~20km"),
// 价格:31 ~ 50
sum(
when(
col("start_dest_distance").between(200001, 30000), 1
).otherwise(0)
).as("20~30km"),
// 价格:50 ~ 100
sum(
when(
col("start_dest_distance").between(30001, 5000), 1
).otherwise(0)
).as("30~50km"),
// 价格:100+
sum(
when(
col("start_dest_distance").gt(50000), 1
).otherwise(0)
).as("50+km")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
This indicator is similar to indicator four, using when conditional function and sum summation function for statistics.
2.4.8 Indicator 6: Weekly order statistics
Convert the date into a week, group and aggregate statistics, check the working day and rest, and drop out the situation, the code is as follows:
/**
* 订单星期分组统计,字段:departure_time
*/
def reportWeek(dataframe: DataFrame): Unit = {
// a. 自定义UDF函数,转换日期为星期
val to_week: UserDefinedFunction = udf(
// 0实时,1预约
(dateStr: String) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd")
val calendar: Calendar = Calendar.getInstance()
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek: String = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
}
// 返回星期
dayWeek
}
)
// b. 转换日期为星期,并分组和统计
val resultDF: DataFrame = dataframe
.select(
to_week(col("departure_time")).as("week")
)
.groupBy(col("week")).count()
.select(
col("week"), col("count").as("total") //
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
Looking at the results, it can be seen that 【during weekdays, Haikou residents' demand for taxi travel decreases, but it is relatively strong on weekends】.
2.5 Integrated Hive query
Previously, the Didi travel data was stored in the Hudi table, and SparkSQL was used to read the data, and then the Hive table data was integrated to read the data from the Hudi table.
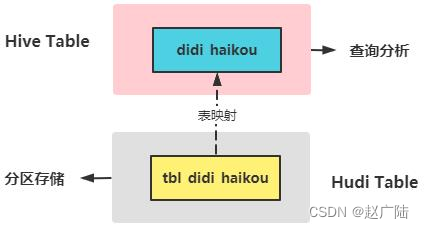
2.5.1 Create table and query
To create a table in Hive and associate it with the Hudi table, you need to put the integrated JAR package: hudi-hadoop-mr-bundle-0.9.0.jar into the $HIVE_HOME/lib directory.
[root@node1 ~]# cp hudi-hadoop-mr-bundle-0.9.0.jar /export/server/hive/lib/
Copying the dependency package to the Hive path is for Hive to read Hudi data normally, and the server environment is ready.
Earlier, Spark wrote Didi Chuxing data to the Hudi table. To access this data through Hive, you need to create a Hive external table. Because Hudi is configured with partitions, in order to be able to read all the data, the external table is also Score zone, zone field name can be freely configured
1. 创建数据库
create database db_hudi ;
2. 使用数据库
use db_hudi ;
3. 创建外部表
CREATE EXTERNAL TABLE tbl_hudi_didi(
order_id bigint ,
product_id int ,
city_id int ,
district int ,
county int ,
type int ,
combo_type int ,
traffic_type int ,
passenger_count int ,
driver_product_id int ,
start_dest_distance int ,
arrive_time string ,
departure_time string ,
pre_total_fee double ,
normal_time string ,
bubble_trace_id string ,
product_1level int ,
dest_lng double ,
dest_lat double ,
starting_lng double ,
starting_lat double ,
partitionpath string ,
ts bigint
)
PARTITIONED BY (
