[SpringBoot Advanced] SpringBoot integrates Sharding-JDBC sub-database and sub-table
Apache ShardingSphere
Apache ShardingSphere (Incubator) is an ecosystem composed of an open source distributed database middleware solution. It consists of three independent but capable of mixed deployment Composition of products used together. They all provide standardized data sharding, distributed transactions, and database governance functions, and can be applied to various application scenarios such as Java isomorphism, heterogeneous languages, and cloud native.
ShardingSphere is positioned as a relational database middleware, which aims to fully and reasonably utilize the computing and storage capabilities of relational databases in distributed scenarios, rather than implementing a brand new relational database. It captures the essence of things by focusing on the unchanged. Relational databases still occupy a huge market today and are the cornerstone of the core business of various companies, and they will be difficult to shake in the future. At this stage, we pay more attention to the increase on the original basis rather than subversion. The official Apache release starts with version 4.0.0.
Sub-library and sub-table
The amount of data in the database is not necessarily controllable. Without sub-database sub-tables, with the development of time and business, there will be more and more tables in the database, and the amount of data in the tables will also increase. The larger the value, the correspondingly, the overhead of data operation, addition, deletion, modification and query will also increase; in addition, because distributed deployment cannot be performed, the resources (CPU, disk, memory, IO, etc.) of a server are limited In the end, the data volume and data processing capacity that the database can carry will encounter bottlenecks.
Sub-database sub-table is to solve the problem of database performance degradation due to excessive data volume. The original independent database is split into several databases, and the large data table is split into several data tables, so that a single database and a single data The amount of data in the table becomes smaller, so as to achieve the purpose of improving the performance of the database.
The way of sub-database sub-table
The segmentation of the database refers to the distribution of the data we store in the same database into multiple databases (hosts) through certain specific conditions, so as to achieve the effect of spreading the load of a single device, that is, sub-database sub-table .
Data segmentation can be divided into vertical segmentation and horizontal segmentation according to the type of segmentation rules
- Vertical segmentation: Split a single table into multiple tables and distribute them to different databases (hosts)
- Horizontal segmentation: According to the logical relationship of the data in the table, the data in the table is split into multiple databases according to certain conditions
vertical split
A database consists of multiple tables, and each table corresponds to a different business. Vertical segmentation is to classify the tables according to the business and distribute them to different databases, so that the data is distributed to different databases (special databases) dedicated)
vertical table
Operate a table in the database, save part of the field data in this table into a new table, and then save the other part of the field data in this table into another table
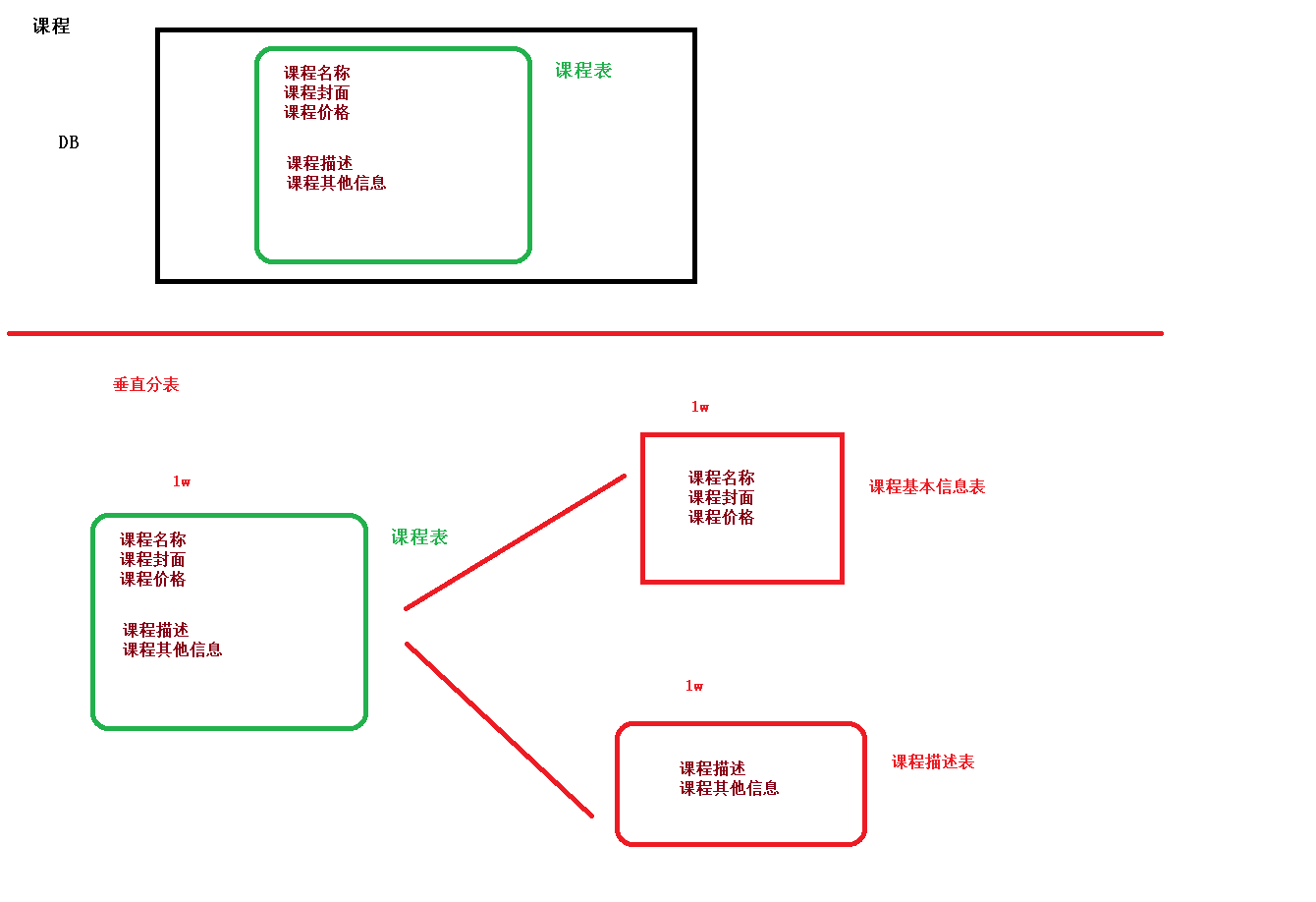
Vertical sub-library
Divide a single database according to business, special database table
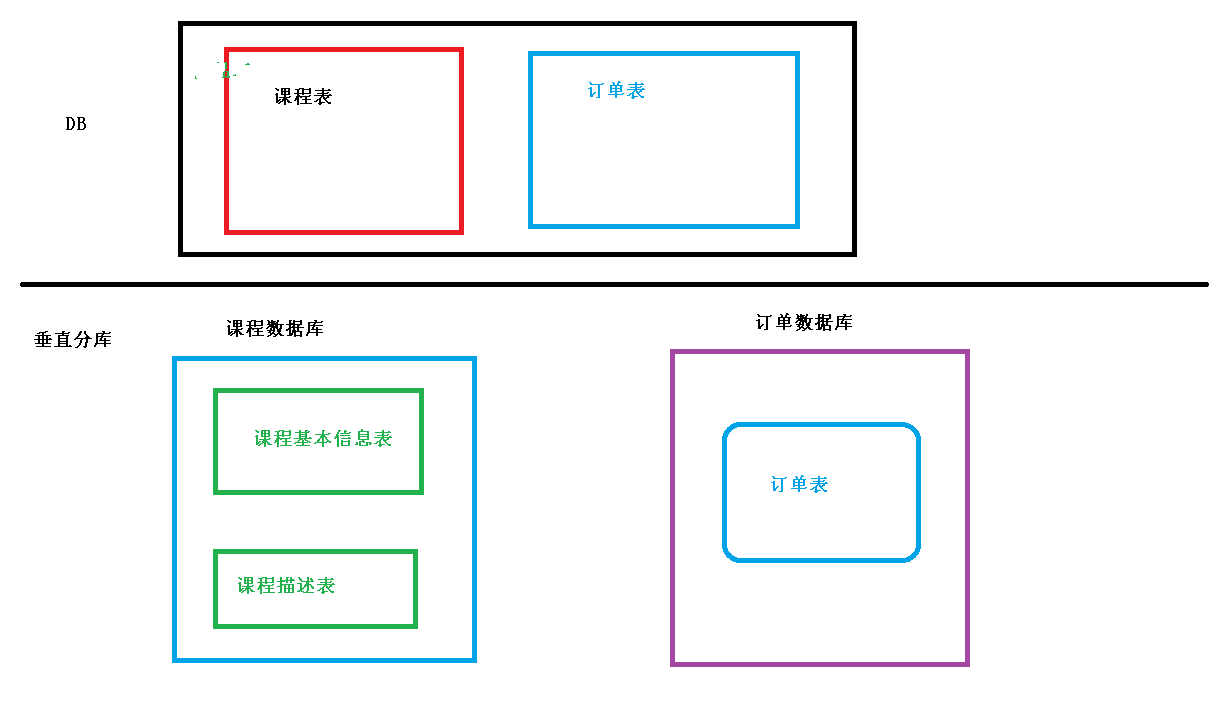
The advantages of vertical splitting are as follows:
-
After the split, the business is clear, and it is easy to integrate or expand between systems.
-
Prize tables are placed on different machines according to cost, application level, application type, etc., which is easy to manage and data maintenance is simple.
The disadvantages of vertical splitting are as follows:
-
Some business tables cannot be associated (Join), and can only be solved through interfaces, which increases the complexity of the system.
-
Due to the different limitations of each business, there is a single-database performance bottleneck, which makes it difficult to expand data and improve performance.
-
Transaction processing becomes complex.
split horizontally
Compared with vertical segmentation, horizontal segmentation does not classify tables, but disperses them into multiple libraries according to a certain rule of a certain field. Each table contains a part of data, and all tables add up to a full amount. data.
To put it simply, we can understand the horizontal splitting of data as splitting according to data rows, that is, splitting some rows in a table into one database table, and splitting other rows into other database tables.
Horizontal sub-library
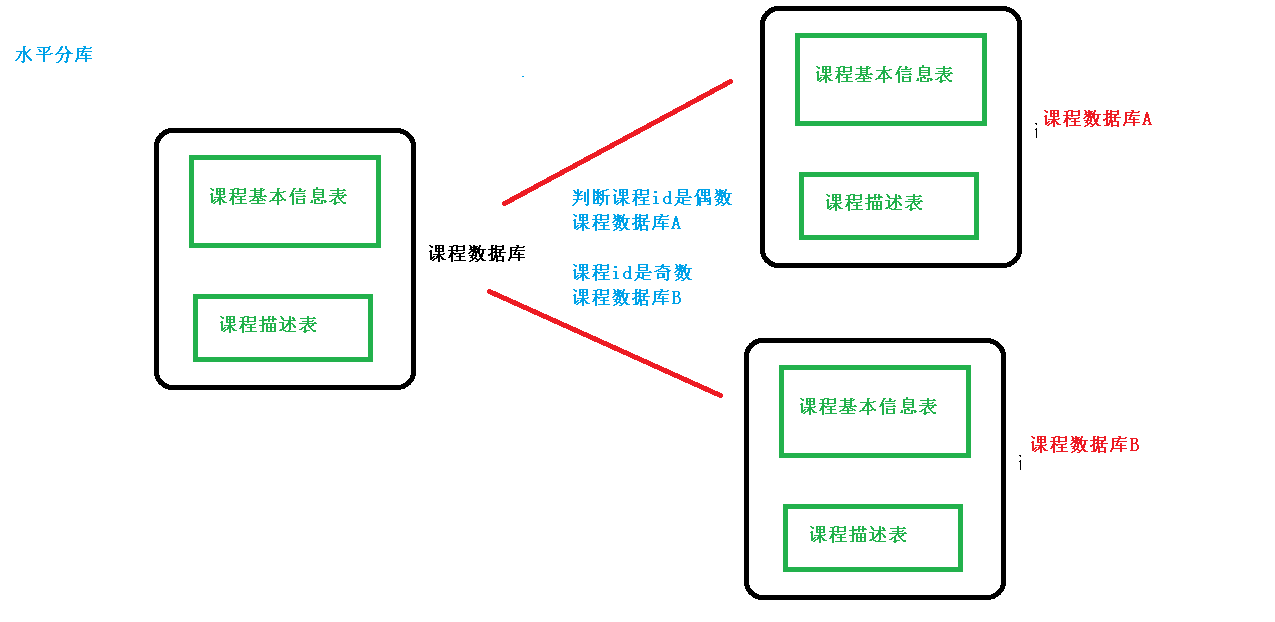
level table

Advantages of splitting horizontally:
-
The data in a single database and single table is kept at a certain level, which helps to improve performance.
-
The structure of the split tables is the same, and the application layer requires less modification, and only needs to add routing rules.
-
Improved system stability and load capacity.
The disadvantages of horizontal splitting are as follows:
-
After splitting, the data is scattered, it is difficult to use the join operation of the database, and the performance of cross-database join is poor.
-
The consistency of fragmented transactions is difficult to solve, and the difficulty and maintenance of data expansion are extremely large.
Problems caused by sub-database and sub-table
- There is a problem of cross-node Join.
- There are problems of cross-node merge sorting and paging.
- There is a problem with multiple data source management
Sub-database and sub-table middleware
At present, there are many middleware for sub-database and sub-table in domestic use, mainly including:
- Apache ShardingSphere
- Mycat
Sharding-JDBC
Sharding-JDBC is an open source distributed database middleware developed by Dangdang. Sharding-JDBC has been included in Sharding-Sphere since version 3.0, and then the project entered the Apache incubator, and versions after version 4.0 are Apache versions. maven coordinates
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
Sharding-JDBC is the first product of ShardingSphere and the predecessor of ShardingSphere. It is positioned as a lightweight Java framework that provides additional services on top of Java's JDBC layer. It uses the client to directly connect to the database and provides services in the form of jar packages without additional deployment and dependencies. It can be understood as an enhanced version of the JDBC driver and is fully compatible with JDBC and various ORM frameworks.
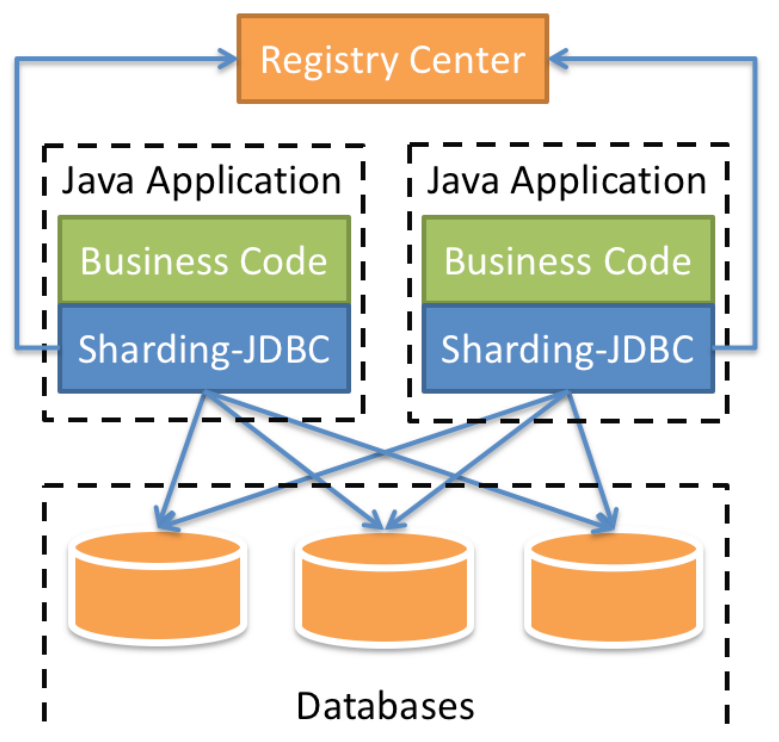
The core function of Sharding-JDBC is data sharding and separation of reading and writing. Through Sharding-JDBC, applications can transparently use jdbc to access multiple data sources that have been divided into databases and tables, and separated from reading and writing, regardless of the number of data sources and How the data is distributed.
- Applicable to any JDBC-based ORM framework, such as: JPA, Hibernate, Mybatis, Spring JDBC Template or use JDBC directly.
- Support any third-party database connection pool, such as: DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
- Any database that implements the JDBC specification is supported. Currently supports MySQL, Oracle, SQLServer, PostgreSQL and any database that follows the SQL92 standard.
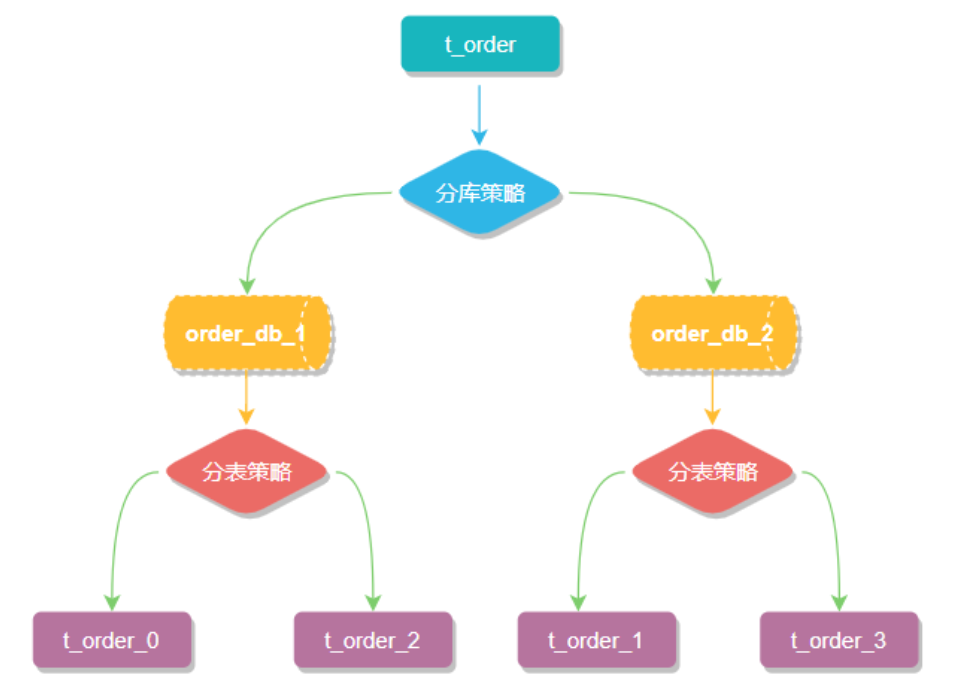
sharding-jdbc implements horizontal table sharding
db script
db: order_db_1
table: t_order_1、t_order_2
CREATE TABLE `t_order_1` (
`id` int NOT NULL,
`order_type` int DEFAULT NULL,
`customer_id` int DEFAULT NULL,
`amount` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;

pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Order
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {
private Integer id;
private Integer orderType;
private Integer customerId;
private Double amount;
}
application.yml
spring:
shardingsphere:
datasource:
# 配置数据源的名称
names: ds1
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
# 打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,SQL语句中写对应的逻辑表
# 如:insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)
# 虽然写的是添加数据到t_order表,实际会根据分表策略路由到t_order_1或t_order_2
t_order:
# 指定t_order表的分布情况,配置表在哪个数据库中,表名称是什么
actual-data-nodes: ds1.t_order_$->{
1..2}
# 指定t_order表里主键id生成策略
key-generator:
column: id
type: SNOWFLAKE
# 指定分片策略。根据id的奇偶性来判断插入到哪个表
table-strategy:
inline:
algorithm-expression: t_order_${
id%2+1}
sharding-column: id
proficiency test
@SpringBootTest(classes = ShardingJdbcApplication.class)
public class OrderTest {
@Autowired
private JdbcTemplate jdbcTemplate;
@Test
public void testSave() {
String saveSQL = "insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)";
ArrayList<Order> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Order(i, i, i,1000.0*i));
}
jdbcTemplate.batchUpdate(saveSQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
Order order = list.get(i);
preparedStatement.setInt(1,order.getId());
preparedStatement.setInt(2,order.getOrderType());
preparedStatement.setInt(3,order.getCustomerId());
preparedStatement.setDouble(4,order.getAmount());
}
@Override
public int getBatchSize() {
return list.size();
}
});
}
@Test
public void getOrder() {
String querySQL = "select * from t_order";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class));
orders.forEach(System.out::println);
}
}
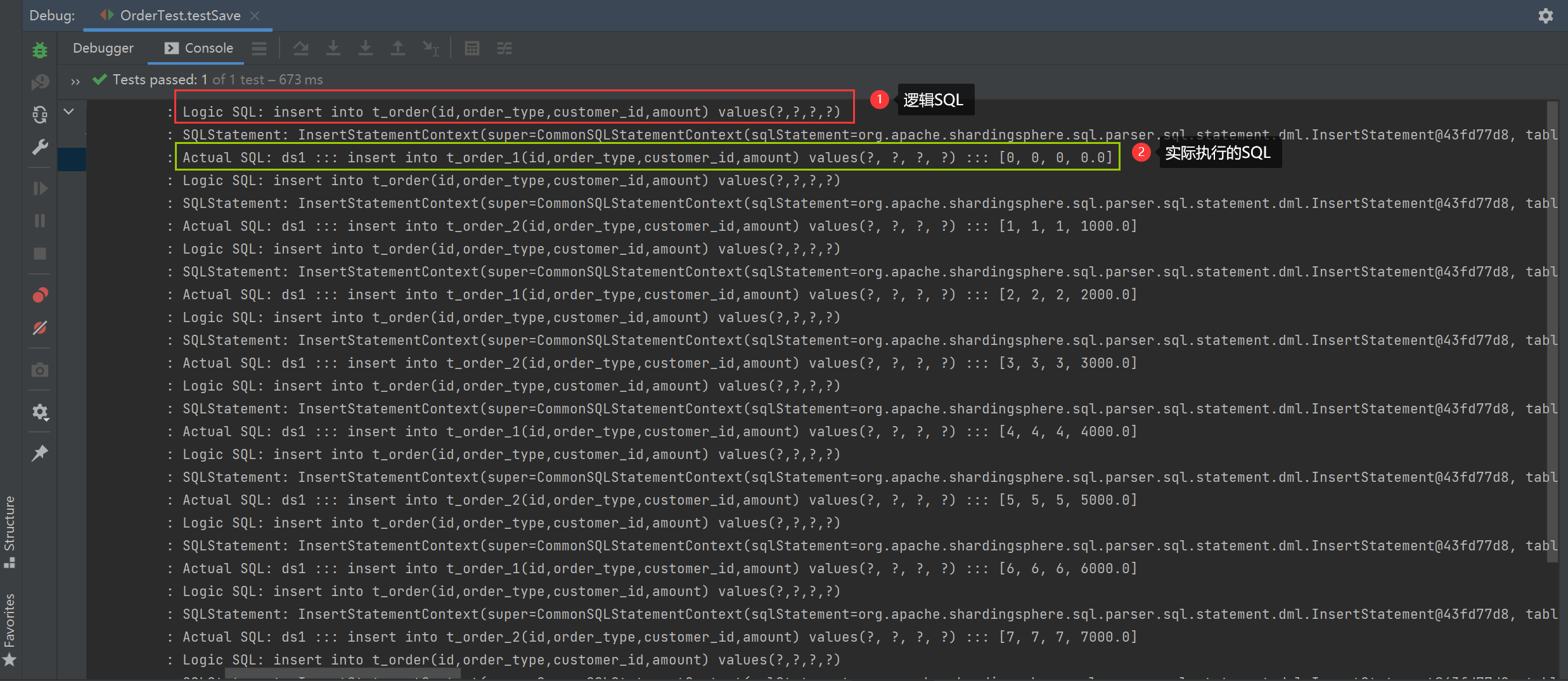
1. Execution result of testSave() method
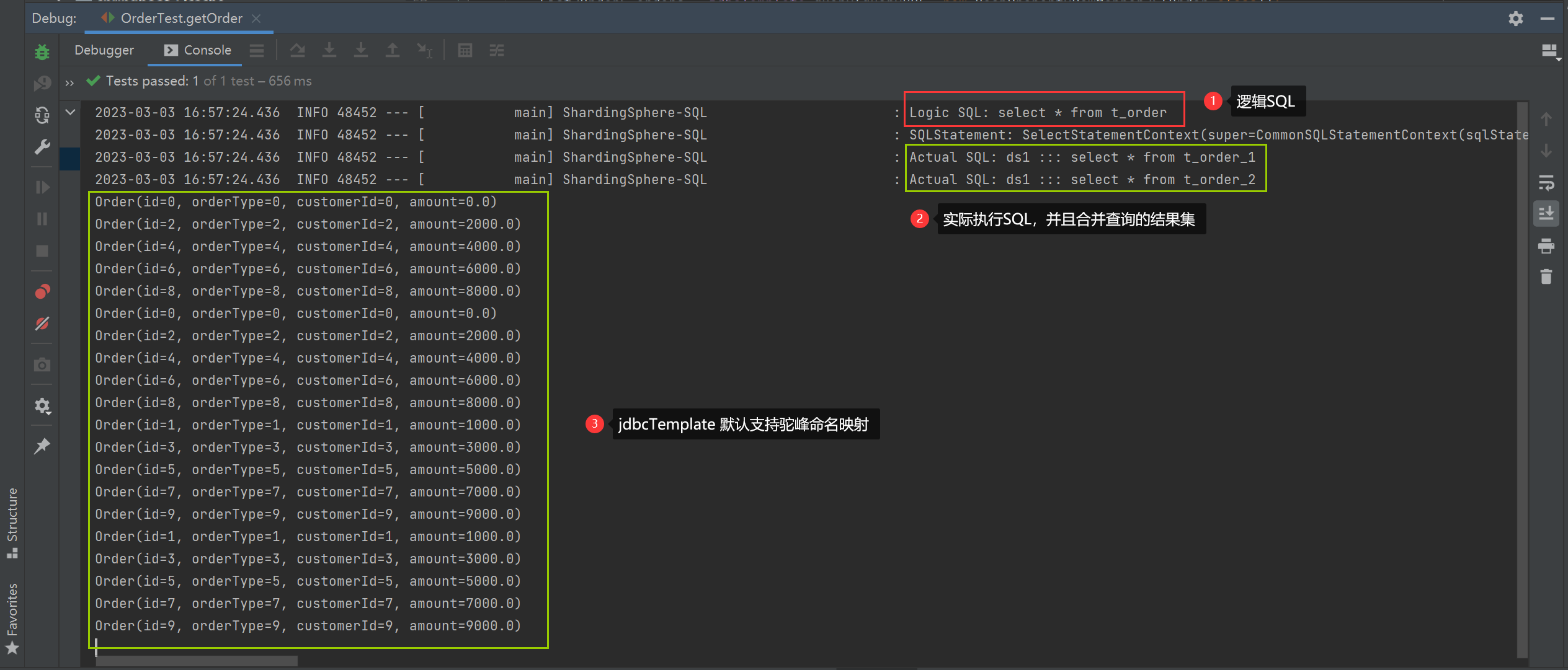
2. Execution result of getOrder method
sharding-jdbc implements horizontal database sharding
db

application.yml
spring:
shardingsphere:
datasource:
# 配置不同的数据源
names: ds1,ds2
#配置ds1数据源的基本信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#配置ds2数据源的基本信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_2?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,必须配置正确,如:分表t_order_1,t_order_2,则逻辑表为 t_order
t_order:
#指定数据库表的分布情况
actual-data-nodes: ds$->{
1..2}.t_order_$->{
1..2}
#指定库分片策略,根据customer_id的奇偶性来添加到不同的库中,customer_id为基数路由到ds2,customer_id为偶数路由到ds1
database-strategy:
inline:
sharding-column: customer_id
algorithm-expression: ds$->{
customer_id%2+1}
#指定t_order表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
#指定表分片策略,根据id的奇偶性来添加到不同的表中,id为基数路由到ds2,id为偶数路由到ds1
table-strategy:
inline:
sharding-column: id
algorithm-expression: t_order_$->{
id%2+1}
Routing Test Verification
No routing key specified
/**
* 不指定路由键,扫描全库全表查询汇总,效率低
*/
@Test
public void getOrder() {
String querySQL = "select * from t_order";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class));
orders.forEach(System.out::println);
}
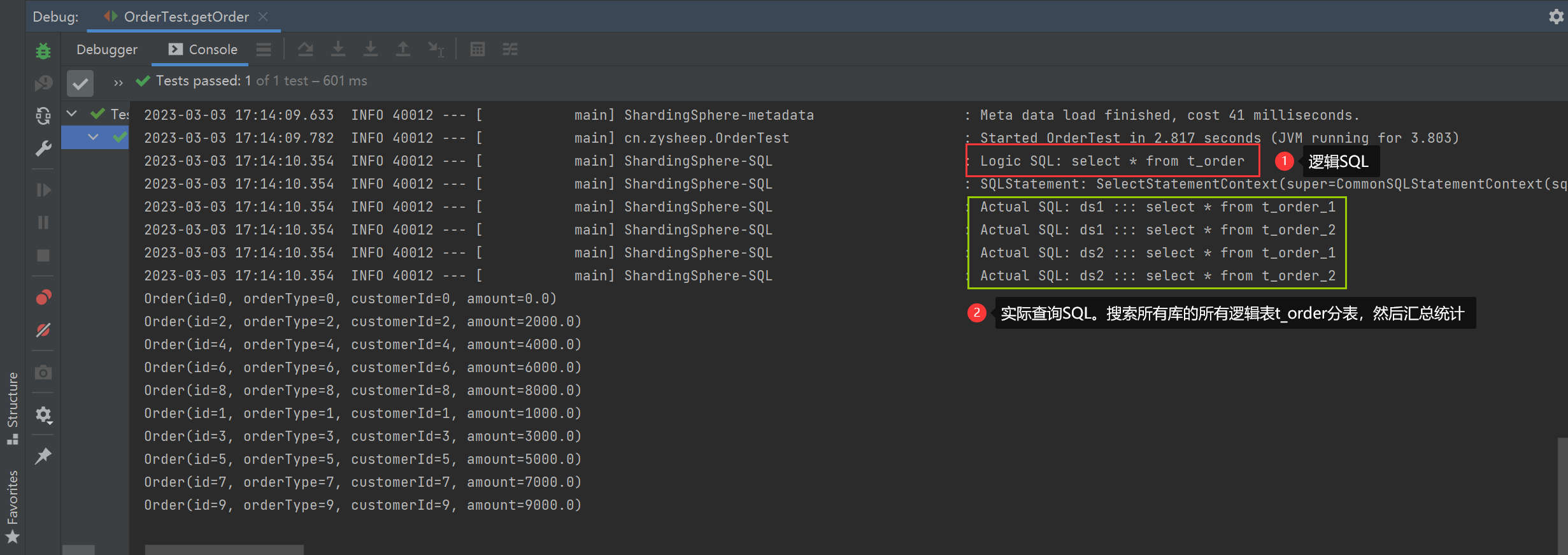
Specify library routing key
/**
* 指定库路由键
*/
@Test
public void getOrderByCustomerId() {
String querySQL = "select * from t_order where customer_id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2);
orders.forEach(System.out::println);
}
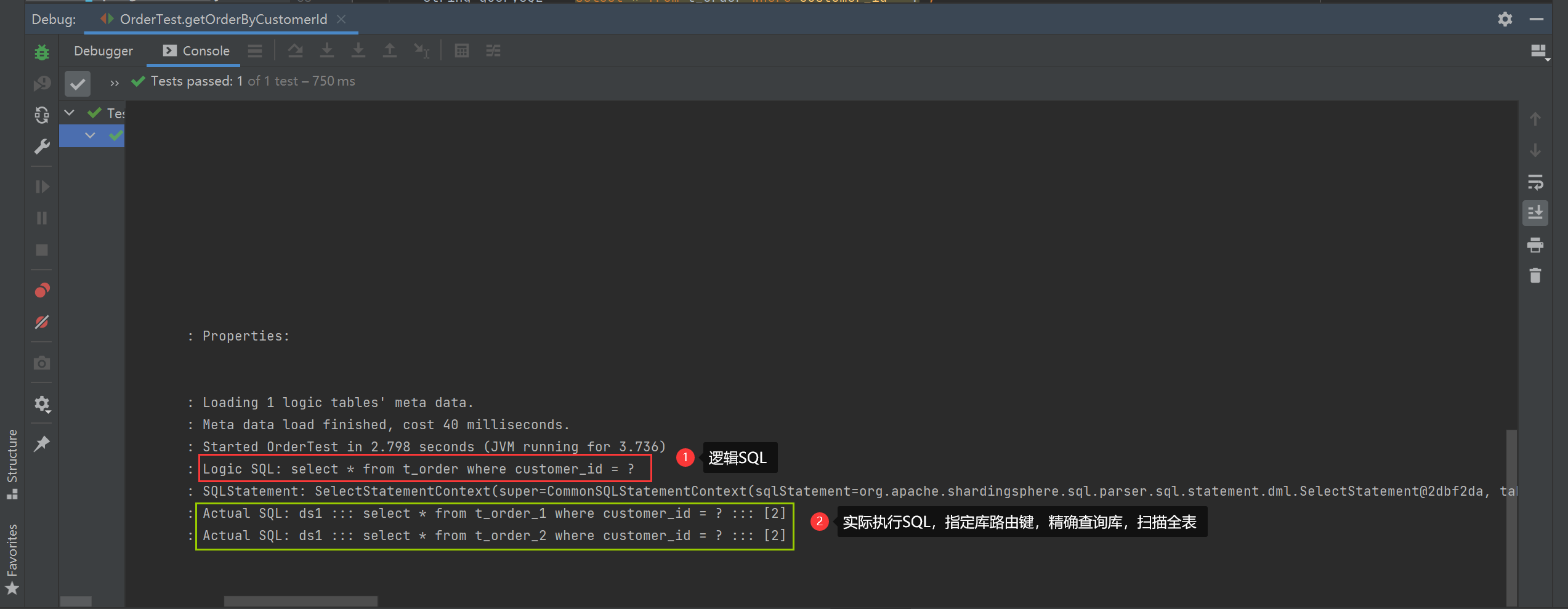
specify table routing key
/**
* 指定表路由键
*/
@Test
public void getOrderById() {
String querySQL = "select * from t_order where id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2);
orders.forEach(System.out::println);
}
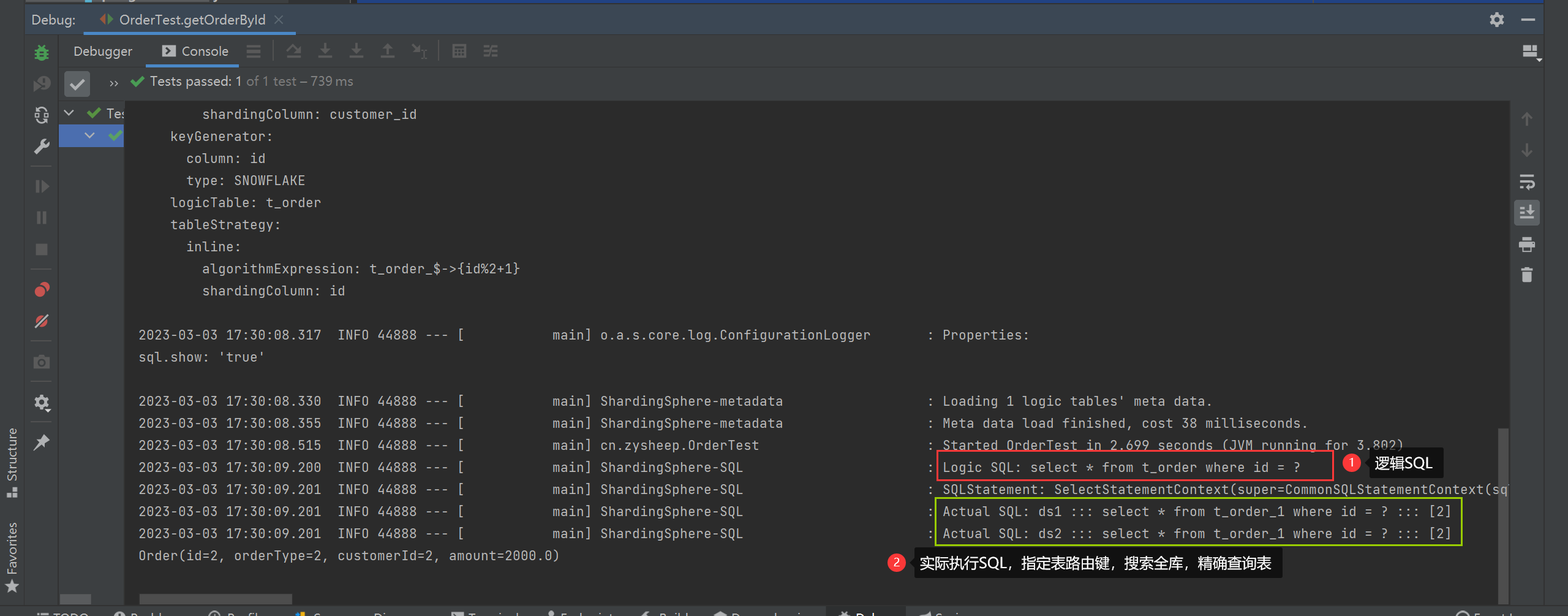
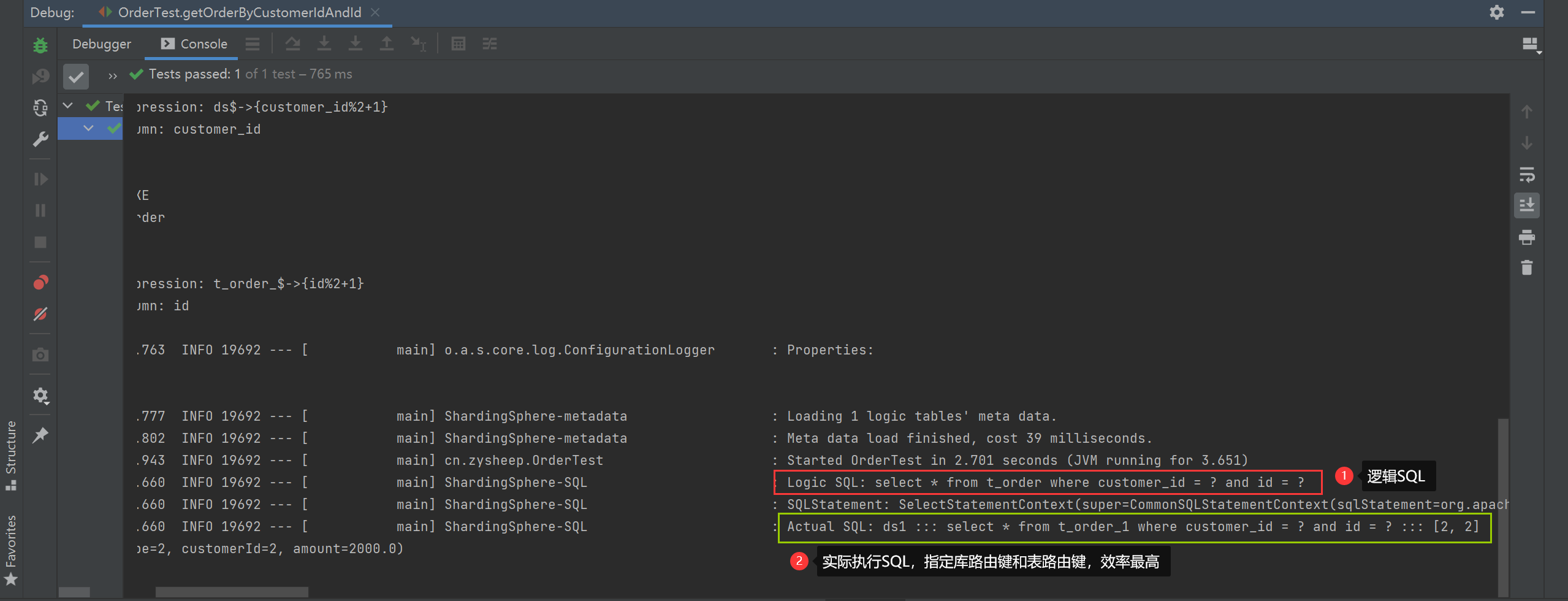
Specify library routing key and table routing key
/**
* 指定库路由键和表路由键 效率最高
*/
@Test
public void getOrderByCustomerIdAndId() {
String querySQL = "select * from t_order where customer_id = ? and id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2,2);
orders.forEach(System.out::println);
}
sharding-jdbc implements vertical database sharding
Create the same library order_db_1 on different data nodes.
I have a local database, and the virtual machine uses docker to start a database
db
docker pull mysql:5.7
docker run -d -p 3306:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci


application.yml
spring:
shardingsphere:
datasource:
# 配置不同的数据源
names: ds1,ds2
#配置ds1数据源的基本信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#配置ds2数据源的基本信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.56.10:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: 123456
#打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,必须配置正确
customer:
#配置customer表所在的数据节点
actual-data-nodes: ds2.customer
#指定orders表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
#指定表分片策略
table-strategy:
inline:
sharding-column: id
algorithm-expression: customer
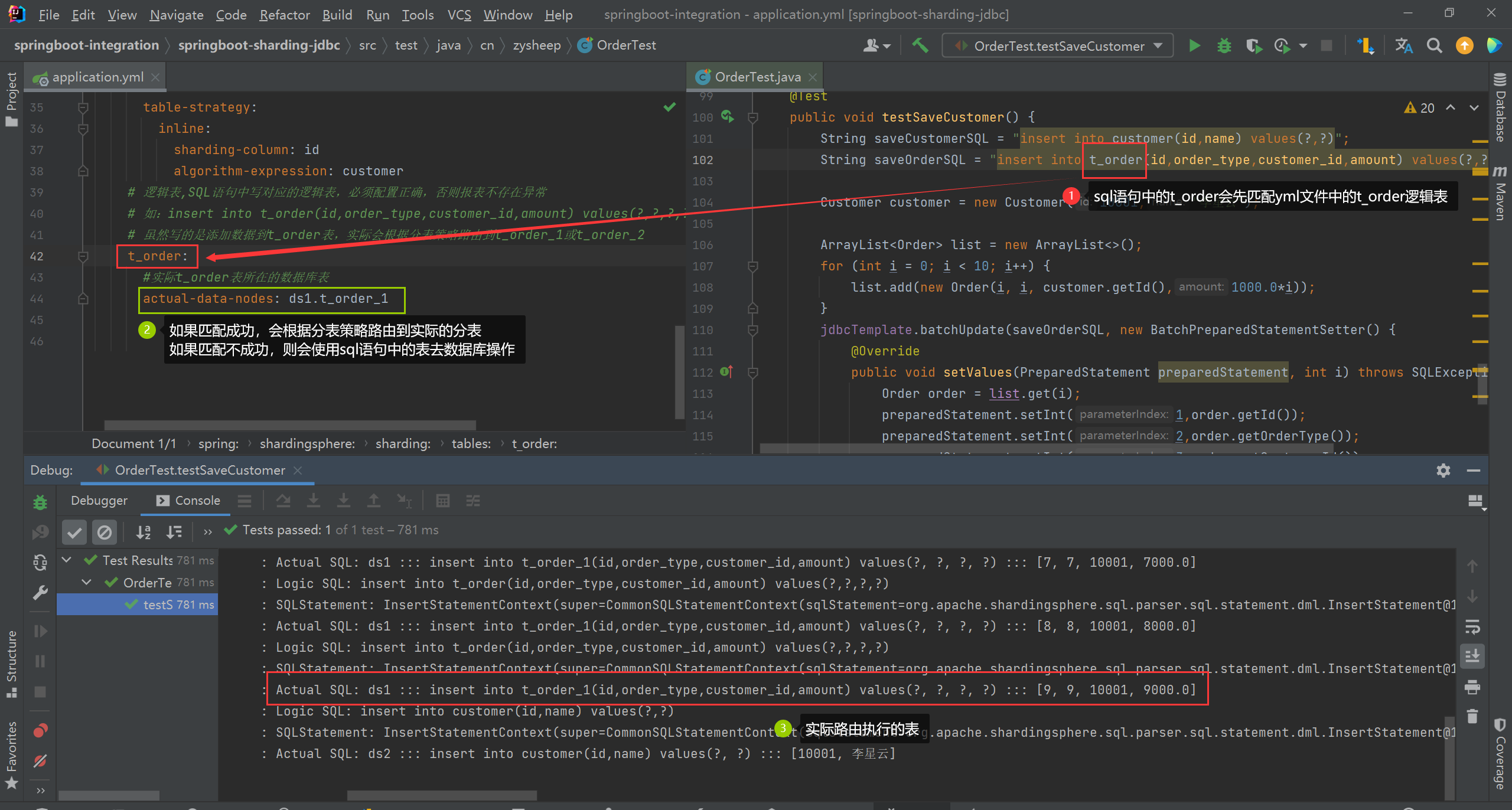
# 逻辑表,SQL语句中写对应的逻辑表,必须配置正确,否则报表不存在异常
# 如:insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)
# 虽然写的是添加数据到t_order表,实际会根据分表策略路由到t_order_1或t_order_2
t_order:
#实际t_order表所在的数据库表
actual-data-nodes: ds1.t_order_1
Test the vertical sharding strategy
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Customer {
private Integer id;
private String name;
}
/**
* 测试垂直分库
*/
@Test
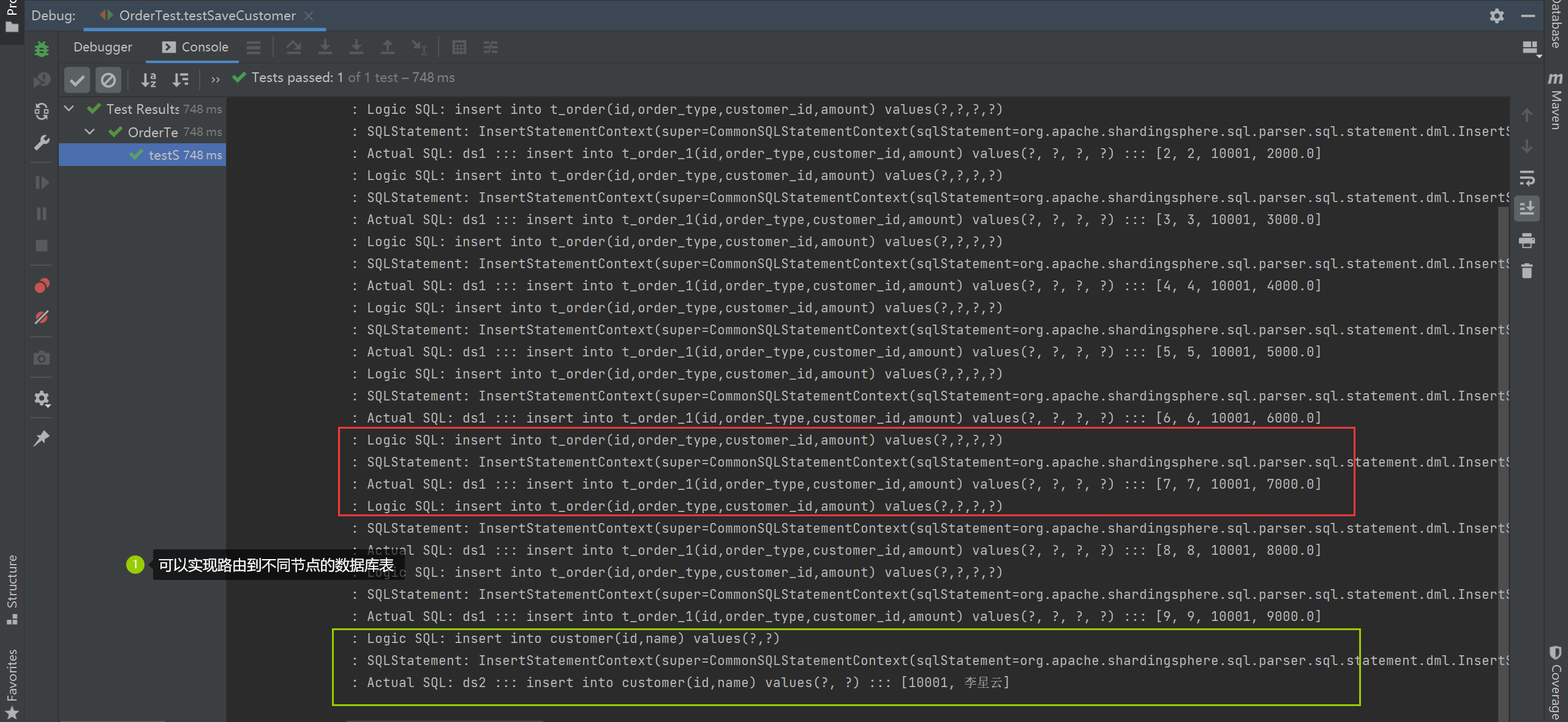
public void testSaveCustomer() {
String saveCustomerSQL = "insert into customer(id,name) values(?,?)";
String saveOrderSQL = "insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)";
Customer customer = new Customer(10001,"李星云");
ArrayList<Order> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Order(i, i, customer.getId(),1000.0*i));
}
jdbcTemplate.batchUpdate(saveOrderSQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
Order order = list.get(i);
preparedStatement.setInt(1,order.getId());
preparedStatement.setInt(2,order.getOrderType());
preparedStatement.setInt(3,order.getCustomerId());
preparedStatement.setDouble(4,order.getAmount());
}
@Override
public int getBatchSize() {
return list.size();
}
});
jdbcTemplate.update(saveCustomerSQL, preparedStatement -> {
preparedStatement.setInt(1,customer.getId());
preparedStatement.setString(2, customer.getName());
});
}
Summary of sub-database and sub-table
1. When using sharding-jdbc for sub-database and sub-table, it is most efficient to specify the corresponding library routing key and table routing key according to the rules, so the routing key can be set as the index of the corresponding table to improve query efficiency. If it is really impossible to set two routing keys during development, try to set one to avoid scanning the entire database and tables. low efficiency
2. Regarding the configuration of spring.shardingsphere.sharding.tables.(logical table).actual-data-nodes=ds1.t_order_1, the
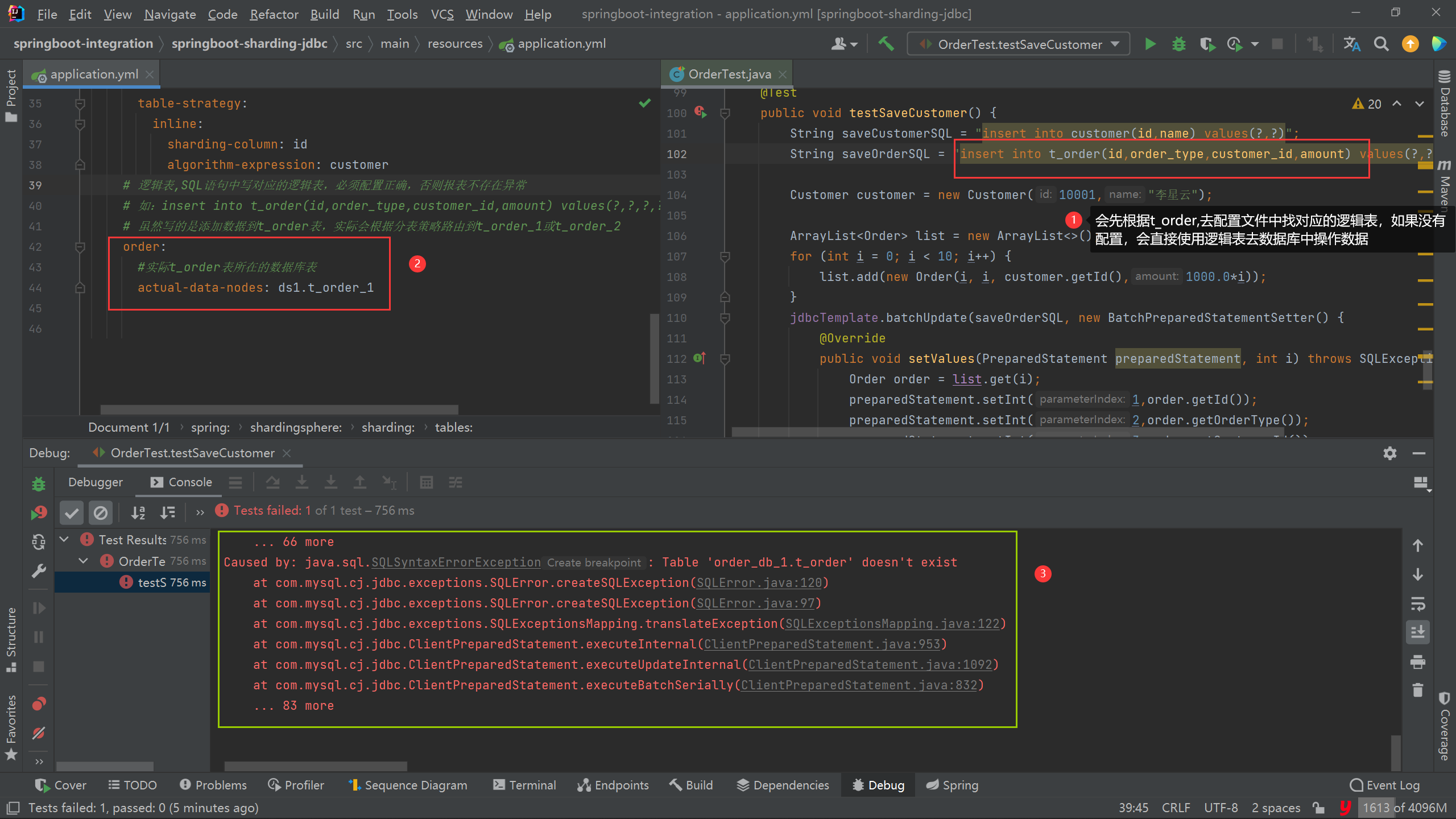
correct logical table routing configuration should be: