
Article directory
foreword
Stable diffusion is a text-to-image model based on Latent Diffusion Models (LDMs) . Specifically, thanks to Stability AI 's computing resource support and a subset of LAION-5B data support training, it is used for text generation.
Latent Diffusion Models generate images by iterating "denoising" data in a latent representation space, and then decode the representation results into complete images, allowing text-to-image generation to generate images in 10 seconds on a consumer-grade GPU . Currently, Stable Diffusion has released the v2 version. The v1 version is a specific implementation of Latent Diffusion Models. The model architecture is set: the autoencoder downsampling factor is 8, the UNet size is 860M, and the text encoder is CLIP ViT-L/14. The official currently provides the following weights :

提示:以下是本篇文章正文内容,下面案例可供参考
1. Latent space
A latent space is a representation of compressed data. The purpose of data compression is to learn the more important information in the data. Taking the encoder-decoder network as an example, first use the fully convolutional neural network (FCN) network to learn image features, and we regard the dimensionality reduction of data in feature extraction as a lossy compression . Since the decoder needs to reconstruct (reconstruct) data, the model must learn how to store all relevant information and ignore noise. The advantage of compression (dimension reduction) is that it can remove redundant information and focus on the most critical features.
2. AutoEncoder and VAE
1.AutoEncoder:
(1) AE is a pre-trained autoencoder. The optimization goal is to compress the data through the Encoder, and then restore the data through the decoder, so that the input and output data are as similar as possible.
(2) For image data, the decoder restored data can be regarded as a generator. Since the decoder input data z belongs to the R space, the distribution of the input z cannot be fixed, so most of the generated pictures are meaningless.
2.LEGS:
(1) A distribution of z given the input decoder can solve the above problems. Assume a data set X of multidimensional random variables subject to the standard multivariate Gaussian distribution , and train the decoder neural network based on the zi obtained by sampling the known distribution, so as to obtain The mean and variance of the multivariate Gaussian distribution, thus successfully obtaining a p'(X) that approximates the real distribution p(X)
(2) Solve the probability distribution of p'(X|z)
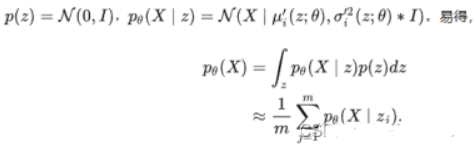
(3) Maximize the probability of p'(X) through maximum likelihood estimation, but since the dimension of xi is very large, the dimension of zi is also large, and it is necessary to Accurately finding zi related to the xi distribution requires a large number of samples, so it is necessary to introduce the posterior distribution p'(z|xi) in the encoder to associate xi with zi
