In the long-term implementation of the recommendation algorithm, the Meituan food delivery recommendation team conducted in-depth exploration and optimization of the ranking model according to the contextual characteristics of the food delivery business. This paper introduces the modeling idea of "situation subdivision + unified model" for situational modeling. Through the user behavior sequence modeling and the optimization of the two modules of the expert network, the uniqueness and commonality of information between different scenarios can be realized. Mutual transmission, thereby improving the overall flow efficiency.
1 Introduction
Meituan Food Delivery Recommendations has served hundreds of millions of users. By continuously optimizing the user experience and the accuracy of traffic distribution, it provides users with a quality life, "helping everyone eat better and live better". Everyone may have different understandings of "users". The usual understanding is that users are natural persons. Most of the industry’s main recommendation scenarios, such as Taobao homepage guessing what you like, Douyin Kuaishou Feeds stream recommendation, etc., also think so. In these e-commerce, short video and other businesses, users use recommendation services whenever and wherever they like, and their The demand is roughly unified, and the supply of commodities, information, videos, etc. is also consistent.
But in fact, in the Meituan food delivery scenario, users are not only natural persons, but also a collection of needs. Needs are context-dependent, that is, where there is a situation, there is a need. Meituan Waimai has significant differences in user demand and business supply in different time, space and other broader environments. Therefore, localization, catering habits, and instant fulfillment jointly create a variety of scenarios for Meituan Waimai, and then derive a variety of user needs. The contextualization of the recommendation algorithm can help the algorithm better understand and satisfy users in different scenarios. need.
2. Issues and Challenges
The takeaway scene has strong geographical location and dining cultural constraints, and the needs of users in different locations (such as companies and residences) are quite different. Moreover, the time is also a key factor in determining the user's order. Taking high-consumption users in a certain area of Beijing as an example, there are obvious differences between weekdays and weekends in terms of order categories, order prices, and delivery distances from order merchants. As shown in Figure 1 below, there are obvious changes in the taste and mentality of users on weekdays and weekends. Most of the weekdays are for single meals, mainly rice set meals, light meals, and rice noodles, which are more suitable for the fast pace of work; On weekends, users will properly reward themselves and take care of their families, and tend to choose barbecue, Korean cuisine, and hot pot that are more suitable for dining with multiple people. It can also be seen from Figure 1 that from weekdays to weekends, the median price of a user's order increases from 30 yuan to 50 yuan, and the acceptable delivery distance is also getting longer.
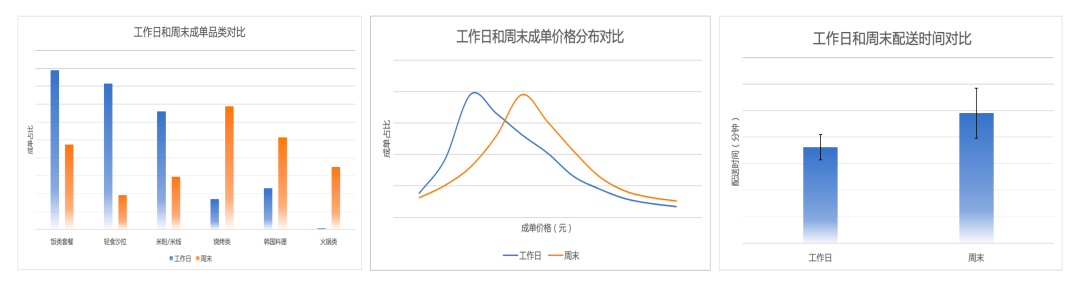
Figure 1 Different dining habits of high-spending users in a certain area on weekdays and weekends
Meituan food delivery recommendations need to meet the sum of needs in the context of "user X time X location" and respond to the continuous expansion and evolution of demand. In order to better understand the user needs we are facing, as shown in Figure 2 below, define it into a Magic Cube. User, time, and location are the three dimensions of the Magic Cube. Among them, each point in the Rubik's Cube, like the yellow dot in Figure 2, represents the needs of a user in a specific situation; each small cube in the Rubik's Cube, like the yellow cube in Figure 2, represents a group of similar users in a group requirements in similar circumstances. In addition, in terms of problem definition, in order to support the further expansion of the situational dimension, we use Hyper Cube to define more dimensional user requirements.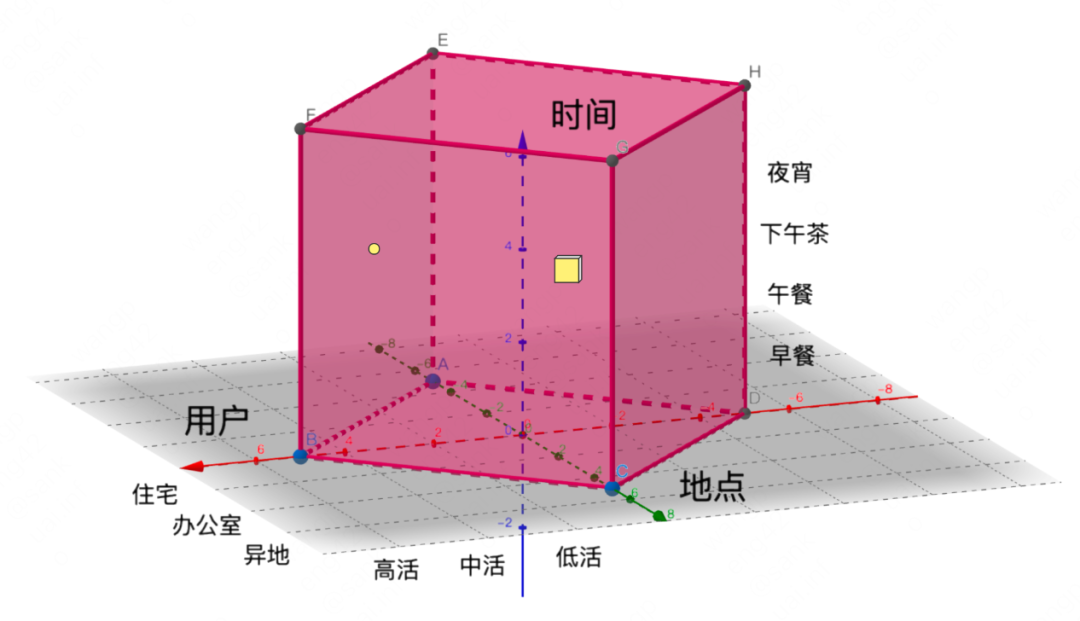
Faced with the above three-dimensional model, model design is very tricky. Previous model designs, such as user interest modeling, or simple multi-layer neural networks cannot cope with these complex situations where users, time, and geographic environments are entangled. User interest modeling usually adopts continuous modeling method to extract important behavior preference information through attention mechanism. However, in the case of rich user behaviors, it is difficult for the model to learn all behaviors, and only a part of the historical behavior in the takeaway scene is highly related to the user's current visit, and continuous behavior modeling will weaken the relevant part of the signal.
In addition, the simple multi-layer neural network is trained based on the data and labels in all situations, and can only learn the overall data distribution performance, and it is difficult to achieve the best effect in each situation. In response to this problem, Ali SIM4 first considered the method of searching out important relevant information in the behavior for modeling, but the problem they want to solve is to reduce the offline resource consumption of the user's ultra-long sequence modeling, which is not included in the model Introduce situational features; Ant ASEM216, Tencent CSRec17, etc. use model automation to select expert networks in different scenarios for sharing or independent learning to improve the performance of full-scenario or multi-task models, but these works only focus on single-dimensional scenarios and have not done wider expansion .
In view of the infinitely subdivided user context and the continuous expansion and evolution of the context, in order to solve the above challenges, we propose the modeling idea of "Segmented and Unified Model" (Segmented and Unified Model). Context subdivision conducts targeted modeling for specific user contexts to improve recommendation accuracy, and the unified model performs knowledge sharing and transfer of multiple similar user contexts to solve the problem of context expansion and evolution.