`yarn_str` string, `month_str` string, `day_str` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'/ehualu/hudi-warehouse/idea_didi_haikou' ;
5. 添加分区
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='22') location '/hudi-warehouse/tbl_didi_haikou/2017/5/22' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='23') location '/hudi-warehouse/tbl_didi_haikou/2017/5/23' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='24') location '/hudi-warehouse/tbl_didi_haikou/2017/5/24' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='25') location '/hudi-warehouse/tbl_didi_haikou/2017/5/25' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='26') location '/hudi-warehouse/tbl_didi_haikou/2017/5/26' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='27') location '/hudi-warehouse/tbl_didi_haikou/2017/5/27' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='28') location '/hudi-warehouse/tbl_didi_haikou/2017/5/28' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='29') location '/hudi-warehouse/tbl_didi_haikou/2017/5/29' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='30') location '/hudi-warehouse/tbl_didi_haikou/2017/5/30' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='5', day_str='31') location '/hudi-warehouse/tbl_didi_haikou/2017/5/31' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='1') location '/hudi-warehouse/tbl_didi_haikou/2017/6/1' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='2') location '/hudi-warehouse/tbl_didi_haikou/2017/6/2' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='3') location '/hudi-warehouse/tbl_didi_haikou/2017/6/3' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='4') location '/hudi-warehouse/tbl_didi_haikou/2017/6/4' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='5') location '/hudi-warehouse/tbl_didi_haikou/2017/6/5' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='6') location '/hudi-warehouse/tbl_didi_haikou/2017/6/6' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='7') location '/hudi-warehouse/tbl_didi_haikou/2017/6/7' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='8') location '/hudi-warehouse/tbl_didi_haikou/2017/6/8' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='9') location '/hudi-warehouse/tbl_didi_haikou/2017/6/9' ;
alter table db_hudi.tbl_hudi_didi add if not exists partition(yarn_str='2017', month_str='6', day_str='10') location '/hudi-warehouse/tbl_didi_haikou/2017/6/10' ;
查看分区信息
show partitions tbl_hudi_didi ;
After the above commands are executed, the data in the Hive table is successfully associated with the data in the Hudi table. You can write SQL statements in Hive to analyze the Hudi data, and use the SELECT statement to query the data in the table.
设置非严格模式
set hive.mapred.mode = nonstrict ;
SQL查询前10条数据
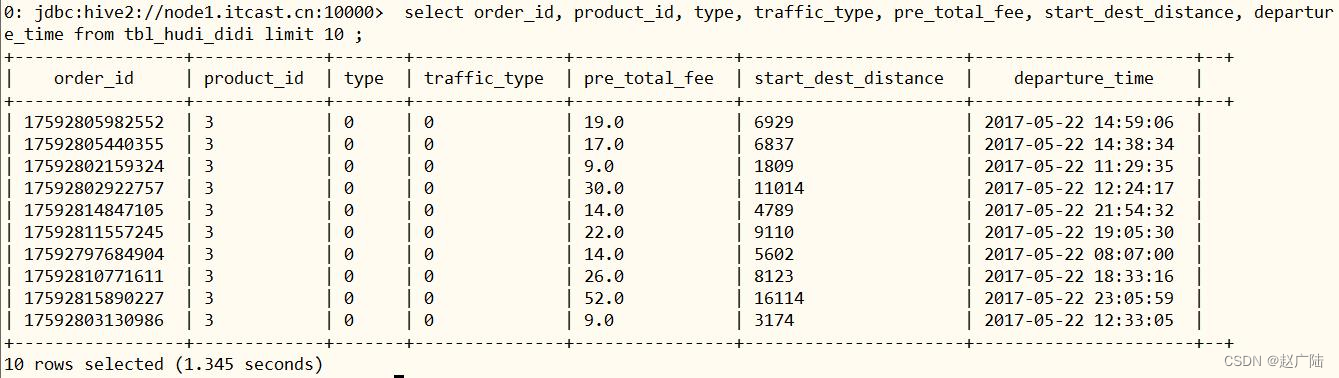
select order_id, product_id, type, traffic_type, pre_total_fee, start_dest_distance, departure_time
from db_hudi.tbl_hudi_didi limit 10 ;
The displayed results are as follows:
2.5.2 HiveQL Analysis
Write HiveQL statements in the Hive framework beeline command line, and perform statistical analysis on the indicators in Section 5.4 above.
设置Hive本地模式
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.tasks.max=10;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
12345
■Indicator 1: Order type statistics
WITH tmp AS (
SELECT product_id, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY product_id
)
SELECT
CASE product_id
WHEN 1 THEN "滴滴专车"
WHEN 2 THEN "滴滴企业专车"
WHEN 3 THEN "滴滴快车"
WHEN 4 THEN "滴滴企业快车"
END AS order_type,
total
FROM tmp ;
The analysis result (only a small part of Didi Chuxing data is imported to the Hudi table), as shown in the following figure:
■Indicator 2: Order Timeliness Statistics
WITH tmp AS (
SELECT type AS order_realtime, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY type
)
SELECT
CASE order_realtime
WHEN 0 THEN "实时"
WHEN 1 THEN "预约"
END AS order_realtime,
total
FROM tmp ;
The analysis result (only a small part of Didi Chuxing data is imported to the Hudi table), as shown in the following figure:
■Indicator 3: Order Traffic Type Statistics
WITH tmp AS (
SELECT traffic_type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY traffic_type
)
SELECT
CASE traffic_type
WHEN 0 THEN "普通散客"
WHEN 1 THEN "企业时租"
WHEN 2 THEN "企业接机套餐"
WHEN 3 THEN "企业送机套餐"
WHEN 4 THEN "拼车"
WHEN 5 THEN "接机"
WHEN 6 THEN "送机"
WHEN 302 THEN "跨城拼车"
ELSE "未知"
END AS traffic_type,
total
FROM tmp ;
The analysis result (only a small part of Didi Chuxing data is imported to the Hudi table), as shown in the following figure:
■Indicator 4: Order Price Statistics
SELECT
SUM(
CASE WHEN pre_total_fee BETWEEN 1 AND 15 THEN 1 ELSE 0 END
) AS 0_15,
SUM(
CASE WHEN pre_total_fee BETWEEN 16 AND 30 THEN 1 ELSE 0 END
) AS 16_30,
SUM(
CASE WHEN pre_total_fee BETWEEN 31 AND 50 THEN 1 ELSE 0 END
) AS 31_150,
SUM(
CASE WHEN pre_total_fee BETWEEN 51 AND 100 THEN 1 ELSE 0 END
) AS 51_100,
SUM(
CASE WHEN pre_total_fee > 100 THEN 1 ELSE 0 END
) AS 100_
FROM
db_hudi.tbl_hudi_didi;
The analysis result (only a small part of Didi Chuxing data is imported to the Hudi table), as shown in the following figure:

3 Write structured stream to Hudi
Integrate Spark Structured Streaming and Hudi, write streaming data into Hudi tables in real time, and use Spark DataSource to write data for each batch of data batch DataFrame.
Attribute parameter description: https://hudi.apache.org/docs/writing_data#datasource-writer
3.1 Simulated trading orders
Programming simulation generates transaction order data, and sends Kafka Topic in real time. For simplicity, the transaction order data fields are as follows, encapsulated into the sample class OrderRecord:
/**
* 订单实体类(Case Class)
*
* @param orderId 订单ID
* @param userId 用户ID
* @param orderTime 订单日期时间
* @param ip 下单IP地址
* @param orderMoney 订单金额
* @param orderStatus 订单状态
*/
case class OrderRecord(
orderId: String,
userId: String,
orderTime: String,
ip: String,
orderMoney: Double,
orderStatus: Int
)
Write a program [MockOrderProducer] to generate transaction order data in real time, use the Json4J class library to convert the data into JSON characters, and send it to Kafka Topic, the code is as follows:
import java.util.Properties
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{
KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
/**
* 模拟生产订单数据,发送到Kafka Topic中
* Topic中每条数据Message类型为String,以JSON格式数据发送
* 数据转换:
* 将Order类实例对象转换为JSON格式字符串数据(可以使用json4s类库)
*/
object MockOrderProducer {
def main(args: Array[String]): Unit = {
var producer: KafkaProducer[String, String] = null
try {
// 1. Kafka Client Producer 配置信息
val props = new Properties()
props.put("bootstrap.servers", "node1.oldlu.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 2. 创建KafkaProducer对象,传入配置信息
producer = new KafkaProducer[String, String](props)
// 随机数实例对象
val random: Random = new Random()
// 订单状态:订单打开 0,订单取消 1,订单关闭 2,订单完成 3
val allStatus = Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
while (true) {
// 每次循环 模拟产生的订单数目
val batchNumber: Int = random.nextInt(1) + 5
(1 to batchNumber).foreach {
number =>
val currentTime: Long = System.currentTimeMillis()
val orderId: String = s"${
getDate(currentTime)}%06d".format(number)
val userId: String = s"${
1 + random.nextInt(5)}%08d".format(random.nextInt(1000))
val orderTime: String = getDate(currentTime, format = "yyyy-MM-dd HH:mm:ss.SSS")
val orderMoney: String = s"${
5 + random.nextInt(500)}.%02d".format(random.nextInt(100))
val orderStatus: Int = allStatus(random.nextInt(allStatus.length))
// 3. 订单记录数据
val orderRecord: OrderRecord = OrderRecord(
orderId, userId, orderTime, getRandomIp, orderMoney.toDouble, orderStatus
)
// 转换为JSON格式数据
val orderJson = new Json(org.json4s.DefaultFormats).write(orderRecord)
println(orderJson)
// 4. 构建ProducerRecord对象
val record = new ProducerRecord[String, String]("order-topic", orderId, orderJson)
// 5. 发送数据:def send(messages: KeyedMessage[K,V]*), 将数据发送到Topic
producer.send(record)
}
Thread.sleep(random.nextInt(500))
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != producer) producer.close()
}
}
/** =================获取当前时间================= */
def getDate(time: Long, format: String = "yyyyMMddHHmmssSSS"): String = {
val fastFormat: FastDateFormat = FastDateFormat.getInstance(format)
val formatDate: String = fastFormat.format(time) // 格式化日期
formatDate
}
/** ================= 获取随机IP地址 ================= */
def getRandomIp: String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/** =================将Int类型IPv4地址转换为字符串类型================= */
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
Run the application to simulate the generation of transaction order data, after formatting:
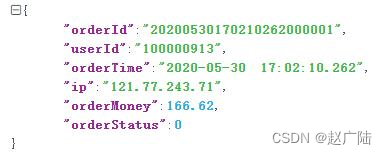
3.2 Streaming program development
Write a Structured Streaming Application: HudiStructuredDemo, consume JSON format data from Kafka's [order-topic] in real time, and store it in the Hudi table after ETL conversion.
package cn.oldlu.hudi.streaming
import org.apache.spark.internal.Logging
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
/**
* 基于StructuredStreaming结构化流实时从Kafka消费数据,经过ETL转换后,存储至Hudi表
*/
object HudiStructuredDemo extends Logging{
def main(args: Array[String]): Unit = {
// step1、构建SparkSession实例对象
val spark: SparkSession = createSparkSession(this.getClass)
// step2、从Kafka实时消费数据
val kafkaStreamDF: DataFrame = readFromKafka(spark, "order-topic")
// step3、提取数据,转换数据类型
val streamDF: DataFrame = process(kafkaStreamDF)
// step4、保存数据至Hudi表中:COW(写入时拷贝)和MOR(读取时保存)
saveToHudi(streamDF)
// step5、流式应用启动以后,等待终止
spark.streams.active.foreach(query => println(s"Query: ${
query.name} is Running ............."))
spark.streams.awaitAnyTermination()
}
/**
* 创建SparkSession会话实例对象,基本属性设置
*/
def createSparkSession(clazz: Class[_]): SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 设置属性:Shuffle时分区数和并行度
.config("spark.default.parallelism", 2)
.config("spark.sql.shuffle.partitions", 2)
.getOrCreate()
}
/**
* 指定Kafka Topic名称,实时消费数据
*/
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.oldlu.cn:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
/**
* 对Kafka获取数据,进行转换操作,获取所有字段的值,转换为String,以便保存Hudi表
*/
def process(streamDF: DataFrame): DataFrame = {
/* 从Kafka消费数据后,字段信息如
key -> binary,value -> binary
topic -> string, partition -> int, offset -> long
timestamp -> long, timestampType -> int
*/
streamDF
// 选择字段,转换类型为String
.selectExpr(
"CAST(key AS STRING) order_id", //
"CAST(value AS STRING) message", //
"topic", "partition", "offset", "timestamp"//
)
// 解析Message,提取字段内置
.withColumn("user_id", get_json_object(col("message"), "$.userId"))
.withColumn("order_time", get_json_object(col("message"), "$.orderTime"))
.withColumn("ip", get_json_object(col("message"), "$.ip"))
.withColumn("order_money", get_json_object(col("message"), "$.orderMoney"))
.withColumn("order_status", get_json_object(col("message"), "$.orderStatus"))
// 删除Message列
.drop(col("message"))
// 转换订单日期时间格式为Long类型,作为Hudi表中合并数据字段
.withColumn("ts", to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss.SSSS"))
// 订单日期时间提取分区日期:yyyyMMdd
.withColumn("day", substring(col("order_time"), 0, 10))
}
/**
* 将流式数据集DataFrame保存至Hudi表,分别表类型:COW和MOR
*/
def saveToHudi(streamDF: DataFrame): Unit = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-streaming")
// 针对每微批次数据保存
.foreachBatch((batchDF: Dataset[Row], batchId: Long) => {
println(s"============== BatchId: ${
batchId} start ==============")
writeHudiMor(batchDF) // TODO:表的类型MOR
})
.option("checkpointLocation", "/datas/hudi-spark/struct-ckpt-100")
.start()
}
/**
* 将数据集DataFrame保存到Hudi表中,表的类型:MOR(读取时合并)
*/
def writeHudiMor(dataframe: DataFrame): Unit = {
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
dataframe.write
.format("hudi")
.mode(SaveMode.Append)
// 表的名称
.option(TBL_NAME.key, "tbl_kafka_mor")
// 设置表的类型
.option(TABLE_TYPE.key(), "MERGE_ON_READ")
// 每条数据主键字段名称
.option(RECORDKEY_FIELD_NAME.key(), "order_id")
// 数据合并时,依据时间字段
.option(PRECOMBINE_FIELD_NAME.key(), "ts")
// 分区字段名称
.option(PARTITIONPATH_FIELD_NAME.key(), "day")
// 分区值对应目录格式,是否与Hive分区策略一致
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
// 插入数据,产生shuffle时,分区数目
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 表数据存储路径
.save("/hudi-warehouse/tbl_order_mor")
}
}
There are two details in the above code, which are critical for streaming applications:
1. When consuming data from Kafka, set the maximum amount of data per batch through the attribute [maxOffsetsPerTrigger]. The actual production project needs to combine the peak of streaming data and application running resources comprehensively consider the settings;
■ Second, save the data after ETL to Hudi, and set the checkpoint location Checkpoint Location, so that after the streaming application fails to run, it can recover from the Checkpoint, continue the last consumption data, and perform real-time processing ;
Run the above program to view the Hudi table storage transaction order data storage directory structure on HDFS:
3.3 Spark query analysis
Start the spark-shell command line and query the Hudi table to store transaction order data. The command is as follows:
/export/server/spark/bin/spark-shell --master local[2] --jars /root/hudi-jars/org.apache.hudi_hudi-spark3-bundle_2.12-0.9.0.jar,/root/hudi-jars/org.apache.spark_spark-avro_2.12-3.0.1.jar,/root/hudi-jars/org.spark-project.spark_unused-1.0.0.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
Specify the Hudi table data storage directory and load data:
val orderDF = spark.read.format("hudi").load("/ehualu/hudi-warehouse/tbl_order_mor")
View Schema information
orderDF.printSchema()

View the first 10 items of data in the order table, and select the relevant fields of the order:
orderDF.select("order_id", "user_id", "order_time", "ip", "order_money", "order_status", "day").show(false)

View the total number of data entries:
orderDF.count()
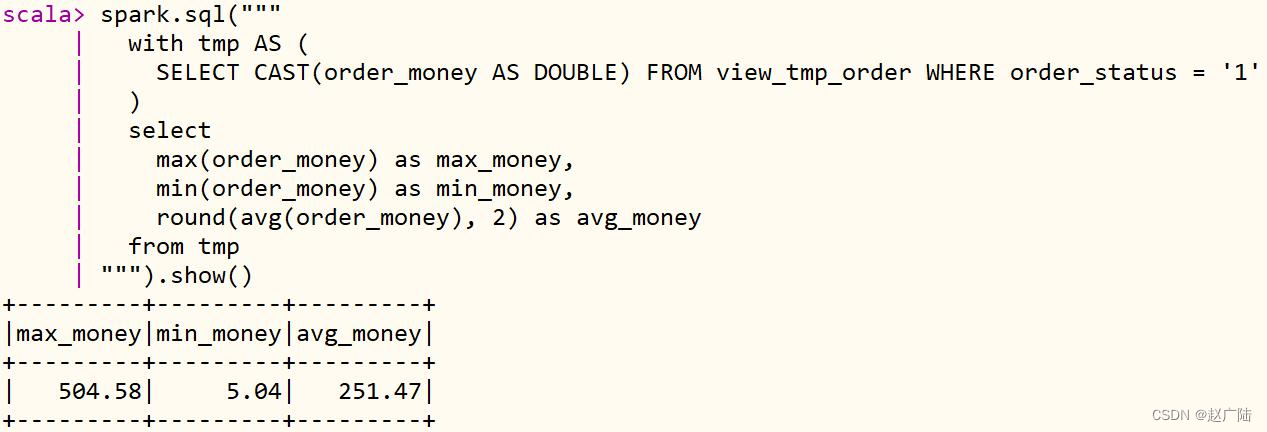
Basic aggregation statistics of transaction order data: maximum amount max, minimum amount min, average amount avg
spark.sql("""
with tmp AS (
SELECT CAST(order_money AS DOUBLE) FROM view_tmp_order WHERE order_status = '0'
)
select
max(order_money) as max_money,
min(order_money) as min_money,
round(avg(order_money), 2) as avg_money
from tmp
""").show()
3.4 DeltaStreamer tool class
The HoodieDeltaStreamer tool (part of hudi-utilities-bundle) provides a way to ingest from different sources such as DFS or Kafka, and has the following features: Single ingestion of new events from Kafka Support for json, avro or
custom
record types Incoming data
Manage checkpoints, rollback and recovery
Utilize the Avro mode of DFS or Confluent schema registry
Support custom conversion operation
tool class: HoodieDeltaStreamer, essentially run Spark streaming program, get data from real-time, store Ohudi In the table, execute the following command to view the help document:
spark-submit --master local[2] \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/root/hudi-utilities-bundle_2.11-0.9.0.jar \
--help
Note: The jar package where the tools are located [hudi-utilities-bundle_2.11-0.9.0.jar], add it to the CLASSPATH.
The official case is provided: real-time consumption of data in Kafka, the data format is Avro, and it is stored in the Hudi table.
4 Integrating SparkSQL
The latest version 0.9.0 of Hudi supports integration with SparkSQL, and directly writes SQL statements on the spark-sql interactive command line, which greatly facilitates users' DDL/DML operations on Hudi tables. Documentation: https://hudi.apache.org/docs/quick-start-guide
4.1 start spark-sql
Hudi table data is stored in the HDFS file system, first start the NameNode and DataNode services.
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
Start the spark-sql interactive command line, and set dependent jar packages and related property parameters.
/export/server/spark/bin/spark-sql --master local[2] --jars /root/hudi-jars/org.apache.hudi_hudi-spark3-bundle_2.12-0.9.0.jar,/root/hudi-jars/org.apache.spark_spark-avro_2.12-3.0.1.jar,/root/hudi-jars/org.spark-project.spark_unused-1.0.0.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Hudi's default upsert/insert/delete concurrency is 1500, and a smaller concurrency is set for the demonstration of small-scale data sets.
set hoodie.upsert.shuffle.parallelism = 1;
set hoodie.insert.shuffle.parallelism = 1;
set hoodie.delete.shuffle.parallelism = 1;
设置不同步Hudi表元数据:
set hoodie.datasource.meta.sync.enable=false;
4.2 Quick Start
Use DDL and DML statements to create tables, delete tables, and perform CURD operations on data.
4.2.1 Create table
Write a DDL statement, create a Hudi table, the table type: MOR and partition table, the primary key is id, the partition field is dt, and the merge field defaults to ts.
create table test_hudi_table (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
type = 'mor'
)
location 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/test_hudi_table' ;
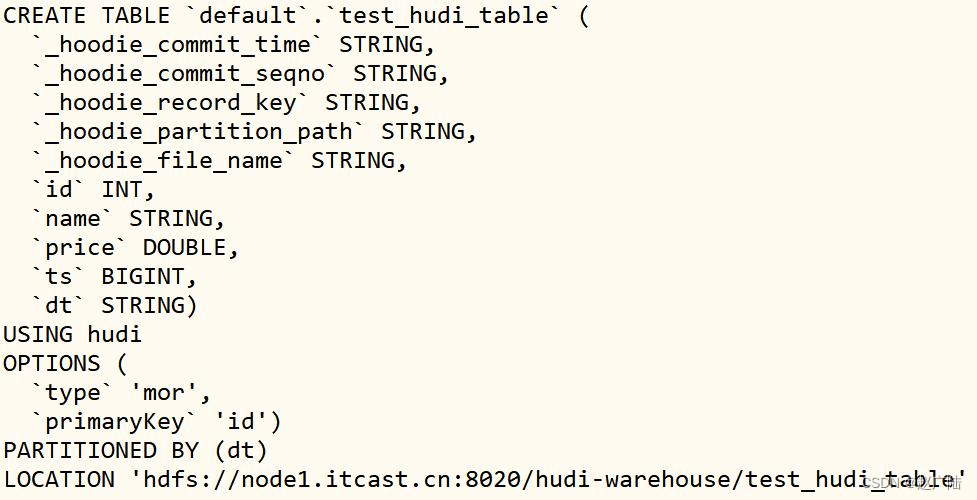
View the created Hudi table after creating the Hudi table
show create table test_hudi_table
4.2.2 Insert data
Use INSERT INTO to insert data into the Hudi table:
insert into test_hudi_table select 1 as id, 'hudi' as name, 10 as price, 1000 as ts, '2021-11-01' as dt;
After the insert is completed, check the local directory structure of the Hudi table. The generated metadata, partitions, and data are the same as those written by Spark Datasource.

Use the ISNERT INTO statement to insert a few more pieces of data, the command is as follows:
insert into test_hudi_table select 2 as id, 'spark' as name, 20 as price, 1100 as ts, '2021-11-01' as dt;
insert into test_hudi_table select 3 as id, 'flink' as name, 30 as price, 1200 as ts, '2021-11-01' as dt;
insert into test_hudi_table select 4 as id, 'sql' as name, 40 as price, 1400 as ts, '2021-11-01' as dt;
4.2.3 Query data
Use SQL to query Hudi table data, full table scan query:
select * from test_hudi_table ;

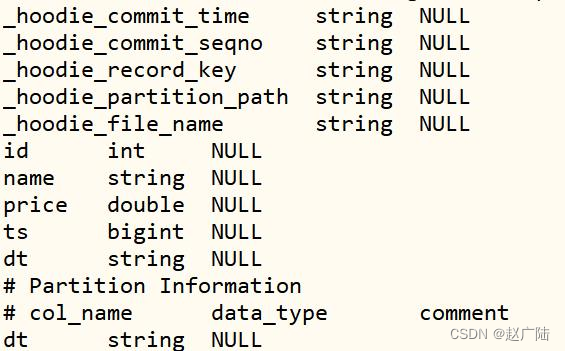
To view the field structure in the table, use the DESC statement:
desc test_hudi_table ;
Specify the query field to query the data of the previous few days in the table:
SELECT _hoodie_commit_time,_hoodie_record_key,_hoodie_partition_path, id, name, price, ts, dt FROM test_hudi_table ;

4.2.4 Update data
Use the update statement to update the price in the id=1 data to 100, the statement is as follows:
update test_hudi_table set price = 100.0 where id = 1 ;
Query the Hudi table data again to check whether the data is updated:
SELECT id, name, price, ts, dt FROM test_hudi_table WHERE id = 1;
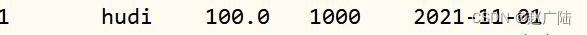
4.2.5 Delete data
Use the DELETE statement to delete the record with id=1, the command is as follows:
delete from test_hudi_table where id = 1 ;
Query the Hudi table data again to check whether the data is updated:
SELECT COUNT(1) AS total from test_hudi_table WHERE id = 1;
The query results are as follows. It can be seen that no data can be queried, indicating that there are no records in the Hudi table.

4.3 DDL create table
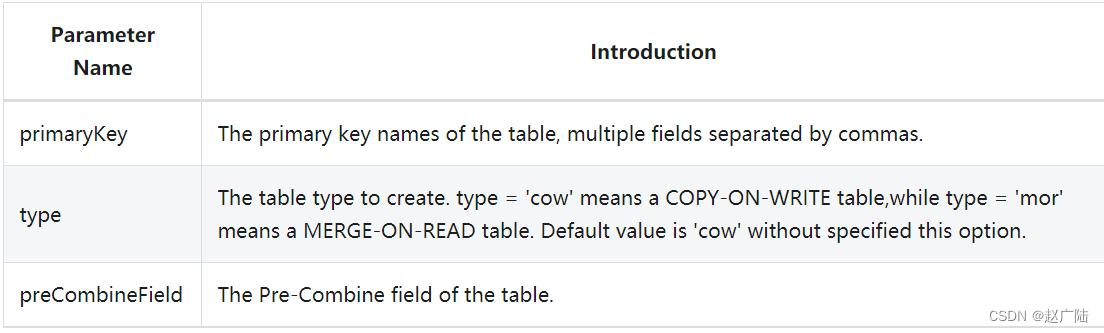
Write DDL statements in spark-sql, create Hudi table data, and core three attribute parameters:
■ Specify the type of Hudi table:

Official case: Create a COW type Hudi table.

■Management table and external table: When creating a table, specify the location storage path, and the table is an external table

■Set as a partition table when creating a table: partitioned table
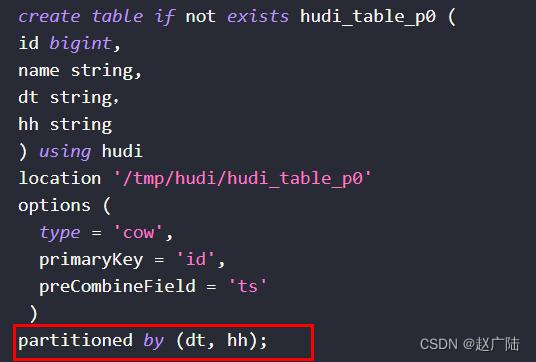
■Support using CTAS: Create table as select to create a table
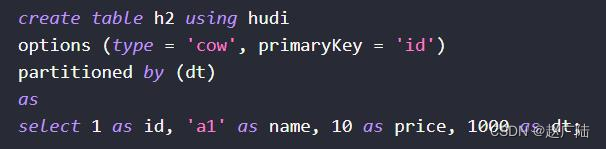
In practical applications, choose a reasonable way to create tables. It is recommended to create external and partitioned tables to facilitate data management and security.
4.4 MergeInto statement
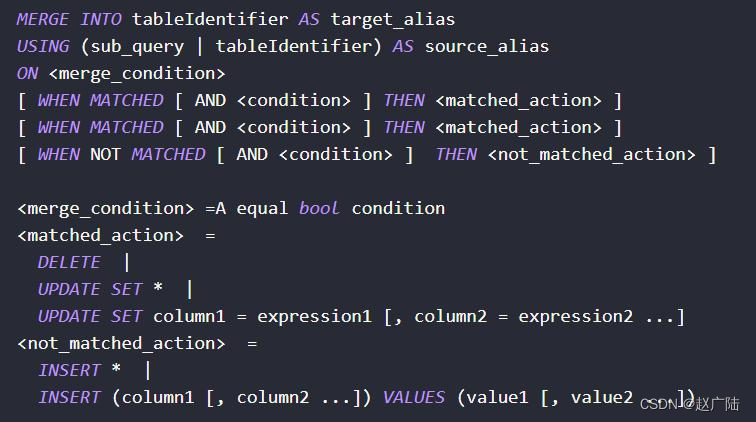
The MergeInto statement is provided in Hudi. According to the judgment conditions, it is determined whether to insert, update or delete the data when operating on the data. The syntax is as follows:
4.4.1 Merge Into Insert
When the condition is not met (association condition does not match), insert data into the Hudi table
merge into test_hudi_table as t0
using (
select 1 as id, 'hadoop' as name, 1 as price, 9000 as ts, '2021-11-02' as dt
) as s0
on t0.id = s0.id
when not matched then insert * ;
Query the Hudi table data, you can see that there is a record in the Hudi table
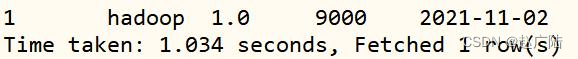
4.4.2 Merge Into Update
When the conditions are met (association conditions match), update the data:
merge into test_hudi_table as t0
using (
select 1 as id, 'hadoop3' as name, 1000 as price, 9999 as ts, '2021-11-02' as dt
) as s0
on t0.id = s0.id
when matched then update set *
Query the Hudi table, you can see that the partitions in the Hudi table have been updated

4.4.3 Merge Into Delete
When the conditions are met (association conditions match), delete the data:
merge into test_hudi_table t0
using (
select 1 as s_id, 'hadoop3' as s_name, 8888 as s_price, 9999 as s_ts, '2021-11-02' as dt
) s0
on t0.id = s0.s_id
when matched and s_ts = 9999 then delete