(4) Use the encoder to fit its parameters by assuming the distribution of known data, so as to approximate the real posterior distribution p'(z|xi). Here, it is assumed that the posterior distribution is based on a multivariate Gaussian distribution, then let the encoder output the distribution mean and variance of
(5) Overall process

3. Diffusion diffusion model
1. Forward process
1. The distribution at time t is equal to the distribution at time t-1 + the noise of random Gaussian distribution, where α is the attenuation value of the noise. 2. The
distribution X t at any time can be calculated from the initial state of X 0 and the number of steps:
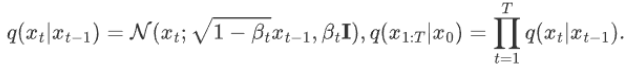
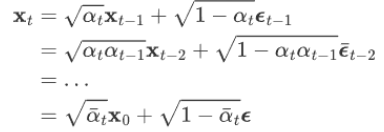
2. Reverse process
Knowing X t , find the initial state X 0 , here use the Bayesian formula to predict X 0 :
first find the distribution of the known X t and get the distribution at **X t-1 ** time (see the previous blog for detailed derivation ) :

4. Multimodal cross attention
Introduce cross attention in the middle layer of Unet , add multi-modal conditions (text, category, layout, mask), and implement as follows: where Q comes from latent space , K and V come from another sequence such as text :
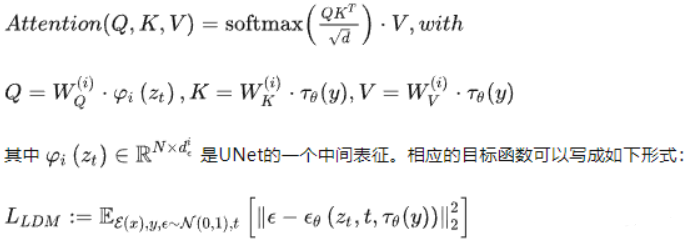
5. Principle of Stable Diffusion
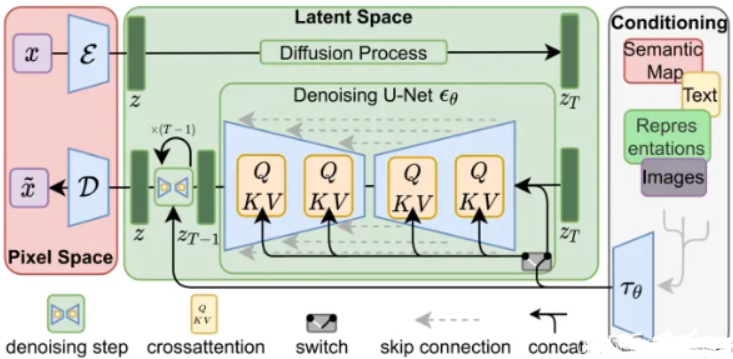
1. Training process:
(1) Use the pre-trained CLIP model to generate corresponding description words for the image data that needs to be trained.
(2) Use the pre-trained general-purpose VAE, first use Encoder to reduce the input image to latent space (usually the downsampling factor is 4-16)
(3) Input the latent space into the diffusion model, perform diffusion (forward sampling), and generate noise step by step (in this process, control the intensity of noise generation at each step through weight β until pure noise is generated, and record the noise generation at each step data, as GT
(4) Use cross attention to fuse the features of the latent space with the features of another modal sequence, and add it to the reverse process of the diffusion model, reversely predict the noise that needs to be reduced in each step through Unet, and use the loss function of GT noise and prediction noise Compute the gradient.
(5) The structure of Denoising Unet is as follows:
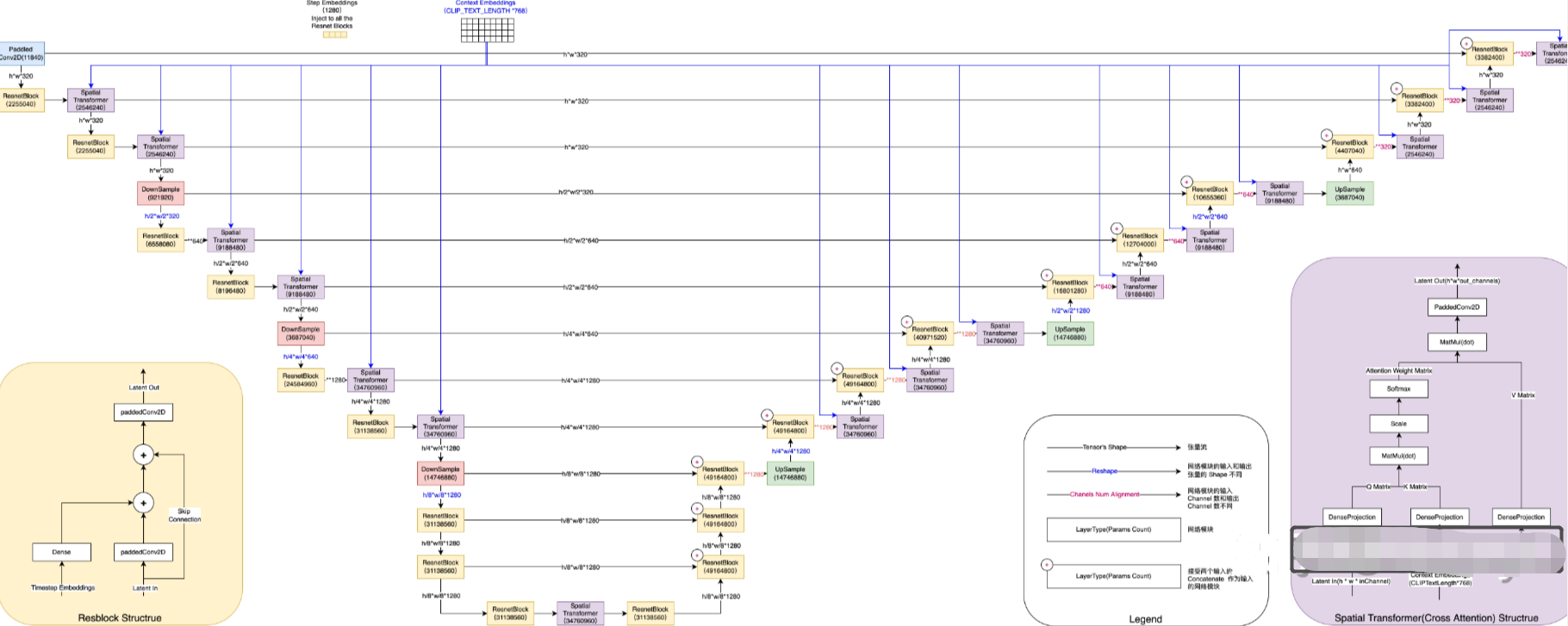
ResnetBlock
As shown in the small picture in the lower left corner, ResnetBlock accepts two inputs: the latent vector is summed with the timestep_embedding of the fully connected projection after convolution transformation, and then summed with the original latent vector after skip connection, and sent to another convolution layer to get the latent output after Resnet encoding transformation.