Specifically, according to each context in the Cube, the behavior most relevant to the current visit can be retrieved from the user's historical behavior, and the user preference in the current context can be accurately described. In addition, we design multiple expert networks, so that each expert can focus on learning the data distribution in the subdivided context, and then select experts based on context-related characteristics such as users, cities, time periods, and weekends. Different contexts can learn whether Share an expert or learn a different distribution of expert choices. For new users or users whose behaviors are not rich enough, referring to the concept of Cube, it can be considered to retrieve approximate contexts from Cubes, and the behavior retrieved based on the approximate contexts can be used as a supplement to the user's interests in the current context. At the same time, for the contextualized expert network, Through the model design, different experts can focus on their own situations, and at the same time, use other situational knowledge to carry out knowledge transfer for this situation, which alleviates the cold start problem of new users and the possible data sparsity problem.
In addition to contextual segmentation based on time and location, different traffic portals (homepage, diamond position, activity page) and business types (takeaway, flash sales, medicine) can also be regarded as a special "situation". "User X time X location" can be naturally expanded into a high-dimensional scenario of "user X time X location X entrance X business", through the description of the uniqueness of information and the mutual transmission of information commonality, the efficiency of all traffic can be improved.
3. Contextual intelligent traffic distribution
The implementation idea of "situation segmentation + unified model" is mainly divided into two components: user behavior sequence modeling and expert network structure. The overall structure of the model is shown in Figure 3:
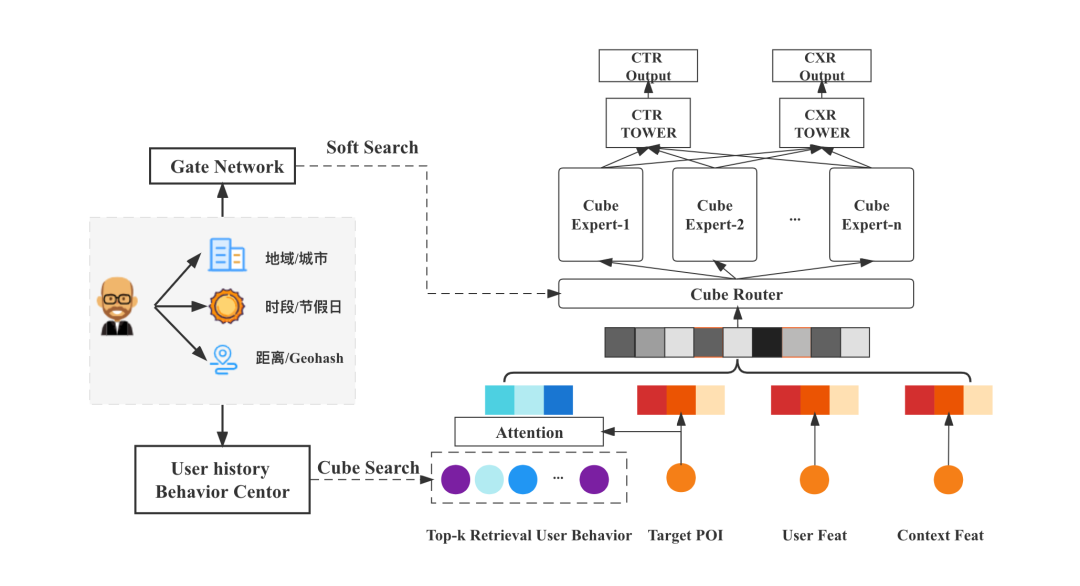
The model retrieves user behaviors in specific subdivided situations through Cube for sequence modeling, and automatically learns parameters of different situations through the expert network model, maintaining the unity of the model, which can not only describe the uniqueness of the situation, but also realize different situations. Knowledge sharing and transfer between. Specifically, in terms of user behavior sequence modeling, first carefully consider the important role of fine-grained behavior characteristics for the recommendation of takeaway merchants, and based on this, perform long-sequence multi-channel context retrieval on user sequences according to time and space scenarios; for The expert network structure first establishes multi-entry situation modeling based on the Attention mechanism for different entry situations, and then explores the contextualized dense MMOE and sparse MMOE models. It is found that in the takeaway scene, the expert network can learn different situations and tasks difference, thereby improving the accuracy of the model.
Based on this solution, for CTR and CXR (CTCVR) tasks, the model has achieved significant improvement in offline indicators AUC and GAUC (perSessionAUC), and has also achieved online UV_RPM, UV_CXR, PV_CTR, exposure novelty, first purchase order share Equivalent index income. The calculation caliber of online indicators is as follows:
-
UV_RPM = actual paid transaction volume (GMV) / number of exposures * 1000
-
UV_CXR = number of trading users / number of exposures
-
PV_CTR = Clicks/Impressions
-
Exposure novelty = (A - (A∩B)) / A, the set of merchants exposed in the user's current session is A, and the set of merchants exposed in all sessions of the user within 7 days is B
-
Proportion of first-time purchase orders = number of orders of new merchant users / total number of orders
3.1 Contextual long sequence retrieval
Deep learning based methods have achieved great success in CTR prediction tasks. In the early days, most works used deep neural networks to capture the interactions between features from different domains, so that engineers can get rid of the boring feature engineering work. Recently, a series of works, which we call user interest models, focus on learning representations of latent user interests from historical behaviors, using different neural network architectures such as CNN, RNN, Transformer, and Capsule, etc. DIN1 emphasizes that user interests are diverse, and introduces an attention mechanism to capture users' different interests on different target items. DIEN2 pointed out that the temporal relationship between historical behaviors is important for modeling user interest drift, and designed a GRU interest extraction layer with an auxiliary loss.
However, for Meituan Waimai, based on the above continuous modeling method, it is difficult to extract effective information highly related to the user's current visit situation from the user's historical behavior. MIMN3 shows that considering long-term historical behavior sequences in user interest models can significantly improve the performance of the models. However, long user behavior sequences contain a lot of noise, and at the same time greatly increase the delay and storage burden of online service systems. In response to the above problems, SIM4 proposes to search for important relevant information in behaviors. Specifically, after getting the product information that needs to be estimated, you can build a quick query index for user behavior products like information retrieval. The information of the product to be estimated can be regarded as a Query, from all the behaviors of the user, query the behavior subsequence related to it.
Therefore, inspired by MIMN's ultra-long sequence and SIM's retrieval ideas, we designed a contextualized sequence retrieval method. According to the context in the Cube, the most relevant to the current visit context is retrieved from the user's ultra-long historical behavior sequence. Sexual user behavior, and then capture more accurate user interests.
3.1.1 Fine-grained behavior characteristics
Different from the product recommendation form in e-commerce, Meituan Waimai Recommendation is based on merchants, and users have richer fine-grained behaviors from entering the merchant to the final order. By capturing the fine-grained behavior of users in the merchant, it can Finely perceive the differentiated preferences of users. For example, users who pay attention to quality merchants will view more merchant/product descriptions and reviews, while users with high discount sensitivity will view discount information and receive coupons.
In industrial practice, user behavior sequence features often include merchant/commodity representation features such as merchant/commodity ID, category, price, etc. In terms of behavior representation, in addition to the user's click to the merchant, what page does the user use to enter the merchant's order page, The user's fine-grained behavior on the merchant's order page can also reflect the user's preference. Therefore, it is possible to conduct an inductive analysis of the entire process of users from browsing merchants to placing an order, capture the most delicate behaviors of users and incorporate them into the model, and fully learn the most important and fine-grained behaviors of users in the delivery scene and the intention preferences they represent .
