
Polars is an extremely fast DataFrames library.
It has the following properties:
1. Multithreading
2. Powerful expression API
3. Query optimization
Here is a brief introduction to how to use this module.
1. Prepare
Before starting, you need to make sure that Python and pip have been successfully installed on your computer. If not, you can visit this article: Super detailed Python installation guide for installation.
(Optional 1) If you use Python for data analysis, you can install Anaconda directly: Anaconda, a good helper for Python data analysis and mining , has built-in Python and pip.
(Optional 2) In addition, it is recommended that you use the VSCode editor, which has many advantages: The best partner for Python programming—VSCode detailed guide .
Please choose one of the following ways to enter the command to install dependencies :
1. Open Cmd (Start-Run-CMD) in the Windows environment.
2. Open Terminal in the MacOS environment (command+space to enter Terminal).
3. If you are using VSCode editor or Pycharm, you can directly use the Terminal at the bottom of the interface.
pip install polars2. Polars introduction
When initializing variables, the way Polars is used is not much different from Pandas. Below we define an initial variable, which will be used in all subsequent examples:
import polars as pl
df = pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
}
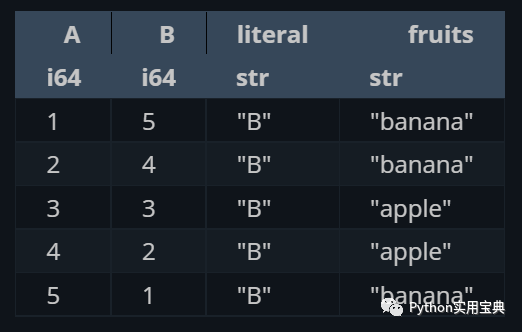
)Select the data to display:
(df.select([
pl.col("A"),
"B", # the col part is inferred
pl.lit("B"), # we must tell polars we mean the literal "B"
pl.col("fruits"),
]))The effect is as follows:
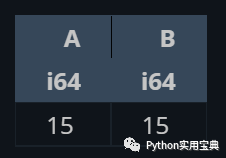
He can also use regular expressions to filter values and perform operations such as summing:
# 正则表达式
(df.select([
pl.col("^A|B$").sum()
]))
# 或者多选
(df.select([
pl.col(["A", "B"]).sum()
]))
Polars supports the following complex and efficient query and display:
>>> df.sort("fruits").select(
... [
... "fruits",
... "cars",
... pl.lit("fruits").alias("literal_string_fruits"),
... pl.col("B").filter(pl.col("cars") == "beetle").sum(),
... pl.col("A").filter(pl.col("B") > 2).sum().over("cars").alias("sum_A_by_cars"),
... pl.col("A").sum().over("fruits").alias("sum_A_by_fruits"),
... pl.col("A").reverse().over("fruits").alias("rev_A_by_fruits"),
... pl.col("A").sort_by("B").over("fruits").alias("sort_A_by_B_by_fruits"),
... ]
... )
shape: (5, 8)
┌──────────┬──────────┬──────────────┬─────┬─────────────┬─────────────┬─────────────┬─────────────┐
│ fruits ┆ cars ┆ literal_stri ┆ B ┆ sum_A_by_ca ┆ sum_A_by_fr ┆ rev_A_by_fr ┆ sort_A_by_B │
│ --- ┆ --- ┆ ng_fruits ┆ --- ┆ rs ┆ uits ┆ uits ┆ _by_fruits │
│ str ┆ str ┆ --- ┆ i64 ┆ --- ┆ --- ┆ --- ┆ --- │
│ ┆ ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞══════════╪══════════╪══════════════╪═════╪═════════════╪═════════════╪═════════════╪═════════════╡
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 4 ┆ 4 │
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 3 ┆ 3 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 5 ┆ 5 │
│ "banana" ┆ "audi" ┆ "fruits" ┆ 11 ┆ 2 ┆ 8 ┆ 2 ┆ 2 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 1 ┆ 1 │
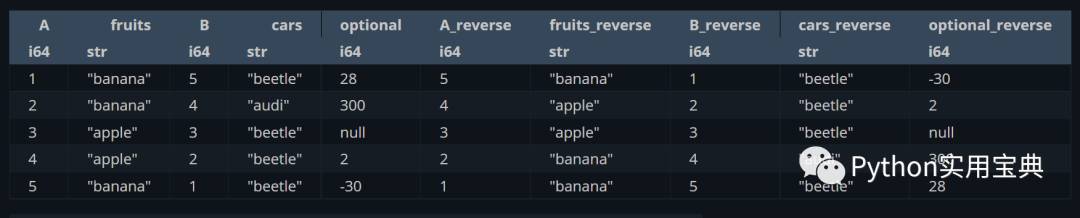
└──────────┴──────────┴──────────────┴─────┴─────────────┴─────────────┴─────────────┴─────────────┘3. Advanced use of Polars
Reverse operation, reverse the value and put it back into the variable, named xxx_reverse:
(df.select([
pl.all(),
pl.all().reverse().suffix("_reverse")
]))
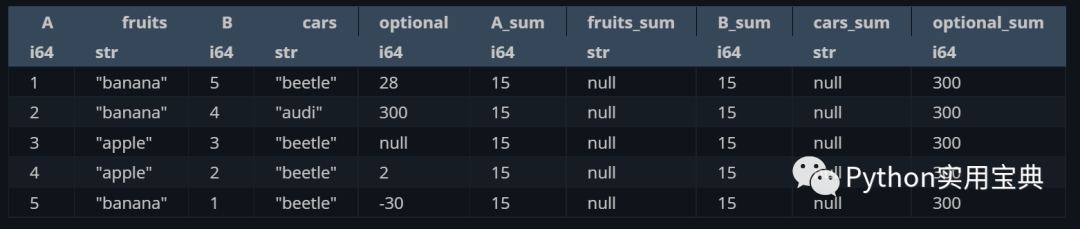
Sum all the columns and put them back into a variable named xxx_sum:
(df.select([
pl.all(),
pl.all().sum().suffix("_sum")
]))
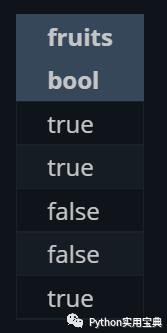
Regex can also be used for filtering:
predicate = pl.col("fruits").str.contains("^b.*")
(df.select([
predicate
]))
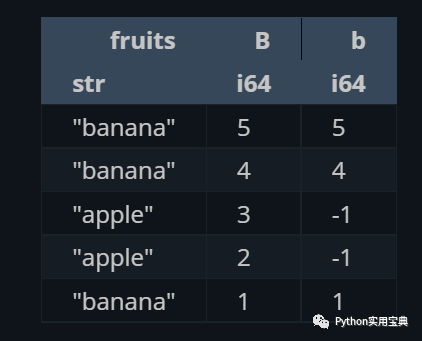
When setting a new column, it is even possible to set values for different rows based on conditions:
(df.select([
"fruits",
"B",
pl.when(pl.col("fruits") == "banana").then(pl.col("B")).otherwise(-1).alias("b")
]))
The fold function is powerful, and it performs operations on columns for the fastest, aka vectorized execution:
df = pl.DataFrame({
"a": [1, 2, 3],
"b": [10, 20, 30],
}
)
out = df.select(
pl.fold(acc=pl.lit(0), f=lambda acc, x: acc + x, exprs=pl.col("*")).alias("sum"),
)
print(out)
# shape: (3, 1)
# ┌─────┐
# │ sum │
# │ --- │
# │ i64 │
# ╞═════╡
# │ 11 │
# ├╌╌╌╌╌┤
# │ 22 │
# ├╌╌╌╌╌┤
# │ 33 │
# └─────┘Polars also has many other useful features, if you are interested, you can visit their user manual to read and learn:
https://pola-rs.github.io/polars-book/user-guide
This is the end of our article. If you like today's Python practical tutorial, please continue to pay attention to Python Practical Collection.
If you have any questions, you can reply in the background of the official account: join the group , answer the corresponding red letter verification information , and enter the mutual assistance group to ask.
Originality is not easy, I hope you can give me a thumbs up below and watch to support me to continue creating, thank you!
Click below to read the original text for a better reading experience
Python Practical Collection (pythondict.com)
is not just a collection.
Welcome to pay attention to the official account: Python Practical Collection