Note the slight difference between the ResnetBlock on the left and the ResnetBlock on the right. The latent vector accepted by the Resnet Block on the left is passed in from the upper layer of UNET, while the Resnet Block on the right needs to accept the output of the corresponding UNET layer on the left in addition to the latent result of the upper layer of UNET. Two latent concat up as input. Therefore, if the output result of the upper layer of the ResnetBlock on the right is (64, 64, 320), and the output result of the corresponding UNET layer on the left is (64, 64, 640), then the shape of the input latent obtained by this ResnetBlock is (64 , 64, 960).
Spatial Transformer(Cross Attention)
As shown in the small picture in the lower right corner, the Spatial Transformer also accepts two inputs: the latent vector (corresponding to the image token ) processed and transformed by the previous network module (usually ResnetBlock), and the corresponding context embedding (the text prompt passed through CLIP encoded output), after cross attention, the transformed latent vector is obtained (through the attention mechanism, the semantic information corresponding to the token is injected into the image patch that the model thinks should be affected). The shape output by the Spatial Transformer is the same as the input, but the semantic information is fused at the corresponding position.
DownSample/UpSample
DownSample reduces the size of the first two axes of the latent vector by 50%, and UpSample doubles the size of the first two axes of the latent vector. DownSample is implemented using a two-dimensional convolution with a step size of 2, and at the same time changes the channel number of the input latent vector to the channel number of the output latent vector; UpSample is implemented using an interpolation algorithm, and a step size of 1 is performed after interpolation Convolution, at the same time, through a two-dimensional convolution with a step size of 1, the channel number of the input latent vector is changed to the channel number of the output latent vector.
It should be noted that timestep_embedding and content embedding remain unchanged during the entire UNET execution. In the process of repeated execution of UNET for many times, timestep_embedding will change every time, but content embedding will always remain unchanged. In the iterative process, the noise_slice output by UNET is subtracted from the original latent vector each time, and used as the latent input of UNET in the next iteration.
2. Forward process
An Image Auto Encoder-Decoder, which is used to encode the Image into a hidden vector
, or
restore the image from the hidden vector;
a UNET structure, which uses UNET for iterative noise reduction, and performs multiple rounds of prediction under the guidance of the text, and random Gaussian The noise
is transformed into image latent vectors
.
1. Use a text encoder (CLIP's ViT-L/14) to convert the Prompt text input by the user into text embedding;
2. Generate a pure noise image according to the assumed distribution (usually a multivariate Gaussian distribution);
3. Use VAE encoder compresses to latent space;
4. Execute Denoising Unet, use cross attention to fuse multi-modal information, and predict the noise that needs to be subtracted in each step:
5. Use VAE decoder to restore the original image size under the same distribution
*, code analysis
1. Overall code
1、prompt编码为token。编码器为FrozenCLIPEmbedde(包括1层的 CLIPTextEmbeddings 和12层的自注意力encoder)
c = self.cond_stage_model.encode(c) # (c为输入的提示语句,重复2次) 输出:(2,77,768)
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
# self.tokenizer来自 transformers包中的 预训练CLIPTokenizer
tokens = batch_encoding["input_ids"].to(self.device) # (2,77)一句话编码为77维
outputs = self.transformer(input_ids=tokens).last_hidden_state # 12层self-atten,结果(2,77,768)
2、samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
01、self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose) # S=50
# 这一步是ddim中,预先register超参数,如a的连乘等
# Data shape for PLMS sampling is (2, 4, 32, 32)
02、samples, intermediates = self.plms_sampling(conditioning, size,
callback=callback,
img_callback=img_callback,
quantize_denoised=quantize_x0,
mask=mask, x0=x0,
ddim_use_original_steps=False,
noise_dropout=noise_dropout,
temperature=temperature,
score_corrector=score_corrector,
corrector_kwargs=corrector_kwargs,
x_T=x_T )
img = torch.randn(shape, device=device) # (2,4,32,32)
for i, step in enumerate(iterator):
index = total_steps - i - 1 # index=50-i-1, step=981
ts = torch.full((b,), step, device=device, dtype=torch.long) # [981,981]
outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
quantize_denoised=quantize_denoised, temperature=temperature,
noise_dropout=noise_dropout, score_corrector=score_corrector,
corrector_kwargs=corrector_kwargs,
unconditional_guidance_scale=unconditional_guidance_scale,
unconditional_conditioning=unconditional_conditioning,
old_eps=old_eps, t_next=ts_next)
c_in = torch.cat([unconditional_conditioning, c]) # 添加一个空字符,与promt拼接
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False) # timesteps:[981,981,981,981] -> (4,320)
emb = self.time_embed(t_emb) # 2*linear:(4,320) -> (4,1280)
# unet中带入embed与prompt,具体代码见下节
for module in self.input_blocks:
h = module(h, emb, context) # 输入(4,4,32,32) (4,1280) (4,77,768)
hs.append(h)
h = self.middle_block(h, emb, context)
for module in self.output_blocks:
h = th.cat([h, hs.pop()], dim=1) # (4,1280,4,4) -> (4,2560,4,4)
h = module(h, emb, context)
return self.out(h) # (4,320,32,32)卷积为(4,4,32,32)
3、e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2) # 上步中得到的结果拆开:(2,4,32,32
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond) # 用7.5乘以二者差距,再加回空语句生成的图
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index) # DDIM计算:e_t(2,4,32,32) index:49 -> (2,4,32,32)
4、x_samples_ddim = model.decode_first_stage(samples_ddim) # (2,4,32,32)
h = self.conv_in(z) # 卷积4->512
x = torch.nn.functional.interpolate(h, scale_factor=2.0, mode="nearest") #(2,512,64,64)
h = self.up[i_level].block[i_block](h) # 经过几次卷积与上采样
h = self.norm_out(h) # (2,128,256,256)
h = nonlinearity(h) # x*torch.sigmoid(x)
h = self.conv_out(h) # conv(128,3) -》(2,3,256,256)
5、后处理
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
2.unet analysis
Unet in DDIM includes three parts: input module , intermediate module and output module :
1、self.input_blocks
Contains 12 different TimestepEmbedSequential structures, three of which are listed below:
1、self.input_blocks
ModuleList(
(0): TimestepEmbedSequential(
(0): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): TimestepEmbedSequential(
(0): ResBlock(
(in_layers): Sequential(
(0): GroupNorm32(32, 320, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(h_upd): Identity()
(x_upd): Identity()
(emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=1280, out_features=320, bias=True)
)
(out_layers): Sequential(
(0): GroupNorm32(32, 320, eps=1e-05, affine=True)
(1): SiLU()
(2): Dropout(p=0, inplace=False)
(3): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(skip_connection): Identity()
)
(1): SpatialTransformer(
(norm): GroupNorm(32, 320, eps=1e-06, affine=True)
(proj_in): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(attn1): CrossAttention(
(to_q): Linear(in_features=320, out_features=320, bias=False)
(to_k): Linear(in_features=320, out_features=320, bias=False)
(to_v): Linear(in_features=320, out_features=320, bias=False)
(to_out): Sequential(
(0): Linear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(ff): FeedForward(
(net): Sequential(
(0): GEGLU(
(proj): Linear(in_features=320, out_features=2560, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): Linear(in_features=1280, out_features=320, bias=True)
)
)
(attn2): CrossAttention(
(to_q): Linear(in_features=320, out_features=320, bias=False)
(to_k): Linear(in_features=768, out_features=320, bias=False)
(to_v): Linear(in_features=768, out_features=320, bias=False)
(to_out): Sequential(
(0): Linear(in_features=320, out_features=320, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
)
(proj_out): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
)
)
(6): TimestepEmbedSequential(
(0): Downsample(
(op): Conv2d(640, 640, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
Forward process :
add emb to h and cross attention with propmt, which will be executed multiple times
emb_out = self.emb_layers(emb) # (4,1280)卷积为(4,320)
h = h + emb_out # (4,320,32,32)+(4,320,1,1)
x = self.attn1(self.norm1(x)) + x # 自注意力:x(4,1024,320)映射到qkv,均320维
x = self.attn2(self.norm2(x), context=context) + x # 交叉注意力:context(4,77,768)映射到kv的320维
x = self.ff(self.norm3(x)) + x
The noise image h(4, 4, 32, 32) changes in it to: (4, 320, 32, 32) (4, 320, 16, 16) (4, 640, 16, 16) (4, 1280, 8 , 8) (4, 1280, 4, 4)
2、middle_blocks
TimestepEmbedSequential(
(0): ResBlock(
(in_layers): Sequential(
(0): GroupNorm32(32, 1280, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(h_upd): Identity()
(x_upd): Identity()
(emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=1280, out_features=1280, bias=True)
)
(out_layers): Sequential(
(0): GroupNorm32(32, 1280, eps=1e-05, affine=True)
(1): SiLU()
(2): Dropout(p=0, inplace=False)
(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(skip_connection): Identity()
)
(1): SpatialTransformer(
(norm): GroupNorm(32, 1280, eps=1e-06, affine=True)
(proj_in): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))
(transformer_blocks): ModuleList(
(0): BasicTransformerBlock(
(attn1): CrossAttention(
(to_q): Linear(in_features=1280, out_features=1280, bias=False)
(to_k): Linear(in_features=1280, out_features=1280, bias=False)
(to_v): Linear(in_features=1280, out_features=1280, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(ff): FeedForward(
(net): Sequential(
(0): GEGLU(
(proj): Linear(in_features=1280, out_features=10240, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): Linear(in_features=5120, out_features=1280, bias=True)
)
)
(attn2): CrossAttention(
(to_q): Linear(in_features=1280, out_features=1280, bias=False)
(to_k): Linear(in_features=768, out_features=1280, bias=False)
(to_v): Linear(in_features=768, out_features=1280, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1280, out_features=1280, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
)
)
(proj_out): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResBlock(
(in_layers): Sequential(
(0): GroupNorm32(32, 1280, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(h_upd): Identity()
(x_upd): Identity()
(emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=1280, out_features=1280, bias=True)
)
(out_layers): Sequential(
(0): GroupNorm32(32, 1280, eps=1e-05, affine=True)
(1): SiLU()
(2): Dropout(p=0, inplace=False)
(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(skip_connection): Identity()
)
3、self.output_blocks
Same as the input module, containing 12 TimestepEmbedSequential in reverse order
Summarize
整体结构比较简单,先用预训练CLIP将prompt变为token; DDIM模型将噪音与token逆扩散为图像;再采用VAE的decoder将图像复原到正常大小: