The above Flink from getting started to giving up (12) - stepping on pits in event-driven scenarios in actual combat in enterprises (1) introduced Flink's real-time needs and pitfalls for channel traffic analysis based on event-driven scenarios.
This article continues to explain based on the event-driven scenario to explain the response timeliness, service quality requirements scheme design and pitfalls encountered (all articles on the topic of Flink have been organized and synchronized to the online Tencent document , and other knowledge points involved in this article can be used View it in the document, and reply to [ documentation ] in the background to get the link).
demand background
Requirements for response timeliness and service quality are applicable to various business scenarios. Here is a practical example: We select goods to pay for and place an order on some food delivery platforms, and then enter the link of merchant order acceptance. At this time, we want to analyze the efficiency of merchant order acceptance and rank this merchant based on customer evaluation data. Then the efficiency of receiving orders can be reflected by calculating the waiting time, and some rules can be applied in conjunction with the early warning mechanism to reach merchants.
Design
The real-time calculation waiting time here is actually the same as the actual case in the previous article, but there are still some differences. In the previous article, it only needs to be triggered once regularly to restore or initialize the indicator value. In this demand, because the order does not have any events during the process from placing the order to receiving the order, it will be difficult for us to calculate the waiting time in real time, instead of waiting until the merchant accepts the order to trigger the calculation. Get the wait time.
Therefore, how to generate circular drive events is the biggest difficulty in this requirement. Here, the editor adopts the idea of queue shunting to design, as shown in the figure below: 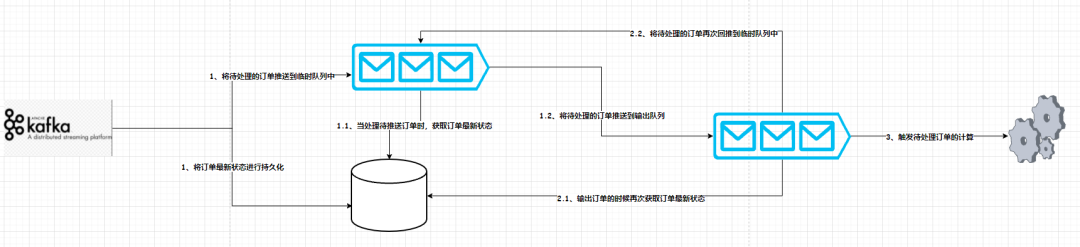 the process details are as follows:
the process details are as follows:
1. Consume data from the data source Kafka, and then shunt;
2. Push pending orders to a temporary queue, and update all the latest status 3. Take out the order to be processed from the temporary queue, and then query the
latest status of the order from the persistent storage. If the order has been processed, it will be discarded from the temporary queue; if the order is still unprocessed, Then put it in the result queue for the next step of processing
4. Get the order that is still pending from the result queue, and then query the latest status from the persistent storage system. If it is pending, it will flow back to the temporary Waiting in the queue for processing, if the order has been processed, it will be discarded;
5. The last order that needs to be calculated from the result queue is output to the downstream, and the calculation time is enough.
engineering practice
According to the above scheme design, queues and persistent storage are involved. As for the technology selection, it can be selected according to the actual situation of the enterprise. The implementation method can be either Flink SQL or Jar.
The editor here chooses a general solution: that is, the queue is based on Kafka, and the persistent storage uses HBase as the dimension table association. The implementation method first uses the pseudo code of SQL for your reference;
--输出队列
insert into real_dwd_order_info
select
t1.*
from
( --临时队列
select *,PROCTIME() as proctime
from real_tmp_order_info_from_kafka
)t1
left join real_dim_order_info_to_hbase FOR SYSTEM_TIME AS OF t1.proctime t2 --维度关联最新订单状态
on t1.order_id = t2.order_id
where t2.order_id is null or t2.order_status='待处理'
--回流到临时队列
insert into real_tmp_order_info_from_kafka
select
t1.*
from
( --输出队列
select *,PROCTIME() as proctime
from real_dwd_order_info
)t1
left join real_dim_order_info_to_hbase FOR SYSTEM_TIME AS OF t1.proctime t2 --维度关联最新订单状态
on t1.order_id = t2.order_id
where t2.order_id is null or t2.order_status='待处理'
As shown in the figure below: the above scheme is achievable.
Step on the pit and fill the pit
Although the above solution can be realized, there are several disadvantages as follows:
1. The dimension table is frequently queried, and because the latest order status needs to be obtained, there must be a certain trade-off in cache control.
2. Temporary queues and output queues are in a cyclic state, which inevitably leads to serious waste of storage resources and affects downstream calculations. There may be backpressure, which has a certain impact on timeliness . Here you can weigh whether it can be driven in a regular loop according to the actual situation (just need to adjust the structure)
3. Due to the characteristics of loop-driven backflow, the fluctuation of downstream data may be more obvious (considering the retracement problem, similar to Question 2)