We extracted 70 different Micro-Behaviors from the whole process from browsing merchants to ordering products, and summarized four steps: locating merchants, inspecting merchants, selecting commodities, and settling bills of lading. When summarizing Micro-Behaviors with different intents, the daily average PV, daily conversion rate, behavior jump path, and page display information of Micro-Behaviors under the intent were comprehensively considered, and Micro-Behaviors with a daily average PV coverage rate of less than 1% were excluded. -Behavior, which aggregates behaviors with the same intention as feature representations (such as evaluating Tab clicks, evaluating label clicks, and user evaluation thumbnail clicks into "view comments" intent representations), and finally abstracts 12 Micro-Behaviors with different intentions , used to capture users' deeper and finer-grained interests. Based on the user Micro-Behavior, the flow from entering the merchant to the final order is extracted as shown in Figure 4 below:
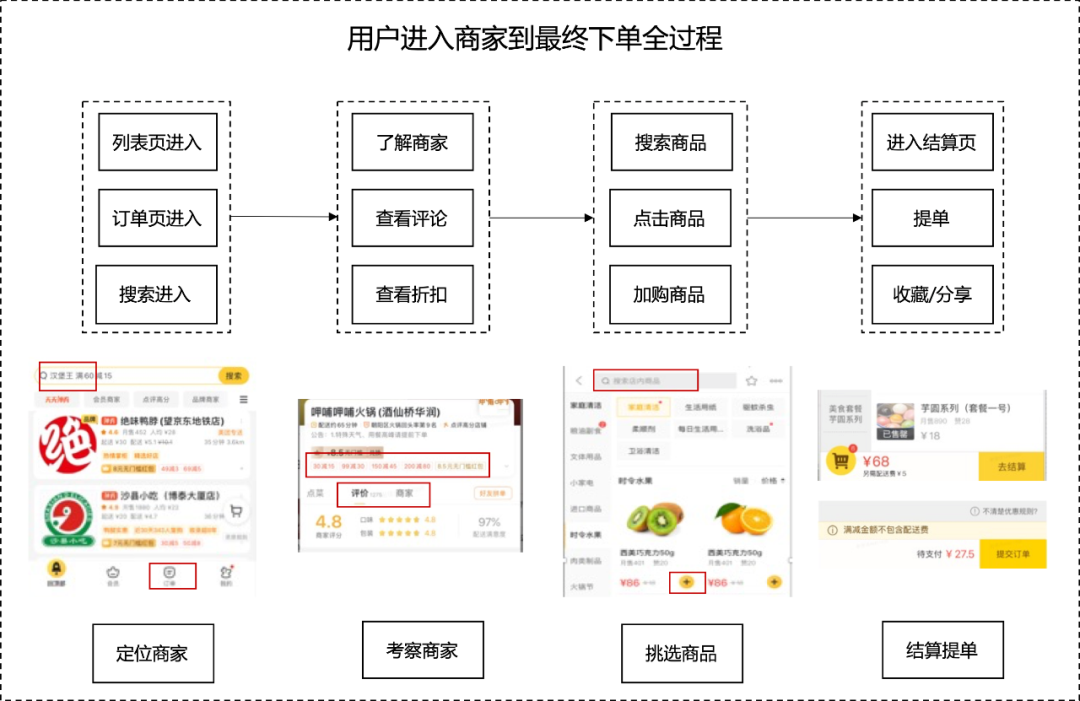
Next, we introduce in detail the 12 types of Micro-Behavior in 4 categories in the process of ordering takeout in Figure 4 below.
-
Locating merchants refers to the entrance logo for users to enter the merchants, which can reflect the reasons why users are interested in the merchants; for example, entering from the search result page means that the user has a strong willingness to buy, and users who enter the store from the recommended result page have more clear intent.
-
The behavior of investigating merchants includes clicking to learn about merchant details, viewing product reviews, and viewing merchant discounts. It can help better understand users' concerns. Students may pay more attention to discounts, while home users may pay more attention to merchant quality.
-
Selecting a product means that the user's satisfaction with the merchant has reached the standard. Among them, clicking on a product and purchasing an additional product can reflect the user's different degrees of interest in the merchant.
-
The settlement bill of lading means that the merchant can meet the needs of the user under the current situation, which includes not only the recognition of the merchant, but also the satisfaction with the merchandise in the merchant. Collection and sharing also show the user's high appreciation for the merchant.
As shown on the left side of Figure 5 below, there are significant differences in the conversion rates of the 9 Micro-Behaviors with different intentions on the day (the definition of conversion on the day: the user has a transaction within a natural day after a certain Micro-Behavior occurs at the merchant; This behavior is not shown due to its high conversion rate).
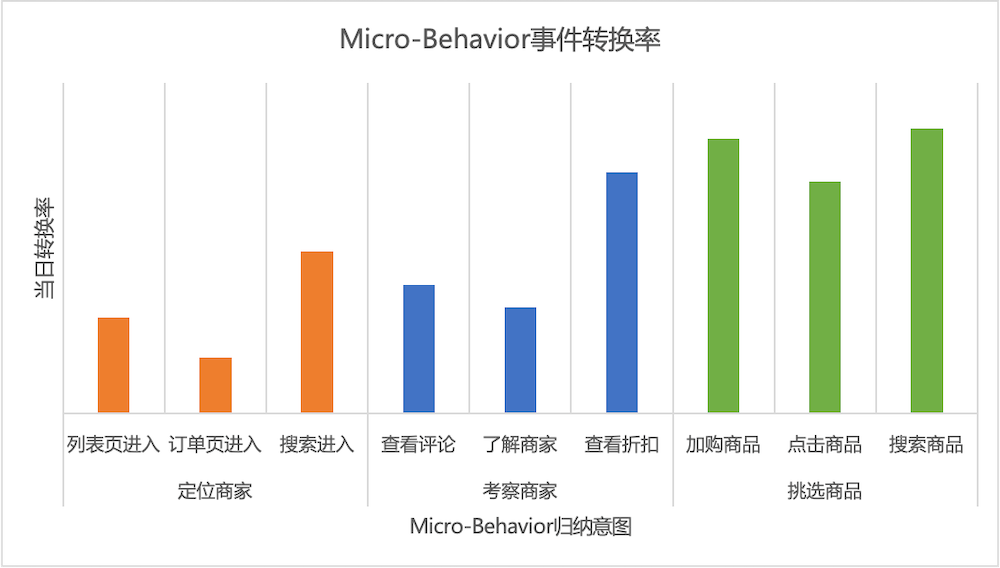
Micro-Behavior information is introduced into the user's real-time (short-period behavior) and historical (long-period behavior) business sequences respectively. As shown in the table below, the offline experimental data shows that the introduced Micro-Behavior information has achieved a significant improvement. In the end, the fine-grained behavioral features online achieved UV_RPM+1.77%, PV_CTR+1.05%.

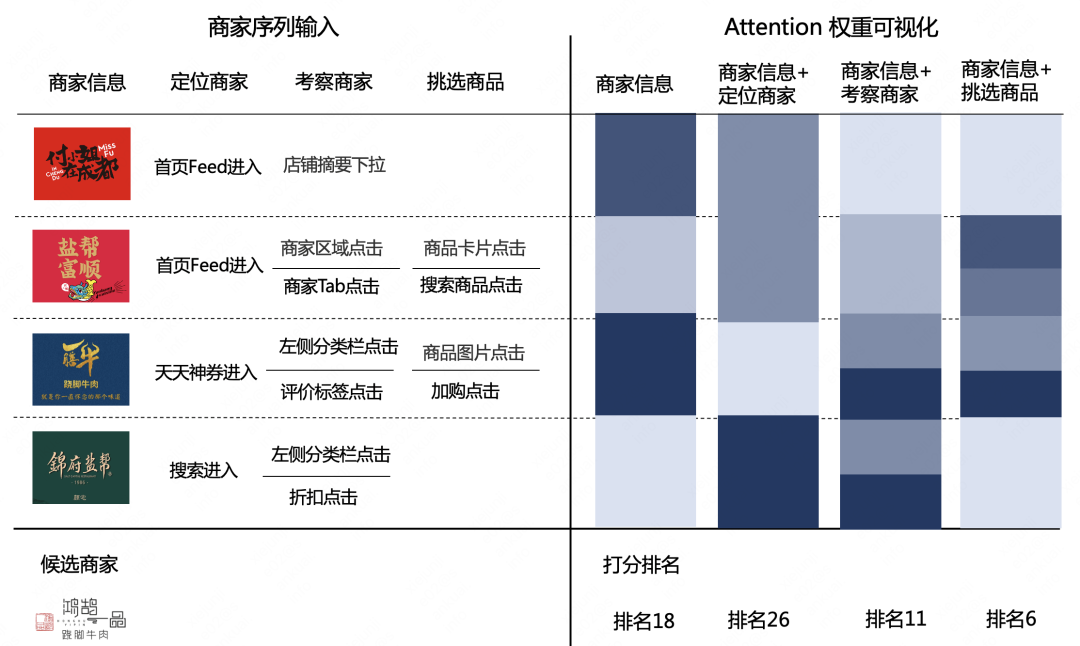
The offline experiment results show that the introduction of Micro-Behavior information increases the accurate recommendation ability of the model. In addition, we further validate whether the model learns fine-grained behaviors correctly. Randomly select a user’s single merchant and its merchant sequence and introduce the Attention weight change after introducing Micro-Behavior, as shown in Figure 6 below. The upper left part of the figure shows the merchants in the user behavior sequence and the corresponding Micro-Behavior information, and the upper right part of the figure is the sequence. The corresponding Attention weight after the merchant introduces the Micro-Behavior information is visualized. The darker the color of the square, the greater the Attention weight. The lower part of the figure is the user's final order. After introducing different Micro-Behavior information merchant ranking. Observe the change of Attention weight by introducing Micro-Behavior in the comparison sequence:
-
When the merchant sequence input only contains the first column of merchant information, the weight of Attention is mainly determined by the merchant ID, merchant Tag, merchant name and other information. The merchant name and merchant Tag of "Yishan Niu swaying beef" and "Honghu Yipin swaying beef" are relatively high. similarity and thus the greatest weight.
