Table of contents
(3) Front and rear pointer method (recommended)
(1) Take the middle of the three numbers
(2) Inter-cell optimization (the complete code of recursion is here!!!)
Three: non-recursive quick sort
Complete sorting (non-recursive full code here!!!)
Foreword:
The sorting in this article is in ascending order, descending order and vice versa
swap sort
Basic idea: The so-called exchange is to swap the positions of the two records in the sequence according to the comparison result of the key values of the two records in the sequence .The characteristic of exchange sorting is: the data with larger key value is moved to the end of the sequence, and the data with smaller key value is moved .Bubble sort and quick sort are exchange sorts.
One: bubble sort
basic idea
1. From the first element to the last element, repeat the following steps:
2. Each time two adjacent elements are compared, if the first element is greater than the second element, their positions are exchanged ;
3. After one round of traversal, the last element must be the largest element in the current unsorted part, so the number of comparisons in the next round of traversal can be reduced ;
4. Repeat the above steps until all elements are arranged in ascending order.
full sort
code:
//冒泡排序 void BubbleSort(int* a, int n) { int i = 0; int j = 0; for (i = 0; i < n; i++) { //设计一个标志,如果没有进入循环说明后面已经有序,跳出循环 int exchange = 0; for (j = 1; j < n - i; j++) { if (a[j] < a[j - 1]) { swap(&a[j], &a[j - 1]); exchange = 1; } } if (exchange == 0) { break; } } }Illustration:
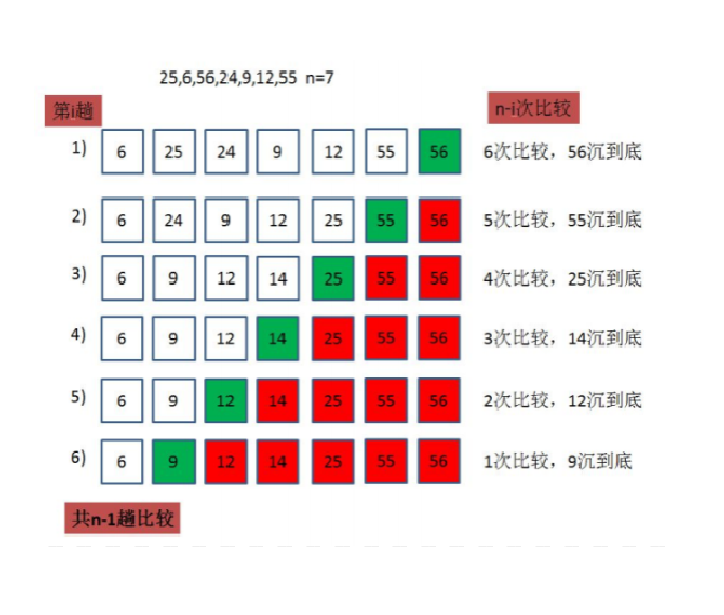
Time Complexity Analysis
In the process of bubble sorting, n-1 traversals are required
Each traversal needs to compare two adjacent elements and possibly exchange positions, that is to say, each traversal will fix the position of a largest (smaller) element, so it needs to traverse at most n-1 times, and each traversal needs to compare at most n -1 time.
So the number of comparisons is: (n-1) + (n-2) + ... + 2 + 1 = n(n-1)/2
So the time complexity is O(n^2).
It should be noted that in the best case, that is, all elements have been arranged in ascending order, and the positions of all elements can be determined during the first traversal, so only one traversal is required, and the time complexity is O(n);
In the worst case, that is, all elements have been arranged in descending order, comparison and exchange are required for each traversal, and the time complexity is O(n^2).
Two: recursive quick sort
basic idea
1. Select a reference value (key) to divide the array or sequence into two parts.
2. Place elements smaller than the reference value on the left side of the reference value, elements greater than the reference value on the right, and elements equal to the reference value can be placed on the left or right.
3. Recursively sort the left and right sides until the sort is complete.
(In simple terms, the core idea of quick sorting is to put each piece of data where it belongs )
single pass sort
Let's look at the following array:
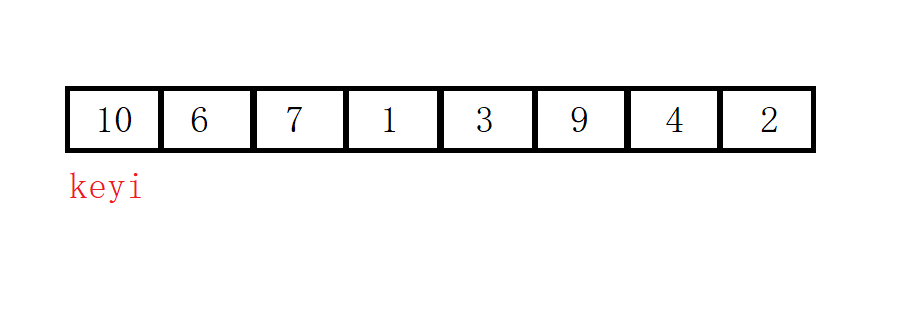
We select the leftmost data as the reference value key (the selection of the key is not stipulated, it can be done according to individual needs), and we adopt the method of exchanging instead of overwriting, and we save the subscript keyi of the key. If the method of overriding is used, we save the value key .
To move all the values smaller than the key to the left, and all the values larger than the key to the right (it doesn't matter if they are equal), we have three methods in total.
After the single sorting is completed, we need to let the program know that the position of the data has been determined, so each group of methods must finally return the determined position subscript.
(1) Two-way scanning method
Basic idea:
① Select a reference value (key), scan from left to right and from right to left
② Swap the elements smaller than the reference value to the left, and the elements larger than the reference value to the right until the two scans meet
③ Finally , insert the reference value between the left and right sides
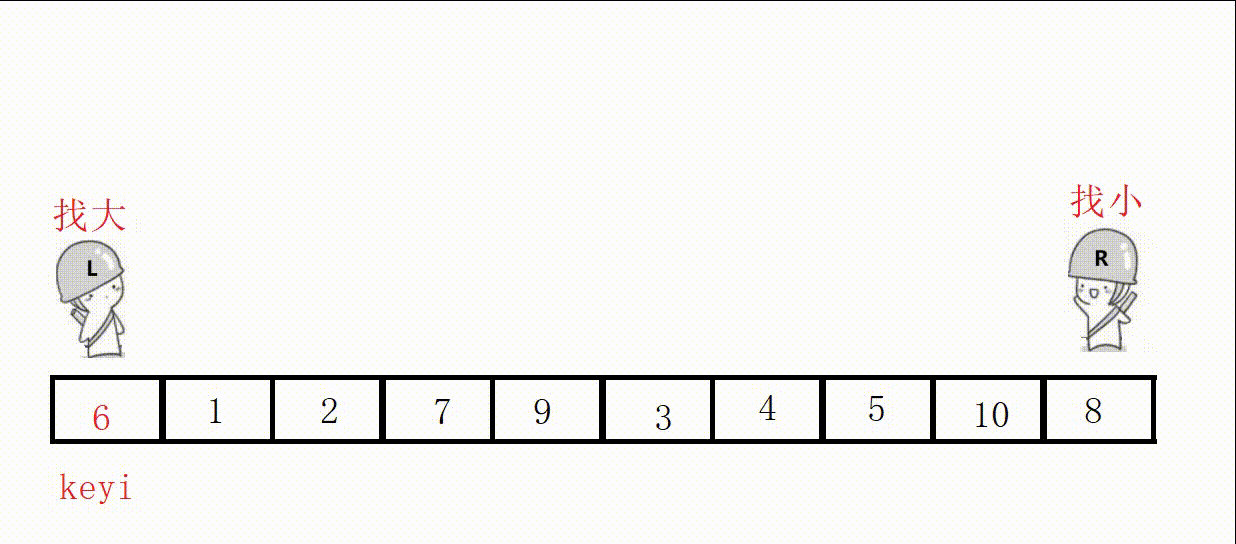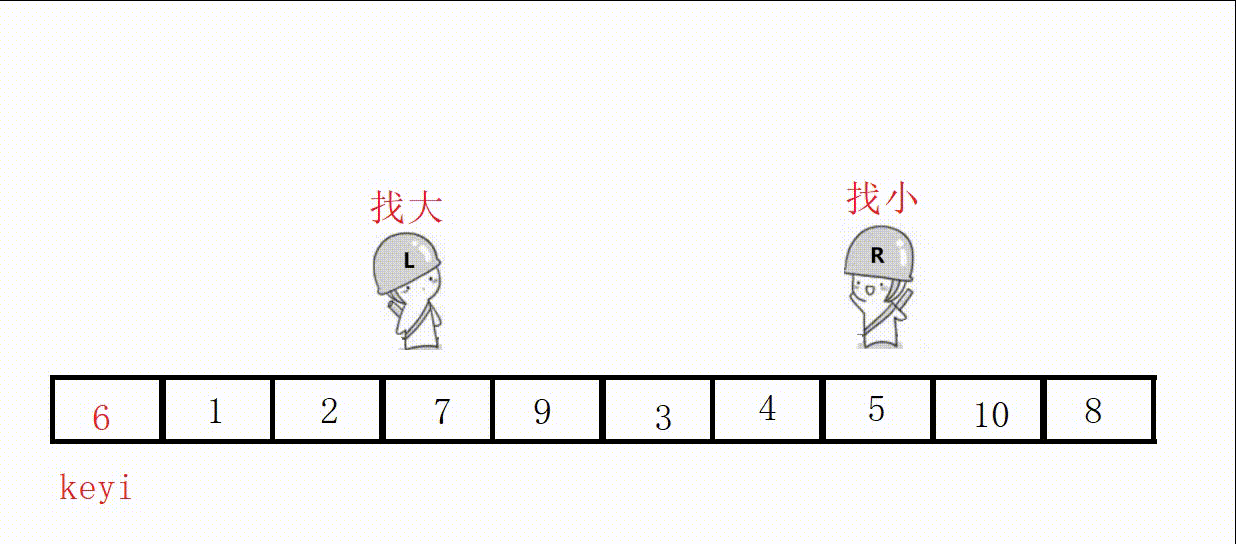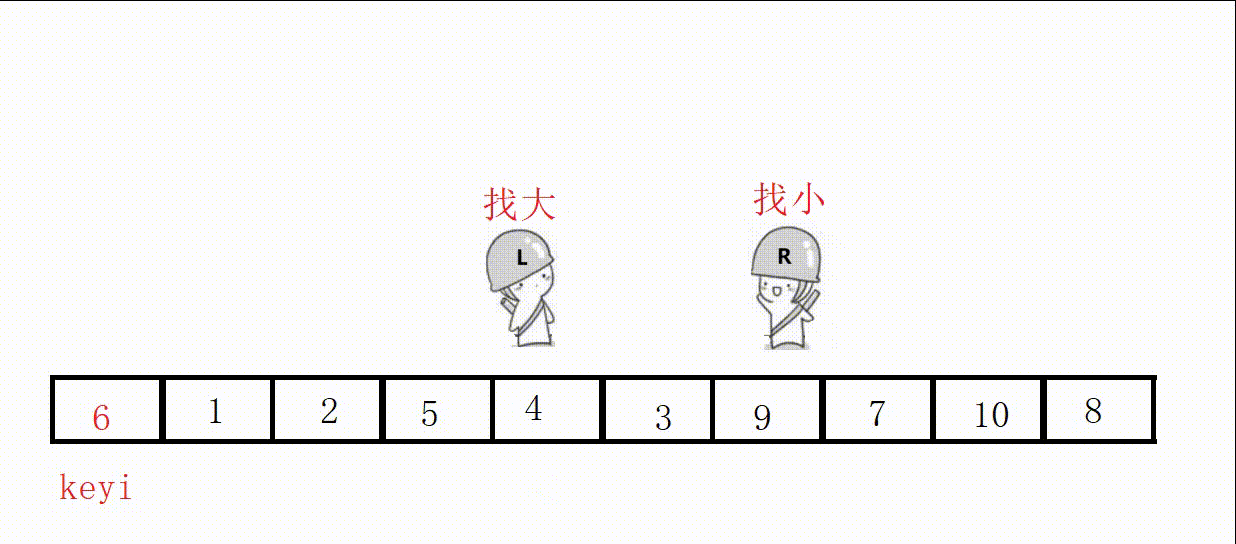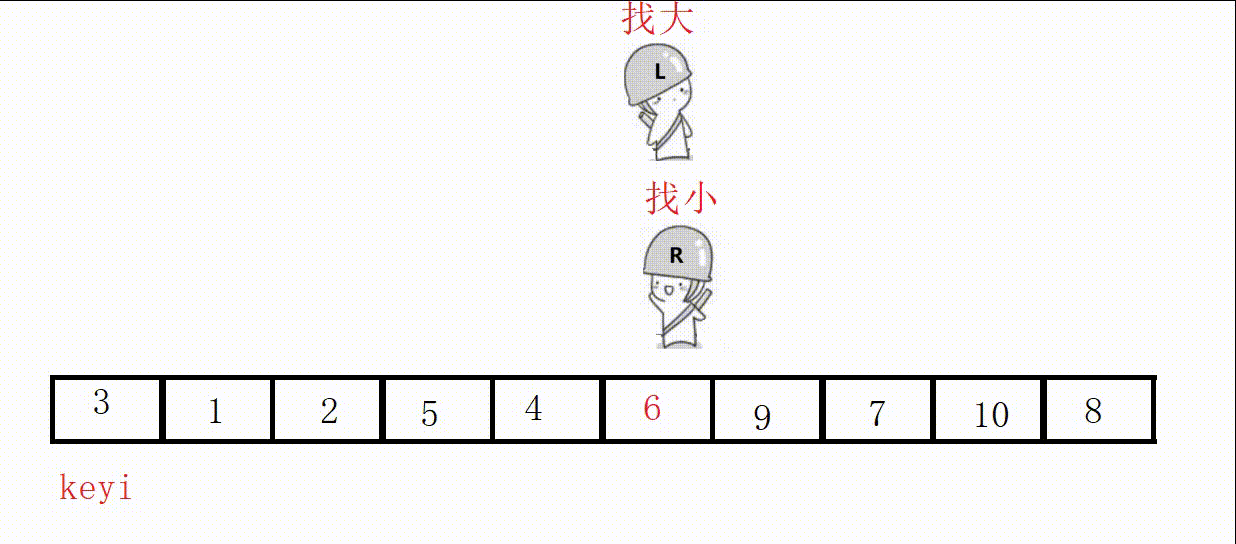
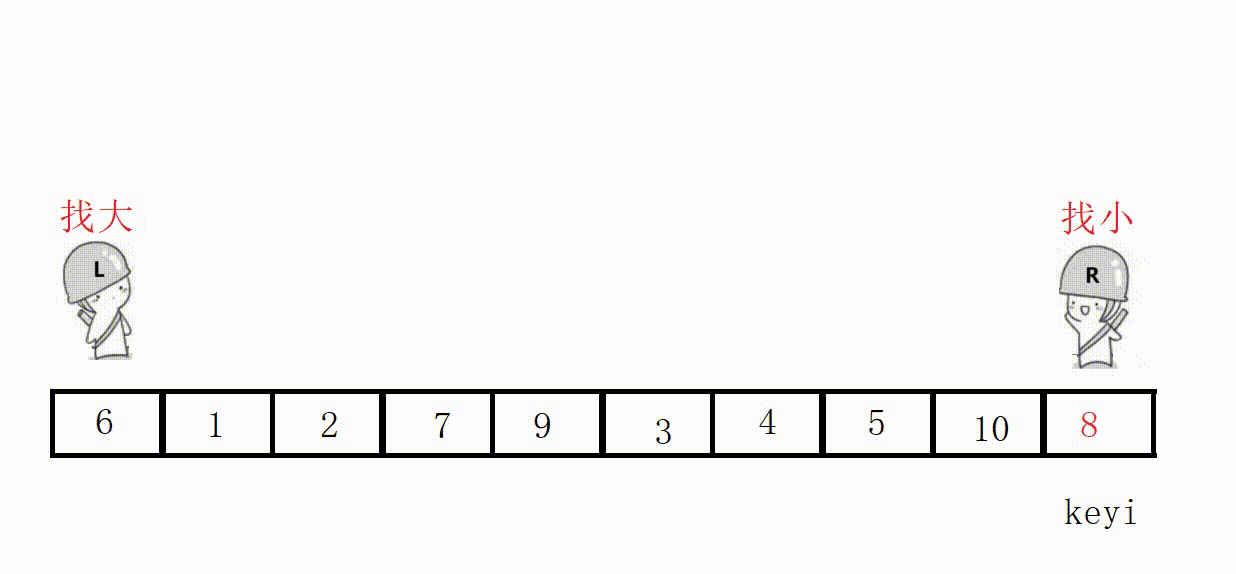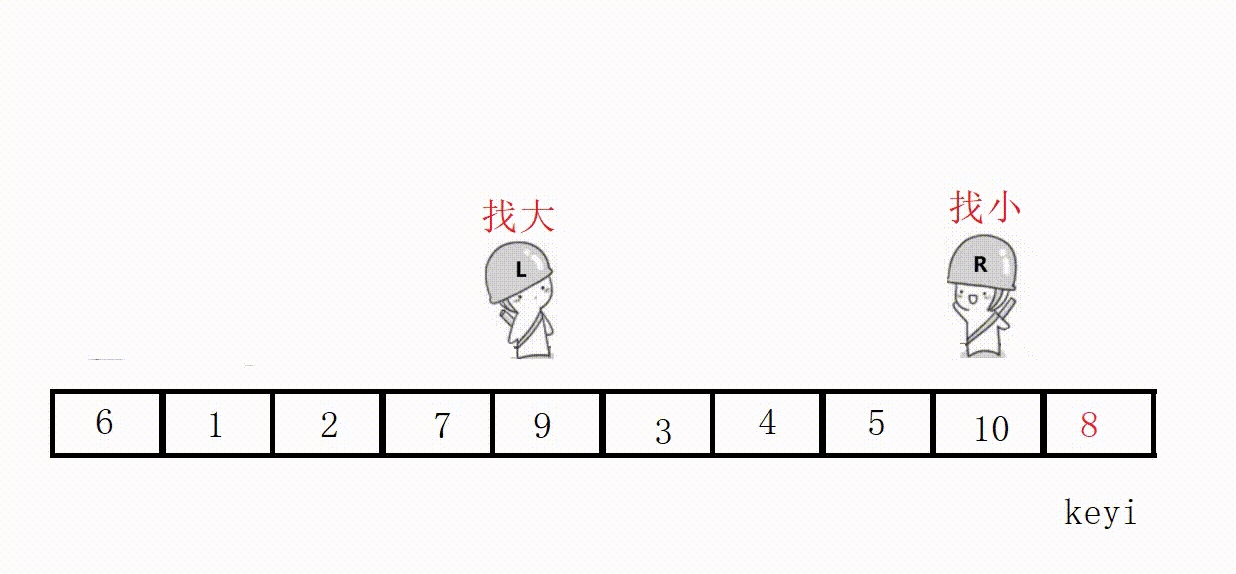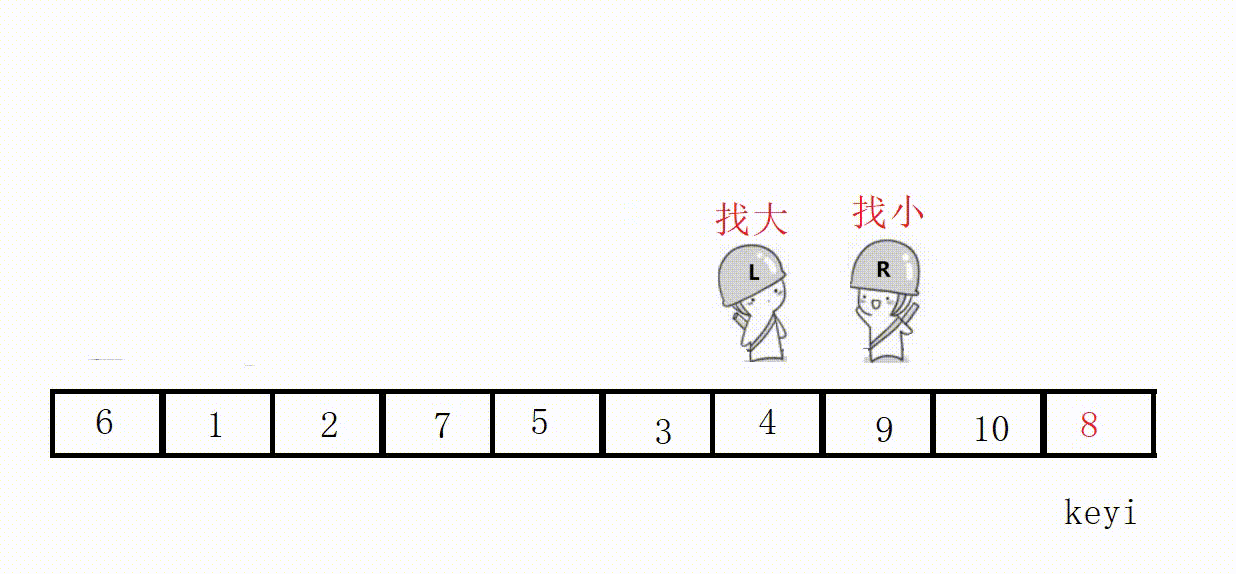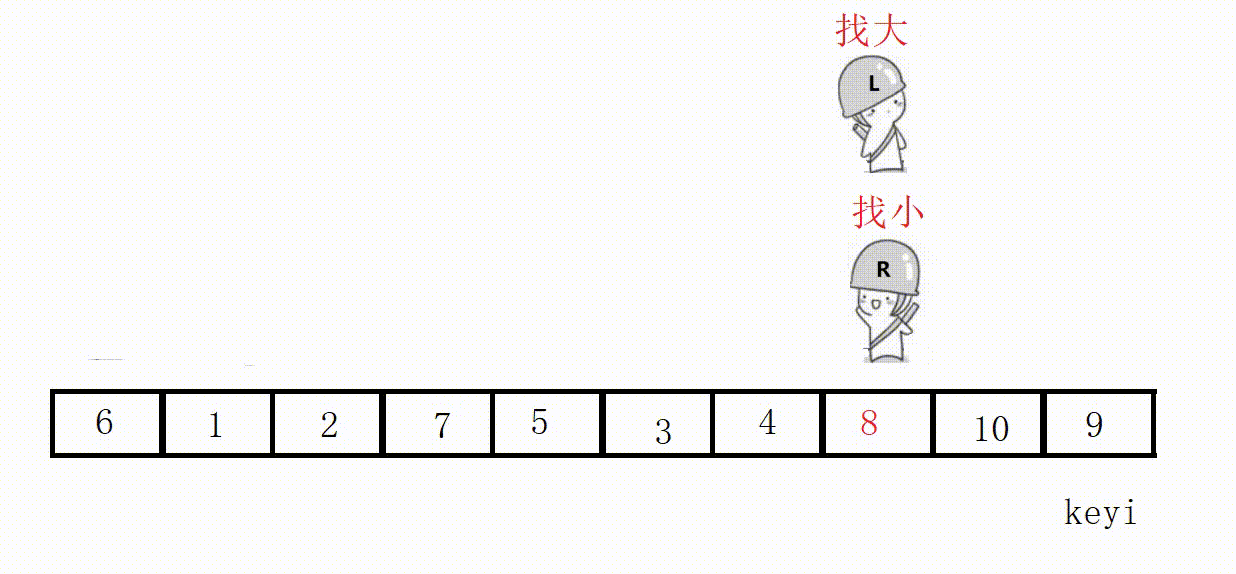
Choose the leftmost as the key, and start from the right first, so as to ensure that the position value of the last encounter is smaller than the key .
Illustration:
On the contrary, choose the right side as the key, and start from the left side first, which can ensure that the meeting position is greater than the key
Illustration:
Code (here the leftmost is selected as the key):
//单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; }
(2) digging method
Basic idea:
① Select a reference value (key), design a variable pivot to record the pit position, the initial value of the pit position is the same as the key subscript, and scan from left to right and from right to left
②Exchange the elements smaller than the reference value to the left pit to form a new pit by itself; swap the elements greater than the reference value to the right pit to form a new pit by itself until the two scans meet
③ Finally, insert the reference value between the left and right sides
Unlike before, the digging method will overwrite the data, and we choose to save the value instead of the subscript .
Choose the leftmost as the key, and start from the right first.
Illustration:
Instead, choose the right side as the key, and the left side starts first.
Illustration:
code:
//挖坑法单趟 int partion2(int* a, int left, int right) { int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; }
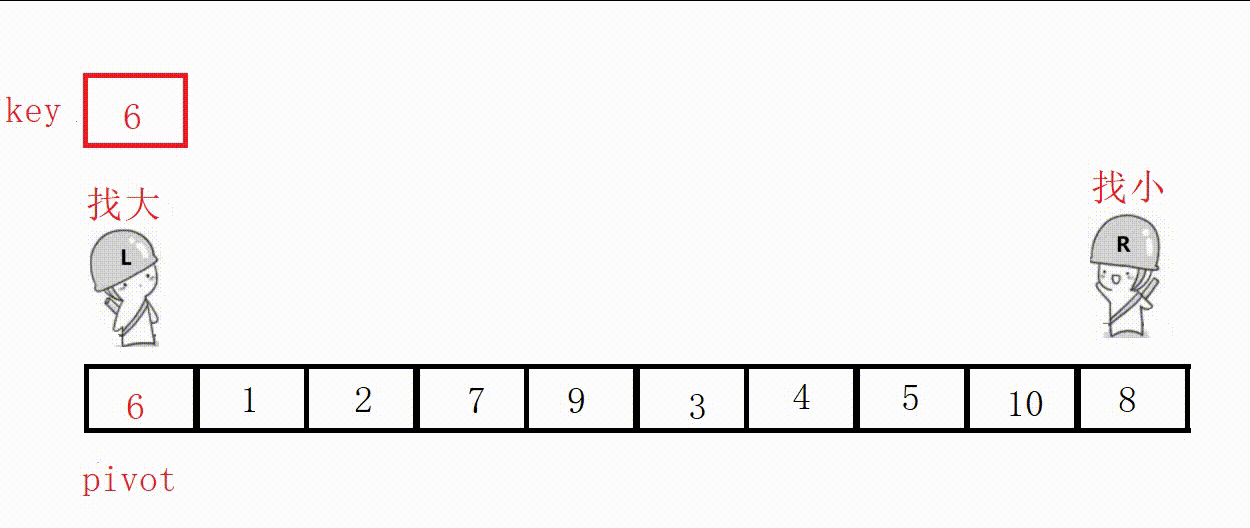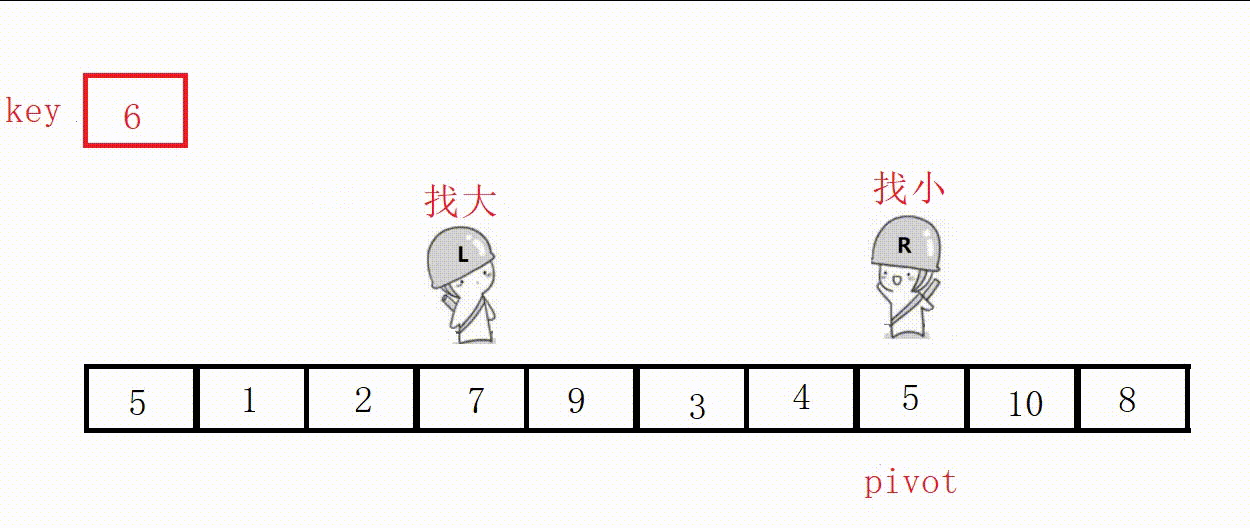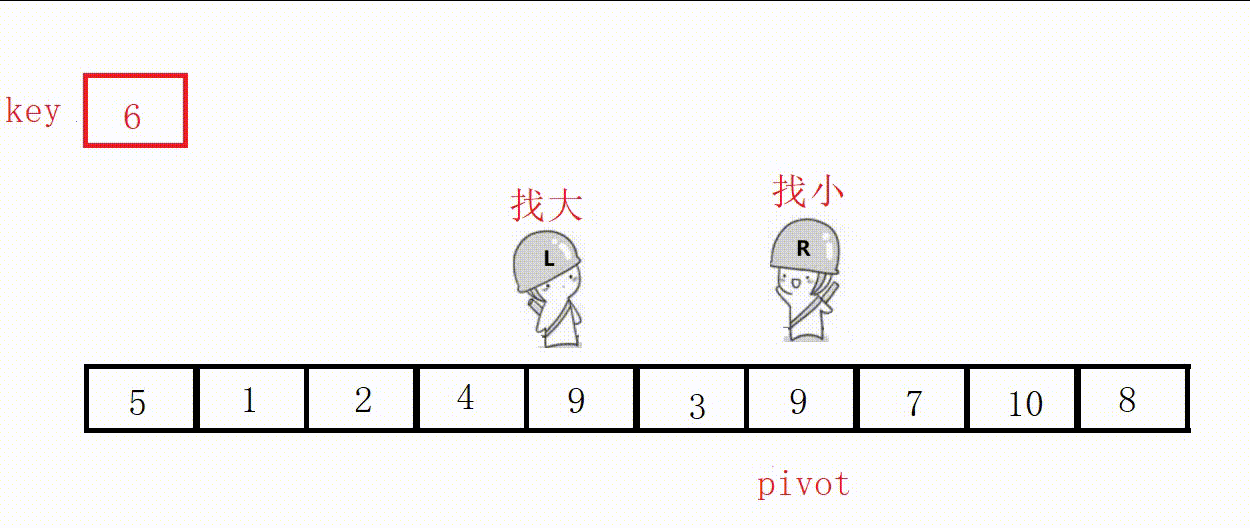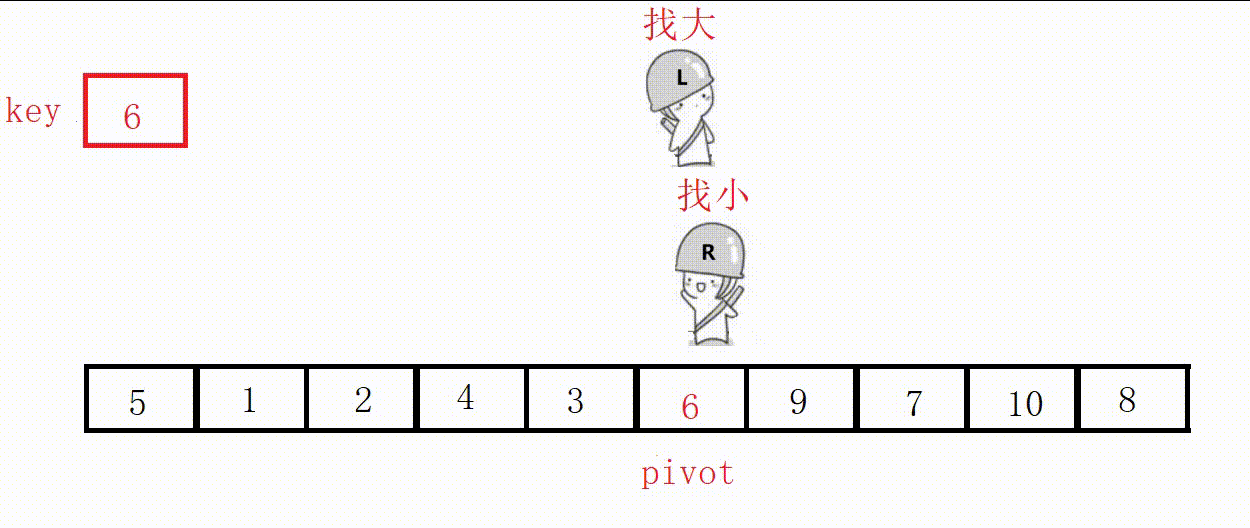
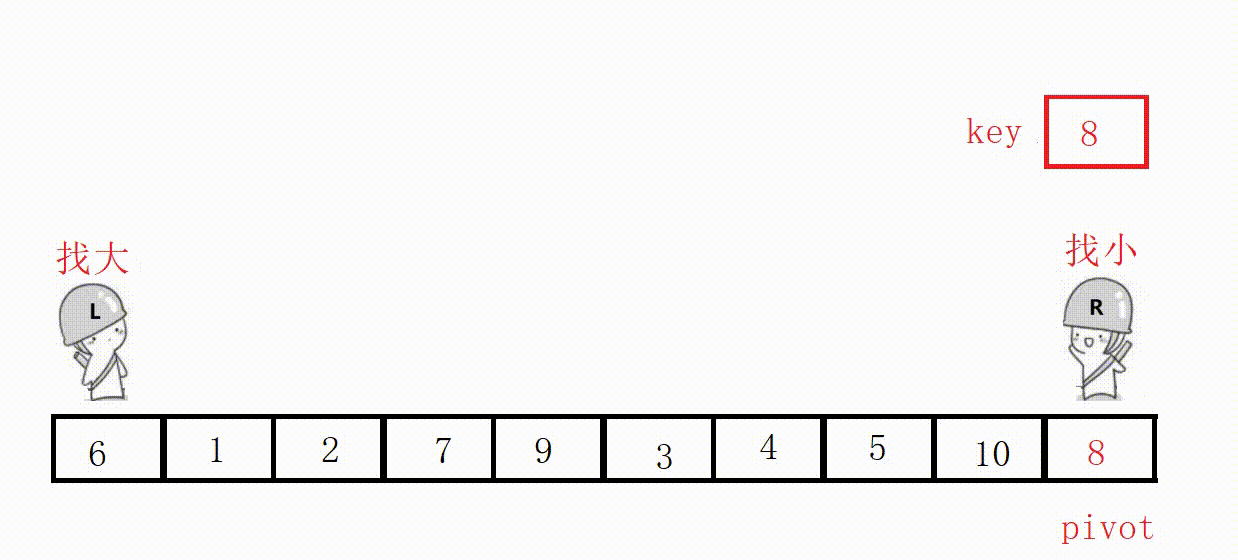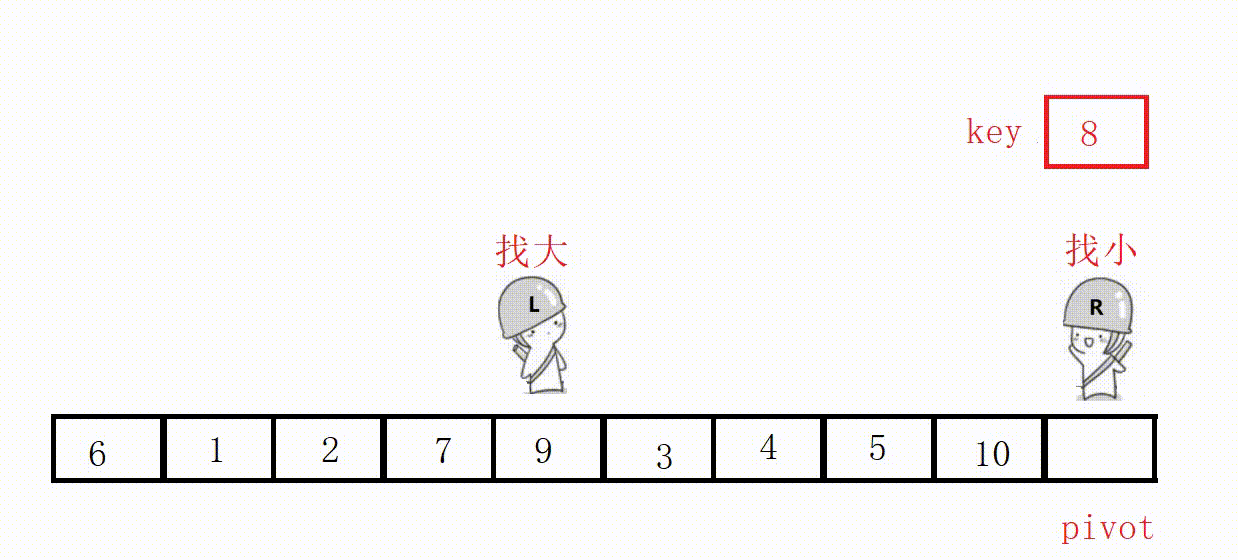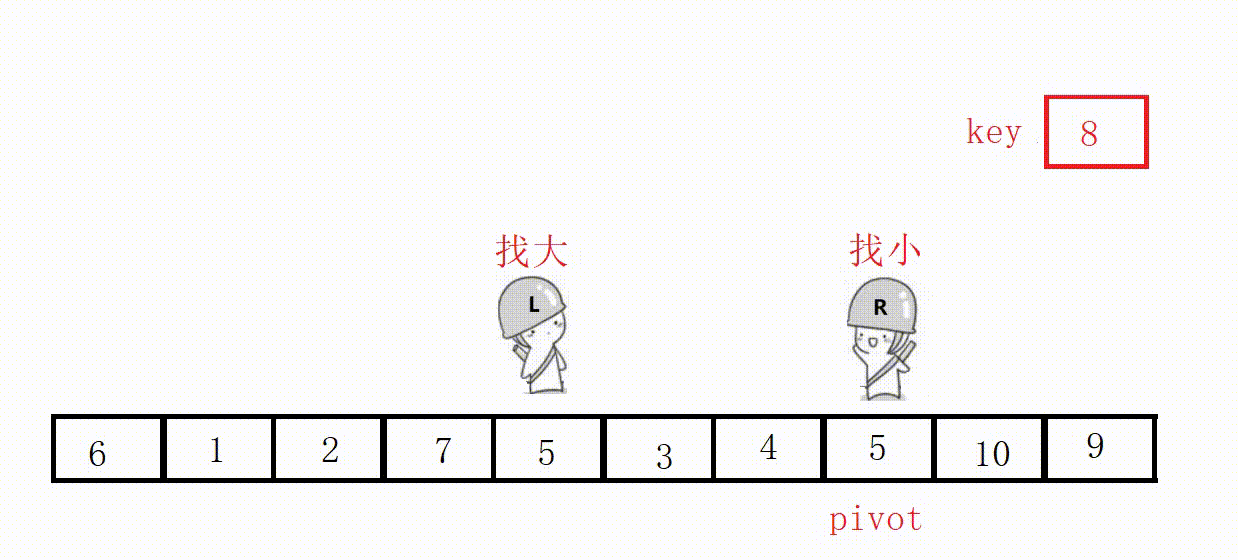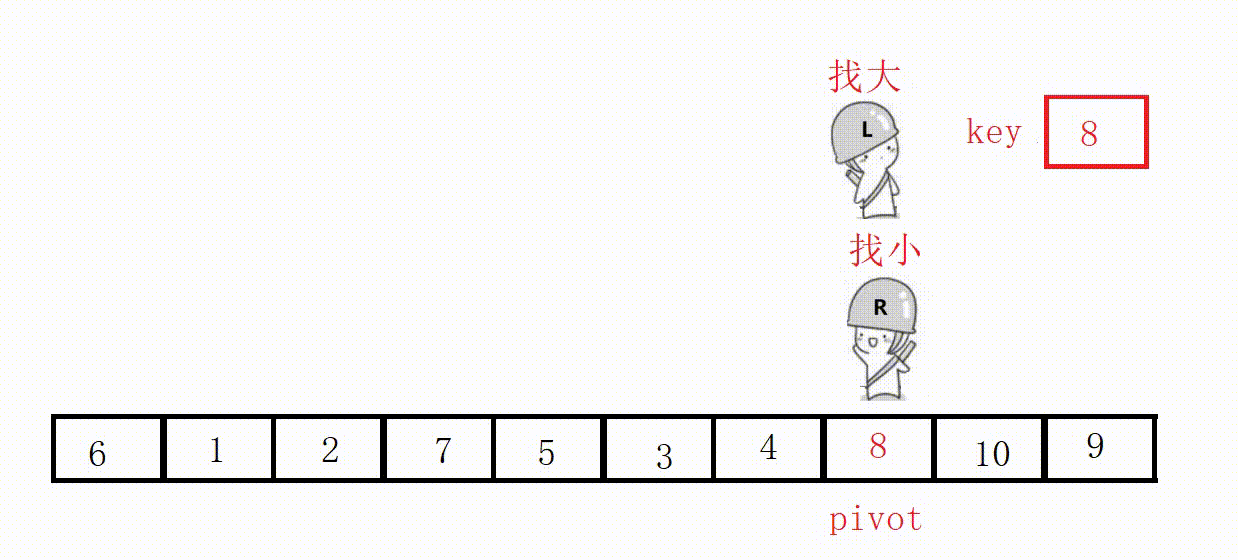
(3) Front and rear pointer method (recommended)
Basic idea:
① Define two pointers prev and cur, prev indicates the end of the processed area on the left, and cur indicates the start of the unprocessed area on the right.
②Scan from cur to the right, if the scanned element is smaller than the reference value, it is exchanged with the element after prev, and the prev pointer is moved to the right by one .
③ Finally, insert the benchmark value into the prev position.
( This process is actually equivalent to driving all values smaller than the key to the left )
Choose the leftmost as the key, and the value at the prev position must be smaller than the key in the end.
Illustration:
code:
//前后指针法 int partion3(int* a, int left, int right) { int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; }
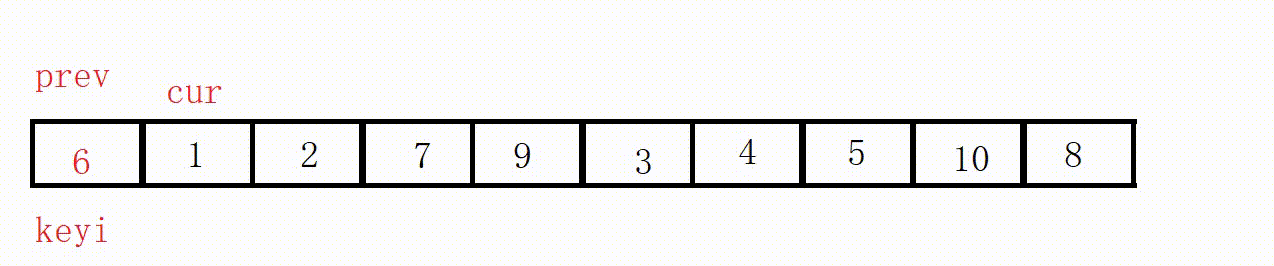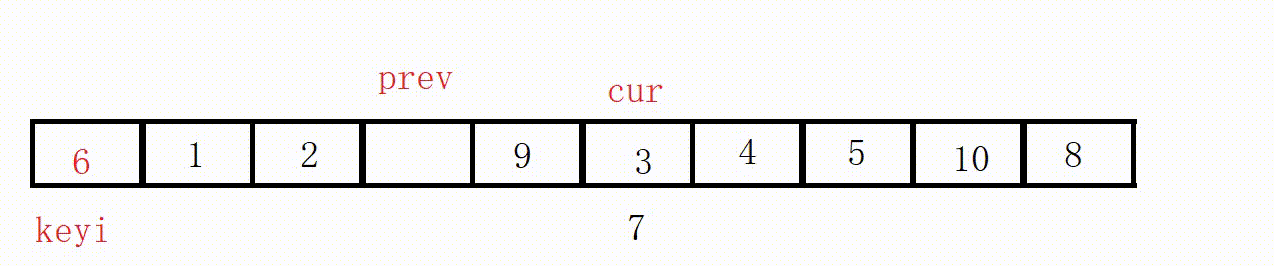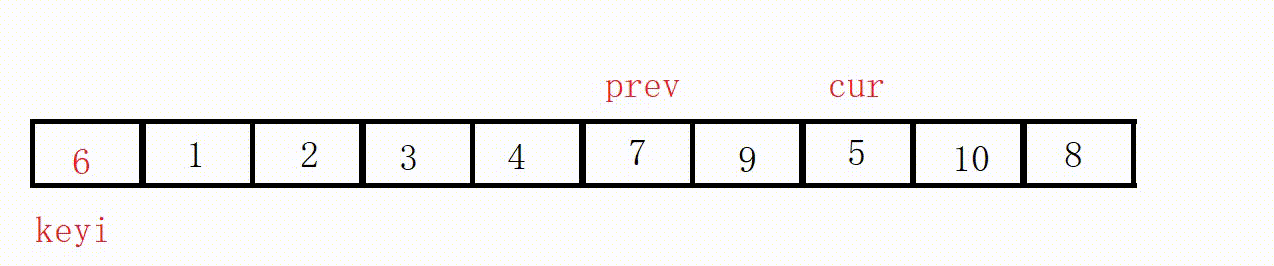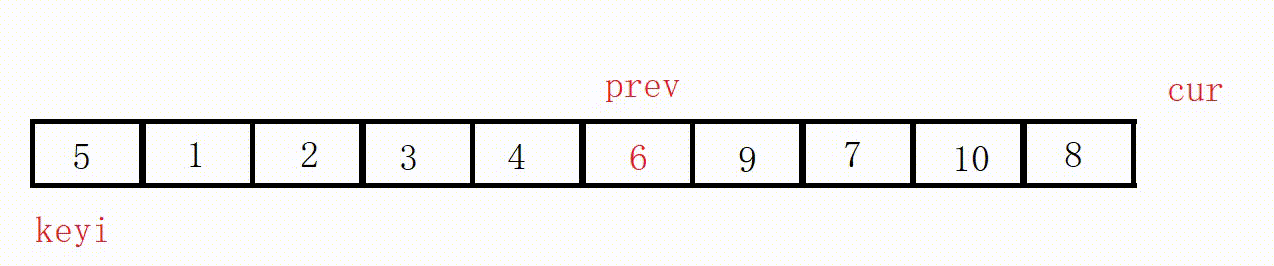
full sort
The core of complete sorting lies in the idea of divide and conquer.
To sort the entire array, we can first determine the position of the key, and use this position as the boundary to divide the left and right areas .
To sort the left area, we first determine the position of the key, and use this position as a boundary to divide two areas.
………………
It has been subdivided until the area does not exist (right<left) or there is only one element (right==left, which is equivalent to order).
Then sort the right region in the same way.
Code (not optimized):
//单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; } //挖坑法单趟 int partion2(int* a, int left, int right) { int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; } //前后指针法 int partion3(int* a, int left, int right) { int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //快速排序 void QuickSort(int* a, int left, int right) { //如果left>right,区间不存在 //left==right,只有一个元素,可以看成是有序的 if (left >= right) { return; } //单次排序 int keyi = partion3(a, left, right); //分成左右区间,排序左右区间 QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); }Illustration:
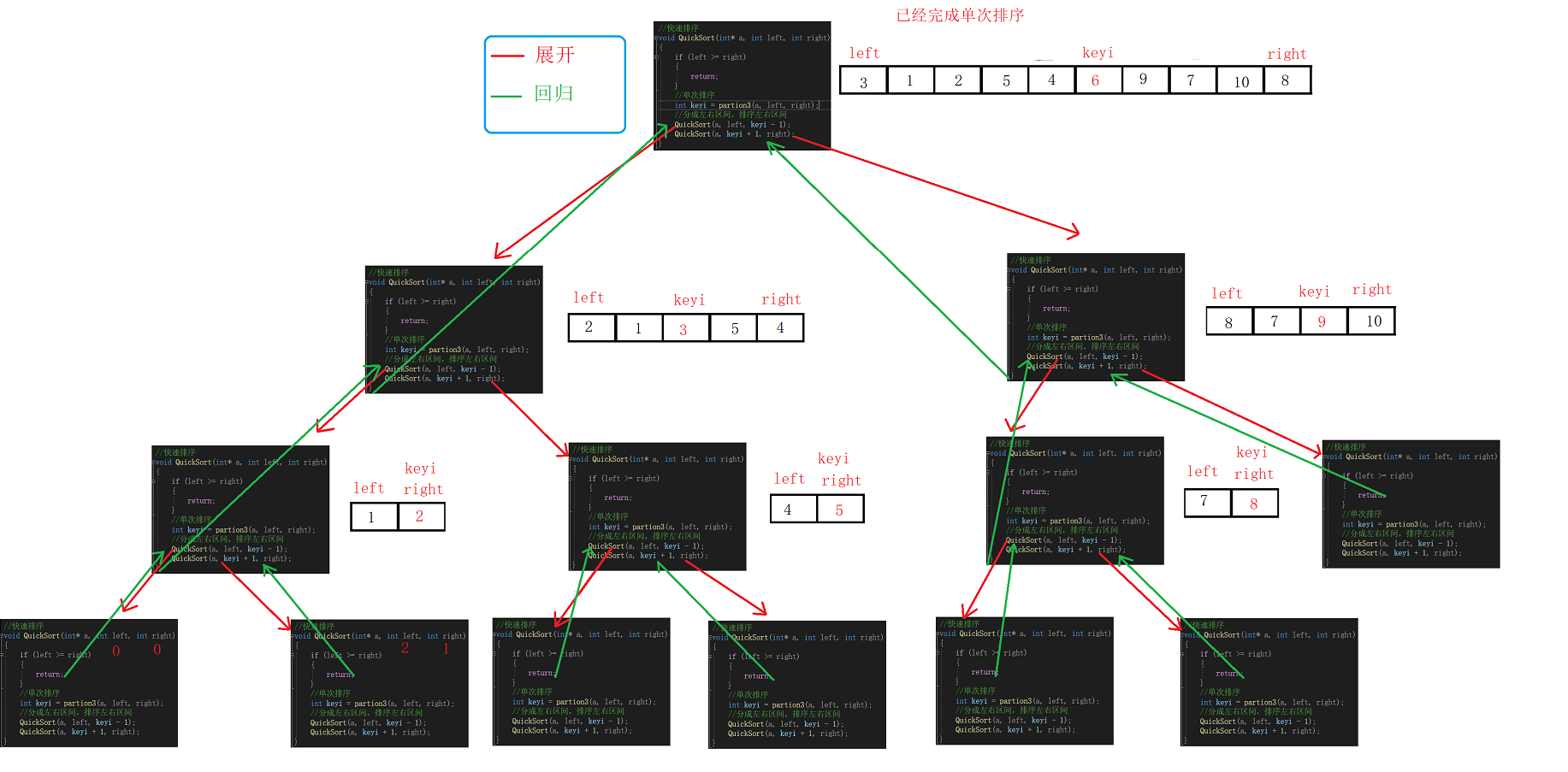
Time Complexity Analysis
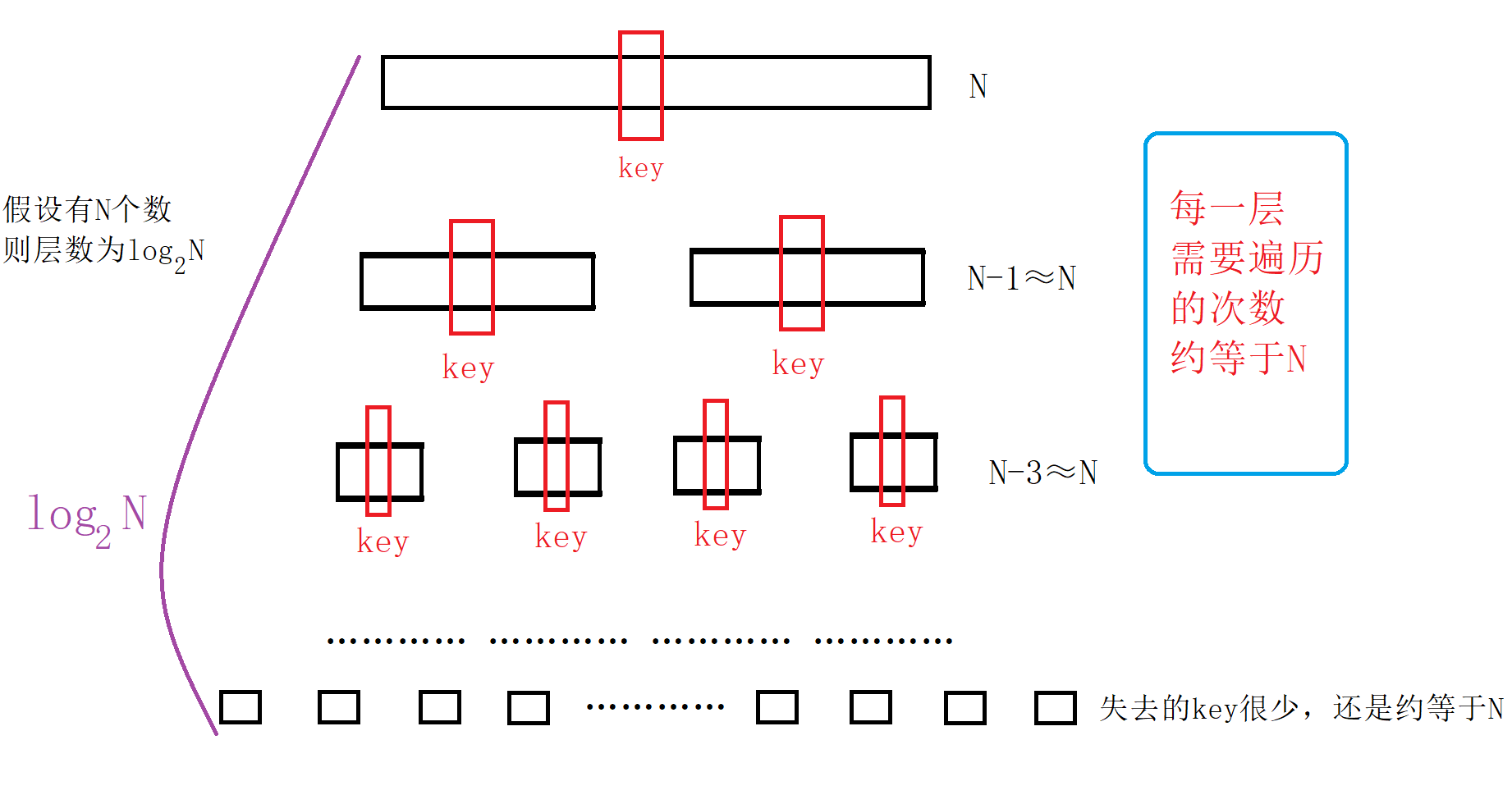
Assuming there are N numbers, the time complexity of quick sorting is generally O(N*logN)
Illustration:
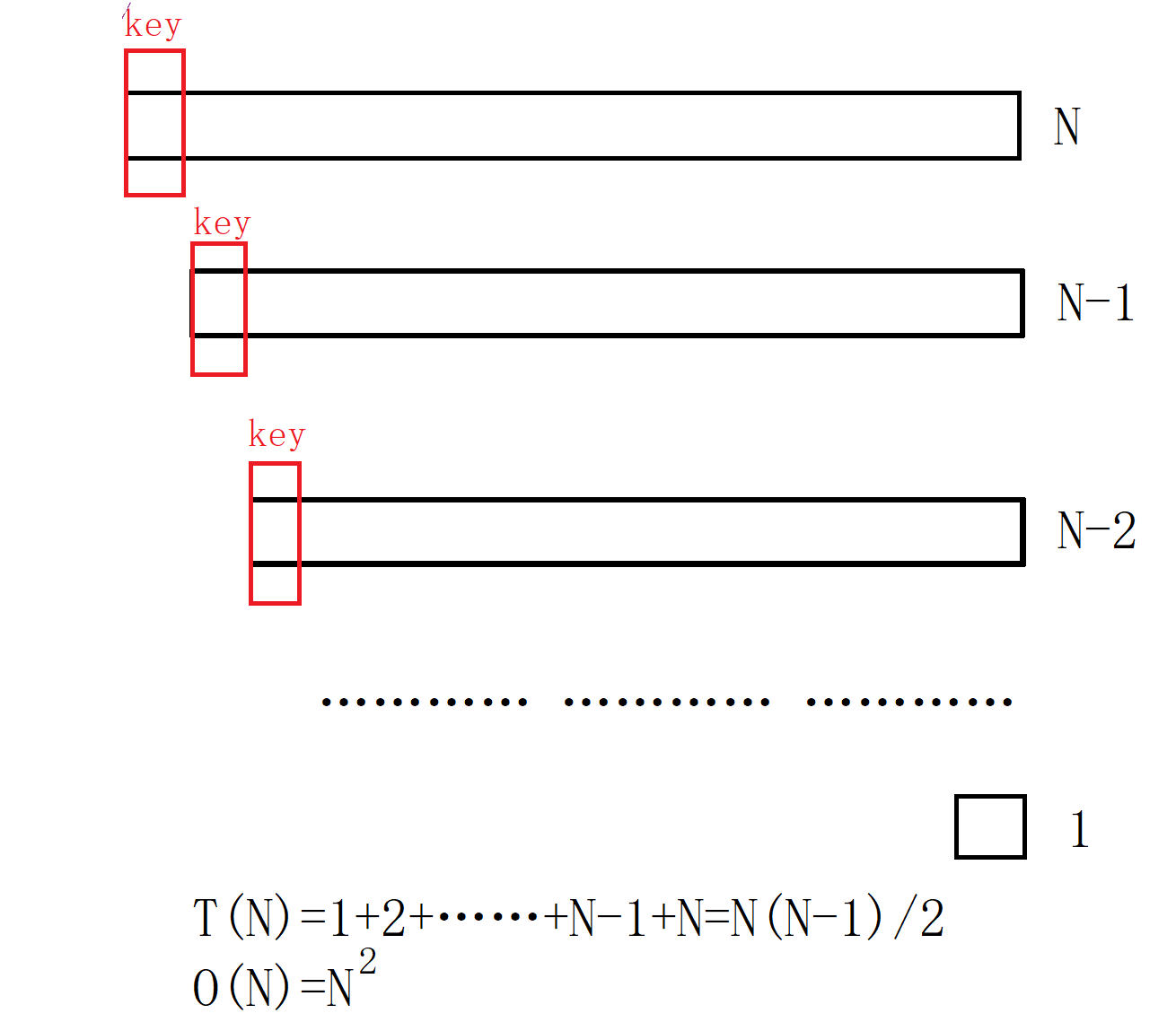
In most cases, this is the case above, but there are also special cases that will reduce the efficiency of quick sorting, such as the original array is in order (later optimization can deal with this situation) or there are many identical data in the array. At this time, the time The complexity is O(N^2).
optimization
(1) Take the middle of the three numbers
Basic idea:
①Since ordering will reduce the sorting efficiency of quick sort, we can shuffle the array by ourselves
②Get the leftmost data, the rightmost data and the middle data of the interval, and get the middle value
③ Exchange this intermediate value with the key we selected
( In this way, the final position of each key is close to the median )
code:
// 三数取中 int GetMidIndex(int* a, int left, int right) { int midi = left + (right - left) / 2; if (a[midi] > a[right]) { if (a[midi] < a[left]) return midi; else if (a[right] > a[left]) return right; else return left; } else // a[right] > a[mid] { if (a[midi] > a[left]) return midi; else if (a[left] < a[right]) return left; else return right; } } //单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //三数取中,打乱顺序 int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; }
(2) Inter-cell optimization (the complete code of recursion is here!!!)
As far as the optimization of the current compiler is concerned, as long as it is properly controlled, the efficiency of recursion and non-recursion is almost the same
The biggest disadvantage of recursion is that if the recursion depth is too deep, it may cause stack overflow.
The purpose of inter-cell optimization is to complete the last few layers of recursion (the last few layers account for 90% of the number of recursions) using other sorting , thus reducing the possibility of stack overflow to a certain extent (it is still possible to overflow).
As for the choice of sorting, because the amount of data is small, a relatively simple sorting method can be used, and the process interval of the quick sorting is constantly approaching order, so it is more appropriate to use direct insertion sorting .
code:
// 三数取中 int GetMidIndex(int* a, int left, int right) { int midi = left + (right - left) / 2; if (a[midi] > a[right]) { if (a[midi] < a[left]) return midi; else if (a[right] > a[left]) return right; else return left; } else // a[right] > a[mid] { if (a[midi] > a[left]) return midi; else if (a[left] < a[right]) return left; else return right; } } //单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; } //挖坑法单趟 int partion2(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; } //前后指针法 int partion3(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //快速排序 void QuickSort(int* a, int left, int right) { //如果left>right,区间不存在 //left==right,只有一个元素,可以看成是有序的 if (left >= right) { return; } //优化,减少递归次数(差不多三层),效率提升几乎没有 //小于10的区间用直接插入排序 if (right - left + 1 < 10) { InsertSort(a + left, right - left + 1); return; } else { //单次排序 int keyi = partion3(a, left, right); //分成左右区间,排序左右区间 QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); } }
Three: non-recursive quick sort
basic idea
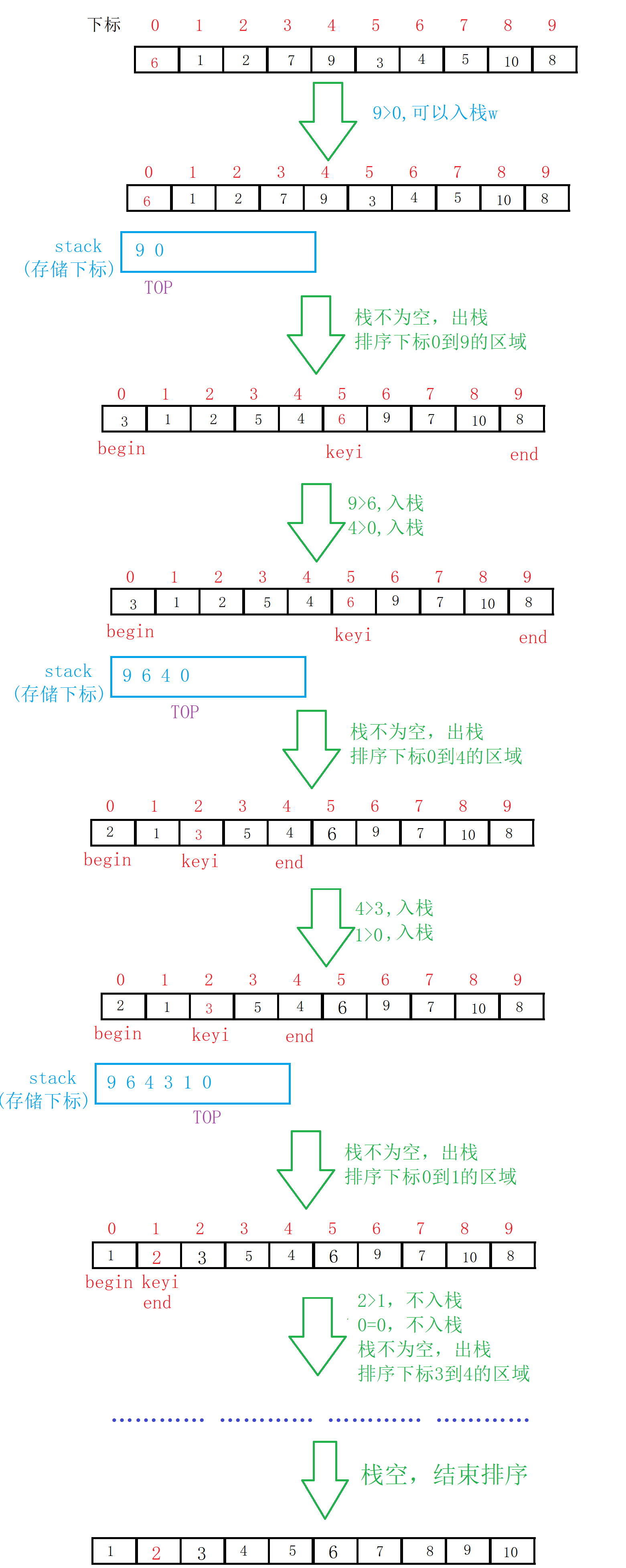
1. The idea of non-recursive implementation is consistent with that of recursion. It is necessary to use the stack to simulate the establishment and destruction of the function stack frame . The entire sequence is regarded as an interval to be sorted, and the left and right pointers are used to point to both ends of the interval;
2. Use the range pointed to by the left and right pointers of the range as the left range and right range of the sequence to be sorted, and save the range information in the stack. This step is equivalent to performing a push operation on the sequence to be sorted ;
3. When the stack is not empty, a range is popped from the top of the stack, and the left and right pointers of the range are used as the reference value for quick sorting. Specifically, divide the interval, select a reference value, divide the array into two parts, and push the left and right intervals into the stack for later sorting;
4. Repeat step 3 until the stack is empty.
Complete sorting (non-recursive full code here!!!)
Illustration:
If you have doubts about the implementation and nature of the stack, you can click the link below, and the code is directly given here
Implementation of the stack: https://blog.csdn.net/2301_76269963/article/details/129823215?spm=1001.2014.3001.5502
code:
//栈的代码 //重定义数据类型,方便更改 typedef int STDataType; typedef struct stack { //存储数据 STDataType* a; //栈顶(位置) int top; //容量 int capacity; }ST; //判断栈是否为空 bool StackEmpty(ST* ps) { //断言,不能传空指针进来 assert(ps); //依据top来判断 /*if (ps->top == 0) return true; return false;*/ //更简洁的写法,一个判断语句的值要么为true,要么false return ps->top == 0; } //初始化 void StackInit(ST* ps) { //断言,不能传空指针进来 assert(ps ); //一开始指向NULL ps->a = NULL; //把栈顶和容量都置为空 ps->top = ps->capacity = 0; } //销毁 void StackDestroy(ST* ps) { //断言,不能传空指针进来 assert(ps ); //栈顶和容量置为空 ps->top = ps->capacity = 0; //释放空间 free(ps->a); ps->a = NULL; } //入栈 void StackPush(ST* ps, STDataType x) { //断言,不能传空指针进来 assert(ps); //先判断是否扩容 if (ps->top == ps->capacity) { int newcapacity = ps->capacity == 0 ? 4 : (ps->capacity) * 2; //扩容 STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity); //扩容失败 if (tmp == NULL) { printf("realloc error\n"); exit(-1); } //更新 ps->capacity = newcapacity; ps->a = tmp; } //存储数据 ps->a[ps->top] = x; ps->top++; } //出栈(删除) void StackPop(ST* ps) { //断言,不能传空指针进来 assert(ps); //如果栈为空,不能出栈 assert(!StackEmpty(ps)); ps->top--; } //取顶部数据 STDataType StackTop(ST* ps) { //断言,不能传空指针进来 assert(ps); //如果栈为空,不能进行访问 assert(!StackEmpty(ps)); //返回栈顶数据 return ps->a[ps->top-1]; } // 三数取中 int GetMidIndex(int* a, int left, int right) { int midi = left + (right - left) / 2; if (a[midi] > a[right]) { if (a[midi] < a[left]) return midi; else if (a[right] > a[left]) return right; else return left; } else // a[right] > a[mid] { if (a[midi] > a[left]) return midi; else if (a[left] < a[right]) return left; else return right; } } //单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; } //挖坑法单趟 int partion2(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; } //前后指针法 int partion3(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //非递归快排 void QuickSortNonR(int* a, int left, int right) { ST s; StackInit(&s); StackPush(&s, right); StackPush(&s, left); //栈不为空,循环继续 while (!StackEmpty(&s)) { int begin = StackTop(&s); StackPop(&s); int end = StackTop(&s); StackPop(&s); int keyi = partion3(a, begin, end); //要先排序左区间,先入右区间,后进先出 //不满足条件代表区间不存在或者区间元素个数为1 if (keyi + 1 < end) { StackPush(&s, end); StackPush(&s, keyi + 1); } if (begin < keyi - 1) { StackPush(&s, keyi-1); StackPush(&s, begin); } } StackDestroy(&s); }
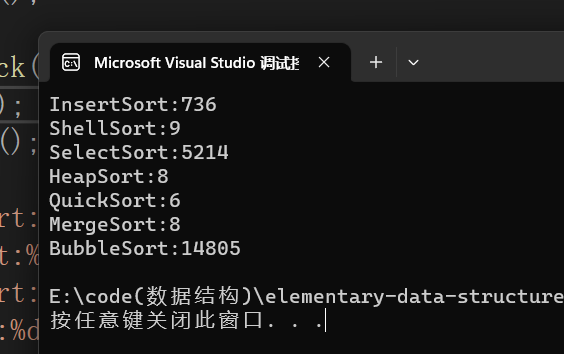
Four: Efficiency comparison
code:
// 测试排序的性能对比 void TestOP() { srand(time(0)); //随机生成十万个数 const int N = 100000; int* a1 = (int*)malloc(sizeof(int) * N); int* a2 = (int*)malloc(sizeof(int) * N); int* a3 = (int*)malloc(sizeof(int) * N); int* a4 = (int*)malloc(sizeof(int) * N); //5和6是给快速排序和归并排序的 int* a5 = (int*)malloc(sizeof(int) * N); int* a6 = (int*)malloc(sizeof(int) * N); int* a7 = (int*)malloc(sizeof(int) * N); if (a1==NULL || a2==NULL ) { printf("malloc error\n"); exit(-1); } if (a3 == NULL || a4 == NULL) { printf("malloc error\n"); exit(-1); } if (a5 == NULL || a6 == NULL || a7 == NULL) { printf("malloc error\n"); exit(-1); } for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; a3[i] = a1[i]; a4[i] = a1[i]; a5[i] = a1[i]; a6[i] = a1[i]; a7[i] = a1[i]; } //clock函数可以获取当前程序时间 int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); int begin3 = clock(); SelectSort(a3, N); int end3 = clock(); int begin4 = clock(); HeapSort(a4, N); int end4 = clock(); int begin5 = clock(); QuickSort(a5, 0, N - 1); int end5 = clock(); int begin6 = clock(); MergeSort(a6, N); int end6 = clock(); int begin7 = clock(); BubbleSort(a7, N); int end7 = clock(); printf("InsertSort:%d\n", end1 - begin1); printf("ShellSort:%d\n", end2 - begin2); printf("SelectSort:%d\n", end3 - begin3); printf("HeapSort:%d\n", end4 - begin4); printf("QuickSort:%d\n", end5 - begin5); printf("MergeSort:%d\n", end6 - begin6); printf("BubbleSort:%d\n", end7 - begin7); free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); free(a7); } int main() { //测试效率 TestOP(); }