-
Merchant sequence input adds rich behaviors of locating merchants, inspecting merchants, and selecting products on the basis of merchant information. According to the Attention weight of each corresponding Micro-Behavior on the right, it can be seen that the searched merchants in the locating merchants column have the largest weight , while the weight of list page entry (homepage feed entry) is relatively small, which is in line with business cognition; in the behavior of investigating merchants, viewing discounts (discount clicks) and viewing comments (comment label clicks) indicate that users are screening merchants, and their Attention weights It is far greater than general intention clicks such as understanding merchants (store summary pull-down); clicks to add purchases (purchase products) and search products (clicks to search products) in selected products can show the user's intention to complete an order, due to the richness of this part of information , the ranking of candidate merchants was promoted to No. 6.
From the above process, it can be seen that the more complete the information introduced into Micro-Behavior, the more fully the model understands the user's interests, and the merchants that the user finally orders can also be ranked at the top.
3.1.2 Long Sequence Multiple Context Retrieval
Since its launch, Meituan Waimai has accumulated a wealth of user behavior data. Introducing such rich behavioral information into the model is a recent hot direction in industry and academia, and we have also conducted a series of explorations in this direction.
Initially, we directly introduced the click behavior of the past three years into the model, and found that the offline effect was significantly improved, but the pressure of training and reasoning was unbearable. On this basis, using SIM4 for reference, the category ID of candidate merchants is used as a query, and merchants of the same category are first retrieved from the user's behavior sequence, and then interest modeling is carried out, which has achieved good benefits offline.
Specifically, I have tried to use the secondary category and the leaf category to search separately. After the search, the maximum length is truncated according to the quantile point, the average length of the sequence retrieved by the secondary category is about X, and the leaf category is due to the category If the division is too fine, the average length of the retrieved sequences is greatly reduced. According to the evaluation of offline experiments, we finally chose to use the secondary category for retrieval, and achieved the effect of CXR GAUC+0.30pp offline. For the trade off between generalization and precision in retrieval conditions, such as secondary categories and leaf categories, we are currently conducting further exploration.
In order to further improve the effect of the model, considering the development of user interest modeling from DIN to SIM, it is based on the attributes of candidate merchants and commodities, and the interest in the candidate merchants and commodities is extracted from the user's behavior history. It works in the scenario, because the user’s interest in a certain merchant or product basically does not change with his location and time period (the user wants to buy a mobile phone case, it will not change because he is at home or in the company, and it will not change. will change depending on whether his shopping hours are in the morning or evening). However, compared with traditional e-commerce, catering takeaway, as mentioned in the previous problems and challenges, its distinctive LBS and catering cultural characteristics constitute a variety of situations, and users have different preferences for different merchants and products in different situations. It is different, it will change. Therefore, in addition to modeling category preferences, users' geographical location preferences and time period preferences should be further modeled.
-
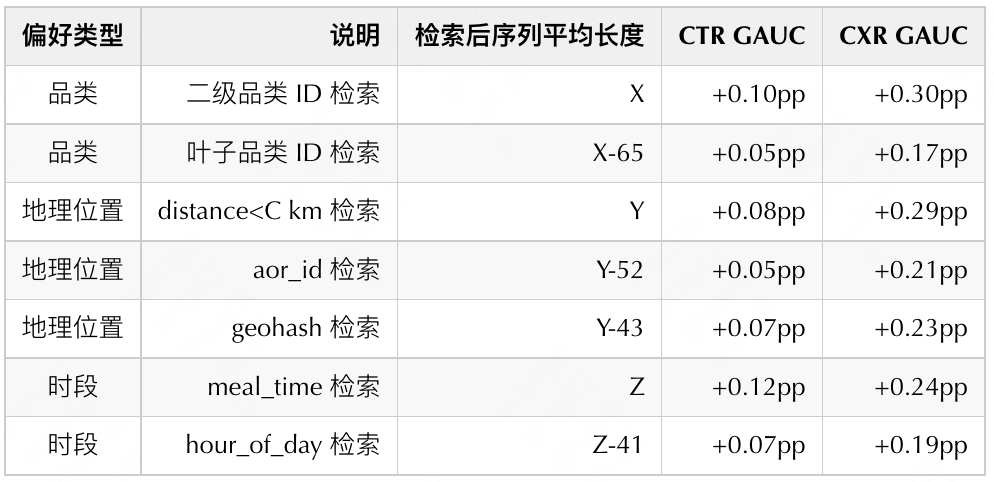
For the modeling of geographic location preference, we try to use the geohash (a geographic location code, see Wikipedia)/aor_id (cellular ID) of the user's current geographic location as the query to retrieve the same geohash/aor_id in the user's historical behavior Merchants, also based on business experience, directly retrieve all merchants whose distance to the user’s current request location is less than C kilometers from the user’s historical behavior. The average length of the sequence after retrieval is shown in the table below. <C km is retrieved to model the user's geographic location preference. Kilometers C is a hyperparameter obtained based on business experience statistics. Considering that different users may have different tolerances for distance, how to adjust this hyperparameter for different users in different scenarios is still to be determined. Actively exploring.
-
Two retrieval methods are tried for the modeling of time slot preference: from the user's historical behavior, the meal_time of the current request (dividing a day into breakfast, lunch, afternoon tea, dinner, and supper according to business) or hour_of_day (behavior hour period ) to retrieve the same business. The granularity of the meal_time division is coarser, and more merchants are retrieved. It can also be seen from the table below that its offline results are better, and it has become the final choice of modeling time preference. Obviously, meal_time retrieval and hour_of_day retrieval also have a trade off problem between generalization and precision.
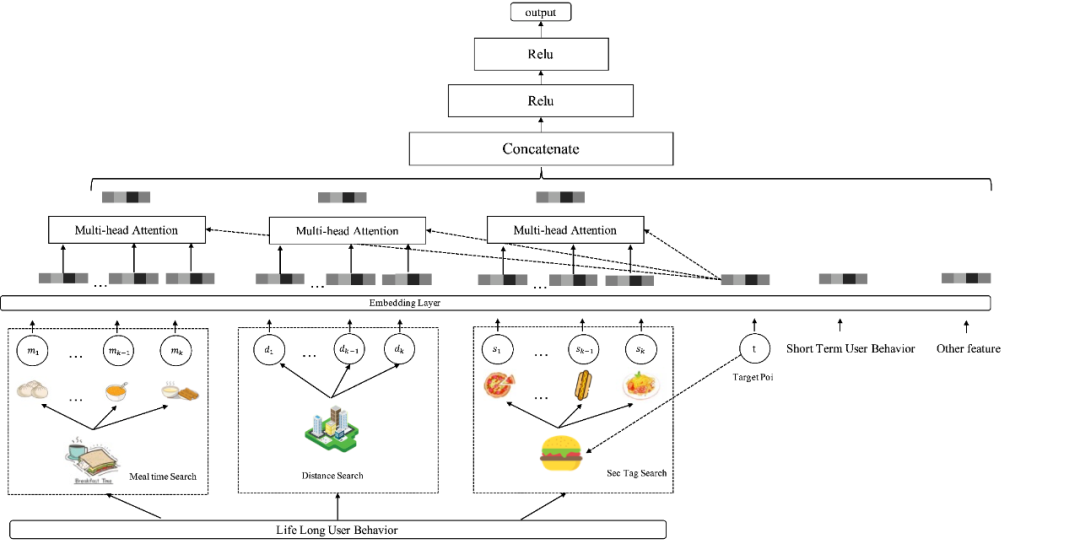
Finally, we add the secondary category ID retrieval sequence (category preference), distance<C km retrieval sequence (geographic location preference) and meal_time retrieval sequence (period preference) into the model, and compare different The subsequences have been adjusted to different maximum lengths respectively, and the model structure is shown in Figure 7 below:
In the end, CTR GAUC+0.30pp and CXR GAUC+0.52pp were obtained offline, and UV_CXR+0.87%, UV_RPM+0.70%, PV_CTR+0.70% were obtained online, and the proportion of first-order orders was +1.29%. It can be noticed that the introduction of the above-mentioned long sequence not only improves the efficiency, but also improves the novelty. The analysis shows that by modeling the longer-term interest of the user, the field of view of the model is expanded, and it no longer focuses on the short-term interest of the user. interest, which can better meet the characteristics of "short aggregation, long variety" of user tastes.
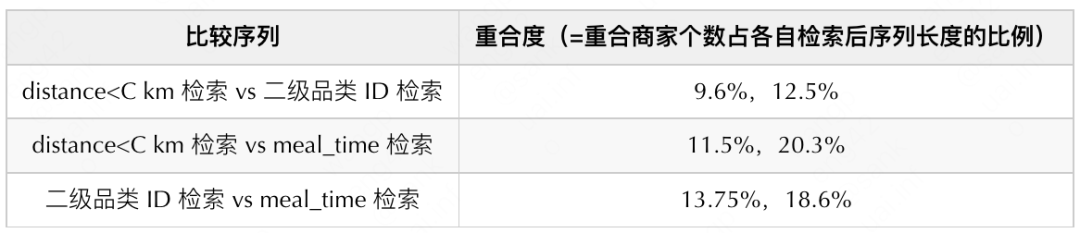
In the follow-up data exploration, based on the sample dimension, the coincidence degree of the secondary category ID retrieval sequence, meal_time retrieval sequence and distance<C km retrieval sequence was counted. As can be seen from the table below, the coincidence degree of merchants retrieved by each of the three is indeed very low, which is in line with the expectations of different modeling preferences, and also explains why the effect still increases after the three sequences are superimposed.
However, although the current combined version of the three-way search can effectively model the user's category preference, geographical location preference and time period preference, there are still two obvious defects. First of all, there is still redundant information in each retrieval sequence, and three sequences need to be modeled separately, which brings great performance pressure. Secondly, the situation is divided into separate dimensions for modeling, and the connection between them cannot be modeled. A more realistic and accurate situation should be a unified modeling of different dimensions of the user's situation. Aiming at these two problems, under the concept of Situation Cube, we are carrying out the exploratory work of modeling the user's situation preference through a sequence.
The following section continues to introduce long-sequence engineering optimization practices. Long sequence models will bring a series of engineering challenges to online services. The longer sequence length greatly increases the cost of data transmission and model reasoning during service. Special optimization needs to be made for these two aspects.
-
Data transfer optimization : repeated retrieval information compression. Taking tag_id retrieval as an example, since the scheme adopts a relatively coarse category division, the number of tag_id itself is very limited, and the tag_ids corresponding to the candidate merchants in a request batch have a lot of repetitions. Based on the above analysis, when searching in the same request, only the non-repeated tag_id subsequence features are retained, and the overall transmission data is finally compressed to about 1/7 of the previous one, and the optimization effect is very obvious.
-
Model inference optimization :
-
1) Embedding is transferred from memory to GPU memory storage. In the model calculation module, the Embedding will be queried in the CPU hash table according to the model input characteristics. The core of query optimization is to solve the problem of low query efficiency of the CPU hash table. The low query efficiency is mainly caused by many hash conflicts and few query threads. . In order to fundamentally solve the above problems, we upgrade the CPU hash table to GPU hash table, transfer the model Embedding from memory to GPU memory storage, and directly perform query operations on GPU. The GPU hash table has been optimized for data rearrangement, which greatly reduces the number of data detections when hash conflicts occur, and uses more threads provided by the GPU to achieve faster queries when hash conflicts occur. The pressure test shows that through the above optimizations, more queries can be processed in a shorter time, and the query problem is effectively solved.
-
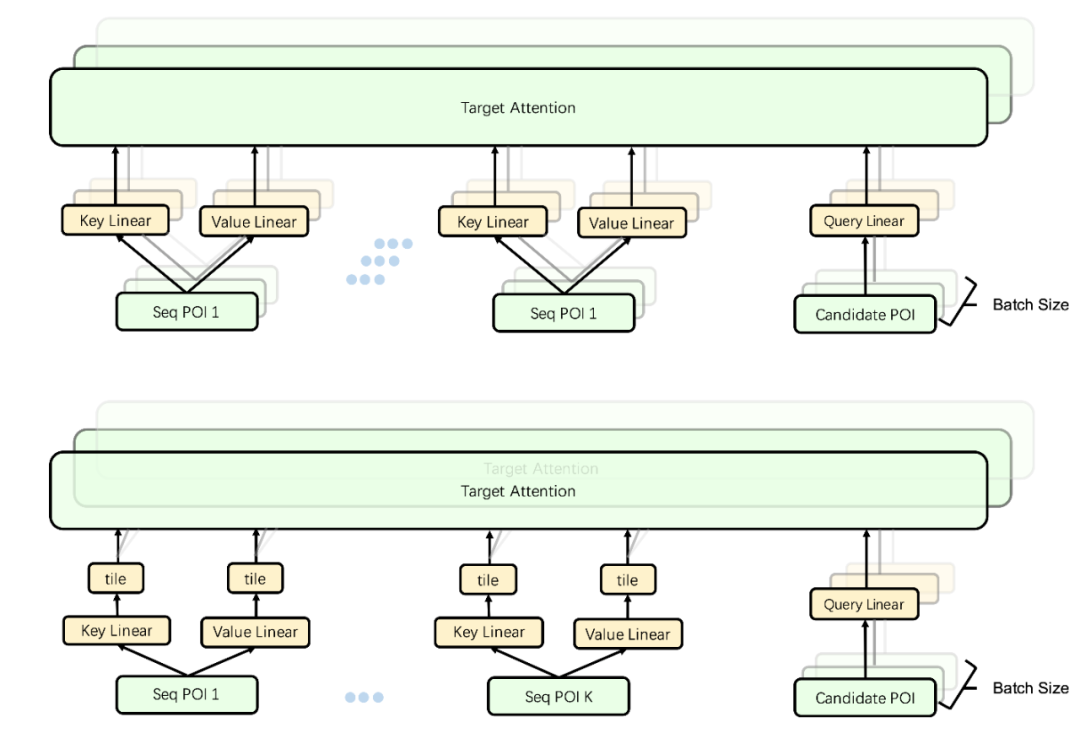
2) The user sequence calculation graph is folded. The addition of long sequence modules has brought enormous pressure to online computing, so consider optimizing the online computing graph. Since part of the user sequence input is consistent within a batch within a request, when the original calculation graph projects the user sequence, a large number of redundant calculations will be generated. Based on this, when requesting model services, we fold the id query module and projection calculation of the user-side sequence in the calculation graph, as shown in Figure 8, first reduce the user-side feature batch size to 1, calculate only once, and then When calculating the attention with the candidate merchants, it is expanded, and the calculation graph is folded, which greatly reduces the huge calculation overhead caused by the online sequence part.
-
3.2 Contextualized multi-expert networks
Most of the CTR prediction models in the industry follow the traditional Embedding&MLP paradigm, taking user interest vectors, merchant/commodity representations and other features as input, and learning the relationship between features, samples, and labels through a simple multi-layer neural network. In addition, some well-known works in academia, such as PNN5, DeepFM6, xDeepFM7, DCN8 and other methods, are trying to model the co-occurrence relationship between features, the specificity of features, the hierarchical relationship of features, the relationship between samples and other information, and Remarkable results have been achieved in public datasets and some specific industrial scenarios. In the field of NLP, in October 2018, Google released the BERT9 model, which refreshed the best level of 11 NLP tasks, thus opening the era of NLP "big refining model" and detonating a research boom in the industry.
Mixture of Experts (MOE) models have proven to be an effective route to machine learning models with larger capacity and higher performance. MOE is built on the principle of divide and conquer, where the problem space is partitioned among several neural network experts, supervised by a gating network. On the basis of MOE, MMOE10 proposes a novel multi-task learning method, which shares the expert sub-model in all tasks, adapts the MOE structure to multi-task learning, and achieves significant benefits in Google's large-scale content recommendation system.
Inspired by MOE, we first explore the multi-expert network model under different entrances, and then use MMOE to expand the entrance context to multiple complex scenarios such as cities and time periods, so that each expert can focus on learning the data distribution under the subdivided context, Learn user interests in different scenarios, and finally explore sparse MMOE modeling to further improve the model effect while keeping the reasoning performance unchanged. The use of contextualized multi-expert networks may also lead to a large number of expert problems caused by multi-dimensional cross multiplication of situations. For this problem, in some situations with clear differences, such as entrances, we will use an Expert corresponding to one entrance. For different For particularly clear complex situations, such as time crossing locations, etc., we will use a fixed number of Experts to reduce the dimensionality of a large number of Experts, and then use the Gate network for automatic learning.
3.2.1 Multi-entry scenario modeling
Meituan Waimai covers multiple recommended portals, including the homepage Feed (the main traffic portal), as well as food "King Kong", dessert "King Kong", night snack "King Kong", afternoon tea and other sub-channels. The following challenges exist for modeling different entry scenarios:
-
There are obvious differences in the amount of traffic, richness of user behaviors, and business exposure of each recommended portal. The data volume of multiple small portals is less than 10% of the home page feed, resulting in limited sample accumulation, and it is difficult to use these data to train high-precision models.
-
There is a mutually exclusive relationship between the user's behavior under each entrance. For example, users will not place orders on different channels at the same time, so the traditional multi-task modeling paradigm that simply regards each entry as a task as a learning goal is difficult to achieve better model accuracy.
-
In order to meet the user experience, different channels will have corresponding category rules, time period rules, and special business support rules, which makes the recommended entrances of each channel have different degrees of difference and commonality. While different recommendation portals overlap in terms of users and merchants, there are also considerable differences in user behavior and merchant distribution. For example, the homepage feed will include all merchant categories, and dessert drinks mainly include milk tea, coffee, desserts and other merchants. Therefore, it becomes particularly important for the model to model the commonality and difference between channels, and at the same time dynamically model the relationship between channels.
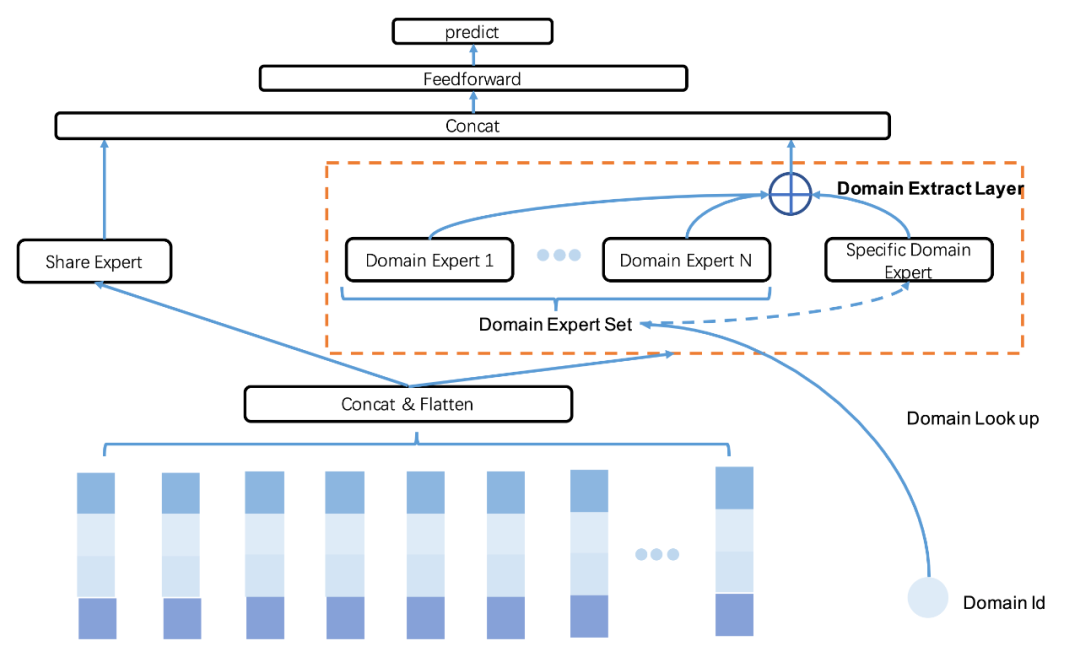
We address the above challenges by implementing a multi-entry unified modeling (AutoAdapt). Specifically, a multi-entry situational expert model as shown in Figure 9 is designed, and a Share Expert is constructed between the feature Embedding of the model structure and the multi-task Tower to learn the information of all entrances, and the Expert will always be active; in order to capture multiple For the difference and connection between the entrances, the Domain Extract module is constructed, and an expert network (Expert) composed of MLPs is set up for each entrance.
-
In order to enable the Expert corresponding to each entry to fully model the private expression, during model training and inference, for the sample or request of entry i, activate its corresponding Expert Di according to the entry ID, and the output generated by the Expert will be directly input to Xi Go to the Tower corresponding to the task.
-
For a sample or request of an entry, when the Expert of this entry is guaranteed to be activated, the Experts of other entries are activated with a certain probability, and the output of these Experts is extracted by Pooling, so as to effectively utilize the Experts of other entries. Knowledge. Obviously, the degree of similarity between entries and the degree of dependence of the same sample on different entry knowledge are different, so a Query-Key Attention module is added for dynamic probability activation. As shown in the Domain Extract module in Figure 9, for the sample or request of the entry i, the output Xi of its own Expert is used as the Query, and the output of the other entry Expert is used as the Key, and the similarity between the Query and the Key Attention score That is, corresponding to the activation probability of the Expert, the output of each Expert is weighted and aggregated using the activation probability normalized by Softmax to obtain the representation Xagg, which will also be input to the Tower corresponding to the prediction task.
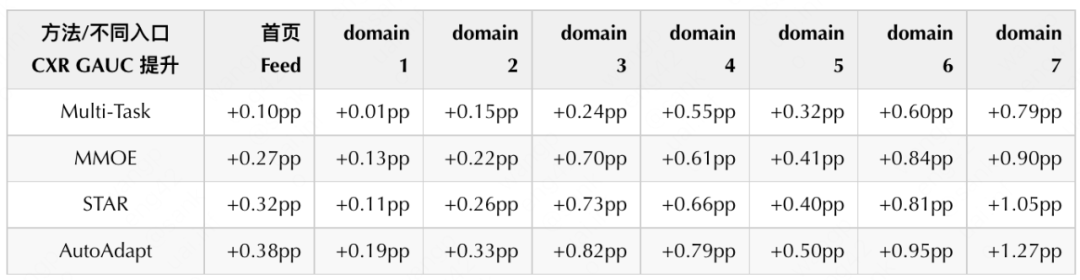
In the offline experiment, we used the model of all-entry data mixed training + entry ID features as the baseline, and tried methods such as Multi-Task (setting an estimation task for each entry), MMOE, and STAR11. Since the consumption behaviors of users at each entrance of food delivery are mutually exclusive, and the behavior samples of small entrances are relatively sparse, the effect of directly adopting multi-tasking is poor, and the introduction of MMOE will have a certain improvement. At the same time, compared with Ali's STAR, each entry in this method has its own independent network parameters, but it fails to capture the relationship between each entry, and the improvement in the takeaway recommendation scenario is limited. In contrast, AutoAdapt achieves large improvements on both main and small ingress.
In order to do a visual analysis of the activation weights generated by Attention, specifically, we group and average the results of Attention in the evaluation set according to different entry Query, as shown in Figure 10 below, the vertical axis represents the entry of Query, and the horizontal axis Represents the entry as a Key, and the value of each point in the figure represents the average value of the Attention score when an entry pair is used as a Query-Key. For example, the second line represents the average activation probability of other entry Experts when Gourmet King Kong (D1) is used as a query, and it is found that the model can learn a similar relationship between the entrances that conform to cognition, for example, when the afternoon tea sample (D7) is used as a query , it has an average activation probability of 0.3 with Dessert Drink (D2) Expert, which is significantly higher than the activation probability of other entrances. In addition, Food King (D1) and Dinner Channel (D5) also have a high correlation.
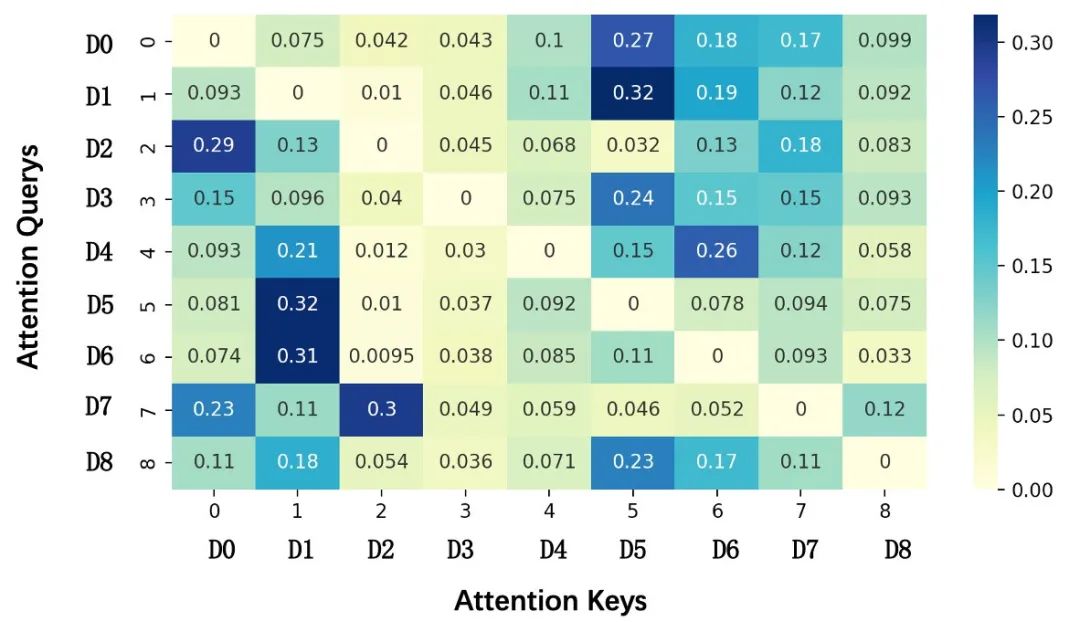
Figure 10 Heat map of different entrance Attention weights
This solution not only realizes the unification of models among traffic portals such as homepage feed, gourmet "King Kong", desserts and drinks, but also brings significant offline index benefits and online index growth to each entry. After joint modeling, the small portal can effectively use the rich information of the home page feed, which significantly improves the online and offline effects. In addition, for the home page feed, this solution also has a significant effect improvement. The online benefits of different scenarios are shown in the following table :

3.2.2 Contextualized Dense MMOE
The expert network is one of the main means of situational modeling. The model can automatically select the parameters to be activated according to different situations to participate in reasoning to achieve a higher level of overall accuracy. We found that on the basis of the Share-Bottom CTR/CXR multi-objective structure, the introduction of the MMOE structure can bring significant offline CTR/CXR AUC benefits (as shown in the table below). It can be found that when the number of Experts reaches 64, the CTR GAUC and CXR GAUC There is an increase of about 0.3pp and 0.4pp respectively.
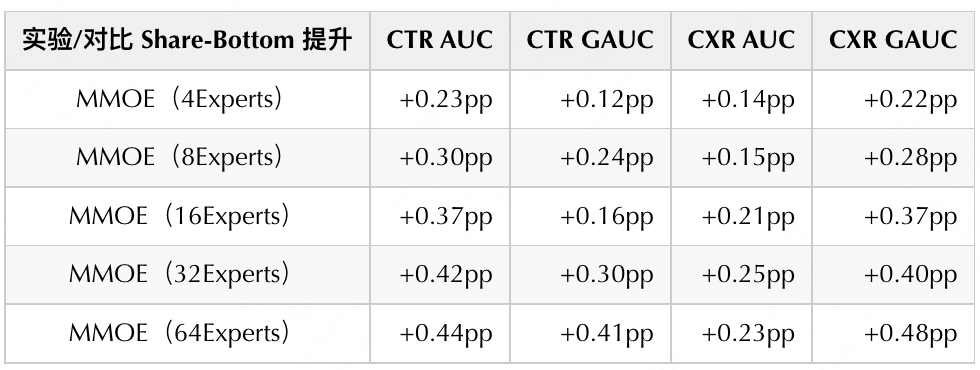
The introduction of the MMOE structure with a large number of Experts can bring significant offline benefits, but at the same time it will also increase the cost of offline training and online services, which requires a trade-off between effectiveness and efficiency. Under the constraints of maintaining a certain offline training time and online latency, we chose the 4Experts MMOE version as the new baseline model, and made detailed exploration and more detailed optimization, including:
-
Introduce residual connection : Inspired by Switch Transformer12, introduce residual connection between embedding layer and Experts output layer to alleviate gradient disappearance, offline CXR GAUC+0.1pp.
-
Gate optimization of MMOE : Try to input only strong situational features such as time period and city in the embedding layer of Gate of MMOE (that is, select Expert for each task based on the situation), and found in the experiment that compared to using all features in Gate , this way of building gates only with scene-related features will achieve a certain offline GAUC improvement, offline CXR GAUC+0.1pp.
-
Nonlinear activation : A number of NLP works such as B Zoph13 and Chen14 pointed out that the use of nonlinear activation can further improve the effect of large-scale models. We use Gelu to replace the leaky relu activation function, and the offline CXR GAUC+0.11pp.
Finally, the contextualized dense MMOE online achieved gains of UV_RPM+0.75%, PV_CTR+0.89%, and exposure novelty+1.51%.
3.2.3 Contextualized sparse MMOE
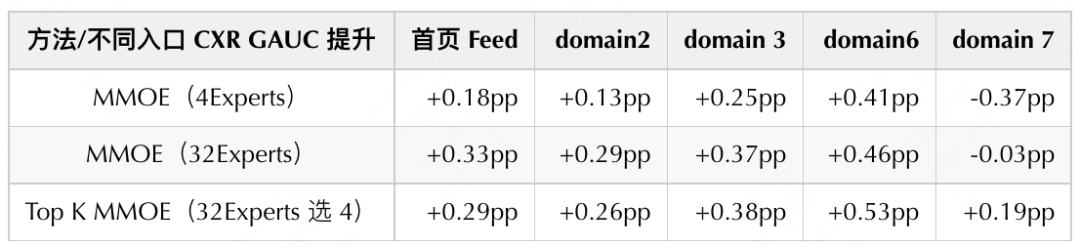
After exploring the optimal version of the dense MMOE, we began to explore the sparse MMOE model. Drawing on the Sparse Expert Model proposed by Google, such as Switch Transformer, we use the Top K MMOE method to try. The core idea is that each sample selects only K (K<<N) output from all N Experts for subsequent calculation according to the calculation result of Gate. The experimental results in the table below show that using 32Experts compared to 4Experts has significantly improved offline indicators at different entrances. At the same time, Top K MMOE (choose 4 from 32Experts) has obvious advantages in different entrances compared with MMOE 4Experts with the same FLOPs, and the effect is close to that of MMOE 32experts.
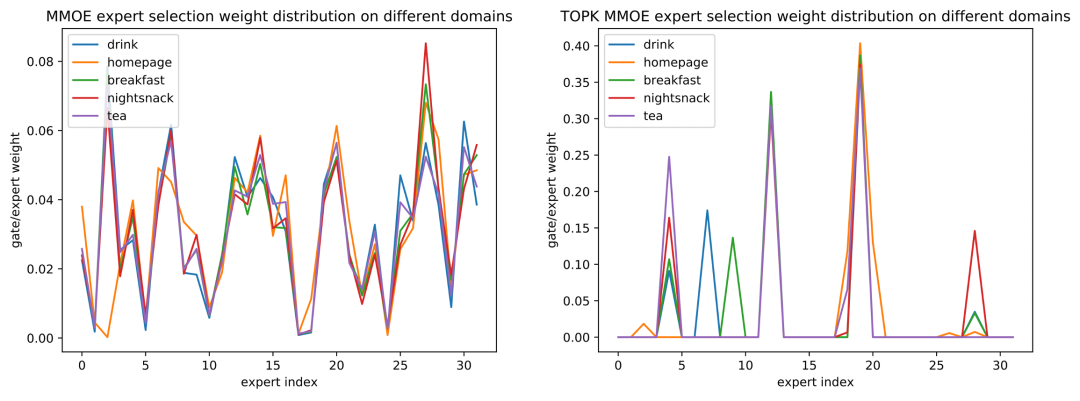
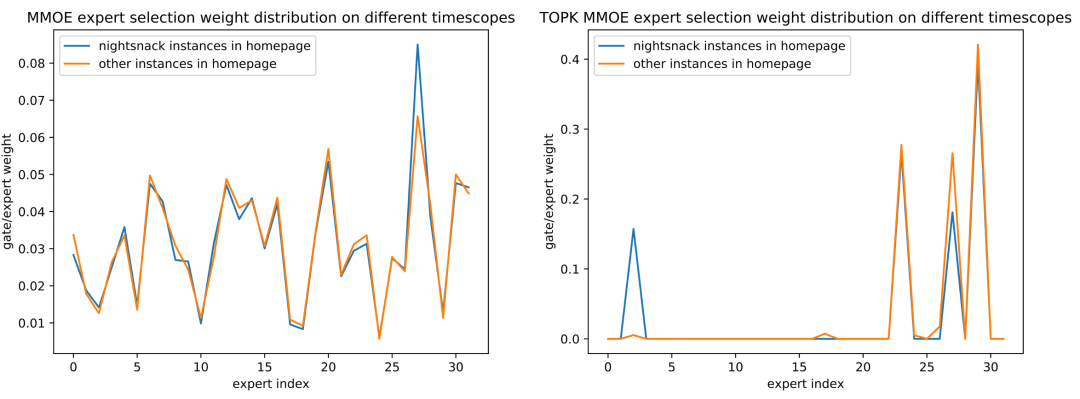
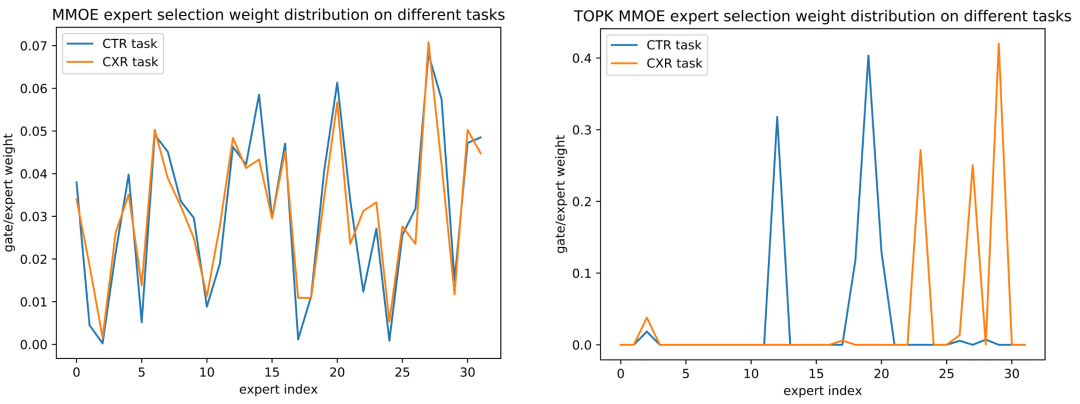
Continue to analyze whether the sparse MMOE can learn the commonality and difference of each slice, and visualize the Expert Gate distribution of the CTR task of MMOE and Top K MMOE on each domain. It can be found that compared with the dense method, the sparse Top-K method can learn to select different Experts for serving according to different entrances, different time periods, and different tasks. For example, for different time periods, the distribution of afternoon tea entrance and breakfast entrance in Figure 11 is obviously different, and the distribution of supper time and non-night supper time at the home page entrance in Figure 12 is obviously different; for different task objectives in the model, as shown in Figure 13 The distribution of CTR/CXR tasks in MMOE is also significantly different, which is consistent with the actual business cognition, indicating that different experts in sparse MMOE learn the differences between different situations and different tasks.
4. Summary and Outlook
Thanks to the Cube concept, we can continue to explore more scenarios and optimize the cold start problem in this scenario. For example, when a user is in a different place, by comparing the similarity of the scenario cubes, users with more mature behaviors in similar scenarios can be found, and their interests, preferences and behaviors can be transferred over (an active user pool is established for each scenario in the implementation), To alleviate the problem of poor user experience in the cold start phase.
In addition, in contextualized long-sequence retrieval, there are often problems of less single-channel retrieval information and poor online performance of the overall retrieval. We consider exploring a new multi-attribute retrieval mechanism to combine multiple retrievals into single-channel retrieval. At the same time, the richness of retrieved information is expanded to further improve the model effect; on the sparse expert network, we found that the recommendation model has a serious parameter saturation phenomenon: when the dense parameters increase to a certain extent, the improvement of the model effect will rapidly decay. Therefore, it is not advisable to improve the effect by simply expanding the number of experts. In the future, we will consider combining AutoML, cross-network and other means to improve the efficiency of parameter utilization, and seek industrial-level solutions for implementing sparse expert networks in recommendation scenarios.
5. Author of this article
Ruidong, Junjie, Leran, Qin Yu, Xiufeng, Wang Chao, Zhang Peng, Yin Bin, Beihai, etc. are all from Daojia Business Group/Daojia R&D Platform/Search and Recommendation Technology Department.
6. References
[1] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction. SIGKDD 2018.
[2] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction. AAAI 2019.
[3] Pi Q, Bian W, Zhou G, et al. Practice on long sequential user behavior modeling for click-through rate prediction. SIGKDD 2019.
[4] Pi Q, Zhou G, Zhang Y, et al. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. CIKM 2020.
[5] Qu Y, Cai H, Ren K, et al. Product-based neural networks for user response prediction. ICDM 2016.
[6] Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv:1703.04247, 2017.
[7] Jianxun Lian, et al. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. KDD 2018.
[8] Wang R, Shivanna R, Cheng D, et al. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. WWW 2021.
[9] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805, 2018.
[10] Ma J, Zhao Z, Yi X, et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-experts. KDD 2018.
[11] Sheng X R, Zhao L, Zhou G, et al. One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction. CIKM 2021.
[12] Fedus W, Zoph B, Shazeer N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961, 2021.
[13] Zoph B, Bello I, Kumar S, et al. Designing effective sparse expert models. arXiv 2202.08906, 2022.
[14] Chen Z, Deng H Wu Y, Gu Q. Towards Understanding Mixture of Experts in Deep Learning. arXiv:2208.02813, 2022.
[15] Zhou M, Ding Z, Tang J, et al. Micro behaviors: A new perspective in e-commerce recommender systems. WSDM 2018.
[16] Zou X, Hu Z, Zhao Y, et al. Automatic Expert Selection for Multi-Scenario and Multi-Task Search. SIGIR 2022.
[17] Bai T, Xiao Y, Wu B, et al. A Contrastive Sharing Model for Multi-Task Recommendation. WWW 2022
---------- END ----------
Job Offers
Search Recommendation Algorithm Engineer
Job Responsibilities
-
Develop large-scale deep learning, graph learning and other technologies, use modules such as attention mechanism, memory network, and relationship network to understand user needs and discover user interests from massive data across multiple time and space scenarios, and optimize click-through rate and conversion rate models. Show users more suitable and interesting delicacies and products;
-
Develop reinforcement learning, explainable deep learning, multi-modal learning, multi-objective optimization and other technologies, optimize rearrangement and mixing models, intelligently control traffic distribution, optimize platform ecology, and achieve a win-win situation for consumers and businesses;
-
Use technologies such as knowledge graphs, computational vision, and natural language generation to help merchants automatically and intelligently generate display content and copywriting based on user interests, and improve promotion efficiency;
-
Track and study the cutting-edge technology of artificial intelligence, and explore the application of technology in retail and medical e-commerce scenarios.
Interested students can send their resumes to: [email protected].
maybe you want to see
| Meituan Waimai search optimization practice based on Elasticsearch
| TensorFlow GPU training optimization practice in Meituan food delivery recommendation scene
| The Application Practice of GPU in Prediction of Fine Arrangement Model in Takeaway Scene
read more
Frontend | Algorithms | Backend | Data
Security | Android | iOS | Operation and Maintenance | Testing